
הגדרה וניהול של צינורות לעיבוד נתונים
המסמך הזה עוזר למהנדסי אבטחה להגדיר ולנהל צינורות לעיבוד נתונים ב-Google SecOps כדי לסנן אירועים, לשנות שדות או לצנזר ערכים רגישים לפני ההטמעה. התכונה הזו מספקת שליטה חזקה בתהליך הטמעת הנתונים לפני הניתוח שלהם. בעזרת השיטות המומלצות במדריך הזה, תוכלו לייעל את התאימות של הנתונים, להפחית את העלויות ולהגן על מידע רגיש ב-Google SecOps.
עיבוד הנתונים מפשט את ניהול היומנים באמצעות הפעולות העיקריות הבאות:
- סינון: צמצום הרעש והעלויות על ידי הטמעה רק של אירועים רלוונטיים.
- טרנספורמציה: שינוי פורמטים של נתונים, ניתוח שדות והעשרה של יומנים לשיפור השימושיות.
- Redact: הגנה על מידע רגיש באמצעות הסתרה או הסרה של ערכים רגישים לפני האחסון.
בתרשים הבא מוצג אופן הזרימה של הנתונים אל Google SecOps ואופן העיבוד של הנתונים על ידי המערכת:
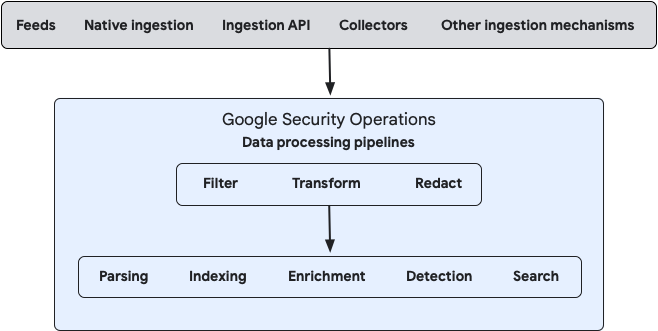
אתם יכולים להגדיר עיבוד של נתונים מקומיים ונתונים בענן באמצעות מסוף הניהול של Bindplane או באמצעות ממשקי ה-API הציבוריים של Google SecOps Data Pipeline.
תרחישים נפוצים לדוגמה
דוגמאות לתרחישי שימוש בעיבוד נתונים:
- הסרת צמדי מפתח/ערך ריקים מיומנים גולמיים.
- צנזור מידע אישי רגיש.
- הוספת תוויות להעברה מתוכן יומן גולמי.
- בסביבות כמה מופעים במקביל, צריך להחיל תוויות להטמעת נתונים על נתוני יומן של הטמעת נתונים ישירה כדי לזהות את מופע מקור הנתונים (למשל,Google Cloud Workspace).
- סינון נתונים של Palo Alto Cortex לפי ערכי שדות.
- צמצום הנתונים של SentinelOne לפי קטגוריה.
- לחלץ מידע על המארח מפידים ומיומנים של הטמעה ישירה ולמפות אותו לשדה
ingestion_sourceב-Cloud Monitoring.
מונחים חשובים
עיבוד הנתונים מתבצע באמצעות הרכיבים הבאים:
- Streams: זרם נתונים ספציפי, שמוגדר לפי סוג היומן ומקור ההטמעה (כמו פיד או API), ומשמש כקלט לצינור לעיבוד נתונים.
- צומת עיבוד: רכיב בצינור שמכיל מעבד אחד או יותר, כמו פעולות סינון, שינוי או עריכה. המעבדים האלה מבצעים שינויים בנתונים באופן עקבי כשהם עוברים דרך הצומת.
- יעד: נקודת הקצה של צינור עיבוד הנתונים, בדרך כלל מופע Google SecOps שאליו נשלחים נתונים מעובדים לצורך הטמעה וניתוח סופיים.
לפני שמתחילים
לפני שמתחילים להגדיר צינורות לעיבוד נתונים, חשוב לעיין בדרישות הבאות:
- השפעה על מנתח התוכן ועל UDM: צינורות לעיבוד נתונים משנים נתוני יומן גולמיים לפני שהם מגיעים למנתחי התוכן של Google SecOps. השינויים האלה יכולים להשפיע על האופן שבו כלי הניתוח מפרשים את היומנים וממירים אותם לפורמט של מודל נתונים מאוחד (UDM). לפני שמפעילים צינור לעיבוד נתונים עבור פיד או סוג יומן, צריך לוודא שכללי הסינון, ההמרה או הצנזורה לא משנים את הנתונים בטעות באופן שמונע ממנתחי הנתונים ליצור אירועי UDM נכונים.
- תמיכה ב-API: אפשר לעבד נתונים בזרמים מבוססי-דחיפה באמצעות קריאה ל-Chronicle API. מסננים שהוגדרו ב-Data Processing Manager (DPM) מוחלים אחרי שהנתונים מתקבלים על ידי Chronicle Ingestion API. לכן, המסננים האלה לא מונעים מלקוחות לחרוג מהמכסות והמגבלות של Ingestion API, כמו המגבלות של importPushLog API, כי המגבלות האלה נבדקות לפני הסינון ב-DPM. כדי לנהל את המגבלות של Ingestion API בצורה יעילה ולא לחרוג מהן, הלקוחות צריכים להטמיע סינון במקור הנתונים עצמו ולא להסתמך על מסנני DPM.
- חשיפת נתונים: נתונים שמועברים מ-forwarders ומ-Bindplane מתויגים ב-
collectorIDשונה מנתונים שמועברים ישירות. כדי לתמוך בחשיפת יומנים מלאה, צריך לבחור את כל שיטות ההעברה כשמבצעים שאילתות על מקורות נתונים, או לציין במפורש את ה-collectorIDהרלוונטי כשמבצעים אינטראקציה עם ה-API. הגדרה של Bindplane console: אם אתם מתכננים להשתמש ב-Bindplane console להגדרה ולניהול, אתם צריכים לבצע את השלבים הבאים:
במסוף Google SecOps, מעניקים למשתמש או לחשבון השירות שבהם תשתמשו כדי להגדיר את השילוב של Bindplane את אחת מההרשאות הבאות:
תפקיד בהתאמה אישית עם ההרשאות הבאות:
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.list
מומלץ להשתמש בתפקיד מותאם אישית עם ההרשאות הנדרשות שצוינו.
מידע נוסף מופיע במאמרים יצירה וניהול של תפקידים בהתאמה אישית והגדרת בקרת גישה לפיצ'רים באמצעות IAM.
תפקיד האדמין המוגדר מראש ב-Chronicle API.
roles/chronicle.adminפרטים נוספים זמינים במאמר הקצאת תפקיד אדמין IAM בפרויקט ייעודי.
מתקינים את מסוף Bindplane Server. ל-SaaS או לפתרון מקומי, אפשר לעיין במאמר התקנת מסוף Bindplane Server. חשוב לוודא שמותקנת הגרסה העדכנית של Bindplane (או Bindplane גרסה 1.96.4 ואילך).
במסוף Bindplane, מקשרים מכונת יעד של Google SecOps לפרויקט Bindplane. פרטים נוספים זמינים במאמר בנושא קישור למכונת Google SecOps.
חיבור למכונת Google SecOps
לפני שמתחילים, צריך לוודא שיש לכם הרשאות אדמין בפרויקט ב-Bindplane כדי לגשת לדף Project Integrations (שילובים בפרויקט).
מכונת Google SecOps משמשת כיעד לפלט הנתונים.
כדי להתחבר למופע של Google SecOps באמצעות מסוף Bindplane Server:
- במסוף של Bindplane Server, לוחצים על Menu (תפריט) ובוחרים באפשרות Project Settings (הגדרות הפרויקט).
- בדף Project Settings (הגדרות הפרויקט), עוברים לכרטיס Integrations (שילובים) ולוחצים על Connect to Google SecOps (חיבור ל-Google SecOps) כדי לפתוח את החלון Edit Integration (עריכת השילוב).
מזינים את הפרטים של מכונת היעד של Google SecOps.
המופע הזה קולט את הנתונים המעובדים (הפלט מעיבוד הנתונים), באופן הבא:שדה תיאור אזור האזור של מכונת Google SecOps.
כדי למצוא את המופע במסוף Google Cloud , עוברים אל אבטחה > Detections and Controls > Google Security Operations > פרטי המופע.מספר לקוח מספר הלקוח של מופע Google SecOps.
במסוף Google SecOps, עוברים אל SIEM Settings > Profile > Organization details.Google Cloud מספר הפרויקט Google Cloud מספר הפרויקט של מופע Google SecOps.
כדי למצוא את מספר הפרויקט במסוף Google SecOps, עוברים אל SIEM Settings > Profile > Organization details.פרטי כניסה פרטי הכניסה של חשבון השירות הם ערך JSON שנדרש לאימות ולגישה ל-Google SecOps Data Pipeline APIs. מקבלים את ערך ה-JSON הזה מקובץ פרטי הכניסה של חשבון השירות של Google.
חשבון השירות צריך להיות באותו פרויקט שבו נמצא מופע Google SecOps, וצריכות להיות לו הרשאות של התפקיד אדמין של Chronicle API (roles/chronicle.admin) או תפקיד בהתאמה אישית עם ההרשאות הנדרשות (ראו דרישות מוקדמות). Google Cloud
למידע על יצירת חשבון שירות והורדת קובץ ה-JSON, אפשר לעיין במאמר יצירה ומחיקה של מפתחות לחשבון שירות.
לחלופין, פריסות של Bindplane Cloud תומכות באיחוד שירותי אימות הזהות של עומסי עבודה (WIF) לצורך אימות. אין תמיכה ב-WIF בפריסות של Bindplane באירוח עצמי. מידע נוסף זמין במאמר חיבור האינטגרציה של Google SecOps לאימות WIF.לוחצים על Connect. אם פרטי החיבור שלכם נכונים והחיבור ל-Google SecOps בוצע בהצלחה, אתם יכולים לצפות לדברים הבאים:
- נפתח חיבור למכונת Google SecOps.
- בפעם הראשונה שמתחברים, הכרטיסייה SecOps Pipelines מופיעה במסוף Bindplane.
- במסוף Bindplane מוצגים נתונים שעברו עיבוד והוגדרו קודם למופע הזה באמצעות ה-API. המערכת ממירה חלק מהמעבדים שהגדרתם באמצעות ה-API למעבדים של Bindplane, ומציגה אחרים בפורמט הגולמי של OpenTelemetry Transformation Language (OTTL). אפשר להשתמש במסוף Bindplane כדי לערוך צינורות ומעבדים שהוגדרו בעבר באמצעות ה-API.
אחרי שיוצרים חיבור בהצלחה למכונת Google SecOps, אפשר להגדיר את עיבוד הנתונים.
הגדרת עיבוד נתונים באמצעות מסוף Bindplane
בקטע הזה מוסבר איך להקצות ולפרוס צינור לעיבוד יומנים חדש ב-Google SecOps באמצעות מסוף Bindplane. אפשר גם להשתמש במסוף Bindplane כדי לנהל צינורות שבעבר הוגדרו באמצעות ה-API.
יצירת פייפליין חדש ב-Google SecOps
צינור נתונים של Google SecOps הוא מאגר שבו אפשר להגדיר מאגר אחד לעיבוד נתונים. כדי ליצור מאגר חדש של צינור נתונים של Google SecOps:
- במסוף Bindplane, לוחצים על הכרטיסייה SecOps Pipelines כדי לפתוח את הדף SecOps Pipelines.
- לוחצים על Create SecOps Pipeline (יצירת צינור SecOps).
מזינים שם של צינור SecOps ותיאור.
לוחצים על יצירה. אפשר לראות את מאגר הצינור החדש בדף SecOps Pipelines.
מגדירים את מקורות הנתונים ואת המעבדים בתוך הקונטיינר הזה.
הגדרה של מאגר לעיבוד נתונים
מאגר לעיבוד נתונים מגדיר את הפידים שיועברו ואת המעבדים שיחולו לפני שהנתונים יגיעו אל היעד.
מגדירים את הזרמים ואת צמתי המעבד בכרטיס ההגדרות של צינור עיבוד הנתונים.
כדי להגדיר מאגר לעיבוד נתונים:
- אם עדיין לא עשיתם זאת, צרו צינור חדש של Google SecOps.
- במסוף Bindplane, לוחצים על הכרטיסייה SecOps Pipelines כדי לפתוח את הדף SecOps Pipelines.
- בוחרים את צינור עיבוד הנתונים של Google SecOps שבו רוצים להגדיר את מאגר התגים החדש לעיבוד נתונים.
בכרטיס ההגדרה Pipeline:
- הוספת מקור נתונים
- מגדירים את צומת העיבוד. כדי להוסיף מעבד באמצעות מסוף Bindplane, אפשר לעיין בפרטים במאמר הגדרת מעבדים.
אחרי שתשלימו את ההגדרות האלה, תוכלו לעיין במאמר הפעלת עיבוד נתונים כדי להתחיל לעבד את הנתונים.
הוספת מקור נתונים
כדי להוסיף שידור:
- בכרטיס ההגדרות Pipeline, לוחצים על add Add Stream (הוספת מקור נתונים) כדי לפתוח את החלון Add Stream (הוספת מקור נתונים).
בחלון הוספת מקור נתונים, מזינים את הפרטים בשדות הבאים:
שדה תיאור סוג היומן בוחרים את סוג היומן של הנתונים שרוצים להוסיף. לדוגמה, CrowdStrike Falcon (CS_EDR).
הערה: סמל אזהרה אזהרה מציין שסוג היומן כבר הוגדר בזרם אחר (בצינור הזה או בצינור אחר במופע Google SecOps שלכם).
כדי להשתמש בסוג יומן שאינו זמין, צריך קודם למחוק אותו מההגדרה של הזרם השני.
כדי לקבל הוראות לגבי איתור הגדרת הסטרימינג שבה מוגדר סוג היומן, אפשר לעיין במאמר סינון הגדרות של צינורות SecOps.שיטת הטמעת הנתונים בוחרים את שיטת ההטמעה שבה רוצים להשתמש כדי להטמיע את הנתונים עבור סוג היומן שנבחר. שיטות ההטמעה האלה הוגדרו בעבר עבור מכונת Google SecOps שלכם.
צריך לבחור אחת מהאפשרויות הבאות:
- כל שיטות ההטמעה: כולל את כל שיטות ההטמעה עבור סוג היומן שנבחר. אם בוחרים באפשרות הזו, אי אפשר להוסיף בהמשך זרמים שמשתמשים בשיטות ספציפיות להעברה של אותו סוג יומן. חריג: אפשר לבחור שיטות ספציפיות אחרות להעברה שלא הוגדרו עבור סוג היומן הזה בזרמים אחרים.
- שיטת הטמעה ספציפית, כמו
Cloud Native Ingestion,Feed,Ingestion APIאוWorkspace Ingestion.
פיד אם בוחרים באפשרות Feedכשיטת ההטמעה, מופיע שדה נוסף עם רשימה של שמות פידים זמינים (שהוגדרו מראש במופע Google SecOps). כדי להשלים את ההגדרה, צריך לבחור את הפיד הרלוונטי. כדי לראות את הפידים הזמינים ולנהל אותם, עוברים אל SIEM Settings > Feeds table (הגדרות SIEM > טבלת פידים).- כל שיטות ההטמעה: כולל את כל שיטות ההטמעה עבור סוג היומן שנבחר. אם בוחרים באפשרות הזו, אי אפשר להוסיף בהמשך זרמים שמשתמשים בשיטות ספציפיות להעברה של אותו סוג יומן. חריג: אפשר לבחור שיטות ספציפיות אחרות להעברה שלא הוגדרו עבור סוג היומן הזה בזרמים אחרים.
לוחצים על הוספת מקור נתונים כדי לשמור את מקור הנתונים החדש.מקור הנתונים החדש מופיע מיד בכרטיס ההגדרה Pipeline. מקור הנתונים מקושר אוטומטית לצומת המעבד וליעד Google SecOps.
סינון הגדרות של צינור עיבוד נתונים ב-SecOps
סרגל החיפוש בדף SecOps Pipelines מאפשר לסנן ולאתר את צינורות הנתונים של Google SecOps (מאגרי נתונים לעיבוד) על סמך רכיבי הגדרה שונים. אפשר לסנן צינורות על ידי חיפוש קריטריונים ספציפיים, כמו סוג יומן, שיטת הטמעה או שם פיד.
כדי לסנן, משתמשים בתחביר הבא:
logType:valueingestionMethod:valuefeed:value
לדוגמה, כדי לזהות הגדרות של זרם שמכילות סוג יומן ספציפי, מזינים logtype: בסרגל החיפוש ובוחרים את סוג היומן מתוך הרשימה שמופיעה.
הגדרת מעבדים
מאגר לעיבוד נתונים מכיל צומת מעבד אחד, שמכיל מעבד אחד או יותר. כל מעבד מטפל בנתונים של הזרם באופן עקבי:
- המעבד הראשון מעבד את הנתונים הגולמיים בסטרימינג.
- הפלט שמתקבל מהמעבד הראשון הופך מיידית לקלט של המעבד הבא ברצף.
- הרצף הזה נמשך לכל המעבדים הבאים, בדיוק לפי הסדר שבו הם מופיעים בחלונית מעבדים, כשהפלט של מעבד אחד הופך לקלט של המעבד הבא.
- מגדירים את צומת המעבד על ידי הוספה, הסרה או שינוי של הרצף של מעבד אחד או יותר.
בטבלה הבאה מפורטים המעבדים:
| סוג המעבד | יכולת |
|---|---|
| מסנן | סינון לפי תנאים |
| מסנן | סינון לפי סטטוס HTTP |
| מסנן | סינון לפי שם מדד |
| מסנן | סינון לפי ביטוי רגולרי |
| מסנן | סינון לפי חומרה |
| מחיקת אזור | צנזור מידע אישי רגיש |
| טרנספורמציה | הוספת שדות |
| טרנספורמציה | Coalesce |
| טרנספורמציה | Concat |
| טרנספורמציה | העתקת שדה |
| טרנספורמציה | מחיקת שדות |
| טרנספורמציה | Marshal |
| טרנספורמציה | העברת שדה |
| טרנספורמציה | ניתוח קובץ CSV |
| טרנספורמציה | ניתוח של JSON |
| טרנספורמציה | ניתוח ערך מפתח |
| טרנספורמציה | ניתוח שדות חומרה |
| טרנספורמציה | ניתוח חותמת הזמן |
| טרנספורמציה | ניתוח באמצעות ביטוי רגולרי |
| טרנספורמציה | ניתוח XML |
| טרנספורמציה | שינוי השם של שדות |
| טרנספורמציה | חותמת זמן של שכתוב |
| טרנספורמציה | פיצול |
| טרנספורמציה | טרנספורמציה |
הוספת מעבד
כדי להוסיף מעבד, פועלים לפי השלבים הבאים:
בכרטיס ההגדרות Pipeline, לוחצים על הצומת Processor כדי לפתוח את החלון Edit Processors. החלון Edit Processors מחולק לחלוניות הבאות, לפי זרימת הנתונים:
- קלט (או נתוני מקור): נתוני יומן עדכניים של סטרימינג (לפני העיבוד)
- הגדרה (או רשימת מעבדים): מעבדים וההגדרות שלהם
- פלט (או תוצאות): נתוני יומן של תוצאות יוצאות מהזמן האחרון (אחרי העיבוד)
אם הצינור הופעל בעבר, המערכת מציגה בחלוניות את נתוני היומן הנכנסים האחרונים (לפני העיבוד) ואת נתוני היומן היוצאים האחרונים (אחרי העיבוד).
לוחצים על הוספת מעבד כדי להציג את רשימת המעבדים. לנוחותכם, רשימת המעבדים מחולקת לקבוצות לפי סוג המעבד. כדי לארגן את הרשימה ולהוסיף חבילות משלכם, בוחרים מעבד אחד או יותר ולוחצים על הוספת חבילות מעבדים חדשות.
ברשימת מעבדי המידע, בוחרים מעבד מידע להוספה.
מגדירים את המעבד לפי הצורך.
לוחצים על שמירה כדי לשמור את הגדרות המעבד בצומת מעבד.
המערכת בודקת מיד את ההגדרה החדשה על ידי עיבוד של מדגם חדש של נתונים מהזרם הנכנס (מהחלונית Input) ומציגה את הנתונים היוצאים שמתקבלים בחלונית Output.
השקת צינור לעיבוד נתונים
אחרי שמסיימים להגדיר את הסטרימינג ואת המעבד, צריך להפעיל את צינור הנתונים כדי להתחיל לעבד את הנתונים:
- לוחצים על הפעלת ההשקה. הפעולה הזו מפעילה מיד את עיבוד הנתונים ומאפשרת לתשתית של Google להתחיל לעבד את הנתונים בהתאם להגדרה שלכם. אם ההשקה תצליח, מספר הגרסה של מאגר התגים לעיבוד נתונים יגדל ויוצג לצד הסמל
nameשל מאגר התגים.
הגדרת עיבוד נתונים באמצעות שיטות API
כחלופה למסוף Bindplane, אפשר להשתמש בשיטות של צינור נתונים ב-Google SecOps כדי לנהל את הנתונים שעברו עיבוד. השיטות האלה כוללות יצירה, עדכון, מחיקה ורישום של צינורות, ושיוך של פידים וסוגי יומנים לצינורות.
כדי להשתמש בדוגמאות שבקטע הזה:
- מחליפים את הפרמטרים שספציפיים ללקוח (לדוגמה, כתובות URL ומזהי פידים) בפרמטרים שמתאימים לסביבה שלכם.
- מוסיפים אימות משלכם. בקטע הזה, אסימוני ה-Bearer מוסתרים באמצעות
******.
הצגת רשימה של כל צינורות הנתונים במכונת Google SecOps ספציפית
הפקודה הבאה מציגה רשימה של כל צינורות הנתונים שקיימים במופע ספציפי של Google SecOps:
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
יצירת צינור בסיסי עם מעבד אחד
כדי ליצור צינור בסיסי עם מעבד טרנספורמציה יחיד שמבצע פעולת upsert לערך של תווית הטמעה מותאמת אישית, ולשייך אליו שלושה מקורות, מבצעים את הפעולות הבאות:
מריצים את הפקודה הבאה:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'מהתשובה, מעתיקים את הערך של השדה
name.מריצים את הפקודה הבאה כדי לשייך שלושה זרמים (סוג יומן, סוג יומן עם מזהה אוסף ופיד) לצינור. שימוש בערך של השדה
nameכערך של{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
יצירת צינור עיבוד נתונים עם שלושה מעבדים
צינור משתמש במעבדים הבאים:
- Filter: מסנן יומנים שתואמים לתנאי מסוים על סמך תוויות ההטמעה.
- שינוי: מוסיף או מעדכן את ערך מרחב השמות.
- השמטה: השמטה של כתובות אימייל ומספרי ביטוח לאומי מנתוני יומן על סמך דפוסי ביטוי רגולרי מותאמים אישית.
כדי ליצור צינור ולשייך אליו שלושה מקורות, מבצעים את הפעולות הבאות:
מריצים את הפקודה הבאה:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'מהתשובה, מעתיקים את הערך של השדה
name.מריצים את הפקודה הבאה כדי לשייך שלושה זרמים (סוג יומן, סוג יומן עם מזהה אוסף ופיד) לצינור. שימוש בערך של השדה
nameכערך של{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
פתרון בעיות
בקטע הזה מפורטות ציפיות הביצועים, ומוצעים פתרונות לבעיות נפוצות בשירות עצמי.
זמן אחזור ומגבלות
אם תגדירו סוכן באמצעות Ingestion API, יכול להיות שתחוו זמני אישור ארוכים יותר בצינורות עיבוד נתונים של Google SecOps עם נפח נמוך.
זמני השהייה הממוצעים יכולים לעלות מ-700 אלפיות השנייה עד 2 שניות. מגדילים את תקופות הזמן הקצובות ואת הזיכרון לפי הצורך. זמן האישור יורד כשקצב העברת הנתונים עולה על 4MB.
אימות ובדיקה
אפשר לראות פרטים על עיבוד הנתונים במסוף Google SecOps:
הצגת כל ההגדרות לעיבוד נתונים
- במסוף Google SecOps, עוברים אל SIEM Settings > Data Processing (הגדרות SIEM > עיבוד נתונים) כדי לראות את כל צינורות הנתונים שהוגדרו.
- בסרגל החיפוש Incoming Data Pipelines, מחפשים את הצינור הרצוי. אפשר לחפש לפי רכיבים, כמו שם הצינור או רכיבים. בתוצאות החיפוש מוצגים המעבדים של הצינור וסיכום של ההגדרה שלו.
- בדף סיכום תהליך המכירה אפשר לבצע את הפעולות הבאות:
- בודקים את הגדרות המעבד.
- העתקת פרטי ההגדרה.
- לוחצים על Open in Bindplane (פתיחה ב-Bindplane) כדי לגשת לצנרת ולנהל אותה ישירות במסוף Bindplane.
צפייה בפידים שהוגדרו
כדי לראות את הפידים שהוגדרו במערכת:
- במסוף Google SecOps, עוברים אל SIEM Settings > Feeds (הגדרות SIEM > פידים). בדף פידים מוצגים כל הפידים שהגדרתם במערכת.
- מעבירים את הסמן מעל כל שורה כדי להציג את התפריט ⋮ עוד, שבו אפשר לראות את פרטי הפיד, לערוך, להשבית או למחוק את הפיד.
- לוחצים על הצגת פרטים כדי להציג את חלון הפרטים.
- לוחצים על Open in Bindplane (פתיחה ב-Bindplane) כדי לפתוח את הגדרות הסטרימינג של הפיד במסוף Bindplane.
הצגת פרטים על עיבוד נתונים עבור סוגי יומנים זמינים
כדי לראות את פרטי עיבוד הנתונים בדף סוגי יומנים זמינים, שבו אפשר לראות את כל סוגי היומנים הזמינים, מבצעים את הפעולות הבאות:
- במסוף Google SecOps, עוברים אל SIEM Settings > Available Log Types. בדף הראשי מוצגים כל סוגי היומנים.
- מעבירים את הסמן מעל כל שורה של פיד כדי להציג את התפריט more_vert עוד. בתפריט הזה אפשר לראות, לערוך, להשבית או למחוק את פרטי הפיד.
- לוחצים על הצגת עיבוד הנתונים כדי לראות את ההגדרה של הפיד.
- לוחצים על Open in Bindplane (פתיחה ב-Bindplane) כדי לפתוח את הגדרות המעבד של המעבד הזה במסוף Bindplane.
הבעיה עדיין לא נפתרה? קבלת תשובות מחברי הקהילה וממומחי Google SecOps.