
Administrar canalizaciones de procesamiento de datos
En este documento, se ayuda a los ingenieros de seguridad a configurar y administrar canalizaciones de procesamiento de datos en Google SecOps para filtrar eventos, transformar campos o ocultar valores sensibles antes de la transferencia. Esta función proporciona un control sólido previo al análisis sobre el proceso de transferencia de datos. Si sigues los métodos recomendados en esta guía, podrás optimizar la compatibilidad de los datos, reducir los costos y proteger la información sensible en Google SecOps.
El procesamiento de datos simplifica la administración de registros a través de las siguientes acciones principales:
- Filtro: Reduce el ruido y los costos incorporando solo los eventos pertinentes.
- Transformar: Modifica los formatos de datos, analiza los campos y enriquece los registros para mejorar la usabilidad.
- Redact: Protege la información sensible enmascarando o quitando los valores sensibles antes del almacenamiento.
En el siguiente diagrama, se ilustra cómo fluyen tus datos a Google SecOps y cómo el sistema los procesa:
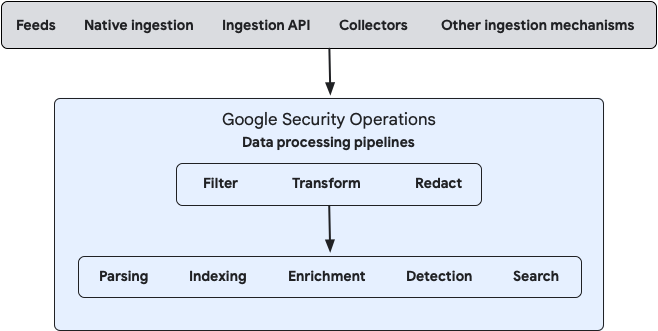
Puedes configurar el procesamiento de datos para los flujos de datos locales y en la nube con la consola de administración de Bindplane o directamente con las APIs públicas de Google SecOps Data Pipeline.
Casos de uso habituales
Entre los casos de uso de ejemplo para el procesamiento de datos, se incluyen los siguientes:
- Quita los pares clave-valor vacíos de los registros sin procesar.
- Oculta datos sensibles.
- Agrega etiquetas de transferencia a partir del contenido de registros sin procesar.
- En entornos de instancias múltiples, aplica etiquetas de transferencia a los datos de registro de transferencia directa para identificar la instancia de la transmisión de origen (comoGoogle Cloud Workspace).
- Filtrar los datos de Palo Alto Cortex por valores de campo
- Reducir los datos de SentinelOne por categoría
- Extrae la información del host de los registros de feeds y de la transferencia directa, y la asigna al campo
ingestion_sourcepara Cloud Monitoring.
Terminología clave
El procesamiento de datos usa los siguientes elementos:
- Flujos: Es un flujo específico de datos, definido por el tipo de registro y la fuente de transferencia (como un feed o una API), que sirve como entrada para una canalización de procesamiento de datos.
- Nodo de procesador: Es un componente dentro de una canalización que contiene uno o más procesadores, como acciones de filtro, transformación o redacción. Estos procesadores manipulan los datos de forma secuencial a medida que pasan por el nodo.
- Destino: Es el extremo de la canalización de procesamiento de datos, que suele ser la instancia de Google SecOps a la que se envían los datos procesados para su análisis y transferencia final.
Antes de comenzar
Antes de comenzar a configurar las canalizaciones de procesamiento de datos, revisa los siguientes requisitos:
- Impacto del analizador y del UDM: Las canalizaciones de procesamiento de datos modifican los datos de registro sin procesar antes de que lleguen a los analizadores de Google SecOps. Estas modificaciones pueden afectar la forma en que los analizadores interpretan los registros y los convierten al formato del modelo de datos unificado (UDM). Antes de activar una canalización para un tipo de feed o registro, verifica que tus reglas de filtrado, transformación o ocultamiento no alteren los datos de forma involuntaria de manera que impidan que los analizadores generen eventos del UDM correctos.
- Compatibilidad con la API: El procesamiento de datos es compatible con las transmisiones basadas en la inserción llamando a la API de Chronicle. Los filtros configurados en el Administrador de procesamiento de datos (DPM) se aplican después de que la API de Ingestión de Chronicle recibe los datos. Por lo tanto, estos filtros no evitan que los clientes alcancen las cuotas y los límites de la API de Ingestion, como los límites de la API de importPushLog, ya que estos límites se evalúan antes de que se aplique el filtrado del DPM. Para administrar de manera eficaz los límites de la API de Ingestion y no superarlos, los clientes deben implementar el filtrado en la fuente de datos en sí, en lugar de depender de los filtros del DPM.
- Visibilidad de los datos: Los datos que se transfieren desde los reenvíadores y Bindplane se etiquetan con un
collectorIDdistinto de los flujos de transferencia directa. Para admitir la visibilidad completa de los registros, debes seleccionar todos los métodos de transferencia cuando consultes fuentes de datos o hacer referencia de forma explícita al objetocollectorIDpertinente cuando interactúes con la API. Configuración de la consola de Bindplane: Si planeas usar la consola de Bindplane para la configuración y la administración, completa los siguientes pasos:
En la consola de Google SecOps, otorga uno de los siguientes roles al usuario o la cuenta de servicio que usarás para configurar la integración de Bindplane:
Un rol personalizado con los siguientes permisos:
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.list
Te recomendamos que uses un rol personalizado con los permisos requeridos especificados.
Para obtener más información, consulta Crea y administra roles personalizados y Configura el control de acceso a las funciones con IAM.
El rol predefinido de administrador de la API de Chronicle
roles/chronicle.adminPara obtener más detalles, consulta Cómo asignar el rol de administrador de IAM del proyecto en un proyecto dedicado.
Instala la consola del servidor de BindPlane. Para SaaS o instalaciones locales, consulta Instala la consola de Bindplane Server. Asegúrate de instalar la versión más reciente de Bindplane (o la versión 1.96.4 o posterior).
En la consola de Bindplane, conecta una instancia de destino de Google SecOps a tu proyecto de Bindplane. Para obtener más información, consulta Conéctate a una instancia de Google SecOps.
Conéctate a una instancia de Google SecOps
Antes de comenzar, confirma que tienes los permisos de administrador del proyecto de Bindplane para acceder a la página Integraciones del proyecto.
La instancia de Google SecOps sirve como destino para el resultado de tus datos.
Para conectarte a una instancia de Google SecOps con la consola de Bindplane Server, haz lo siguiente:
- En la consola de Bindplane Server, haz clic en Menú y selecciona Configuración del proyecto.
- En la página Configuración del proyecto, ve a la tarjeta Integraciones y haz clic en Conectar con Google SecOps para abrir la ventana Editar integración.
Ingresa los detalles de la instancia de destino de Google SecOps.
Esta instancia ingiere los datos procesados (salida del procesamiento de datos) de la siguiente manera:Campo Descripción Región Región de tu instancia de Google SecOps.
Para encontrar la instancia en la consola de Google Cloud , ve a Seguridad > Detecciones y controles > Google Security Operations > Detalles de la instancia.ID de cliente Es el ID de cliente de tu instancia de Google SecOps.
En la consola de Google SecOps, ve a Configuración de SIEM > Perfil > Detalles de la organización.Google Cloud número de proyecto Número de proyecto de tu instancia de Google SecOps.Google Cloud
Para encontrar el número de proyecto en la consola de Google SecOps, ve a Configuración del SIEM > Perfil > Detalles de la organización.Credenciales Las credenciales de la cuenta de servicio son el valor JSON necesario para autenticarse y acceder a las APIs de Google SecOps Data Pipeline. Obtén este valor JSON del archivo de credenciales de la cuenta de servicio de Google.
La cuenta de servicio debe estar ubicada en el mismo proyecto Google Cloud que tu instancia de Google SecOps y requiere privilegios del rol de administrador de la API de Chronicle (roles/chronicle.admin) o un rol personalizado con los permisos requeridos (consulta los requisitos previos).
Para obtener información sobre cómo crear una cuenta de servicio y descargar el archivo JSON, consulta Crea y borra claves de cuentas de servicio.
Como alternativa, las implementaciones de Bindplane Cloud admiten la federación de identidades para cargas de trabajo (WIF) para la autenticación. WIF no se admite en las implementaciones de Bindplane alojadas por el usuario. Para obtener más información, consulta Conecta la integración de Google SecOps con la autenticación de WIF.Haz clic en Conectar. Si los detalles de tu conexión son correctos y te conectas correctamente a Google SecOps, puedes esperar lo siguiente:
- Se abrirá una conexión a la instancia de Google SecOps.
- La primera vez que te conectes, aparecerá la pestaña SecOps Pipelines en la consola de Bindplane.
- La consola de Bindplane muestra los datos procesados que configuraste anteriormente para esta instancia con la API. El sistema convierte algunos de los procesadores que configuraste con la API en procesadores de Bindplane y muestra otros en su formato sin procesar de OpenTelemetry Transformation Language (OTTL). Puedes usar la consola de Bindplane para editar las canalizaciones y los procesadores que se configuraron anteriormente con la API.
Después de crear correctamente una conexión a una instancia de Google SecOps, podrás configurar el procesamiento de datos.
Configura el procesamiento de datos con la consola de Bindplane
En esta sección, se describe cómo aprovisionar e implementar una nueva canalización de procesamiento de registros en Google SecOps con la consola de Bindplane. También puedes usar la consola de Bindplane para administrar las canalizaciones que se configuraron anteriormente con la API.
Crea una nueva canalización de Google SecOps
Una canalización de Google SecOps es un contenedor que te permite configurar un contenedor de procesamiento de datos. Para crear un nuevo contenedor de canalización de Google SecOps, haz lo siguiente:
- En la consola de Bindplane, haz clic en la pestaña Canalizaciones de SecOps para abrir la página Canalizaciones de SecOps.
- Haz clic en Create SecOps Pipeline.
Ingresa un nombre de la canalización de SecOps y una descripción.
Haz clic en Crear. Puedes ver el nuevo contenedor de canalización en la página SecOps Pipelines.
Configura los flujos y procesadores de contenedores de procesamiento de datos dentro de este contenedor.
Configura un contenedor de procesamiento de datos
Un contenedor de procesamiento de datos define los flujos que se deben transferir y los procesadores que se deben aplicar antes de que los datos lleguen al destino.
Configura los nodos de transmisión y procesador en la tarjeta de configuración de la canalización.
Para configurar un contenedor de procesamiento de datos, haz lo siguiente:
- Si aún no lo hiciste, crea una nueva canalización de Google SecOps.
- En la consola de Bindplane, haz clic en la pestaña Canalizaciones de SecOps para abrir la página Canalizaciones de SecOps.
- Selecciona la canalización de Google SecOps en la que deseas configurar el nuevo contenedor de procesamiento de datos.
En la tarjeta de configuración Pipeline, haz lo siguiente:
- Agrega un flujo.
- Configura el nodo del procesador. Para agregar un procesador con la consola de Bindplane, consulta Configura procesadores para obtener más detalles.
Una vez que se completen estos parámetros de configuración, consulta Lanza el procesamiento de datos para comenzar a procesar los datos.
Cómo agregar una transmisión
Para agregar una transmisión, haz lo siguiente:
- En la tarjeta de configuración Pipeline, haz clic en agregar Agregar flujo para abrir la ventana Agregar flujo.
En la ventana Add Stream, ingresa los detalles de estos campos:
Campo Descripción Tipo de registro Selecciona el tipo de registro de los datos que se transferirán. Por ejemplo, CrowdStrike Falcon (CS_EDR)
Nota: El ícono de advertencia Advertencia indica que el tipo de registro ya está configurado en otro flujo (ya sea en esta canalización o en otra canalización de tu instancia de Google SecOps).
Para usar un tipo de registro no disponible, primero debes borrarlo de la otra configuración de transmisión.
Si deseas obtener instrucciones para encontrar la configuración de transmisión en la que se configura el tipo de registro, consulta Cómo filtrar la configuración de la canalización de SecOps.Método de transferencia Selecciona el método de transferencia que se usará para transferir los datos del tipo de registro seleccionado. Estos métodos de transferencia ya se definieron para tu instancia de Google SecOps.
Debes seleccionar una de las siguientes opciones:
- All Ingestion Methods: Incluye todos los métodos de transferencia para el tipo de registro seleccionado. Cuando seleccionas esta opción, se evita que agregues transmisiones posteriores que usen métodos de transferencia específicos para ese mismo tipo de registro. Excepción: Puedes seleccionar otros métodos de transferencia específicos no configurados para este tipo de registro en otros flujos.
- Specific método de transferencia, como
Cloud Native Ingestion,Feed,Ingestion APIoWorkspace Ingestion.
Feed Si seleccionas Feedcomo método de transferencia, aparecerá un campo posterior con una lista de los nombres de feeds disponibles (preconfigurados en tu instancia de Google SecOps) para el tipo de registro seleccionado. Debes seleccionar el feed pertinente para completar la configuración. Para ver y administrar los feeds disponibles, ve a Configuración de SIEM > Tabla de feeds.- All Ingestion Methods: Incluye todos los métodos de transferencia para el tipo de registro seleccionado. Cuando seleccionas esta opción, se evita que agregues transmisiones posteriores que usen métodos de transferencia específicos para ese mismo tipo de registro. Excepción: Puedes seleccionar otros métodos de transferencia específicos no configurados para este tipo de registro en otros flujos.
Haz clic en Agregar flujo de datos para guardar el nuevo flujo de datos.El nuevo flujo de datos aparecerá de inmediato en la tarjeta de configuración de Canalización. La transmisión se conecta automáticamente al nodo del procesador y al destino de Google SecOps.
Filtra la configuración de la canalización de SecOps
La barra de búsqueda de la página SecOps Pipelines te permite filtrar y ubicar tus canalizaciones de Google SecOps (contenedores de procesamiento de datos) según varios elementos de configuración. Puedes filtrar las canalizaciones buscando criterios específicos, como el tipo de registro, el método de transferencia o el nombre del feed.
Usa la siguiente sintaxis para filtrar:
logType:valueingestionMethod:valuefeed:value
Por ejemplo, para identificar las configuraciones de transmisión que contienen un tipo de registro específico, ingresa logtype: en la barra de búsqueda y selecciona el tipo de registro de la lista resultante.
Configura procesadores
Un contenedor de procesamiento de datos tiene un nodo de procesador, que contiene uno o más procesadores. Cada procesador manipula los datos de la transmisión de forma secuencial:
- El primer procesador procesa los datos de transmisión sin procesar.
- El resultado del primer procesador se convierte de inmediato en la entrada del siguiente procesador de la secuencia.
- Esta secuencia continúa para todos los procesadores posteriores, en el orden exacto en que aparecen en el panel Procesadores, y el resultado de uno se convierte en la entrada del siguiente.
- Configura el nodo del procesador agregando, quitando o cambiando la secuencia de uno o más procesadores.
En la siguiente tabla, se enumeran los procesadores:
| Tipo de procesador | Función |
|---|---|
| Filtro | Filtrar por condición |
| Filtro | Filtrar por estado HTTP |
| Filtro | Filtrar por nombre de métrica |
| Filtro | Filtrar por regex |
| Filtro | Filtrar por gravedad |
| Ocultamiento | Oculta datos sensibles |
| Transformar | Agregar campos |
| Transformar | Coalesce |
| Transformar | Concat |
| Transformar | Copiar campo |
| Transformar | Borra campos |
| Transformar | Marshal |
| Transformar | Campo de movimiento |
| Transformar | Analizar CSV |
| Transformar | Analizar JSON |
| Transformar | Analiza el valor de la clave |
| Transformar | Analiza los campos de gravedad |
| Transformar | Analizar marca de tiempo |
| Transformar | Analizar con regex |
| Transformar | Cómo analizar XML |
| Transformar | Cambiar el nombre de los campos |
| Transformar | Marca de tiempo de reescritura |
| Transformar | Dividir |
| Transformar | Transformar |
Cómo agregar un procesador
Para agregar un procesador, sigue estos pasos:
En la tarjeta de configuración de Pipeline, haz clic en el nodo Procesador para abrir la ventana Editar procesadores. La ventana Edit Processors se divide en estos paneles, organizados por flujo de datos:
- Entrada (o datos de origen): Datos de registro de transmisión entrantes recientes (antes del procesamiento)
- Configuración (o lista de procesadores): Procesadores y sus configuraciones
- Salida (o resultados): Datos de registro de resultados salientes recientes (después del procesamiento)
Si la canalización se lanzó anteriormente, el sistema muestra los datos de registro entrantes recientes (antes del procesamiento) y los datos de registro salientes recientes (después del procesamiento) en los paneles.
Haz clic en Agregar procesador para mostrar la lista de procesadores. Para tu comodidad, la lista de procesadores se agrupa por tipo de procesador. Para organizar la lista y agregar tus propios paquetes, selecciona uno o más procesadores y haz clic en Agregar paquetes de procesadores nuevos.
En la lista de procesadores, selecciona un procesador para agregar.
Configura el procesador según sea necesario.
Haz clic en Guardar para guardar la configuración del procesador en el nodo Procesador.
El sistema prueba de inmediato la nueva configuración procesando una muestra reciente de los datos del flujo entrante (desde el panel Input) y muestra los datos salientes resultantes en el panel Output.
Lanza la canalización de procesamiento de datos
Una vez que se completen las configuraciones de la transmisión y del procesador, debes lanzar la canalización para comenzar a procesar los datos:
- Haz clic en Iniciar lanzamiento. Esto activa de inmediato el procesamiento de datos y permite que la infraestructura de Google comience a procesar datos según tu configuración. Si la implementación se realiza correctamente, el número de versión del contenedor de procesamiento de datos se incrementará y se mostrará junto al
namedel contenedor.
Configura el procesamiento de datos con métodos de la API
Como alternativa a la consola de Bindplane, puedes usar los métodos de la canalización de datos de Google SecOps para administrar tus datos procesados. Estos métodos de canalización de datos incluyen la creación, actualización, eliminación y enumeración de canalizaciones, y la asociación de feeds y tipos de registros con canalizaciones.
Para usar los ejemplos de esta sección, haz lo siguiente:
- Reemplaza los parámetros específicos del cliente (por ejemplo, URLs y IDs de feeds) por parámetros que se adapten a tu propio entorno.
- Inserta tu propia autenticación. En esta sección, los tokens de portador se ocultan con
******.
Enumera todas las canalizaciones en una instancia específica de Google SecOps
El siguiente comando enumera todas las canalizaciones que existen en una instancia específica de Google SecOps:
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
Crea una canalización básica con un procesador
Para crear una canalización básica con un solo procesador de transformación que inserte o actualice el valor de una etiqueta de transferencia personalizada y asocie tres fuentes a ella, haz lo siguiente:
Ejecuta el comando siguiente:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'En la respuesta, copia el valor del campo
name.Ejecuta el siguiente comando para asociar tres transmisiones (tipo de registro, tipo de registro con ID de recopilador y feed) a la canalización. Usa el valor del campo
namecomo el valor de{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Crea una canalización con tres procesadores
Una canalización usa los siguientes procesadores:
- Filtro: Filtra los registros que coinciden con una condición basada en las etiquetas de transferencia.
- Transform: Inserta o actualiza el valor del espacio de nombres.
- Ocultación: Oculta direcciones de correo electrónico y números de seguridad social de los datos de registro según patrones de regex personalizados.
Para crear una canalización y asociarle tres fuentes, haz lo siguiente:
Ejecuta el comando siguiente:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'En la respuesta, copia el valor del campo
name.Ejecuta el siguiente comando para asociar tres transmisiones (tipo de registro, tipo de registro con ID de recopilador y feed) a la canalización. Usa el valor del campo
namecomo el valor de{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Soluciona problemas
En esta sección, se describen las expectativas de rendimiento y se proporcionan soluciones de autoservicio para problemas comunes.
Latencia y límites
Si configuras un agente con la API de Ingestion, es posible que experimentes tiempos de confirmación más largos para las canalizaciones de Google SecOps de bajo volumen.
Los promedios de latencia pueden aumentar de 700 ms a 2 segundos. Aumenta los períodos de espera y la memoria según sea necesario. El tiempo de confirmación disminuye cuando el rendimiento de datos supera los 4 MB.
Validación y prueba
Puedes ver los detalles del procesamiento de datos en la consola de Google SecOps:
Ver todos los parámetros de configuración del procesamiento de datos
- En la consola de Google SecOps, ve a Configuración del SIEM > Procesamiento de datos, donde puedes ver todas las canalizaciones configuradas.
- En la barra de búsqueda Incoming Data Pipelines, busca cualquier canalización que hayas creado. Puedes buscar por elementos, como el nombre de la canalización o los componentes. En los resultados de la búsqueda, se muestran los procesadores de la canalización y un resumen de su configuración.
- En el resumen de la canalización, puedes realizar cualquiera de las siguientes acciones:
- Revisa la configuración del procesador.
- Copiar los detalles de configuración
- Haz clic en Abrir en Bindplane para acceder a la canalización y administrarla directamente en la consola de Bindplane.
Ver los feeds configurados
Para ver los feeds configurados en tu sistema, haz lo siguiente:
- En la consola de Google SecOps, ve a Configuración de SIEM > Feeds. En la página Feeds, se muestran todos los feeds que configuraste en tu sistema.
- Mantén el puntero sobre cada fila para mostrar el menú ⋮ Más, en el que puedes ver los detalles del feed, editarlo, inhabilitarlo o borrarlo.
- Haz clic en Ver detalles para ver la ventana de detalles.
- Haz clic en Abrir en Bindplane para abrir la configuración de la transmisión de ese feed en la consola de Bindplane.
Consulta los detalles del procesamiento de datos para los tipos de registros disponibles
Para ver los detalles del procesamiento de datos en la página Available Log Types, donde puedes ver todos los tipos de registros disponibles, haz lo siguiente:
- En la consola de Google SecOps, ve a SIEM Settings > Available Log Types. En la página principal, se muestran todos los tipos de registros.
- Mantén el puntero sobre cada fila del feed para mostrar el menú more_vert Más. Este menú te permite ver, editar, inhabilitar o borrar los detalles del feed.
- Haz clic en Ver procesamiento de datos para ver la configuración del feed.
- Haz clic en Abrir en Bindplane para abrir la configuración del procesador en la consola de Bindplane.
¿Necesitas más ayuda? Obtén respuestas de miembros de la comunidad y profesionales de Google SecOps.