
本頁內容適用於 Apigee 和 Apigee Hybrid。
查看
Apigee Edge 說明文件。

本頁說明如何使用作業異常資訊主頁,查看及調查偵測到的異常狀況。您可以調查異常狀況,並視需要採取適當行動。您也可以建立異常狀況快訊,在日後發生類似事件時收到通知。
偵測到的異常狀況包含下列資訊:
- 導致異常的指標,例如 Proxy 延遲或 HTTP 錯誤代碼。
- 異常狀況的嚴重程度。嚴重程度可能為輕微、中等或嚴重,取決於模型的可信度。如果信心水準較低,代表嚴重程度較輕微;如果信心水準較高,代表嚴重程度較嚴重。
查看異常狀況
Apigee 使用者介面中的「作業異常狀況」資訊主頁,是您取得偵測到的作業異常狀況資訊的主要來源。資訊主頁會顯示最近的異常狀況清單。
如要開啟作業異常狀況資訊主頁,請按照下列步驟操作:
在 Google Cloud 控制台,前往「Analytics」>「Operations anomalies」(作業異常) 頁面。
- 切換至要監控的機構。
系統會顯示作業異常狀況資訊主頁。
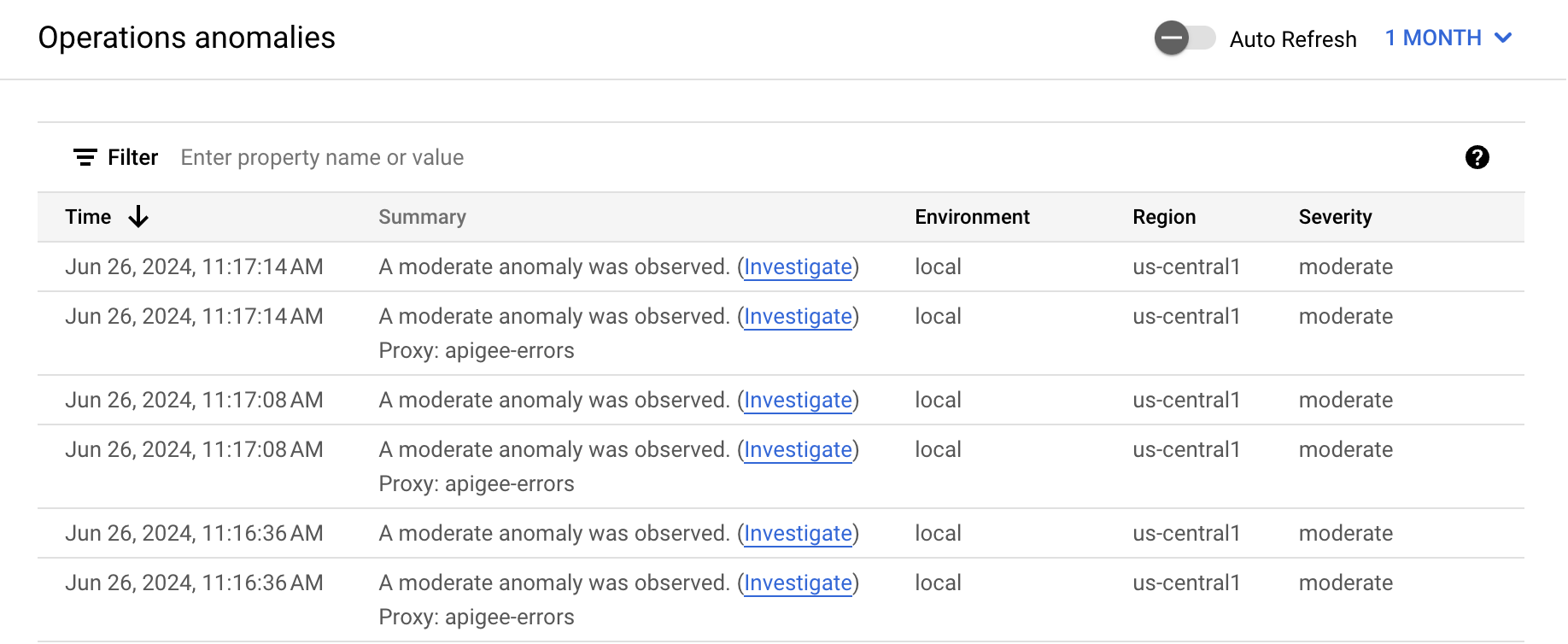
根據預設,資訊主頁會顯示前一小時發生的異常狀況。 如果該時間範圍內未偵測到任何異常狀況,資訊主頁就不會顯示任何資料列。您可以從資訊主頁右上角的時間範圍選單中,選取較大的時間範圍。
表格中的每一列都對應一項偵測到的異常狀況,並顯示下列資訊:
- 異常狀況的日期和時間。
- 異常狀況的簡要摘要,包括發生異常狀況的 Proxy。
- 發生異常狀況的環境。
- 發生異常的區域。
- 異常事件的嚴重程度:輕微、中等或嚴重。嚴重程度是根據統計量 (P 值) 判斷事件偶然發生的機率 (事件越不可能發生,嚴重程度就越高)。
調查異常狀況
在作業異常狀況資訊主頁中發現異常狀況時,您可以在 API 監控資訊主頁中進一步調查。按一下異常狀況「摘要」欄中的「調查」,開啟 API 監控調查資訊主頁。
資訊主頁會顯示近期 API 資料的圖表和表格,提供異常狀況發生時 API 的具體資訊。範例:調查故障代碼異常
假設您正在查看作業異常狀況資訊主頁,並發現下列異常狀況:

按一下「Summary」(摘要) 欄中的「Investigate」(調查),即可查看下方的 API Monitoring Investigate 資訊主頁。
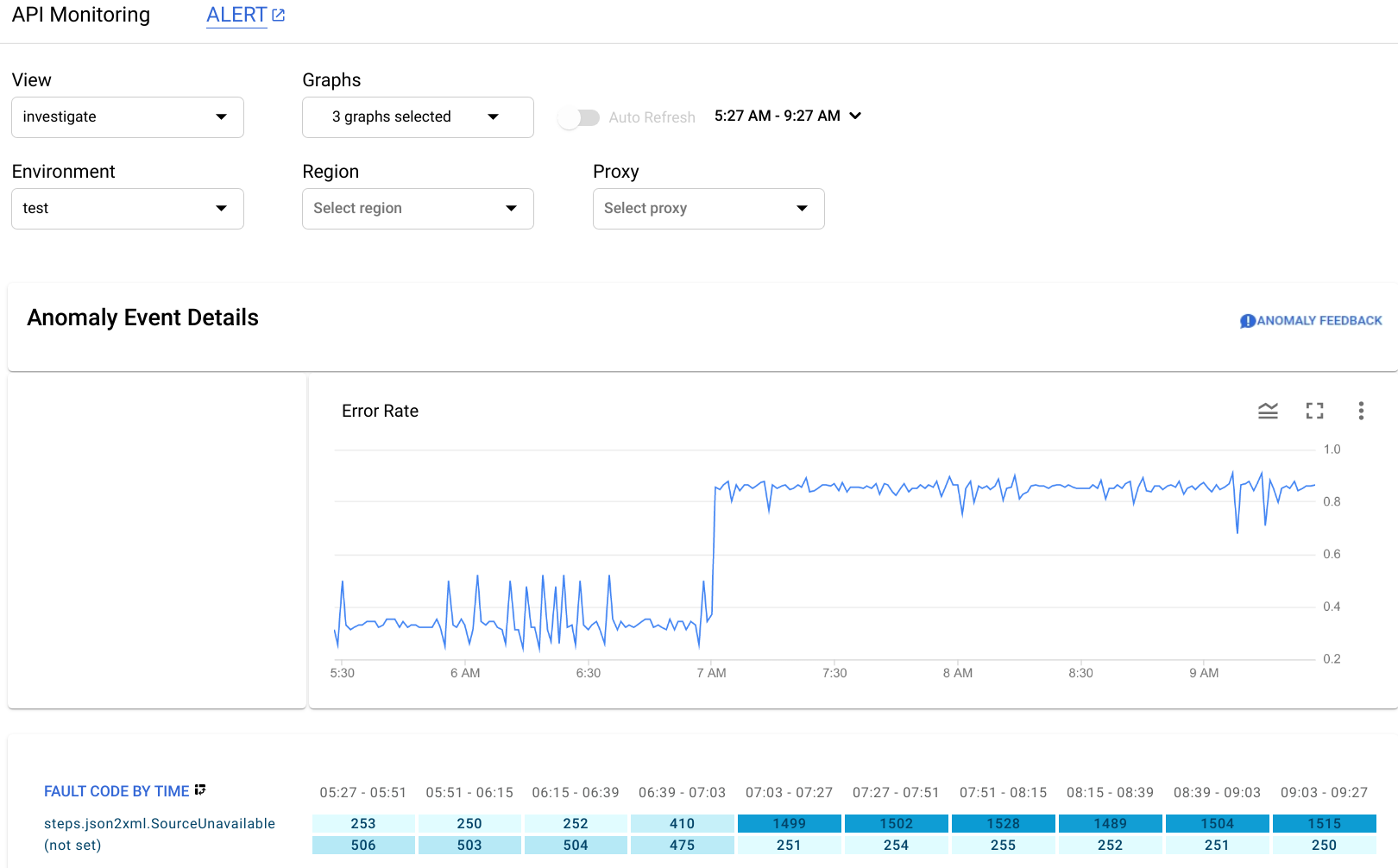
「異常事件詳細資料」窗格會顯示錯誤率時間軸。 圖表顯示,異常狀況發生在上午 7 點後,當時錯誤率從不到 0.4 升至超過 0.8。
時間軸圖表中的錯誤率包含所有故障代碼的錯誤。 如要查看不同故障代碼的錯誤明細,請查看時間軸下方顯示的「依時間劃分的故障代碼」圖表。
注意:如果目前未顯示「Fault Code by Time」圖表,請在「Graphs」選單中選取「Fault Code」,即可顯示該圖表:
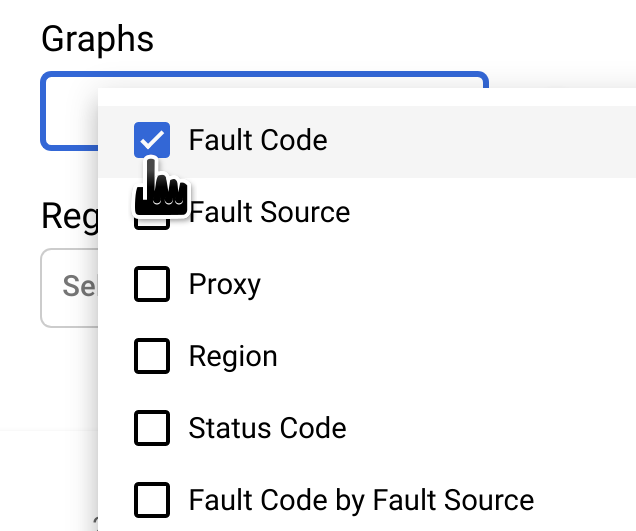
「依時間顯示故障代碼」圖表中以圓圈標示的資料欄,對應的時間間隔包含異常時間。
注意:圖表顯示的資料與異常狀況回報時間略有差異是正常現象。

您發現間隔 07:03 - 07:27 內有 1499 個回應的錯誤代碼為 steps.json2xml.SourceUnavailable (JSON 至 XML 政策訊息來源無法使用時傳回的錯誤代碼)。這是觸發異常狀況的故障代碼。
相較之下,前四個間隔的平均回應數約為 291,因此跳到 1499 絕對是不尋常的事件。
如要進一步瞭解 SourceUnavailable 錯誤訊息,請參閱「
JSON to XML policy runtime error troubleshooting」。
此時,您可以透過下列幾種方式,繼續調查異常狀況的原因:
如要深入瞭解異常狀況發生時的故障代碼資料,請在「故障代碼 (依時間)」圖表中,按一下異常狀況的儲存格。
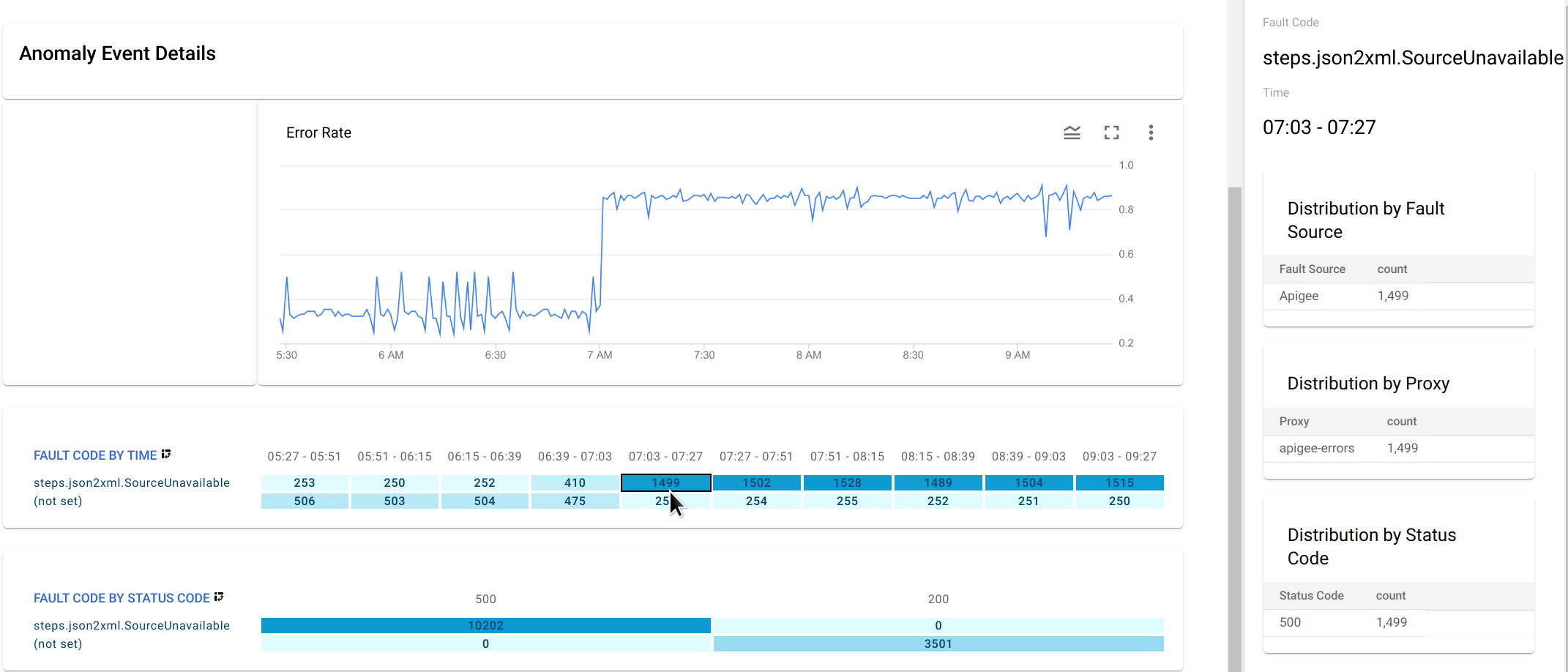
右側窗格會顯示按錯誤來源、Proxy 和狀態碼分類的分配表。
steps.json2xml.SourceUnavailable在本例中,由於所有錯誤代碼都來自相同的錯誤來源、Proxy 和狀態碼,因此表格不會提供任何額外資訊。但在其他情況下,分配資料表可以指出異常狀況的位置和原因。
- 建立異常狀況快訊並設定通知。完成這項操作後,如果日後發生類似事件,作業異常情況就會傳送訊息給您。