
Gérer les pipelines de traitement des données
Ce document aide les ingénieurs en sécurité à configurer et à gérer des pipelines de traitement des données dans Google SecOps pour filtrer les événements, transformer les champs ou masquer les valeurs sensibles avant l'ingestion. Cette fonctionnalité offre un contrôle robuste et pré-analytique sur le processus d'ingestion de données. En suivant les méthodes recommandées dans ce guide, vous pouvez optimiser la compatibilité des données, réduire les coûts et protéger les informations sensibles dans Google SecOps.
Le traitement des données simplifie la gestion des journaux grâce aux actions principales suivantes :
- Filtrer : réduisez le bruit et les coûts en n'ingérant que les événements pertinents.
- Transformer : modifiez les formats de données, analysez les champs et enrichissez les journaux pour une meilleure facilité d'utilisation.
- Redact : protégez les informations sensibles en masquant ou en supprimant les valeurs sensibles avant le stockage.
Le schéma suivant illustre le flux de vos données vers Google SecOps et la façon dont le système les traite :
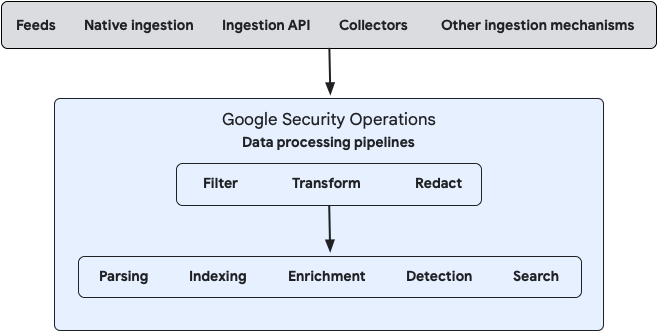
Vous pouvez configurer le traitement des flux de données sur site et dans le cloud à l'aide de la console de gestion Bindplane ou en utilisant directement les API Google SecOps Data Pipeline publiques.
Cas d'utilisation courants
Voici quelques exemples de cas d'utilisation du traitement des données :
- Supprimez les paires clé-valeur vides des journaux bruts.
- Masquer les données sensibles.
- Ajoutez des libellés d'ingestion à partir du contenu brut des journaux.
- Dans les environnements multi-instances, appliquez des libellés d'ingestion aux données de journaux à ingestion directe pour identifier l'instance de flux source (par exemple,Google Cloud Workspace).
- Filtrez les données Palo Alto Cortex par valeurs de champ.
- Réduisez les données SentinelOne par catégorie.
- Extrayez les informations sur l'hôte à partir des flux et des journaux d'ingestion directe, puis mappez-les au champ
ingestion_sourcepour Cloud Monitoring.
Terminologie clé
Le traitement des données utilise les éléments suivants :
- Flux : flux de données spécifique, défini par le type de journal et la source d'ingestion (comme un flux ou une API), qui sert d'entrée à un pipeline de traitement des données.
- Nœud de processeur : composant d'un pipeline contenant un ou plusieurs processeurs, tels que des actions de filtrage, de transformation ou de masquage. Ces processeurs manipulent les données de manière séquentielle à mesure qu'elles traversent le nœud.
- Destination : point de terminaison du pipeline de traitement des données, généralement l'instance Google SecOps où les données traitées sont envoyées pour ingestion et analyse finales.
Avant de commencer
Avant de commencer à configurer des pipelines de traitement des données, vérifiez les exigences suivantes :
- Impact du parseur et de l'UDM : les pipelines de traitement des données modifient les données de journaux brutes avant qu'elles n'atteignent les parseurs Google SecOps. Ces modifications peuvent avoir une incidence sur la façon dont les analyseurs interprètent les journaux et les convertissent au format Unified Data Model (UDM). Avant d'activer un pipeline pour un type de flux ou de journal, vérifiez que vos règles de filtrage, de transformation ou de masquage ne modifient pas involontairement les données de manière à empêcher les analyseurs de générer des événements UDM corrects.
- Compatibilité avec les API : le traitement des données est compatible avec les flux basés sur le push en appelant l'API Chronicle. Les filtres configurés dans le Gestionnaire du traitement des données (DPM) sont appliqués une fois que les données ont été reçues par l'API Chronicle Ingestion. Par conséquent, ces filtres n'empêchent pas les clients d'atteindre les quotas et limites de l'API Ingestion, tels que les limites de l'API importPushLog, car ces limites sont évaluées avant le filtrage DPM. Pour gérer efficacement les limites de l'API Ingestion et les respecter, les clients doivent implémenter le filtrage au niveau de la source de données elle-même, plutôt que de s'appuyer sur les filtres DPM.
- Visibilité des données : les données ingérées à partir des transmetteurs et de Bindplane sont taguées avec un
collectorIDdistinct des flux d'ingestion directe. Pour bénéficier d'une visibilité complète des journaux, vous devez sélectionner toutes les méthodes d'ingestion lorsque vous interrogez des sources de données ou référencer explicitement lecollectorIDconcerné lorsque vous interagissez avec l'API. Configuration de la console Bindplane : si vous prévoyez d'utiliser la console Bindplane pour la configuration et la gestion, procédez comme suit :
Dans la console Google SecOps, accordez l'un des rôles suivants à l'utilisateur ou au compte de service que vous utiliserez pour configurer l'intégration Bindplane :
Un rôle personnalisé avec les autorisations suivantes :
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.list
Nous vous recommandons d'utiliser un rôle personnalisé avec les autorisations requises spécifiées.
Pour en savoir plus, consultez Créer et gérer des rôles personnalisés et Configurer le contrôle des accès aux fonctionnalités à l'aide d'IAM.
Le rôle prédéfini
roles/chronicle.admind'administrateur de l'API ChroniclePour en savoir plus, consultez Attribuer le rôle d'administrateur IAM de projet dans un projet dédié.
Installez la console Bindplane Server. Pour SaaS ou sur site, consultez Installer la console Bindplane Server. Assurez-vous d'installer la dernière version de Bindplane (ou la version 1.96.4 ou ultérieure).
Dans la console Bindplane, associez une instance de destination Google SecOps à votre projet Bindplane. Pour en savoir plus, consultez Se connecter à une instance Google SecOps.
Se connecter à une instance Google SecOps
Avant de commencer, vérifiez que vous disposez des autorisations d'administrateur de projet Bindplane pour accéder à la page Intégrations de projet.
L'instance Google SecOps sert de destination pour les données générées.
Pour vous connecter à une instance Google SecOps à l'aide de la console Bindplane Server, procédez comme suit :
- Dans la console Bindplane Server, cliquez sur Menu, puis sélectionnez Project Settings (Paramètres du projet).
- Sur la page Paramètres du projet, accédez à la fiche Intégrations, puis cliquez sur Associer à Google SecOps pour ouvrir la fenêtre Modifier l'intégration.
Saisissez les informations relatives à l'instance de destination Google SecOps.
Cette instance ingère les données traitées (résultat du traitement de vos données), comme suit :Champ Description Région Région de votre instance Google SecOps.
Pour trouver l'instance dans la console Google Cloud , accédez à Sécurité > Détections et contrôles > Google Security Operations > Détails de l'instance.Numéro client Numéro client de votre instance Google SecOps.
Dans la console Google SecOps, accédez à Paramètres du SIEM > Profil > Détails de l'organisation.Google Cloud : numéro du projet Numéro de projetGoogle Cloud de votre instance Google SecOps.
Pour trouver le numéro de projet dans la console Google SecOps, accédez à Paramètres du SIEM > Profil > Détails de l'organisation.Identifiants Les identifiants de compte de service sont la valeur JSON requise pour s'authentifier et accéder aux API Google SecOps Data Pipeline. Récupérez cette valeur JSON à partir du fichier d'identifiants du compte de service Google.
Le compte de service doit se trouver dans le même projet Google Cloud que votre instance Google SecOps et nécessite les droits du rôle Administrateur de l'API Chronicle (roles/chronicle.admin) ou un rôle personnalisé avec les autorisations requises (voir Conditions préalables).
Pour savoir comment créer un compte de service et télécharger le fichier JSON, consultez Créer et supprimer des clés de compte de service.
Vous pouvez également utiliser la fédération d'identité de charge de travail (WIF) pour l'authentification dans les déploiements Bindplane Cloud. L'identité de charge de travail n'est pas compatible avec les déploiements Bindplane auto-hébergés. Pour en savoir plus, consultez Connecter l'intégration Google SecOps à l'authentification WIF.Cliquez sur Se connecter. Si vos informations de connexion sont correctes et que vous parvenez à vous connecter à Google SecOps, vous pouvez vous attendre à ce qui suit :
- Une connexion à l'instance Google SecOps s'ouvre.
- La première fois que vous vous connectez, l'onglet Pipelines SecOps s'affiche dans la console Bindplane.
- La console Bindplane affiche toutes les données traitées que vous avez précédemment configurées pour cette instance à l'aide de l'API. Le système convertit certains processeurs que vous avez configurés à l'aide de l'API en processeurs Bindplane, et affiche les autres dans leur format brut OpenTelemetry Transformation Language (OTTL). Vous pouvez utiliser la console Bindplane pour modifier les pipelines et les processeurs précédemment configurés à l'aide de l'API.
Une fois que vous avez créé une connexion à une instance Google SecOps, vous pouvez configurer le traitement des données.
Configurer le traitement des données à l'aide de la console Bindplane
Cette section explique comment provisionner et déployer un nouveau pipeline de traitement des journaux dans Google SecOps à l'aide de la console Bindplane. Vous pouvez également utiliser la console Bindplane pour gérer les pipelines précédemment configurés à l'aide de l'API.
Créer un pipeline Google SecOps
Un pipeline Google SecOps est un conteneur qui vous permet de configurer un conteneur de traitement des données. Pour créer un conteneur de pipeline Google SecOps :
- Dans la console Bindplane, cliquez sur l'onglet Pipelines SecOps pour ouvrir la page Pipelines SecOps.
- Cliquez sur Create SecOps Pipeline (Créer un pipeline SecOps).
Saisissez un Nom du pipeline SecOps et une Description.
Cliquez sur Créer. Vous pouvez voir le nouveau conteneur de pipeline sur la page Pipelines SecOps.
Configurez les flux et les processeurs de conteneur de traitement des données dans ce conteneur.
Configurer un conteneur de traitement des données
Un conteneur de traitement des données définit les flux à ingérer et les processeurs à appliquer avant que les données n'atteignent la destination.
Configurez les flux et les nœuds de processeur sur la fiche de configuration du pipeline.
Pour configurer un conteneur de traitement des données :
- Si ce n'est pas déjà fait, créez un pipeline Google SecOps.
- Dans la console Bindplane, cliquez sur l'onglet Pipelines SecOps pour ouvrir la page Pipelines SecOps.
- Sélectionnez le pipeline Google SecOps dans lequel vous souhaitez configurer le nouveau conteneur de traitement des données.
Dans la fiche de configuration Pipeline :
- Ajoutez un flux.
- Configurez le nœud de processeur. Pour ajouter un processeur à l'aide de la console Bindplane, consultez Configurer des processeurs pour en savoir plus.
Une fois ces configurations terminées, consultez Déployer le traitement des données pour commencer à traiter les données.
Ajouter un flux
Pour ajouter un flux :
- Dans la fiche de configuration Pipeline, cliquez sur Ajouter Ajouter un flux pour ouvrir la fenêtre Ajouter un flux.
Dans la fenêtre Ajouter un flux, saisissez les informations suivantes :
Champ Description Type de journal Sélectionnez le type de journal des données à ingérer. Exemple : CrowdStrike Falcon (CS_EDR)
Remarque : Une icône d'avertissement Avertissement indique que le type de journal est déjà configuré dans un autre flux (dans ce pipeline ou dans un autre pipeline de votre instance Google SecOps).
Pour utiliser un type de journal indisponible, vous devez d'abord le supprimer de l'autre configuration de flux.
Pour savoir comment trouver la configuration du flux dans laquelle le type de journal est configuré, consultez Filtrer les configurations de pipeline SecOps.Méthode d'ingestion Sélectionnez la méthode d'ingestion à utiliser pour ingérer les données du type de journal sélectionné. Ces méthodes d'ingestion ont été définies précédemment pour votre instance Google SecOps.
Vous devez sélectionner l'une des options suivantes :
- Toutes les méthodes d'ingestion : inclut toutes les méthodes d'ingestion pour le type de journal sélectionné. Lorsque vous sélectionnez cette option, vous ne pouvez pas ajouter d'autres flux qui utilisent des méthodes d'ingestion spécifiques pour le même type de journal. Exception : Vous pouvez sélectionner d'autres méthodes d'ingestion spécifiques non configurées pour ce type de journal dans d'autres flux.
- Méthode d'ingestion spécifique, telle que
Cloud Native Ingestion,Feed,Ingestion APIouWorkspace Ingestion.
Flux Si vous sélectionnez Feedcomme méthode d'ingestion, un champ s'affiche avec la liste des noms de flux disponibles (préconfigurés dans votre instance Google SecOps) pour le type de journal sélectionné. Vous devez sélectionner le flux concerné pour terminer la configuration. Pour afficher et gérer vos flux disponibles, accédez à Paramètres du SIEM > Tableau "Flux".- Toutes les méthodes d'ingestion : inclut toutes les méthodes d'ingestion pour le type de journal sélectionné. Lorsque vous sélectionnez cette option, vous ne pouvez pas ajouter d'autres flux qui utilisent des méthodes d'ingestion spécifiques pour le même type de journal. Exception : Vous pouvez sélectionner d'autres méthodes d'ingestion spécifiques non configurées pour ce type de journal dans d'autres flux.
Cliquez sur Ajouter un flux pour enregistrer le nouveau flux de données.Il s'affiche immédiatement sur la fiche de configuration Pipeline. Le flux est automatiquement connecté au nœud de processeur et à la destination Google SecOps.
Filtrer les configurations de pipeline SecOps
La barre de recherche de la page Pipelines SecOps vous permet de filtrer et de localiser vos pipelines Google SecOps (conteneurs de traitement des données) en fonction de plusieurs éléments de configuration. Vous pouvez filtrer les pipelines en recherchant des critères spécifiques, tels que le type de journal, la méthode d'ingestion ou le nom du flux.
Utilisez la syntaxe suivante pour filtrer :
logType:valueingestionMethod:valuefeed:value
Par exemple, pour identifier les configurations de flux qui contiennent un type de journal spécifique, saisissez logtype: dans la barre de recherche, puis sélectionnez le type de journal dans la liste qui s'affiche.
Configurer les processeurs
Un conteneur de traitement des données comporte un nœud de processeur, qui contient un ou plusieurs processeurs. Chaque processeur manipule les données du flux de manière séquentielle :
- Le premier processeur traite les données brutes du flux.
- La sortie du premier processeur devient immédiatement l'entrée du processeur suivant de la séquence.
- Cette séquence se poursuit pour tous les processeurs suivants, dans l'ordre exact dans lequel ils apparaissent dans le volet Processeurs, la sortie de l'un devenant l'entrée du suivant.
- Configurez le nœud de processeur en ajoutant, en supprimant ou en modifiant la séquence d'un ou de plusieurs processeurs.
Le tableau suivant répertorie les processeurs :
| Type de processeur | Capacité |
|---|---|
| Filtre | Filtrer par condition |
| Filtre | Filtrer par code d'état HTTP |
| Filtre | Filtrer par nom de métrique |
| Filtre | Filtrer par expression régulière |
| Filtre | Filtrer par gravité |
| Occultation | Masquer les données sensibles |
| Transformer | Ajouter des champs |
| Transformer | Coalesce |
| Transformer | Concat |
| Transformer | Copier le champ |
| Transformer | Supprimer des champs |
| Transformer | Marshal |
| Transformer | Déplacer un champ |
| Transformer | Analyser un fichier CSV |
| Transformer | Analyser le code JSON |
| Transformer | Analyser la clé-valeur |
| Transformer | Analyser les champs de gravité |
| Transformer | Analyse du code temporel |
| Transformer | Analyser avec une expression régulière |
| Transformer | Parse XML |
| Transformer | renommer les champs ; |
| Transformer | Réécrire le code temporel |
| Transformer | Diviser |
| Transformer | Transformer |
Ajouter un processeur
Pour ajouter un processeur, procédez comme suit :
Dans la fiche de configuration Pipeline, cliquez sur le nœud Processeur pour ouvrir la fenêtre Modifier les processeurs. La fenêtre Modifier les processeurs est divisée en plusieurs volets, organisés par flux de données :
- Entrée (ou données sources) : données de journaux de flux entrants récents (avant traitement)
- Configuration (ou liste de processeurs) : processeurs et leurs configurations
- Sortie (ou résultats) : données de journaux de résultats sortants récents (après traitement)
Si le pipeline a déjà été déployé, le système affiche les données de journaux entrantes récentes (avant traitement) et les données de journaux sortantes récentes (après traitement) dans les volets.
Cliquez sur Ajouter un processeur pour afficher la liste des processeurs. Pour plus de commodité, la liste des processeurs est regroupée par type de processeur. Pour organiser la liste et ajouter vos propres groupes, sélectionnez un ou plusieurs processeurs, puis cliquez sur Ajouter des groupes de processeurs.
Dans la liste des processeurs, sélectionnez un processeur à ajouter.
Configurez le processeur selon vos besoins.
Cliquez sur Enregistrer pour enregistrer la configuration du processeur dans le nœud Processeur.
Le système teste immédiatement la nouvelle configuration en traitant un nouvel échantillon des données du flux entrant (à partir du volet Entrée) et affiche les données sortantes résultantes dans le volet Sortie.
Déployer un pipeline de traitement de données
Une fois les configurations du flux et du processeur terminées, vous devez déployer le pipeline pour commencer à traiter les données :
- Cliquez sur Lancer le déploiement. Cela active immédiatement le traitement des données et permet à l'infrastructure de Google de commencer à traiter les données en fonction de votre configuration. Si le déploiement réussit, le numéro de version du conteneur de traitement des données est incrémenté et affiché à côté de l'icône
namedu conteneur.
Configurer le traitement des données à l'aide des méthodes de l'API
Au lieu de la console Bindplane, vous pouvez utiliser les méthodes de pipeline de données Google SecOps pour gérer vos données traitées. Ces méthodes de pipeline de données incluent la création, la mise à jour, la suppression et la liste des pipelines, ainsi que l'association de flux et de types de journaux aux pipelines.
Pour utiliser les exemples de cette section, procédez comme suit :
- Remplacez les paramètres spécifiques aux clients (par exemple, les URL et les ID de flux) par des paramètres adaptés à votre propre environnement.
- Insérez votre propre authentification. Dans cette section, les jetons du porteur sont masqués par
******.
Lister tous les pipelines d'une instance Google SecOps spécifique
La commande suivante liste tous les pipelines qui existent dans une instance Google SecOps spécifique :
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
Créer un pipeline de base avec un processeur
Pour créer un pipeline de base avec un seul processeur de transformation qui insère ou met à jour la valeur d'un libellé d'ingestion personnalisé et y associe trois sources, procédez comme suit :
Exécutez la commande suivante :
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'Dans la réponse, copiez la valeur du champ
name.Exécutez la commande suivante pour associer trois flux (type de journal, type de journal avec ID de collecteur et flux) au pipeline. Utilisez la valeur du champ
namecomme valeur{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Créer un pipeline avec trois processeurs
Un pipeline utilise les processeurs suivants :
- Filtrer : filtre les journaux qui correspondent à une condition basée sur les libellés d'ingestion.
- Transformer : insère ou met à jour la valeur de l'espace de noms.
- Masquage : masque les adresses e-mail et les numéros de sécurité sociale des données de journaux en fonction de modèles d'expressions régulières personnalisés.
Pour créer un pipeline et y associer trois sources, procédez comme suit :
Exécutez la commande suivante :
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'Dans la réponse, copiez la valeur du champ
name.Exécutez la commande suivante pour associer trois flux (type de journal, type de journal avec ID de collecteur et flux) au pipeline. Utilisez la valeur du champ
namecomme valeur{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Dépannage
Cette section décrit les performances attendues et fournit des solutions en libre-service pour les problèmes courants.
Latence et limites
Si vous configurez un agent à l'aide de l'API Ingestion, les délais d'accusé de réception peuvent être plus longs pour les pipelines Google SecOps à faible volume.
Les latences moyennes peuvent passer de 700 ms à 2 secondes. Augmentez les délais d'attente et la mémoire si nécessaire. Le temps d'accusé de réception diminue lorsque le débit de données dépasse 4 Mo.
Validation et test
Vous pouvez afficher les détails du traitement des données dans la console Google SecOps :
Afficher toutes les configurations de traitement des données
- Dans la console Google SecOps, accédez à Paramètres SIEM > Traitement des données, où vous pouvez afficher tous vos pipelines configurés.
- Dans la barre de recherche Pipelines de données entrants, recherchez un pipeline que vous avez créé. Vous pouvez effectuer une recherche par éléments, tels que le nom du pipeline ou les composants. Les résultats de recherche affichent les processeurs du pipeline et un récapitulatif de sa configuration.
- À partir du récapitulatif du pipeline, vous pouvez effectuer l'une des actions suivantes :
- Vérifiez les configurations du processeur.
- Copiez les détails de la configuration.
- Cliquez sur Ouvrir dans Bindplane pour accéder au pipeline et le gérer directement dans la console Bindplane.
Afficher les flux configurés
Pour afficher les flux configurés dans votre système, procédez comme suit :
- Dans la console Google SecOps, accédez à Paramètres du SIEM > Flux. La page Flux affiche tous les flux que vous avez configurés dans votre système.
- Pointez sur chaque ligne pour afficher le menu ⋮ Plus, dans lequel vous pouvez afficher les détails du flux, le modifier, le désactiver ou le supprimer.
- Cliquez sur Afficher les détails pour ouvrir la fenêtre d'informations.
- Cliquez sur Ouvrir dans Bindplane pour ouvrir la configuration du flux correspondant dans la console Bindplane.
Afficher les détails du traitement des données pour les types de journaux disponibles
Pour afficher les détails du traitement des données sur la page Types de journaux disponibles, où vous pouvez voir tous les types de journaux disponibles, procédez comme suit :
- Dans la console Google SecOps, accédez à Paramètres du SIEM > Types de journaux disponibles. La page principale affiche tous vos types de journaux.
- Pointez sur chaque ligne du flux pour afficher le menu more_vert Plus. Ce menu vous permet d'afficher, de modifier, de désactiver ou de supprimer les détails du flux.
- Cliquez sur Afficher le traitement des données pour afficher la configuration du flux.
- Cliquez sur Ouvrir dans Bindplane pour ouvrir la configuration du processeur dans la console Bindplane.
Vous avez encore besoin d'aide ? Obtenez des réponses de membres de la communauté et de professionnels Google SecOps.