
Gestisci le pipeline di elaborazione dei dati
Questo documento aiuta gli ingegneri della sicurezza a configurare e gestire le pipeline di elaborazione dei dati in Google SecOps per filtrare gli eventi, trasformare i campi o oscurare i valori sensibili prima dell'importazione. Questa funzionalità fornisce un controllo robusto e pre-parsing sul processo di importazione dati. Seguendo i metodi consigliati in questa guida, puoi ottimizzare la compatibilità dei dati, ridurre i costi e proteggere le informazioni sensibili in Google SecOps.
L'elaborazione dei dati semplifica la gestione dei log tramite le seguenti azioni principali:
- Filtro: riduci il rumore e i costi inserendo solo gli eventi pertinenti.
- Trasforma: modifica i formati dei dati, analizza i campi e arricchisci i log per una migliore usabilità.
- Redact: proteggi le informazioni sensibili mascherando o rimuovendo i valori sensibili prima dell'archiviazione.
Il seguente diagramma illustra il flusso dei dati in Google SecOps e la modalità di elaborazione dei dati da parte del sistema:
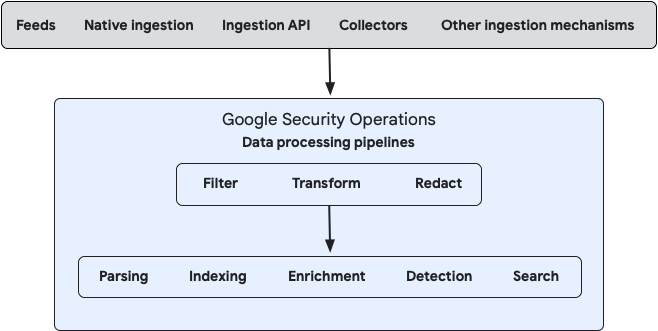
Puoi configurare l'elaborazione dei dati per i flussi di dati on-premise e cloud utilizzando la console di gestione Bindplane o le API Google SecOps Data Pipeline pubbliche.
Casi d'uso comuni
Ecco alcuni casi d'uso per il trattamento dei dati:
- Rimuovi le coppie chiave-valore vuote dai log non elaborati.
- Oscura i dati sensibili.
- Aggiungi etichette di importazione dai contenuti dei log non elaborati.
- Negli ambienti multi-istanza, applica le etichette di importazione ai dati dei log di importazione diretta per identificare l'istanza del flusso di origine (ad esempio Google Cloud Workspace).
- Filtra i dati di Palo Alto Cortex in base ai valori dei campi.
- Ridurre i dati di SentinelOne per categoria.
- Estrai le informazioni sull'host dai feed e dai log di importazione diretta e mappale al campo
ingestion_sourceper Cloud Monitoring.
Terminologia chiave
Il trattamento dei dati utilizza i seguenti elementi:
- Stream: un flusso specifico di dati, definito dal tipo di log e dall'origine di importazione (ad esempio un feed o un'API), che funge da input per una pipeline di elaborazione dei dati.
- Nodo del processore: un componente all'interno di una pipeline che contiene uno o più processori, ad esempio azioni di filtro, trasformazione o oscuramento. Questi processori manipolano i dati in sequenza mentre passano attraverso il nodo.
- Destinazione: l'endpoint della pipeline di elaborazione dei dati, in genere l'istanza Google SecOps in cui i dati elaborati vengono inviati per l'importazione e l'analisi finali.
Prima di iniziare
Prima di iniziare a configurare le pipeline di elaborazione dei dati, esamina i seguenti requisiti:
- Impatto di parser e UDM: le pipeline di elaborazione dei dati modificano i dati dei log non elaborati prima che raggiungano i parser di Google SecOps. Queste modifiche possono influire sul modo in cui i parser interpretano i log e li convertono nel formato Unified Data Model (UDM). Prima di attivare una pipeline per un tipo di feed o log, verifica che le regole di filtro, trasformazione o oscuramento non alterino involontariamente i dati in modo da impedire ai parser di generare eventi UDM corretti.
- Supporto API: l'elaborazione dei dati è supportata per i flussi basati su push chiamando l'API Chronicle. I filtri configurati in Data Processing Manager (DPM) vengono applicati dopo che i dati sono stati ricevuti dall'API Chronicle Ingestion. Di conseguenza, questi filtri non impediscono ai clienti di raggiungere le quote e i limiti dell'API Ingestion, ad esempio i limiti dell'API importPushLog, perché questi limiti vengono valutati prima che venga applicato il filtro DPM. Per gestire in modo efficace i limiti dell'API Ingestion e rispettarli, i clienti devono implementare il filtro nella stessa origine dati anziché fare affidamento sui filtri DPM.
- Visibilità dei dati: i dati importati dai forwarder e da Bindplane vengono taggati con un
collectorIDdistinto rispetto ai flussi di importazione diretta. Per supportare la visibilità completa dei log, devi selezionare tutti i metodi di importazione quando esegui query sulle origini dati o fare riferimento esplicito alcollectorIDpertinente quando interagisci con l'API. Configurazione della console Bindplane: se prevedi di utilizzare la console Bindplane per la configurazione e la gestione, completa i seguenti passaggi:
Nella console Google SecOps, concedi uno dei seguenti ruoli all'utente o al account di servizio che utilizzerai per configurare l'integrazione di Bindplane:
Un ruolo personalizzato con le seguenti autorizzazioni:
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.list
Ti consigliamo di utilizzare un ruolo personalizzato con le autorizzazioni richieste specificate.
Per saperne di più, consulta Creare e gestire ruoli personalizzati e Configurare il controllo dell'accesso alle funzionalità utilizzando IAM.
Il ruolo predefinito Chronicle API Admin
roles/chronicle.admin.Per maggiori dettagli, vedi Assegnare il ruolo Amministratore IAM progetto in un progetto dedicato.
Installa la console Bindplane Server. Per SaaS o on-premise, vedi Installare la console Bindplane Server. Assicurati di installare l'ultima versione di Bindplane (o Bindplane versione 1.96.4 o successive).
Nella console Bindplane, collega un'istanza di destinazione Google SecOps al tuo progetto Bindplane. Per maggiori dettagli, vedi Connettersi a un'istanza Google SecOps.
Connettiti a un'istanza Google SecOps
Prima di iniziare, verifica di disporre delle autorizzazioni di amministratore del progetto di Bindplane per accedere alla pagina Integrazioni progetto.
L'istanza Google SecOps funge da destinazione per l'output dei dati.
Per connetterti a un'istanza Google SecOps utilizzando la console Bindplane Server:
- Nella console di Bindplane Server, fai clic su Menu e seleziona Impostazioni progetto.
- Nella pagina Impostazioni progetto, vai alla scheda Integrazioni e fai clic su Connetti a Google SecOps per aprire la finestra Modifica integrazione.
Inserisci i dettagli dell'istanza di destinazione Google SecOps.
Questa istanza importa i dati elaborati (output dell'elaborazione dei dati) nel seguente modo:Campo Descrizione Regione Regione dell'istanza Google SecOps.
Per trovare l'istanza nella console Google Cloud , vai a Sicurezza > Rilevamenti e controlli > Google Security Operations > Dettagli istanza.ID cliente ID cliente della tua istanza Google SecOps.
Nella console Google SecOps, vai a Impostazioni SIEM > Profilo > Dettagli organizzazione.Google Cloud numero di progetto Numero di progettoGoogle Cloud dell'istanza Google SecOps.
Per trovare il numero di progetto nella console Google SecOps, vai a Impostazioni SIEM > Profilo > Dettagli organizzazione.Credenziali Le credenziali del service account sono il valore JSON necessario per l'autenticazione e l'accesso alle API Google SecOps Data Pipeline. Ottieni questo valore JSON dal file delle credenziali dell'account di servizio Google.
Il service account deve trovarsi nello stesso progetto Google Cloud della tua istanza di Google SecOps e richiede i privilegi del ruolo Amministratore API Chronicle (roles/chronicle.admin) o un ruolo personalizzato con le autorizzazioni richieste (vedi Prerequisiti).
Per informazioni su come creare un service account e scaricare il file JSON, vedi Creare ed eliminare le chiavi del service account.
In alternativa, i deployment di Bindplane Cloud supportano la federazione delle identità per i workload (WIF) per l'autenticazione. WIF non è supportato nelle implementazioni di Bindplane self-hosted. Per saperne di più, consulta Connettere l'integrazione di Google SecOps con l'autenticazione WIF.Fai clic su Connetti. Se i dettagli della connessione sono corretti e la connessione a Google SecOps va a buon fine, puoi aspettarti quanto segue:
- Si apre una connessione all'istanza Google SecOps.
- La prima volta che ti connetti, viene visualizzata la scheda Pipeline SecOps nella console Bindplane.
- La console Bindplane mostra tutti i dati elaborati che hai configurato in precedenza per questa istanza utilizzando l'API. Il sistema converte alcuni processori configurati utilizzando l'API in processori Bindplane e mostra gli altri nel formato OTTL (OpenTelemetry Transformation Language) non elaborato. Puoi utilizzare la console Bindplane per modificare le pipeline e i processori configurati in precedenza utilizzando l'API.
Dopo aver creato correttamente una connessione a un'istanza Google SecOps, puoi configurare l'elaborazione dei dati.
Configura l'elaborazione dei dati utilizzando la console Bindplane
Questa sezione descrive come eseguire il provisioning e il deployment di una nuova pipeline di elaborazione dei log in Google SecOps utilizzando la console Bindplane. Puoi anche utilizzare la console Bindplane per gestire le pipeline precedentemente configurate utilizzando l'API.
Crea una nuova pipeline Google SecOps
Una pipeline Google SecOps è un contenitore in cui configurare un contenitore di elaborazione dei dati. Per creare un nuovo container della pipeline Google SecOps:
- Nella console Bindplane, fai clic sulla scheda Pipeline SecOps per aprire la pagina Pipeline SecOps.
- Fai clic su Crea pipeline SecOps.
Inserisci un nome della pipeline SecOps e una descrizione.
Fai clic su Crea. Puoi visualizzare il nuovo container della pipeline nella pagina Pipeline SecOps.
Configura gli stream e i processori del contenitore di elaborazione dei dati all'interno di questo contenitore.
Configura un contenitore di trattamento dati
Un contenitore di elaborazione dei dati definisce gli stream da importare e i processori da applicare prima che i dati raggiungano la destinazione.
Configura i nodi di stream e processore nella scheda di configurazione della pipeline.
Per configurare un container di trattamento dati:
- Se non l'hai ancora fatto, crea una nuova pipeline Google SecOps.
- Nella console Bindplane, fai clic sulla scheda Pipeline SecOps per aprire la pagina Pipeline SecOps.
- Seleziona la pipeline Google SecOps in cui vuoi configurare il nuovo contenitore di trattamento dei dati.
Nella scheda di configurazione Pipeline:
- Aggiungi uno stream.
- Configura il nodo processore. Per aggiungere un processore utilizzando la console Bindplane, consulta Configurare i processori per maggiori dettagli.
Una volta completate queste configurazioni, consulta Implementare il trattamento dei dati per iniziare a trattare i dati.
Aggiungere uno stream
Per aggiungere uno stream:
- Nella scheda di configurazione Pipeline, fai clic su Aggiungi Aggiungi stream per aprire la finestra Aggiungi stream.
Nella finestra Aggiungi stream, inserisci i dettagli per questi campi:
Campo Descrizione Tipo di log Seleziona il tipo di log dei dati da importare. Ad esempio, CrowdStrike Falcon (CS_EDR).
Nota: un' icona di avviso Avviso indica che il tipo di log è già configurato in un altro stream (in questa pipeline o in un'altra pipeline nell'istanza di Google SecOps).
Per utilizzare un tipo di log non disponibile, devi prima eliminarlo dall'altra configurazione dello stream.
Per istruzioni su come trovare la configurazione dello stream in cui è configurato il tipo di log, vedi Filtrare le configurazioni della pipeline SecOps.Metodo di importazione Seleziona il metodo di importazione da utilizzare per importare i dati per il tipo di log selezionato. Questi metodi di importazione sono stati definiti in precedenza per la tua istanza Google SecOps.
Devi selezionare una delle seguenti opzioni:
- Tutti i metodi di importazione: include tutti i metodi di importazione per il tipo di log selezionato. Se selezioni questa opzione, non potrai aggiungere stream successivi che utilizzano metodi di importazione specifici per lo stesso tipo di log. Eccezione: puoi selezionare altri metodi di importazione specifici non configurati per questo tipo di log in altri stream.
- Metodo di importazione specifico, ad esempio
Cloud Native Ingestion,Feed,Ingestion APIoWorkspace Ingestion.
Feed Se selezioni Feedcome metodo di importazione, viene visualizzato un campo successivo con un elenco di nomi dei feed disponibili (preconfigurati nell'istanza di Google SecOps) per il tipo di log selezionato. Per completare la configurazione, devi selezionare il feed pertinente. Per visualizzare e gestire i feed disponibili, vai a Impostazioni SIEM > Tabella dei feed.- Tutti i metodi di importazione: include tutti i metodi di importazione per il tipo di log selezionato. Se selezioni questa opzione, non potrai aggiungere stream successivi che utilizzano metodi di importazione specifici per lo stesso tipo di log. Eccezione: puoi selezionare altri metodi di importazione specifici non configurati per questo tipo di log in altri stream.
Fai clic su Aggiungi stream per salvare il nuovo stream.Il nuovo stream di dati viene visualizzato immediatamente nella scheda di configurazione Pipeline. Lo stream viene collegato automaticamente al nodo processore e alla destinazione Google SecOps.
Filtra le configurazioni della pipeline SecOps
La barra di ricerca nella pagina Pipeline SecOps ti consente di filtrare e individuare le pipeline Google SecOps (contenitori di elaborazione dei dati) in base a più elementi di configurazione. Puoi filtrare le pipeline cercando criteri specifici, come tipo di log, metodo di importazione o nome del feed.
Utilizza la seguente sintassi per filtrare:
logType:valueingestionMethod:valuefeed:value
Ad esempio, per identificare le configurazioni di stream che contengono un tipo di log specifico, nella barra di ricerca inserisci logtype: e seleziona il tipo di log dall'elenco dei risultati.
Configurare i processori
Un contenitore di elaborazione dei dati ha un nodo di elaborazione, che contiene uno o più processori. Ogni processore manipola i dati dello stream in sequenza:
- Il primo processore elabora i dati di flusso non elaborati.
- L'output risultante dal primo processore diventa immediatamente l'input per il processore successivo nella sequenza.
- Questa sequenza continua per tutti i processori successivi, nell'ordine esatto in cui vengono visualizzati nel riquadro Processori, con l'output di uno che diventa l'input del successivo.
- Configura il nodo del processore aggiungendo, rimuovendo o modificando la sequenza di uno o più processori.
La tabella seguente elenca i processori:
| Tipo di processore | Capacità |
|---|---|
| Filtro | Filtra per condizione |
| Filtro | Filtra per stato HTTP |
| Filtro | Filtra per nome metrica |
| Filtro | Filtra per espressione regolare |
| Filtro | Filtra per gravità |
| Oscuramento | Oscurare i dati sensibili |
| Trasformazione | Aggiungi campi |
| Trasformazione | Coalesce |
| Trasformazione | Concat |
| Trasformazione | Copia campo |
| Trasformazione | Eliminare campi |
| Trasformazione | Marshal |
| Trasformazione | Sposta campo |
| Trasformazione | Analizza CSV |
| Trasformazione | Analizza JSON |
| Trasformazione | Analizza valore chiave |
| Trasformazione | Analizza i campi di gravità |
| Trasformazione | Analizza timestamp |
| Trasformazione | Analizza con regex |
| Trasformazione | Analizza XML |
| Trasformazione | Rinomina i campi |
| Trasformazione | Riscrivi timestamp |
| Trasformazione | Suddividi |
| Trasformazione | Trasformazione |
Aggiungere un processore
Per aggiungere un responsabile del trattamento:
Nella scheda di configurazione Pipeline, fai clic sul nodo Processore per aprire la finestra Modifica processori. La finestra Modifica responsabili del trattamento è suddivisa in questi riquadri, disposti in base al flusso di dati:
- Input (o dati di origine): dati di log del flusso in entrata recenti (prima dell'elaborazione)
- Configurazione (o elenco dei processori): i processori e le relative configurazioni
- Output (o risultati): dati di log dei risultati in uscita recenti (dopo l'elaborazione)
Se la pipeline è stata implementata in precedenza, il sistema mostra i dati di log in entrata recenti (prima dell'elaborazione) e i dati di log in uscita recenti (dopo l'elaborazione) nei riquadri.
Fai clic su Aggiungi processore per visualizzare l'elenco dei processori. Per comodità, l'elenco dei processori è raggruppato per tipo di processore. Per organizzare l'elenco e aggiungere i tuoi bundle, seleziona uno o più processori e fai clic su Aggiungi nuovi bundle di processori.
Nell'elenco dei processori, seleziona un processore da aggiungere.
Configura il processore in base alle esigenze.
Fai clic su Salva per salvare la configurazione del processore nel nodo Processore.
Il sistema testa immediatamente la nuova configurazione elaborando un nuovo campione dei dati di flusso in entrata (dal riquadro Input) e visualizza i dati in uscita risultanti nel riquadro Output.
Implementa la pipeline di elaborazione dei dati
Una volta completate le configurazioni del flusso e del processore, devi implementare la pipeline per iniziare a elaborare i dati:
- Fai clic su Avvia implementazione. In questo modo, l'elaborazione dei dati viene attivata immediatamente e l'infrastruttura di Google inizia a elaborare i dati in base alla configurazione. Se l'implementazione va a buon fine, il numero di versione del contenitore di elaborazione dei dati viene incrementato e visualizzato accanto al
namedel contenitore.
Configurare l'elaborazione dei dati utilizzando i metodi API
In alternativa alla console Bindplane, puoi utilizzare i metodi della pipeline di dati di Google SecOps per gestire i dati elaborati. Questi metodi della pipeline di dati includono la creazione, l'aggiornamento, l'eliminazione e l'elenco delle pipeline, nonché l'associazione di feed e tipi di log alle pipeline.
Per utilizzare gli esempi in questa sezione:
- Sostituisci i parametri specifici del cliente (ad esempio URL e ID feed) con parametri adatti al tuo ambiente.
- Inserisci la tua autenticazione. In questa sezione, i token di autenticazione vengono oscurati con
******.
Elenca tutte le pipeline in una specifica istanza Google SecOps
Il comando seguente elenca tutte le pipeline esistenti in una specifica istanza Google SecOps:
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
Crea una pipeline di base con un processore
Per creare una pipeline di base con un singolo processore di trasformazione che esegue l'upsert del valore per un'etichetta di importazione personalizzata e associarvi tre origini:
Esegui questo comando:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'Dalla risposta, copia il valore del campo
name.Esegui il comando seguente per associare tre stream (tipo di log, tipo di log con ID collector e feed) alla pipeline. Utilizza il valore del campo
namecome valore{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Crea una pipeline con tre processori
Una pipeline utilizza i seguenti processori:
- Filtro: filtra i log che corrispondono a una condizione basata sulle etichette di importazione.
- Trasforma: esegue l'upsert del valore dello spazio dei nomi.
- Oscuramento: oscura gli indirizzi email e i codici fiscali dai dati dei log in base a pattern regex personalizzati.
Per creare una pipeline e associarvi tre origini:
Esegui questo comando:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'Dalla risposta, copia il valore del campo
name.Esegui il comando seguente per associare tre stream (tipo di log, tipo di log con ID collector e feed) alla pipeline. Utilizza il valore del campo
namecome valore{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Risoluzione dei problemi
Questa sezione descrive le aspettative di rendimento e fornisce soluzioni self-service per i problemi comuni.
Latenza e limiti
Se configuri un agente utilizzando l'API Ingestion, potresti riscontrare tempi di riconoscimento più lunghi per le pipeline Google SecOps a basso volume.
Le medie della latenza possono aumentare da 700 ms fino a 2 secondi. Aumenta i periodi di timeout e la memoria in base alle necessità. Il tempo di riconoscimento diminuisce quando il throughput dei dati supera i 4 MB.
Convalida e test
Puoi visualizzare i dettagli del trattamento dei dati dalla console Google SecOps:
Visualizza tutte le configurazioni del trattamento dei dati
- Nella console Google SecOps, vai a Impostazioni SIEM > Trattamento dati, dove puoi visualizzare tutte le pipeline configurate.
- Nella barra di ricerca Pipeline di dati in entrata, cerca le pipeline che hai creato. Puoi eseguire la ricerca per elementi, ad esempio nome pipeline o componenti. I risultati di ricerca mostrano i processori della pipeline e un riepilogo della sua configurazione.
- Dal riepilogo della pipeline, puoi eseguire una delle seguenti azioni:
- Rivedi le configurazioni del processore.
- Copia i dettagli di configurazione.
- Fai clic su Apri in Bindplane per accedere alla pipeline e gestirla direttamente nella console Bindplane.
Visualizza i feed configurati
Per visualizzare i feed configurati nel tuo sistema:
- Nella console Google SecOps, vai a Impostazioni SIEM > Feed. La pagina Feed mostra tutti i feed che hai configurato nel tuo sistema.
- Tieni il puntatore sopra ogni riga per visualizzare il menu ⋮ Altro, in cui puoi visualizzare i dettagli del feed, modificarlo, disattivarlo o eliminarlo.
- Fai clic su Visualizza dettagli per visualizzare la finestra dei dettagli.
- Fai clic su Apri in Bindplane per aprire la configurazione dello stream per quel feed nella console Bindplane.
Visualizzare i dettagli del trattamento dati per i tipi di log disponibili
Per visualizzare i dettagli del trattamento dati nella pagina Tipi di log disponibili, dove puoi visualizzare tutti i tipi di log disponibili, procedi nel seguente modo:
- Nella console Google SecOps, vai a Impostazioni SIEM > Tipi di log disponibili. La pagina principale mostra tutti i tipi di log.
- Tieni il puntatore sopra ogni riga del feed per visualizzare il menu more_vert Altro. Questo menu ti consente di visualizzare, modificare, disattivare o eliminare i dettagli del feed.
- Fai clic su Visualizza trattamento dei dati per visualizzare la configurazione del feed.
- Fai clic su Apri in Bindplane per aprire la configurazione del processore nella console Bindplane.
Hai bisogno di ulteriore assistenza? Ricevi risposte dai membri della community e dai professionisti di Google SecOps.