
データ処理パイプラインを管理する
このドキュメントは、セキュリティ エンジニアが Google SecOps でデータ処理パイプラインを設定して管理し、取り込み前にイベントのフィルタリング、フィールドの変換、機密値の編集を行う際に役立ちます。この機能により、データの取り込みプロセスを堅牢に事前解析して制御できます。このガイドで推奨されている方法に従うことで、データの互換性を最適化し、コストを削減し、Google SecOps 内の機密情報を保護できます。
データ処理では、次のコア アクションを通じてログ管理が簡素化されます。
- フィルタ: 関連するイベントのみを取り込むことで、ノイズとコストを削減します。
- 変換: データの形式を変更し、フィールドを解析して、ログを拡充し、使いやすさを向上させます。
- Redact: 保存前に機密値をマスキングまたは削除して、機密情報を保護します。
次の図は、データが Google SecOps に流れ込む仕組みと、システムがそのデータを処理する方法を示しています。
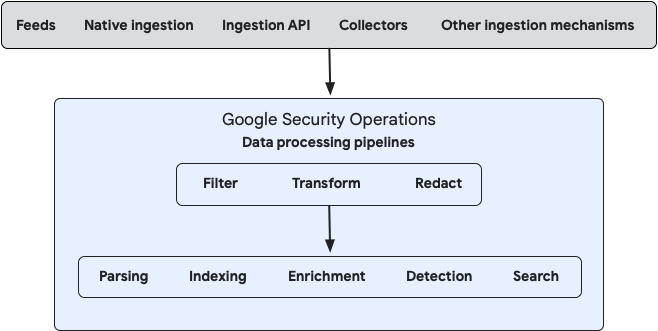
オンプレミスとクラウドの両方のデータ ストリームのデータ処理は、Bindplane 管理コンソールを使用するか、パブリック Google SecOps Data Pipeline API を直接使用して構成できます。
一般的なユースケース
データ処理のユースケースの例を次に示します。
- 未加工のログから空の Key-Value ペアを削除します。
- 機密データを秘匿化する
- 未加工のログコンテンツから取り込みラベルを追加します。
- マルチインスタンス環境では、直接取り込みログデータに取り込みラベルを適用して、ソース ストリーム インスタンス(Google Cloud Workspace など)を識別します。
- フィールド値で Palo Alto Cortex データをフィルタします。
- SentinelOne のデータをカテゴリ別に削減します。
- フィードと直接取り込みログからホスト情報を抽出し、Cloud Monitoring の
ingestion_sourceフィールドにマッピングします。
主な用語
データ処理では、次の要素が使用されます。
- ストリーム: ログタイプと取り込み元(フィードや API など)で定義された特定のデータフロー。データ処理パイプラインの入力として機能します。
- プロセッサノード: フィルタ、変換、編集などの 1 つ以上のプロセッサを含むパイプライン内のコンポーネント。これらのプロセッサは、データがノードを通過する際にデータを順番に操作します。
- 宛先: データ処理パイプラインのエンドポイント。通常は、処理されたデータが最終的な取り込みと分析のために送信される Google SecOps インスタンスです。
始める前に
データ処理パイプラインの設定を開始する前に、次の要件を確認してください。
- パーサーと UDM の影響: データ処理パイプラインは、Google SecOps パーサーに到達する前に未加工のログデータを変更します。これらの変更は、パーサーがログを解釈して Unified Data Model(UDM)形式に変換する方法に影響する可能性があります。フィードまたはログタイプのパイプラインを有効にする前に、フィルタリング、変換、または編集のルールによって、パーサーが正しい UDM イベントを生成できないような形でデータが意図せず変更されないことを確認します。
- API サポート: Chronicle API を呼び出すことで、プッシュベースのストリームのデータ処理がサポートされます。データ処理マネージャー(DPM)で構成されたフィルタは、Chronicle Ingestion API がデータを受信した後に適用されます。そのため、これらのフィルタは、インポート PushLog API の上限などの取り込み API の割り当てと上限に達するのを防ぐことはできません。これらの上限は、DPM フィルタリングが行われる前に評価されるためです。取り込み API の上限を効果的に管理し、上限内に収めるには、DPM フィルタに依存するのではなく、データソース自体でフィルタリングを実装する必要があります。
- データの可視性: 転送元と Bindplane から取り込まれたデータには、直接取り込みストリームとは異なる
collectorIDがタグ付けされます。ログの完全な可視性をサポートするには、データソースのクエリ時にすべての取り込み方法を選択するか、API の操作時に関連するcollectorIDを明示的に参照する必要があります。 Bindplane コンソールの設定: 設定と管理に Bindplane コンソールを使用する場合は、次の操作を行います。
Google SecOps コンソールで、Bindplane 統合の構成に使用するユーザーまたはサービス アカウントに次のいずれかのロールを付与します。
次の権限を持つカスタムロール:
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.list
指定された必須権限を持つカスタムロールを使用することをおすすめします。
詳細については、カスタムロールを作成、管理すると IAM を使用して機能アクセス制御を構成するをご覧ください。
事前定義された Chronicle API 管理者
roles/chronicle.adminロール。詳細については、専用プロジェクトでプロジェクト IAM 管理者のロールを割り当てるをご覧ください。
Bindplane Server コンソールをインストールします。SaaS またはオンプレミスについては、Bindplane Server コンソールをインストールするをご覧ください。Bindplane の最新バージョン(または Bindplane バージョン 1.96.4 以降)をインストールしてください。
Bindplane コンソールで、Google SecOps の宛先インスタンスを Bindplane プロジェクトに接続します。詳細については、Google SecOps インスタンスに接続するをご覧ください。
Google SecOps インスタンスに接続する
開始する前に、[プロジェクトの統合] ページにアクセスするための Bindplane プロジェクト管理者権限があることを確認してください。
Google SecOps インスタンスは、データ出力の宛先として機能します。
Bindplane Server コンソールを使用して Google SecOps インスタンスに接続するには、次の操作を行います。
- Bindplane Server コンソールで、 メニューをクリックし、[プロジェクトの設定] を選択します。
- [プロジェクトの設定] ページで、[統合] カードに移動し、[Google SecOps に接続] をクリックして [統合を編集] ウィンドウを開きます。
Google SecOps の宛先インスタンスの詳細を入力します。
このインスタンスは、次のように処理済みデータ(データ処理の出力)を取り込みます。フィールド 説明 リージョン Google SecOps インスタンスのリージョン。
Google Cloud コンソールでインスタンスを見つけるには、[セキュリティ] > [検出と制御] > [Google Security Operations] > [インスタンスの詳細] に移動します。お客様 ID Google SecOps インスタンスの顧客 ID。
Google SecOps コンソールで、[SIEM 設定] > [プロファイル] > [組織の詳細] に移動します。Google Cloud プロジェクト番号 Google SecOps インスタンスのGoogle Cloud プロジェクト番号。
Google SecOps コンソールでプロジェクト番号を確認するには、[SIEM 設定] > [プロファイル] > [組織の詳細] に移動します。認証情報 サービス アカウントの認証情報は、Google SecOps Data Pipeline API の認証とアクセスに必要な JSON 値です。この JSON 値は、Google サービス アカウントの認証情報ファイルから取得します。
サービス アカウントは、Google SecOps インスタンスと同じ Google Cloud プロジェクトに配置する必要があります。また、Chronicle API 管理者ロール(roles/chronicle.admin)の権限、または必要な権限を持つカスタムロール(前提条件を参照)が必要です。
サービス アカウントを作成して JSON ファイルをダウンロードする方法については、サービス アカウント キーの作成と削除をご覧ください。
また、Bindplane Cloud デプロイでは、認証に Workload Identity 連携(WIF)がサポートされています。WIF は、セルフホスト型の Bindplane デプロイではサポートされていません。詳細については、Google SecOps Integration を WIF 認証に接続するをご覧ください。[接続] をクリックします。接続の詳細が正しく、Google SecOps に正常に接続できる場合は、次のようになります。
- Google SecOps インスタンスへの接続が開きます。
- 初めて接続すると、Bindplane コンソールに [SecOps Pipelines] タブが表示されます。
- Bindplane コンソールには、API を使用してこのインスタンス用に以前に設定した処理済みデータが表示されます。API を使用して構成したプロセッサの一部は Bindplane プロセッサに変換され、残りは未加工の OpenTelemetry Transformation Language(OTTL)形式で表示されます。Bindplane コンソールを使用して、API を使用して以前に設定したパイプラインとプロセッサを編集できます。
Google SecOps インスタンスへの接続が正常に作成されたら、データ処理を設定できます。
Bindplane コンソールを使用してデータ処理を設定する
このセクションでは、Bindplane コンソールを使用して Google SecOps で新しいログ処理パイプラインをプロビジョニングしてデプロイする方法について説明します。Bindplane コンソールを使用して、API を使用して以前に設定したパイプラインを管理することもできます。
新しい Google SecOps パイプラインを作成する
Google SecOps パイプラインは、1 つのデータ処理コンテナを構成するためのコンテナです。新しい Google SecOps パイプライン コンテナを作成する手順は次のとおりです。
- Bindplane コンソールで、[SecOps パイプライン] タブをクリックして、[SecOps パイプライン] ページを開きます。
- [SecOps パイプラインを作成] をクリックします。
[SecOps パイプライン名] と [説明] を入力します。
[作成] をクリックします。新しいパイプライン コンテナは、[SecOps Pipelines] ページで確認できます。
このコンテナ内でデータ処理コンテナ ストリームとプロセッサを構成します。
データ処理コンテナを構成する
データ処理コンテナは、取り込むストリームと、データが宛先に到達する前に適用するプロセッサを定義します。
パイプライン構成カードで、ストリームとプロセッサ ノードを構成します。
データ処理コンテナを構成する手順は次のとおりです。
- まだ作成していない場合は、新しい Google SecOps パイプラインを作成します。
- Bindplane コンソールで、[SecOps パイプライン] タブをクリックして、[SecOps パイプライン] ページを開きます。
- 新しいデータ処理コンテナを構成する Google SecOps パイプラインを選択します。
[パイプライン] 構成カードで、次の操作を行います。
- ストリームを追加します。
- プロセッサ ノードを構成します。Bindplane コンソールを使用してプロセッサを追加するには、プロセッサを構成するをご覧ください。
これらの構成が完了したら、データ処理のロールアウトを参照して、データの処理を開始します。
ストリームを追加する
ストリームを追加する手順は次のとおりです。
- [パイプライン] 構成カードで、[ 追加 ] アイコン ストリームを追加 をクリックして、[ストリームを追加] ウィンドウを開きます。
[ストリームを追加] ウィンドウで、次のフィールドの詳細を入力します。
フィールド 説明 ログタイプ 取り込むデータのログタイプを選択します。例: CrowdStrike Falcon (CS_EDR)
注: 警告 警告アイコンは、ログタイプが別のストリーム(このパイプラインまたは Google SecOps インスタンス内の別のパイプライン)ですでに構成されていることを示します。
使用できないログタイプを使用するには、まず他のストリーム構成から削除する必要があります。
ログタイプが構成されているストリーム構成を見つける方法については、SecOps パイプライン構成をフィルタするをご覧ください。取り込み方法 選択したログタイプのデータを取り込むために使用する取り込み方法を選択します。これらの取り込み方法は、以前に Google SecOps インスタンス用に定義されています。
次のいずれかのオプションを選択する必要があります。
- すべての取り込み方法: 選択したログタイプのすべての取り込み方法が含まれます。このオプションを選択すると、同じログタイプに特定の取り込み方法を使用する後続のストリームを追加できなくなります。例外: 他のストリームで、このログタイプ用に構成されていない他の特定の取り込み方法を選択できます。
- 特定の取り込み方法(
Cloud Native Ingestion、Feed、Ingestion API、Workspace Ingestionなど)。
フィード 取り込み方法として Feedを選択すると、選択したログタイプで使用可能なフィード名(Google SecOps インスタンスで事前構成済み)のリストが次のフィールドに表示されます。設定を完了するには、関連するフィードを選択する必要があります。利用可能なフィードを表示して管理するには、[SIEM 設定] > [フィード テーブル] に移動します。- すべての取り込み方法: 選択したログタイプのすべての取り込み方法が含まれます。このオプションを選択すると、同じログタイプに特定の取り込み方法を使用する後続のストリームを追加できなくなります。例外: 他のストリームで、このログタイプ用に構成されていない他の特定の取り込み方法を選択できます。
[ストリームを追加] をクリックして、新しいストリームを保存します。新しいデータ ストリームが [パイプライン] 構成カードにすぐに表示されます。ストリームは、プロセッサノードと Google SecOps の宛先に自動的に接続されます。
SecOps パイプライン構成をフィルタする
[SecOps Pipelines] ページの検索バーを使用すると、複数の構成要素に基づいて Google SecOps パイプライン(データ処理コンテナ)をフィルタして見つけることができます。ログタイプ、取り込み方法、フィード名などの特定の条件を検索して、パイプラインをフィルタできます。
フィルタするには、次の構文を使用します。
logType:valueingestionMethod:valuefeed:value
たとえば、特定のログタイプを含むストリーム構成を特定するには、検索バーに「logtype:」と入力し、結果のリストからログタイプを選択します。
プロセッサを構成する
データ処理コンテナには 1 つのプロセッサノードがあり、そのノードには 1 つ以上のプロセッサが含まれています。各プロセッサは、ストリームデータを順番に操作します。
- 最初のプロセッサは、未加工のストリーム データを処理します。
- 最初のプロセッサの出力は、シーケンス内の次のプロセッサの入力になります。
- このシーケンスは、[プロセッサ] ペインに表示される順序で、後続のすべてのプロセッサに対して続行されます。1 つのプロセッサの出力が次のプロセッサの入力になります。
- 1 つ以上のプロセッサのシーケンスを追加、削除、または変更して、プロセッサ ノードを構成します。
次の表に、プロセッサを示します。
| プロセッサ タイプ | 能力 |
|---|---|
| フィルタ | 条件でフィルタ |
| フィルタ | HTTP ステータスでフィルタする |
| フィルタ | 指標名でフィルタ |
| フィルタ | 正規表現でフィルタ |
| フィルタ | 重大度でフィルタする |
| 秘匿化 | 機密データの秘匿化 |
| 変換 | 項目の追加 |
| 変換 | Coalesce |
| 変換 | Concat |
| 変換 | フィールドをコピー |
| 変換 | フィールドを削除する |
| 変換 | Marshal |
| 変換 | フィールドを移動 |
| 変換 | CSV を解析 |
| 変換 | JSON を解析する |
| 変換 | Key-Value を解析する |
| 変換 | 重大度フィールドを解析する |
| 変換 | タイムスタンプを変換する |
| 変換 | 正規表現で解析する |
| 変換 | XML を解析する |
| 変換 | 項目名の変更 |
| 変換 | 書き換えタイムスタンプ |
| 変換 | 分割 |
| 変換 | 変換 |
プロセッサを追加する
プロセッサを追加する手順は次のとおりです。
[Pipeline] 構成カードで、[Processor] ノードをクリックして [Edit Processors] ウィンドウを開きます。[プロセッサの編集] ウィンドウは、データフロー順に次のペインに分かれています。
- 入力(またはソースデータ): 最近受信したストリーム ログデータ(処理前)
- 構成(またはプロセッサ リスト): プロセッサとその構成
- 出力(または結果): 最近の送信結果ログデータ(処理後)
パイプラインが以前にロールアウトされた場合、システムは最近の受信ログデータ(処理前)と最近の送信ログデータ(処理後)をペインに表示します。
[プロセッサを追加] をクリックして、プロセッサのリストを表示します。便宜上、プロセッサのリストはプロセッサ タイプ別にグループ化されています。リストを整理して独自のバンドルを追加するには、1 つ以上のプロセッサを選択して [新しいプロセッサ バンドルを追加] をクリックします。
プロセッサのリストで、追加するプロセッサを選択します。
必要に応じてプロセッサを構成します。
[保存] をクリックして、[Processor] ノードにプロセッサ構成を保存します。
システムは、受信ストリーム データ([入力] ペイン)の新しいサンプルを処理して新しい構成をすぐにテストし、結果の送信データを [出力] ペインに表示します。
データ処理パイプラインをロールアウトする
ストリームとプロセッサの構成が完了したら、パイプラインをロールアウトしてデータの処理を開始する必要があります。
- [公開を開始] をクリックします。これにより、データ処理が直ちに有効になり、Google のインフラストラクチャが構成に従ってデータの処理を開始します。ロールアウトが成功すると、データ処理コンテナのバージョン番号が増加し、コンテナの
nameの横に表示されます。
API メソッドを使用してデータ処理を設定する
Bindplane コンソールの代わりに、Google SecOps データ パイプライン メソッドを使用して、処理済みデータを管理できます。これらのデータ パイプライン メソッドには、パイプラインの作成、更新、削除、一覧表示、フィードとログタイプをパイプラインに関連付ける操作が含まれます。
このセクションの例を使用するには、次の操作を行います。
- お客様固有のパラメータ(URL やフィード ID など)を、ご自身の環境に適したパラメータに置き換えます。
- 独自の認証を挿入します。このセクションでは、ベアラー トークンは
******で編集されています。
特定の Google SecOps インスタンス内のすべてのパイプラインを一覧表示する
次のコマンドは、特定の Google SecOps インスタンスに存在するすべてのパイプラインを一覧表示します。
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
1 つのプロセッサを含む基本的なパイプラインを作成する
カスタム取り込みラベルの値を upsert する単一の変換プロセッサを含む基本的なパイプラインを作成し、3 つのソースを関連付けるには、次の操作を行います。
次のコマンドを実行します。
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'レスポンスから
nameフィールドの値をコピーします。次のコマンドを実行して、3 つのストリーム(ログタイプ、コレクタ ID を含むログタイプ、フィード)をパイプラインに関連付けます。
nameフィールドの値を{pipelineName}値として使用します。curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
3 つのプロセッサを含むパイプラインを作成する
パイプラインでは、次のプロセッサが使用されます。
- フィルタ: 取り込みラベルに基づいて条件に一致するログを除外します。
- 変換: Namespace 値を upsert します。
- 秘匿化: カスタムの正規表現パターンに基づいて、ログデータからメールアドレスと社会保障番号を秘匿化します。
パイプラインを作成し、3 つのソースを関連付けるには、次の操作を行います。
次のコマンドを実行します。
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'レスポンスから
nameフィールドの値をコピーします。次のコマンドを実行して、3 つのストリーム(ログタイプ、コレクタ ID を含むログタイプ、フィード)をパイプラインに関連付けます。
nameフィールドの値を{pipelineName}値として使用します。curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
トラブルシューティング
このセクションでは、パフォーマンスの期待値と、一般的な問題に対するセルフサービスによる修正について説明します。
レイテンシと上限
Ingestion API を使用してエージェントを構成すると、低ボリュームの Google SecOps パイプラインで確認応答時間が長くなることがあります。
レイテンシの平均値が 700 ミリ秒から 2 秒まで上昇する可能性があります。必要に応じて、タイムアウト期間とメモリを増やします。データ スループットが 4 MB を超えると、確認応答時間が短くなります。
検証とテスト
データ処理の詳細は、Google SecOps コンソールで確認できます。
すべてのデータ処理構成を表示する
- Google SecOps コンソールで、[SIEM 設定] > [データ処理] に移動すると、構成済みのすべてのパイプラインを表示できます。
- [Incoming Data Pipelines] 検索バーで、作成したパイプラインを検索します。パイプライン名やコンポーネントなどの要素で検索できます。検索結果には、パイプラインのプロセッサと構成の概要が表示されます。
- パイプラインの概要では、次の操作を行うことができます。
- プロセッサ構成を確認します。
- 構成の詳細をコピーします。
- [Bindplane で開く] をクリックして、Bindplane コンソール内でパイプラインに直接アクセスして管理します。
設定済みのフィードを表示する
システムで構成されたフィードを表示するには、次の操作を行います。
- Google SecOps コンソールで、[SIEM 設定] > [フィード] に移動します。[フィード] ページには、システムで構成したすべてのフィードが表示されます。
- 各行にポインタを合わせると、⋮ [その他] メニューが表示されます。このメニューで、フィードの詳細を表示したり、フィードを編集、無効化、削除したりできます。
- [詳細を表示] をクリックして、詳細ウィンドウを表示します。
- [Bindplane で開く] をクリックして、Bindplane コンソールでそのフィードのストリーム構成を開きます。
使用可能なログタイプのデータ処理の詳細を表示する
[利用可能なログタイプ] ページでデータ処理の詳細を表示するには、次の操作を行います。このページでは、利用可能なすべてのログタイプを確認できます。
- Google SecOps コンソールで、[SIEM 設定] > [使用可能なログタイプ] に移動します。メインページには、すべてのログタイプが表示されます。
- 各フィード行にポインタを合わせると、 more_vert [その他] メニューが表示されます。このメニューでは、フィードの詳細の表示、編集、無効化、削除を行うことができます。
- [データ処理を表示] をクリックして、フィードの構成を表示します。
- [Bindplane で開く] をクリックして、Bindplane コンソールでそのプロセッサのプロセッサ構成を開きます。
さらにサポートが必要な場合 コミュニティ メンバーや Google SecOps のプロフェッショナルから回答を得ることができます。