
Datenverarbeitungspipelines verwalten
Dieses Dokument hilft Sicherheitsexperten, Datenverarbeitungs-Pipelines in Google SecOps einzurichten und zu verwalten, um Ereignisse zu filtern, Felder zu transformieren oder vertrauliche Werte vor der Aufnahme zu entfernen. Diese Funktion bietet eine robuste Vorab-Parsing-Kontrolle über den Datenaufnahmeprozess. Wenn Sie die empfohlenen Methoden in diesem Leitfaden befolgen, können Sie die Datenkompatibilität optimieren, Kosten senken und vertrauliche Informationen in Google SecOps schützen.
Die Datenverarbeitung vereinfacht die Logverwaltung durch die folgenden Kernaktionen:
- Filtern: Reduzieren Sie Rauschen und Kosten, indem Sie nur relevante Ereignisse erfassen.
- Transformieren: Datenformate ändern, Felder parsen und Logs für eine bessere Nutzbarkeit anreichern.
- Redact: Schützen Sie vertrauliche Informationen, indem Sie vertrauliche Werte vor dem Speichern maskieren oder entfernen.
Das folgende Diagramm veranschaulicht, wie Ihre Daten in Google SecOps einfließen und wie das System diese Daten verarbeitet:
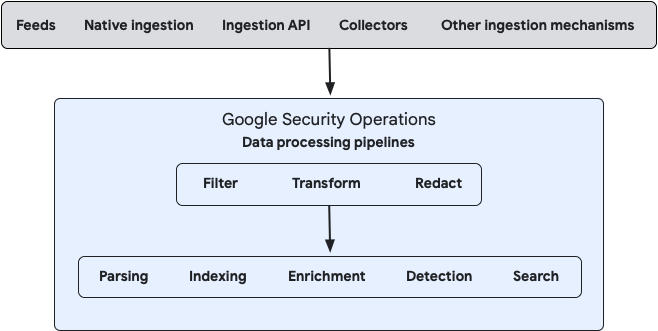
Sie können die Datenverarbeitung für On-Premise- und Cloud-Datenstreams entweder über die Bindplane-Verwaltungskonsole oder direkt über die öffentlichen Google SecOps Data Pipeline APIs konfigurieren.
Gängige Anwendungsfälle
Beispiele für Anwendungsfälle für die Datenverarbeitung:
- Leere Schlüssel/Wert-Paare aus Rohlogs entfernen
- Entfernen Sie sensible Daten.
- Aufnahme-Labels aus Rohlog-Inhalten hinzufügen
- In Umgebungen mit Multi-Instanz-Modus können Sie Aufnahmelabels auf Logdaten für die Direktaufnahme anwenden, um die Quellstream-Instanz (z. B.Google Cloud Workspace) zu identifizieren.
- Palo Alto Cortex-Daten nach Feldwerten filtern
- SentinelOne-Daten nach Kategorie reduzieren
- Extrahieren Sie Hostinformationen aus Feeds und Logs für die direkte Aufnahme und ordnen Sie sie dem Feld
ingestion_sourcefür Cloud Monitoring zu.
Schlüsselterminologie
Für die Datenverarbeitung werden die folgenden Elemente verwendet:
- Streams: Ein bestimmter Datenfluss, der durch den Logtyp und die Erfassungsquelle (z. B. ein Feed oder eine API) definiert wird und als Eingabe für eine Datenverarbeitungs-Pipeline dient.
- Prozessorknoten: Eine Komponente in einer Pipeline, die einen oder mehrere Prozessoren enthält, z. B. Filter-, Transformations- oder Bereinigungsaktionen. Diese Prozessoren bearbeiten Daten sequenziell, während sie den Knoten durchlaufen.
- Ziel: Der Endpunkt der Datenverarbeitungspipeline, in der Regel die Google SecOps-Instanz, an die verarbeitete Daten zur endgültigen Aufnahme und Analyse gesendet werden.
Hinweis
Bevor Sie mit der Einrichtung von Pipelines zur Datenverarbeitung beginnen, sollten Sie die folgenden Anforderungen prüfen:
- Auswirkungen von Parsern und UDM: Datenverarbeitungspipelines ändern Rohprotokolldaten, bevor sie die Google SecOps-Parser erreichen. Diese Änderungen können sich darauf auswirken, wie Parser Logs interpretieren und in das einheitliche Datenmodell (Unified Data Model, UDM) konvertieren. Bevor Sie eine Pipeline für einen Feed- oder Protokolltyp aktivieren, sollten Sie prüfen, ob Ihre Filter-, Transformations- oder Bereinigungsregeln Daten unbeabsichtigt so ändern, dass Parser keine korrekten UDM-Ereignisse generieren können.
- API-Unterstützung: Die Datenverarbeitung wird für Push-basierte Streams durch Aufrufen der Chronicle API unterstützt. Im Data Processing Manager (DPM) konfigurierte Filter werden angewendet, nachdem Daten von der Chronicle Ingestion API empfangen wurden. Diese Filter verhindern daher nicht, dass Kunden die Kontingente und Limits der Ingestion API überschreiten, z. B. die importPushLog API-Limits, da diese Limits vor der DPM-Filterung ausgewertet werden. Um die Limits der Ingestion API effektiv zu verwalten und einzuhalten, sollten Kunden Filter direkt in der Datenquelle implementieren, anstatt sich auf DPM-Filter zu verlassen.
- Datensichtbarkeit: Daten, die von Forwardern und Bindplane aufgenommen werden, werden mit einem anderen
collectorIDals Daten aus direkten Aufnahmestreams getaggt. Damit alle Logs sichtbar sind, müssen Sie entweder alle Erfassungsmethoden auswählen, wenn Sie Datenquellen abfragen, oder explizit auf die relevantencollectorIDverweisen, wenn Sie mit der API interagieren. Bindplane-Console einrichten: Wenn Sie die Bindplane-Console für die Einrichtung und Verwaltung verwenden möchten, führen Sie die folgenden Schritte aus:
Weisen Sie in der Google SecOps Console dem Nutzer oder Dienstkonto, das Sie zum Konfigurieren der Bindplane-Integration verwenden, eine der folgenden Rollen zu:
Eine benutzerdefinierte Rolle mit den folgenden Berechtigungen:
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.list
Wir empfehlen, eine benutzerdefinierte Rolle mit den angegebenen erforderlichen Berechtigungen zu verwenden.
Weitere Informationen finden Sie unter Benutzerdefinierte Rollen erstellen und verwalten und Funktionszugriffssteuerung mit IAM konfigurieren.
Die vordefinierte Rolle „Chronicle API Admin“
roles/chronicle.admin.Weitere Informationen finden Sie unter Rolle „Project IAM Admin“ in einem dedizierten Projekt zuweisen.
Installieren Sie die BindPlane-Serverkonsole. Informationen zur SaaS- oder On-Premise-Installation finden Sie unter BindPlane Server-Konsole installieren. Installieren Sie die neueste Version von Bindplane (oder Bindplane-Version 1.96.4 oder höher).
Verbinden Sie in der BindPlane-Konsole eine Google SecOps-Zielinstanz mit Ihrem BindPlane-Projekt. Weitere Informationen finden Sie unter Verbindung zu einer Google SecOps-Instanz herstellen.
Verbindung zu einer Google SecOps-Instanz herstellen
Bevor Sie beginnen, müssen Sie sicherstellen, dass Sie die Berechtigungen als Bindplane-Projektadministrator haben, um auf die Seite Projektintegrationen zuzugreifen.
Die Google SecOps-Instanz dient als Ziel für Ihre Datenausgabe.
So stellen Sie über die Bindplane Server-Konsole eine Verbindung zu einer Google SecOps-Instanz her:
- Klicken Sie in der Bindplane Server-Konsole auf Menü und wählen Sie Projekteinstellungen aus.
- Rufen Sie auf der Seite Projekteinstellungen die Karte Integrationen auf und klicken Sie auf Mit Google SecOps verbinden, um das Fenster Integration bearbeiten zu öffnen.
Geben Sie die Details für die Google SecOps-Zielinstanz ein.
In dieser Instanz werden die verarbeiteten Daten (Ausgabe aus der Datenverarbeitung) so aufgenommen:Feld Beschreibung Region Region Ihrer Google SecOps-Instanz.
Wenn Sie die Instanz in der Google Cloud -Konsole aufrufen möchten, gehen Sie zu Sicherheit > „Erkennungen und Steuerelemente“ > Google Security Operations > Instanzdetails.Kundennummer Kundennummer Ihrer Google SecOps-Instanz.
Rufen Sie in der Google SecOps-Konsole die SIEM-Einstellungen > Profile > Organisationsdetails auf.Google Cloud Projektnummer Google Cloud – Projektnummer Ihrer Google SecOps-Instanz.
Die Projektnummer finden Sie in der Google SecOps Console unter SIEM Settings > Profile > Organization details.Anmeldedaten Dienstkonto-Anmeldedaten sind der JSON-Wert, der für die Authentifizierung und den Zugriff auf die Google SecOps Data Pipeline APIs erforderlich ist. Rufen Sie diesen JSON-Wert aus der Datei mit den Anmeldedaten für das Google-Dienstkonto ab.
Das Dienstkonto muss sich im selben Projekt wie Ihre Google SecOps-Instanz befinden und erfordert entweder die Berechtigungen der Rolle „Chronicle API Admin“ (roles/chronicle.admin) oder eine benutzerdefinierte Rolle mit den erforderlichen Berechtigungen (siehe Voraussetzungen). Google Cloud
Informationen zum Erstellen eines Dienstkontos und zum Herunterladen der JSON-Datei finden Sie unter Dienstkontoschlüssel erstellen und löschen.
Alternativ unterstützen Bindplane Cloud-Bereitstellungen die Workload Identity Federation (WIF) für die Authentifizierung. WIF wird in selbst gehosteten Bindplane-Bereitstellungen nicht unterstützt. Weitere Informationen finden Sie unter Google SecOps-Integration mit WIF-Authentifizierung verbinden.Klicken Sie auf Verbinden. Wenn Ihre Verbindungsdetails korrekt sind und Sie erfolgreich eine Verbindung zu Google SecOps herstellen, können Sie Folgendes erwarten:
- Eine Verbindung zur Google SecOps-Instanz wird geöffnet.
- Wenn Sie zum ersten Mal eine Verbindung herstellen, wird der Tab SecOps Pipelines in der Bindplane-Konsole angezeigt.
- In der Bindplane-Konsole werden alle verarbeiteten Daten angezeigt, die Sie zuvor für diese Instanz über die API eingerichtet haben. Das System konvertiert einige Prozessoren, die Sie mit der API konfiguriert haben, in Bindplane-Prozessoren und zeigt andere im Rohformat der OpenTelemetry Transformation Language (OTTL) an. Sie können die Bindplane-Konsole verwenden, um Pipelines und Prozessoren zu bearbeiten, die zuvor mit der API eingerichtet wurden.
Nachdem Sie eine Verbindung zu einer Google SecOps-Instanz hergestellt haben, können Sie die Datenverarbeitung einrichten.
Datenverarbeitung mit der Bindplane-Konsole einrichten
In diesem Abschnitt wird beschrieben, wie Sie eine neue Log-Verarbeitungspipeline in Google SecOps mit der Bindplane-Konsole bereitstellen und bereitstellen. Sie können auch die Bindplane-Konsole verwenden, um Pipelines zu verwalten, die zuvor mit der API eingerichtet wurden.
Neue Google SecOps-Pipeline erstellen
Eine Google SecOps-Pipeline ist ein Container, in dem Sie einen Datenverarbeitungscontainer konfigurieren können. So erstellen Sie einen neuen Google SecOps-Pipeline-Container:
- Klicken Sie in der Bindplane-Konsole auf den Tab SecOps Pipelines, um die Seite SecOps Pipelines zu öffnen.
- Klicken Sie auf SecOps-Pipeline erstellen.
Geben Sie einen SecOps-Pipelinennamen und eine Beschreibung ein.
Klicken Sie auf Erstellen. Der neue Pipeline-Container wird auf der Seite SecOps Pipelines angezeigt.
Konfigurieren Sie die Datenverarbeitungscontainer-Streams und ‑Prozessoren in diesem Container.
Container für die Datenverarbeitung konfigurieren
Ein Datenverarbeitungscontainer definiert die Streams, die aufgenommen werden sollen, und die Prozessoren, die angewendet werden sollen, bevor die Daten das Ziel erreichen.
Konfigurieren Sie die Stream- und Prozessorknoten auf der Konfigurationskarte Pipeline.
So konfigurieren Sie einen Datenverarbeitungscontainer:
- Falls noch nicht geschehen, erstellen Sie eine neue Google SecOps-Pipeline.
- Klicken Sie in der Bindplane-Konsole auf den Tab SecOps Pipelines, um die Seite SecOps Pipelines zu öffnen.
- Wählen Sie die Google SecOps-Pipeline aus, in der Sie den neuen Datenverarbeitungscontainer konfigurieren möchten.
Auf der Konfigurationskarte Pipeline:
- Stream hinzufügen
- Konfigurieren Sie den Prozessorknoten. Informationen zum Hinzufügen eines Prozessors über die Bindplane-Konsole finden Sie unter Prozessoren konfigurieren.
Nachdem Sie diese Konfigurationen abgeschlossen haben, können Sie mit der Verarbeitung der Daten beginnen (siehe Datenverarbeitung einführen).
Stream hinzufügen
So fügen Sie einen Stream hinzu:
- Klicken Sie auf der Konfigurationskarte Pipeline auf Hinzufügen Stream hinzufügen, um das Fenster Stream hinzufügen zu öffnen.
Geben Sie im Fenster Stream hinzufügen Details für die folgenden Felder ein:
Feld Beschreibung Logtyp Wählen Sie den Protokolltyp der aufzunehmenden Daten aus. Beispiel: CrowdStrike Falcon (CS_EDR).
Hinweis: Ein Warnsymbol Warnung weist darauf hin, dass der Protokolltyp bereits in einem anderen Stream konfiguriert ist (entweder in dieser Pipeline oder in einer anderen Pipeline in Ihrer Google SecOps-Instanz).
Wenn Sie einen nicht verfügbaren Logtyp verwenden möchten, müssen Sie ihn zuerst aus der anderen Streamkonfiguration löschen.
Eine Anleitung dazu, wie Sie die Streamkonfiguration finden, in der der Logtyp konfiguriert ist, finden Sie unter SecOps-Pipelinekonfigurationen filtern.Aufnahmemethode Wählen Sie die Aufnahmemethode aus, die zum Aufnehmen der Daten für den ausgewählten Logtyp verwendet werden soll. Diese Erfassungsmethoden wurden zuvor für Ihre Google SecOps-Instanz definiert.
Sie müssen eine der folgenden Optionen auswählen:
- Alle Erfassungsmethoden: Enthält alle Erfassungsmethoden für den ausgewählten Logtyp. Wenn Sie diese Option auswählen, können Sie keine weiteren Streams hinzufügen, die bestimmte Aufnahmemethoden für denselben Logtyp verwenden. Ausnahme: Sie können für diesen Logtyp in anderen Streams andere nicht konfigurierte spezifische Erfassungsmethoden auswählen.
- Spezifische Erfassungsmethode, z. B.
Cloud Native Ingestion,Feed,Ingestion APIoderWorkspace Ingestion.
Feed Wenn Sie Feedals Erfassungsmethode auswählen, wird ein weiteres Feld mit einer Liste der verfügbaren Feednamen (in Ihrer Google SecOps-Instanz vorkonfiguriert) für den ausgewählten Logtyp angezeigt. Sie müssen den entsprechenden Feed auswählen, um die Konfiguration abzuschließen. Wenn Sie Ihre verfügbaren Feeds ansehen und verwalten möchten, rufen Sie die SIEM-Einstellungen > Feedtabelle auf.- Alle Erfassungsmethoden: Enthält alle Erfassungsmethoden für den ausgewählten Logtyp. Wenn Sie diese Option auswählen, können Sie keine weiteren Streams hinzufügen, die bestimmte Aufnahmemethoden für denselben Logtyp verwenden. Ausnahme: Sie können für diesen Logtyp in anderen Streams andere nicht konfigurierte spezifische Erfassungsmethoden auswählen.
Klicken Sie auf Stream hinzufügen, um den neuen Stream zu speichern.Der neue Datenstream wird sofort auf der Konfigurationskarte Pipeline angezeigt. Der Stream wird automatisch mit dem Prozessorknoten und dem Ziel von Google SecOps verbunden.
SecOps-Pipeline-Konfigurationen filtern
Mit der Suchleiste auf der Seite SecOps Pipelines können Sie Ihre Google SecOps-Pipelines (Datenverarbeitungscontainer) anhand mehrerer Konfigurationselemente filtern und finden. Sie können Pipelines filtern, indem Sie nach bestimmten Kriterien wie Protokolltyp, Erfassungsmethode oder Feedname suchen.
Verwenden Sie die folgende Syntax zum Filtern:
logType:valueingestionMethod:valuefeed:value
Wenn Sie beispielsweise Streamkonfigurationen ermitteln möchten, die einen bestimmten Logtyp enthalten, geben Sie in der Suchleiste logtype: ein und wählen Sie den Logtyp aus der Ergebnisliste aus.
Prozessoren konfigurieren
Ein Datenverarbeitungscontainer hat einen Prozessorknoten, der einen oder mehrere Prozessoren enthält. Jeder Prozessor verarbeitet die Streamdaten sequenziell:
- Der erste Prozessor verarbeitet die Rohstreamdaten.
- Die Ausgabe des ersten Prozessors wird sofort zur Eingabe für den nächsten Prozessor in der Sequenz.
- Diese Sequenz wird für alle nachfolgenden Prozessoren in der genauen Reihenfolge fortgesetzt, in der sie im Bereich Prozessoren angezeigt werden. Die Ausgabe eines Prozessors wird zur Eingabe des nächsten.
- Konfigurieren Sie den Prozessorknoten, indem Sie einen oder mehrere Prozessoren hinzufügen, entfernen oder die Reihenfolge ändern.
In der folgenden Tabelle sind die Prozessoren aufgeführt:
| Prozessortyp | Funktion |
|---|---|
| Filter | Nach Bedingung filtern |
| Filter | Nach HTTP-Status filtern |
| Filter | Nach Messwertname filtern |
| Filter | Nach regulärem Ausdruck filtern |
| Filter | Nach Schweregrad filtern |
| Entfernen | Sensible Daten unkenntlich machen |
| Transformieren | Felder hinzufügen |
| Transformieren | Coalesce |
| Transformieren | Concat |
| Transformieren | Feld kopieren |
| Transformieren | Felder löschen |
| Transformieren | Marshal |
| Transformieren | Feld verschieben |
| Transformieren | CSV parsen |
| Transformieren | JSON parsen |
| Transformieren | Schlüsselwert parsen |
| Transformieren | Schweregradfelder parsen |
| Transformieren | Zeitstempel parsen |
| Transformieren | Mit regulären Ausdrücken parsen |
| Transformieren | XML parsen |
| Transformieren | Felder umbenennen |
| Transformieren | Zeitstempel für das Umschreiben |
| Transformieren | Aufteilen |
| Transformieren | Transformieren |
Prozessor hinzufügen
So fügen Sie einen Prozessor hinzu:
Klicken Sie auf der Konfigurationskarte Pipeline auf den Knoten Prozessor, um das Fenster Prozessoren bearbeiten zu öffnen. Das Fenster Prozessoren bearbeiten ist in die folgenden Bereiche unterteilt, die nach Datenfluss angeordnet sind:
- Eingabe (oder Quelldaten): Aktuelle eingehende Stream-Logdaten (vor der Verarbeitung)
- Konfiguration (oder Prozessorliste): Prozessoren und ihre Konfigurationen
- Ausgabe (oder Ergebnisse): Aktuelle ausgehende Ergebnisprotokolldaten (nach der Verarbeitung)
Wenn die Pipeline bereits eingeführt wurde, werden im System in den Bereichen die letzten eingehenden Logdaten (vor der Verarbeitung) und die letzten ausgehenden Logdaten (nach der Verarbeitung) angezeigt.
Klicken Sie auf Prozessor hinzufügen, um die Prozessorliste aufzurufen. Die Liste der Auftragsverarbeiter ist nach Auftragsverarbeitertyp gruppiert. Wenn Sie die Liste organisieren und eigene Sets hinzufügen möchten, wählen Sie einen oder mehrere Prozessoren aus und klicken Sie auf Neue Prozessorsets hinzufügen.
Wählen Sie in der Liste der Prozessoren einen Prozessor aus, den Sie hinzufügen möchten.
Konfigurieren Sie den Prozessor nach Bedarf.
Klicken Sie auf Speichern, um die Prozessorkonfiguration im Knoten Prozessor zu speichern.
Das System testet die neue Konfiguration sofort, indem es eine neue Stichprobe der eingehenden Streamdaten (aus dem Bereich Eingabe) verarbeitet und die resultierenden ausgehenden Daten im Bereich Ausgabe anzeigt.
Datenverarbeitungspipeline einführen
Nachdem Sie die Stream- und Prozessorkonfigurationen abgeschlossen haben, müssen Sie die Pipeline bereitstellen, um mit der Verarbeitung von Daten zu beginnen:
- Klicken Sie auf Roll-out starten. Dadurch wird die Datenverarbeitung sofort aktiviert und die Infrastruktur von Google kann mit der Verarbeitung von Daten gemäß Ihrer Konfiguration beginnen. Wenn die Einführung erfolgreich ist, wird die Versionsnummer des Datenverarbeitungscontainers erhöht und neben dem
namedes Containers angezeigt.
Datenverarbeitung mit API-Methoden einrichten
Als Alternative zur Bindplane-Konsole können Sie die Google SecOps-Methoden für Datenpipelines verwenden, um Ihre verarbeiteten Daten zu verwalten. Zu diesen Methoden für Datenpipelines gehören das Erstellen, Aktualisieren, Löschen und Auflisten von Pipelines sowie das Verknüpfen von Feeds und Log-Typen mit Pipelines.
So verwenden Sie die Beispiele in diesem Abschnitt:
- Ersetzen Sie die kundenspezifischen Parameter (z. B. URLs und Feed-IDs) durch Parameter, die für Ihre Umgebung geeignet sind.
- Fügen Sie Ihre eigene Authentifizierung ein. In diesem Abschnitt werden die Bearer-Tokens mit
******unkenntlich gemacht.
Alle Pipelines in einer bestimmten Google SecOps-Instanz auflisten
Mit dem folgenden Befehl werden alle Pipelines aufgelistet, die in einer bestimmten Google SecOps-Instanz vorhanden sind:
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
Einfache Pipeline mit einem Prozessor erstellen
So erstellen Sie eine einfache Pipeline mit einem einzelnen Transformationsprozessor, der den Wert für ein benutzerdefiniertes Ingestionslabel einfügt oder aktualisiert, und drei Quellen damit verknüpfen:
Führen Sie dazu diesen Befehl aus:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'Kopieren Sie aus der Antwort den Wert des Felds
name.Führen Sie den folgenden Befehl aus, um drei Streams (Logtyp, Logtyp mit Collector-ID und Feed) mit der Pipeline zu verknüpfen. Verwenden Sie den Wert des Felds
nameals{pipelineName}-Wert.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Pipeline mit drei Prozessoren erstellen
Eine Pipeline verwendet die folgenden Prozessoren:
- Filter: Filtert Logs heraus, die einer Bedingung auf Grundlage der Ingestion-Labels entsprechen.
- Transform: Führt ein Upsert für den Namespace-Wert aus.
- Entfernen: E-Mail-Adressen und Sozialversicherungsnummern werden anhand benutzerdefinierter regulärer Ausdrücke aus Logdaten entfernt.
So erstellen Sie eine Pipeline und verknüpfen drei Quellen damit:
Führen Sie dazu diesen Befehl aus:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'Kopieren Sie aus der Antwort den Wert des Felds
name.Führen Sie den folgenden Befehl aus, um drei Streams (Logtyp, Logtyp mit Collector-ID und Feed) mit der Pipeline zu verknüpfen. Verwenden Sie den Wert des Felds
nameals{pipelineName}-Wert.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Fehlerbehebung
In diesem Abschnitt werden die Leistungserwartungen beschrieben und Self-Service-Lösungen für häufige Probleme bereitgestellt.
Latenz und Limits
Wenn Sie einen Agenten mit der Ingestion API konfigurieren, kann es bei Google SecOps-Pipelines mit geringem Volumen zu längeren Bestätigungszeiten kommen.
Die durchschnittliche Latenz kann von 700 ms auf bis zu 2 Sekunden steigen. Erhöhen Sie bei Bedarf die Zeitüberschreitungen und den Arbeitsspeicher. Die Bestätigungszeit sinkt, wenn der Datendurchsatz 4 MB überschreitet.
Validierung und Tests
Sie können sich die Details zur Datenverarbeitung in der Google SecOps Console ansehen:
Alle Konfigurationen für die Datenverarbeitung ansehen
- Rufen Sie in der Google SecOps Console SIEM-Einstellungen > Datenverarbeitung auf, um alle konfigurierten Pipelines anzusehen.
- Suchen Sie in der Suchleiste Incoming Data Pipelines (Eingehende Datenpipelines) nach einer von Ihnen erstellten Pipeline. Sie können nach Elementen wie Pipelinename oder Komponenten suchen. In den Suchergebnissen werden die Prozessoren der Pipeline und eine Zusammenfassung ihrer Konfiguration angezeigt.
- In der Pipelineübersicht haben Sie folgende Möglichkeiten:
- Prüfen Sie die Prozessorkonfigurationen.
- Konfigurationsdetails kopieren.
- Klicken Sie auf In Bindplane öffnen, um direkt in der Bindplane-Konsole auf die Pipeline zuzugreifen und sie zu verwalten.
Konfigurierte Feeds ansehen
So rufen Sie konfigurierte Feeds in Ihrem System auf:
- Rufen Sie in der Google SecOps Console SIEM-Einstellungen > Feeds auf. Auf der Seite Feeds werden alle Feeds angezeigt, die Sie in Ihrem System konfiguriert haben.
- Bewegen Sie den Mauszeiger auf die jeweilige Zeile, um das Menü ⋮ Mehr aufzurufen. Dort können Sie Feeddetails ansehen, den Feed bearbeiten, deaktivieren oder löschen.
- Klicken Sie auf Details ansehen, um das Detailfenster aufzurufen.
- Klicken Sie auf In Bindplane öffnen, um die Streamkonfiguration für diesen Feed in der Bindplane-Konsole zu öffnen.
Details zur Datenverarbeitung für verfügbare Logtypen ansehen
So rufen Sie die Details zur Datenverarbeitung auf der Seite Verfügbare Logtypen auf, auf der alle verfügbaren Logtypen angezeigt werden:
- Rufen Sie in der Google SecOps Console SIEM Settings > Available Log Types auf. Auf der Hauptseite werden alle Ihre Logtypen angezeigt.
- Bewegen Sie den Mauszeiger auf die einzelnen Feedzeilen, um das more_vert Mehr aufzurufen. In diesem Menü können Sie Feeddetails ansehen, bearbeiten, deaktivieren oder löschen.
- Klicken Sie auf Datenverarbeitung ansehen, um die Konfiguration des Feeds aufzurufen.
- Klicken Sie auf In Bindplane öffnen, um die Prozessorkonfiguration für diesen Prozessor in der Bindplane-Konsole zu öffnen.
Benötigen Sie weitere Hilfe? Antworten von Community-Mitgliedern und Google SecOps-Experten erhalten