
Gerenciar pipelines de tratamento de dados
Este documento ajuda os engenheiros de segurança a configurar e gerenciar pipelines de processamento de dados no Google SecOps para filtrar eventos, transformar campos ou encobrir valores sensíveis antes da ingestão. Esse recurso oferece controle robusto de pré-análise sobre o processo de ingestão de dados. Seguindo os métodos recomendados neste guia, você pode otimizar a compatibilidade de dados, reduzir custos e proteger informações sensíveis no Google SecOps.
O processamento de dados simplifica o gerenciamento de registros com as seguintes ações principais:
- Filtrar: reduza o ruído e os custos ingerindo apenas eventos relevantes.
- Transformar: modifique formatos de dados, analise campos e enriqueça os registros para melhorar a usabilidade.
- Redact: proteja informações sensíveis mascarando ou removendo valores sensíveis antes do armazenamento.
O diagrama a seguir ilustra como seus dados fluem para o Google SecOps e como o sistema os processa:
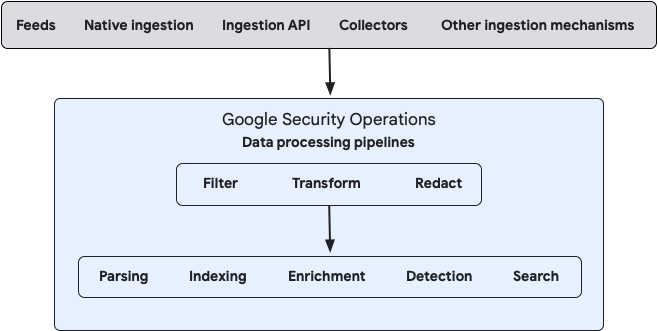
É possível configurar o processamento de fluxos de dados locais e na nuvem usando o console de gerenciamento do Bindplane ou as APIs públicas do pipeline de dados do Google SecOps diretamente.
Casos de uso comuns
Exemplos de casos de uso para processamento de dados:
- Remova pares de chave-valor vazios dos registros brutos.
- Editar dados confidenciais
- Adicione rótulos de ingestão do conteúdo bruto do registro.
- Em ambientes de várias instâncias, aplique rótulos de ingestão aos dados de registros de ingestão direta para identificar a instância do fluxo de origem (como oGoogle Cloud Workspace).
- Filtre dados do Palo Alto Cortex por valores de campo.
- Reduza os dados do SentinelOne por categoria.
- Extraia informações do host de feeds e registros de ingestão direta e mapeie-as para o campo
ingestion_sourcedo Cloud Monitoring.
Terminologia importante
O tratamento de dados usa os seguintes elementos:
- Streams: um fluxo específico de dados, definido por tipo de registro e origem de ingestão (como um feed ou uma API), que serve como entrada para um pipeline de processamento de dados.
- Nó de processador: um componente em um pipeline que contém um ou mais processadores, como ações de filtro, transformação ou redação. Esses processadores manipulam os dados sequencialmente à medida que eles passam pelo nó.
- Destino: o endpoint do pipeline de tratamento de dados, geralmente a instância do Google SecOps em que os dados tratados são enviados para ingestão e análise finais.
Antes de começar
Antes de começar a configurar pipelines de processamento de dados, revise os seguintes requisitos:
- Impacto do analisador e da UDM: os pipelines de processamento de dados modificam os dados de registros brutos antes de chegarem aos analisadores do Google SecOps. Essas modificações podem afetar a forma como os analisadores interpretam os registros e os convertem para o formato do Modelo de Dados Unificado (UDM). Antes de ativar um pipeline para um feed ou tipo de registro, verifique se as regras de filtragem, transformação ou redação não alteram os dados de maneira não intencional, impedindo que os analisadores gerem eventos UDM corretos.
- Suporte à API: o processamento de dados é compatível com streams baseados em push ao chamar a API Chronicle. Os filtros configurados no Gerenciador de tratamento de dados (DPM, na sigla em inglês) são aplicados depois que os dados são recebidos pela API de ingestão do Chronicle. Consequentemente, esses filtros não impedem que os clientes atinjam as cotas e os limites da API Ingestion, como os limites da API importPushLog, porque esses limites são avaliados antes da filtragem do DPM. Para gerenciar e respeitar os limites da API Ingestion, os clientes precisam implementar a filtragem na própria fonte de dados, em vez de usar filtros do DPM.
- Visibilidade dos dados: os dados ingeridos de encaminhadores e do Bindplane são marcados com um
collectorIDdistinto dos fluxos de ingestão direta. Para oferecer suporte à visibilidade total dos registros, selecione todos os métodos de ingestão ao consultar fontes de dados ou faça referência explícita aocollectorIDrelevante ao interagir com a API. Configuração do console do Bindplane: se você planeja usar o console do Bindplane para configuração e gerenciamento, conclua as etapas a seguir:
No console do Google SecOps, conceda um dos seguintes papéis ao usuário ou à conta de serviço que você vai usar para configurar a integração do Bindplane:
Um papel personalizado com as seguintes permissões:
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.list
Recomendamos usar uma função personalizada com as permissões obrigatórias especificadas.
Para mais informações, consulte Criar e gerenciar papéis personalizados e Configurar o controle de acesso a recursos usando o IAM.
O papel predefinido Administrador da API Chronicle
roles/chronicle.admin.Para mais detalhes, consulte Atribuir a função de administrador do IAM do projeto em um projeto dedicado.
Instale o console do servidor do BindPlane. Para SaaS ou no local, consulte Instalar o console do servidor Bindplane. Instale a versão mais recente do Bindplane (ou a versão 1.96.4 ou mais recente).
No console do Bindplane, conecte uma instância de destino do Google SecOps ao seu projeto do Bindplane. Para mais detalhes, consulte Conectar-se a uma instância do Google SecOps.
Conectar a uma instância do Google SecOps
Antes de começar, confirme se você tem as permissões de administrador do projeto do Bindplane para acessar a página Integrações do projeto.
A instância do Google SecOps serve como destino para a saída de dados.
Para se conectar a uma instância do Google SecOps usando o console do Bindplane Server, faça o seguinte:
- No console do Bindplane Server, clique em Menu e selecione Configurações do projeto.
- Na página Configurações do projeto, acesse o card Integrações e clique em Conectar ao Google SecOps para abrir a janela Editar integração.
Insira os detalhes da instância de destino do Google SecOps.
Essa instância ingere os dados processados (saída do seu processamento de dados) da seguinte maneira:Campo Descrição Região Região da sua instância do Google SecOps.
Para encontrar a instância no console Google Cloud , acesse Segurança > Detecções e controles > Google Security Operations > Detalhes da instância.ID do cliente ID do cliente da sua instância do Google SecOps.
No console do Google SecOps, acesse Configurações do SIEM > Perfil > Detalhes da organização.Google Cloud número do projeto Google Cloud número do projeto da sua instância do Google SecOps.
Para encontrar o número do projeto no console do Google SecOps, acesse Configurações do SIEM > Perfil > Detalhes da organização.Credenciais As credenciais da conta de serviço são o valor JSON necessário para autenticar e acessar as APIs do Google SecOps Data Pipeline. Extraia esse valor JSON do arquivo de credencial da conta de serviço do Google.
A conta de serviço precisa estar localizada no mesmo projeto Google Cloud da sua instância do Google SecOps e exige privilégios de administrador da API Chronicle (roles/chronicle.admin) ou um papel personalizado com as permissões necessárias. Consulte Pré-requisitos.
Para informações sobre como criar uma conta de serviço e fazer o download do arquivo JSON, consulte Criar e excluir chaves de conta de serviço.
Como alternativa, as implantações do Bindplane Cloud oferecem suporte à federação de identidade da carga de trabalho (WIF, na sigla em inglês) para autenticação. A WIF não é compatível com implantações autohospedadas do Bindplane. Para mais informações, consulte Conectar a integração do Google SecOps à autenticação WIF.Clique em Conectar. Se os detalhes da conexão estiverem corretos e você se conectar ao Google SecOps, espere o seguinte:
- Uma conexão com a instância do Google SecOps será aberta.
- Na primeira vez que você se conectar, a guia Pipelines do SecOps vai aparecer no console do Bindplane.
- O console do Bindplane mostra todos os dados processados que você configurou anteriormente para essa instância usando a API. O sistema converte alguns processadores configurados usando a API em processadores do Bindplane e mostra outros no formato bruto da linguagem de transformação do OpenTelemetry (OTTL). É possível usar o console do Bindplane para editar pipelines e processadores configurados anteriormente com a API.
Depois de criar uma conexão com uma instância do Google SecOps, você poderá configurar o processamento de dados.
Configurar o processamento de dados usando o console do Bindplane
Nesta seção, descrevemos como provisionar e implantar um novo pipeline de processamento de registros no Google SecOps usando o console do Bindplane. Também é possível usar o console do Bindplane para gerenciar pipelines configurados anteriormente com a API.
Criar um pipeline do Google SecOps
Um pipeline do Google SecOps é um contêiner para configurar um contêiner de processamento de dados. Para criar um novo contêiner de pipeline do Google SecOps, faça o seguinte:
- No console do Bindplane, clique na guia Pipelines do SecOps para abrir a página Pipelines do SecOps.
- Clique em Criar pipeline de SecOps.
Insira um Nome do pipeline de SecOps e uma Descrição.
Clique em Criar. O novo contêiner de pipeline aparece na página Pipelines do SecOps.
Configure os fluxos e processadores de contêiner de processamento de dados nesse contêiner.
Configurar um contêiner de tratamento de dados
Um contêiner de processamento de dados define os fluxos a serem ingeridos e os processadores a serem aplicados antes que os dados cheguem ao destino.
Configure os fluxos e nós de processador no card de configuração do pipeline.
Para configurar um contêiner de processamento de dados, faça o seguinte:
- Se ainda não tiver feito isso, crie um novo pipeline do Google SecOps.
- No console do Bindplane, clique na guia Pipelines do SecOps para abrir a página Pipelines do SecOps.
- Selecione o pipeline do Google SecOps em que você quer configurar o novo contêiner de tratamento de dados.
No card de configuração Pipeline:
- Adicione um fluxo.
- Configure o nó de processador. Para adicionar um processador usando o console do Bindplane, consulte Configurar processadores para mais detalhes.
Depois de concluir essas configurações, consulte Implantar o processamento de dados para começar a processar os dados.
Adicionar um stream
Para adicionar um stream, faça o seguinte:
- No card de configuração Pipeline, clique em adicionar Adicionar fluxo para abrir a janela Adicionar fluxo.
Na janela Adicionar stream, insira detalhes para estes campos:
Campo Descrição Tipo de registro Selecione o tipo de registro dos dados a serem ingeridos. Por exemplo, CrowdStrike Falcon (CS_EDR).
Observação: um ícone de aviso Aviso indica que o tipo de registro já está configurado em outro fluxo (neste pipeline ou em outro na sua instância do Google SecOps).
Para usar um tipo de registro indisponível, primeiro exclua-o da outra configuração de stream.
Para instruções sobre como encontrar a configuração de fluxo em que o tipo de registro está configurado, consulte Filtrar configurações de pipeline do SecOps.Método de ingestão Selecione o método de ingestão que será usado para ingerir os dados do tipo de registro selecionado. Esses métodos de ingestão foram definidos anteriormente para sua instância do Google SecOps.
Selecione uma das seguintes opções:
- Todos os métodos de ingestão: inclui todos os métodos de ingestão para o tipo de registro selecionado. Ao selecionar essa opção, você não poderá adicionar streams subsequentes que usam métodos de ingestão específicos para o mesmo tipo de registro. Exceção: é possível selecionar outros métodos de ingestão específicos não configurados para esse tipo de registro em outros fluxos.
- Método de ingestão específico, como
Cloud Native Ingestion,Feed,Ingestion APIouWorkspace Ingestion.
Feed Se você selecionar Feedcomo o método de ingestão, um campo vai aparecer com uma lista de nomes de feeds disponíveis (pré-configurados na sua instância do Google SecOps) para o tipo de registro selecionado. Selecione o feed relevante para concluir a configuração. Para ver e gerenciar seus feeds disponíveis, acesse Configurações do SIEM > Tabela de feeds.- Todos os métodos de ingestão: inclui todos os métodos de ingestão para o tipo de registro selecionado. Ao selecionar essa opção, você não poderá adicionar streams subsequentes que usam métodos de ingestão específicos para o mesmo tipo de registro. Exceção: é possível selecionar outros métodos de ingestão específicos não configurados para esse tipo de registro em outros fluxos.
Clique em Adicionar fluxo de dados para salvar o novo fluxo de dados.O novo fluxo de dados aparece imediatamente no card de configuração Pipeline. O fluxo é conectado automaticamente ao nó do processador e ao destino do Google SecOps.
Filtrar configurações de pipeline do SecOps
A barra de pesquisa na página Pipelines do SecOps permite filtrar e localizar seus pipelines do Google SecOps (contêineres de processamento de dados) com base em vários elementos de configuração. É possível filtrar pipelines pesquisando critérios específicos, como tipo de registro, método de ingestão ou nome do feed.
Use a seguinte sintaxe para filtrar:
logType:valueingestionMethod:valuefeed:value
Por exemplo, para identificar configurações de stream que contêm um tipo de registro específico, digite logtype: na barra de pesquisa e selecione o tipo de registro na lista resultante.
Configurar processadores
Um contêiner de tratamento de dados tem um nó de processador, que contém um ou mais processadores. Cada processador manipula os dados de fluxo de forma sequencial:
- O primeiro processador processa os dados brutos de stream.
- A saída resultante do primeiro processador se torna imediatamente a entrada para o próximo processador na sequência.
- Essa sequência continua para todos os processadores subsequentes, na ordem exata em que aparecem no painel Processadores, com a saída de um se tornando a entrada do próximo.
- Configure o nó do processador adicionando, removendo ou mudando a sequência de um ou mais processadores.
A tabela a seguir lista os processadores:
| Tipo de processador | Capacidade |
|---|---|
| Filtro | Filtrar por condição |
| Filtro | Filtrar por status HTTP |
| Filtro | Filtrar por nome da métrica |
| Filtro | Filtrar por regex |
| Filtro | Filtrar por gravidade |
| Encobrimento | encobrir dados sensíveis |
| Transformar | Adicionar campos |
| Transformar | Coalesce |
| Transformar | Concat |
| Transformar | Copiar campo |
| Transformar | Excluir campos |
| Transformar | Marshal |
| Transformar | Mover campo |
| Transformar | Analisar CSV |
| Transformar | Analisar JSON |
| Transformar | Analisar chave-valor |
| Transformar | Analisar campos de gravidade |
| Transformar | Analisar carimbo de data/hora |
| Transformar | Analisar com regex |
| Transformar | Analisar XML |
| Transformar | renomear campos; |
| Transformar | Reescrever carimbo de data/hora |
| Transformar | Divisão |
| Transformar | Transformar |
Adicionar um processador
Para adicionar um processador, siga estas etapas:
No card de configuração Pipeline, clique no nó Processador para abrir a janela Editar processadores. A janela Editar processadores é dividida nestes painéis, organizados por fluxo de dados:
- Entrada (ou dados de origem): dados de registro de stream recebidos recentemente (antes do processamento)
- Configuração (ou lista de processadores): processadores e configurações deles.
- Saída (ou resultados): dados recentes de registro de resultados de saída (após o processamento)
Se o pipeline já tiver sido lançado, o sistema vai mostrar os dados de registro de entrada recentes (antes do processamento) e os dados de registro de saída recentes (após o processamento) nos painéis.
Clique em Adicionar processador para mostrar a lista de processadores. Para sua conveniência, a lista de processadores é agrupada por tipo. Para organizar a lista e adicionar seus próprios pacotes, selecione um ou mais processadores e clique em Adicionar novos pacotes de processadores.
Na lista de processadores, selecione um Processador para adicionar.
Configure o processador conforme necessário.
Clique em Salvar para salvar a configuração do processador no nó Processador.
O sistema testa imediatamente a nova configuração processando uma nova amostra dos dados de fluxo de entrada (no painel Entrada) e mostra os dados de saída resultantes no painel Saída.
Implantar pipeline de tratamento de dados
Depois que as configurações de stream e processador forem concluídas, implante o pipeline para começar a processar os dados:
- Clique em Iniciar lançamento. Isso ativa imediatamente o tratamento de dados e permite que a infraestrutura do Google comece a processar dados de acordo com sua configuração. Se o lançamento for bem-sucedido, o número da versão do contêiner de tratamento de dados será incrementado e exibido ao lado do
namedo contêiner.
Configurar o tratamento de dados usando métodos de API
Como alternativa ao console do Bindplane, use os métodos do pipeline de dados do Google SecOps para gerenciar seus dados processados. Esses métodos incluem criar, atualizar, excluir e listar pipelines, além de associar feeds e tipos de registros a eles.
Para usar os exemplos nesta seção, faça o seguinte:
- Substitua os parâmetros específicos do cliente (por exemplo, URLs e IDs de feed) por parâmetros adequados ao seu ambiente.
- Insira sua própria autenticação. Nesta seção, os tokens de portador são editados com
******.
Listar todos os pipelines em uma instância específica do Google SecOps
O comando a seguir lista todos os pipelines que existem em uma instância específica do Google SecOps:
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
Criar um pipeline básico com um processador
Para criar um pipeline básico com um único processador de transformação que insere ou atualiza o valor de um rótulo de ingestão personalizado e associa três fontes a ele, faça o seguinte:
Execute este comando:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'Na resposta, copie o valor do campo
name.Execute o comando a seguir para associar três fluxos (tipo de registro, tipo de registro com ID do coletor e feed) ao pipeline. Use o valor do campo
namecomo o valor de{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Criar um pipeline com três processadores
Um pipeline usa os seguintes processadores:
- Filtro: filtra os registros que correspondem a uma condição com base nos rótulos de ingestão.
- Transformação: faz um upsert do valor do namespace.
- Encobrimento: encobre endereços de e-mail e números de CPF ou CNPJ dos dados de registro com base em padrões regex personalizados.
Para criar um pipeline e associar três fontes a ele, faça o seguinte:
Execute este comando:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'Na resposta, copie o valor do campo
name.Execute o comando a seguir para associar três fluxos (tipo de registro, tipo de registro com ID do coletor e feed) ao pipeline. Use o valor do campo
namecomo o valor de{pipelineName}.curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
Solução de problemas
Esta seção descreve as expectativas de desempenho e oferece correções de autoatendimento para problemas comuns.
Latência e limites
Se você configurar um agente usando a API Ingestion, poderá ter tempos de confirmação mais longos para pipelines de baixo volume do Google SecOps.
As médias de latência podem aumentar de 700 ms para até 2 segundos. Aumente os períodos de tempo limite e a memória conforme necessário. O tempo de confirmação diminui quando a capacidade de processamento de dados excede 4 MB.
Validação e teste
É possível conferir os detalhes do tratamento de dados no console do Google SecOps:
Ver todas as configurações de tratamento de dados
- No console do Google SecOps, acesse Configurações do SIEM > Tratamento de dados, onde é possível conferir todos os pipelines configurados.
- Na barra de pesquisa Pipelines de dados de entrada, procure qualquer pipeline que você criou. É possível pesquisar por elementos, como nome do pipeline ou componentes. Os resultados da pesquisa mostram os processadores do pipeline e um resumo da configuração.
- No resumo do pipeline, você pode fazer qualquer uma das seguintes ações:
- Revise as configurações do processador.
- Copie os detalhes da configuração.
- Clique em Abrir no Bindplane para acessar e gerenciar o pipeline diretamente no console do Bindplane.
Ver feeds configurados
Para ver os feeds configurados no seu sistema, faça o seguinte:
- No console do Google SecOps, acesse Configurações do SIEM > Feeds. A página Feeds mostra todos os feeds que você configurou no sistema.
- Mantenha o ponteiro sobre cada linha para mostrar o menu ⋮ Mais, onde é possível ver detalhes, editar, desativar ou excluir o feed.
- Clique em Ver detalhes para abrir a janela de detalhes.
- Clique em Abrir no Bindplane para abrir a configuração de stream desse feed no console do Bindplane.
Ver detalhes do tratamento de dados para tipos de registros disponíveis
Para conferir detalhes do tratamento de dados na página Tipos de registros disponíveis, onde você pode ver todos os tipos de registros disponíveis, faça o seguinte:
- No console do Google SecOps, acesse Configurações do SIEM > Tipos de registros disponíveis. A página principal mostra todos os tipos de registros.
- Mantenha o ponteiro sobre cada linha do feed para mostrar o menu more_vert Mais. Nesse menu, é possível ver, editar, desativar ou excluir detalhes do feed.
- Clique em Ver processamento de dados para conferir a configuração do feed.
- Clique em Abrir no Bindplane para abrir a configuração do processador no console do Bindplane.
Precisa de mais ajuda? Receba respostas de membros da comunidade e profissionais do Google SecOps.