
管理数据处理流水线
本文档可帮助安全工程师在 Google SecOps 中设置和管理数据处理流水线,以便在提取事件之前过滤事件、转换字段或编辑敏感值。此功能可对数据注入流程提供强大的预解析控制。按照本指南中推荐的方法操作,您可以优化数据兼容性、降低成本,并保护 Google SecOps 中的敏感信息。
数据处理通过以下核心操作简化了日志管理:
- 过滤:仅提取相关事件,从而减少干扰和费用。
- 转换:修改数据格式、解析字段和丰富日志,以提高可用性。
- Redact:在存储之前,通过遮盖或移除敏感值来保护敏感信息。
下图说明了数据如何流入 Google SecOps 以及系统如何处理这些数据:
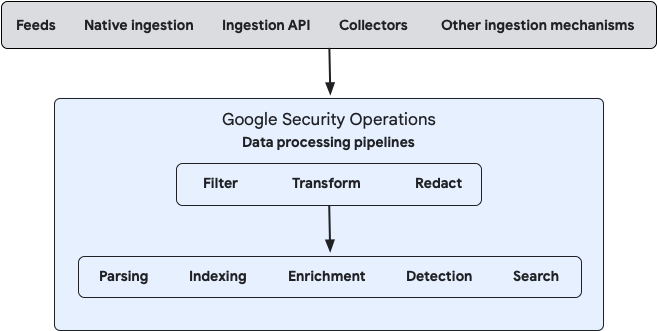
您可以使用 Bindplane 管理控制台或直接使用公共 Google SecOps 数据管道 API 来配置本地数据流和云数据流的数据处理。
常见使用场景
数据处理的示例使用场景包括:
- 从原始日志中移除空键值对。
- 隐去敏感数据。
- 从原始日志内容添加注入标签。
- 在多实例环境中,将注入标签应用于直接注入的日志数据,以识别源数据流实例(例如Google Cloud Workspace)。
- 按字段值过滤 Palo Alto Cortex 数据。
- 按类别减少 SentinelOne 数据。
- 从 Feed 和直接提取日志中提取主机信息,并将其映射到 Cloud Monitoring 的
ingestion_source字段。
主要术语
数据处理使用以下元素:
- 数据流:一种特定的数据流,由日志类型和提取来源(例如 Feed 或 API)定义,用作数据处理流水线的输入。
- 处理器节点:流水线中包含一个或多个处理器(例如过滤、转换或编辑操作)的组件。这些处理器会按顺序处理通过节点的数据。
- 目的地:数据处理流水线的端点,通常是 Google SecOps 实例,处理后的数据会发送到该实例以进行最终注入和分析。
准备工作
在开始设置数据处理流水线之前,请查看以下要求:
- 解析器和 UDM 影响:数据处理流水线会在原始日志数据到达 Google SecOps 解析器之前对其进行修改。这些修改可能会影响解析器解读日志并将其转换为统一数据模型 (UDM) 格式的方式。在为 Feed 或日志类型启用流水线之前,请验证您的过滤、转换或遮盖规则是否会无意中以某种方式更改数据,从而导致解析器无法生成正确的 UDM 事件。
- API 支持:通过调用 Chronicle API,可以对基于推送的数据流进行数据处理。在数据处理管理器 (DPM) 中配置的过滤条件会在 Chronicle Ingestion API 收到数据后应用。因此,这些过滤条件不会阻止客户达到 Ingestion API 配额和限制(例如 importPushLog API 限制),因为这些限制是在 DPM 过滤之前进行评估的。为了有效管理数据并遵守 Ingestion API 限制,客户应在数据源本身中实现过滤,而不是依赖 DPM 过滤器。
- 数据可见性:从转发器和 Bindplane 注入的数据会标记一个与直接注入流不同的唯一
collectorID。为了支持完整的日志可见性,您必须在查询数据源时选择所有提取方法,或者在与 API 互动时明确引用相关的collectorID。 Bindplane 控制台设置:如果您打算使用 Bindplane 控制台进行设置和管理,请完成以下步骤:
在 Google SecOps 控制台中,向将用于配置 Bindplane 集成的用户或服务账号授予以下角色之一:
具有以下权限的自定义角色:
chronicle.logProcessingPipelines.associateStreamschronicle.logProcessingPipelines.createchronicle.logProcessingPipelines.deletechronicle.logProcessingPipelines.dissociateStreamschronicle.logProcessingPipelines.fetchAssociatedPipelinechronicle.logProcessingPipelines.fetchSampleLogsByStreamschronicle.logProcessingPipelines.getchronicle.logProcessingPipelines.listchronicle.logProcessingPipelines.testPipelinechronicle.logProcessingPipelines.updatechronicle.logTypes.getchronicle.logTypes.listchronicle.feeds.getchronicle.feeds.listchronicle.logs.listchronicle.parsers.list:仅当您使用 Bindplane 的 Validate SecOps Parser 操作时,才需要此权限。chronicle.parsers.runParser:仅当您使用 Bindplane 的 Validate SecOps Parser 操作时,才需要此权限。
我们建议使用具有指定所需权限的自定义角色。
如需了解详情,请参阅创建和管理自定义角色和使用 IAM 配置功能访问权限控制。
预定义的 Chronicle API Admin
roles/chronicle.admin角色。有关详情,请参阅在专用项目中分配 Project IAM Admin 角色。
安装 Bindplane 服务器控制台。对于 SaaS 或本地,请参阅安装 Bindplane Server 控制台。 确保您安装的是最新版本的 Bindplane(或 Bindplane 版本 1.96.4 或更高版本)。
在 Bindplane 控制台中,将 Google SecOps 目标实例连接到您的 Bindplane 项目。如需了解详情,请参阅连接到 Google SecOps 实例。
连接到 Google SecOps 实例
在开始之前,请确认您拥有 Bindplane 项目管理员权限,可以访问项目集成页面。
Google SecOps 实例用作数据输出的目标位置。
如需使用 Bindplane Server 控制台连接到 Google SecOps 实例,请执行以下操作:
- 在 Bindplane Server 控制台中,点击 Menu,然后选择 Project Settings。
- 在项目设置页面上,前往集成卡片,然后点击关联到 Google SecOps 以打开修改集成窗口。
输入 Google SecOps 目标实例的详细信息。
此实例会接收处理后的数据(数据处理的输出),如下所示:字段 说明 区域 Google SecOps 实例的区域。
如需在 Google Cloud 控制台中查找实例,请依次前往安全性 > 检测和控制 > Google Security Operations > 实例详情。客户 ID Google SecOps 实例的客户 ID。
在 Google SecOps 控制台中,依次前往 SIEM 设置 > 个人资料 > 组织详情。Google Cloud 项目编号 Google Cloud Google SecOps 实例的项目编号。
如需在 Google SecOps 控制台中查找项目编号,请依次前往 SIEM 设置 > 个人资料 > 组织详情。凭据 服务账号凭据是用于验证身份并访问 Google SecOps Data Pipeline API 所需的 JSON 值。从 Google 服务账号凭据文件中获取此 JSON 值。
服务账号必须位于与 Google SecOps 实例相同的 Google Cloud 项目中,并且需要 Chronicle API Admin 角色 (roles/chronicle.admin) 权限或具有所需权限的自定义角色(请参阅前提条件)。
如需了解如何创建服务账号并下载 JSON 文件,请参阅创建和删除服务账号密钥。
或者,Bindplane Cloud 部署支持使用工作负载身份联合 (WIF) 进行身份验证。自托管的 Bindplane 部署不支持 WIF。如需了解详情,请参阅将 Google SecOps 集成与 WIF 身份验证相关联。点击连接。如果您的连接详细信息正确无误,并且您已成功连接到 Google SecOps,则可以预期会发生以下情况:
- 系统会打开与 Google SecOps 实例的连接。
- 首次连接时,Bindplane 控制台中会显示 SecOps Pipelines 标签页。
- Bindplane 控制台会显示您之前使用 API 为此实例设置的所有已处理数据。系统会将您使用该 API 配置的部分处理器转换为 Bindplane 处理器,并以原始 OpenTelemetry Transformation Language (OTTL) 格式显示其他处理器。您可以使用 Bindplane 控制台修改之前使用 API 设置的流水线和处理器。
成功创建与 Google SecOps 实例的连接后,您就可以开始设置数据处理。
使用 Bindplane 控制台设置数据处理
本部分介绍了如何使用 Bindplane 控制台在 Google SecOps 中预配和部署新的日志处理流水线。您还可以使用 Bindplane 控制台管理之前使用 API 设置的流水线。
创建新的 Google SecOps 流水线
Google SecOps 流水线是一个容器,您可以在其中配置一个数据处理容器。如需创建新的 Google SecOps 流水线容器,请执行以下操作:
- 在 Bindplane 控制台中,点击 SecOps 流水线标签页,打开 SecOps 流水线页面。
- 点击创建 SecOps 流水线。
输入 SecOps 流水线名称和说明。
点击创建。您可以在 SecOps 流水线页面上看到新的流水线容器。
配置此容器内的数据处理容器流和处理器。
配置数据处理容器
数据处理容器定义了要提取的数据流以及在数据到达目标位置之前要应用的处理器。
在流水线配置卡上配置流和处理器节点。
如需配置数据处理容器,请执行以下操作:
- 如果您尚未创建 Google SecOps 流水线,请创建一个新的流水线。
- 在 Bindplane 控制台中,点击 SecOps 流水线标签页,打开 SecOps 流水线页面。
- 选择要配置新数据处理容器的 Google SecOps 流水线。
在流水线配置卡片上:
完成这些配置后,请参阅推出数据处理功能,开始处理数据。
添加数据流
如需添加直播,请执行以下操作:
- 在流水线配置卡片中,点击 添加 图标 添加数据流,打开添加数据流窗口。
在添加数据流窗口中,输入以下字段的详细信息:
字段 说明 日志类型 选择要注入的数据的日志类型。例如 CrowdStrike Falcon (CS_EDR)。
注意: 警告 警告图标表示相应日志类型已在另一个数据流(在此流水线中或 Google SecOps 实例中的另一个流水线中)中配置。
如需使用不可用的日志类型,您必须先从其他数据流配置中将其删除。
如需了解如何查找配置了日志类型的流配置,请参阅过滤 SecOps 流水线配置。注入方法 选择用于注入所选日志类型的数据的注入方法。这些提取方法之前已为您的 Google SecOps 实例定义。
您必须选择以下选项之一:
- 所有提取方法:包括所选日志类型的所有提取方法。选择此选项后,您将无法为同一日志类型添加使用特定提取方法的后续数据流。例外情况:您可以在其他数据流中为此日志类型选择其他未配置的特定提取方法。
- 特定提取方法,例如
Cloud Native Ingestion、Feed、Ingestion API或Workspace Ingestion。
Feed 如果您选择 Feed作为注入方法,系统随后会显示一个字段,其中包含所选日志类型的可用 Feed 名称(在您的 Google SecOps 实例中预配置)。您必须选择相关 Feed 才能完成配置。如需查看和管理可用的 Feed,请前往 SIEM 设置 >“Feed”表格。- 所有提取方法:包括所选日志类型的所有提取方法。选择此选项后,您将无法为同一日志类型添加使用特定提取方法的后续数据流。例外情况:您可以在其他数据流中为此日志类型选择其他未配置的特定提取方法。
点击添加数据流以保存新数据流。新数据流会立即显示在流水线配置卡片上。该数据流会自动连接到处理器节点和 Google SecOps 目标位置。
过滤 SecOps 流水线配置
您可以使用 SecOps 流水线页面上的搜索栏,根据多个配置元素过滤和查找 Google SecOps 流水线(数据处理容器)。您可以搜索特定条件(例如日志类型、提取方法或 Feed 名称)来过滤流水线。
使用以下语法进行过滤:
logType:valueingestionMethod:valuefeed:value
例如,如需识别包含特定日志类型的流配置,请在搜索栏中输入 logtype:,然后从结果列表中选择相应日志类型。
配置处理器
数据处理容器具有一个处理器节点,该节点包含一个或多个处理器。每个处理器按顺序处理流数据:
- 第一个处理器处理原始流数据。
- 第一个处理器的输出结果会立即成为序列中下一个处理器的输入。
- 此序列会按 Processors 窗格中显示的顺序继续处理所有后续处理器,其中一个处理器的输出会成为下一个处理器的输入。
- 通过添加、移除或更改一个或多个处理器的顺序来配置处理器节点。
下表列出了处理器:
| 处理器类型 | 能力 |
|---|---|
| 过滤 | 按条件过滤 |
| 过滤 | 按 HTTP 状态过滤 |
| 过滤 | 按指标名称过滤 |
| 过滤 | 按正则表达式过滤 |
| 过滤 | 按严重程度过滤 |
| 隐去 | 隐去敏感数据 |
| 转换 | 添加字段 |
| 转换 | 合并 |
| 转换 | Concat |
| 转换 | 复制字段 |
| 转换 | 删除字段 |
| 转换 | Marshal |
| 转换 | 移动字段 |
| 转换 | 解析 CSV |
| 转换 | 解析 JSON |
| 转换 | 解析键值 |
| 转换 | 解析严重程度字段 |
| 转换 | 解析时间戳 |
| 转换 | 使用正则表达式进行解析 |
| 转换 | 解析 XML |
| 转换 | 重命名字段 |
| 转换 | 重写时间戳 |
| 转换 | 拆分 |
| 转换 | 转换 |
添加处理器
如需添加处理器,请按以下步骤操作:
在流水线配置卡片中,点击处理器节点以打开修改处理器窗口。 修改处理器窗口分为以下窗格,按数据传输排列:
- 输入(或源数据):最近传入的流日志数据(处理前)
- 配置(或处理器列表):处理器及其配置
- 输出(或结果):最近的传出结果日志数据(处理后)
如果流水线之前已推出,系统会在窗格中显示最近的传入日志数据(处理前)和最近的传出日志数据(处理后)。
点击添加处理器以显示处理器列表。 为方便起见,处理器列表按处理器类型分组。如需整理列表并添加您自己的处理器软件包,请选择一个或多个处理器,然后点击添加新的处理器软件包。
在处理器列表中,选择要添加的处理器。
根据需要配置处理器。
点击保存,以将处理器配置保存在处理器节点中。
系统会立即处理来自输入窗格的传入流数据的新鲜样本,从而测试新配置,并在输出窗格中显示生成的传出数据。
推出数据处理流水线
完成数据流和处理器配置后,您必须推出流水线才能开始处理数据:
- 点击开始发布。这会立即激活数据处理,并让 Google 的基础架构开始根据您的配置处理数据。如果发布成功,数据处理容器的版本号会递增,并显示在容器的
name旁边。
使用 API 方法设置数据处理
除了使用 Bindplane 控制台之外,您还可以使用 Google SecOps 数据流水线方法来管理处理后的数据。这些数据流水线方法包括创建、更新、删除和列出流水线,以及将 Feed 和日志类型与流水线相关联。
如需使用本部分中的示例,请执行以下操作:
- 将特定于客户的参数(例如网址和 Feed ID)替换为适合您自己环境的参数。
- 插入您自己的身份验证。在本部分中,不记名令牌已使用
******进行编辑。
列出特定 Google SecOps 实例中的所有流水线
以下命令会列出特定 Google SecOps 实例中的所有流水线:
curl --location 'https://abc.def.googleapis.com/v123/'\
'projects/projectabc-byop/locations/us/'\
'instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/'\
'logProcessingPipelines' \
--header 'Authorization: Bearer ******'
创建包含一个处理器的基本流水线
如需创建包含单个转换处理器的基本流水线,该处理器会更新自定义提取标签的值,并将三个来源与该流水线相关联,请执行以下操作:
运行以下命令:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "displayName": "Example Pipeline", "description": "My description", "processors": [ { "transformProcessor": { "statements": [ "set(attributes[\"labels.myLabel.value\"], \"myValue\")" ] } } ] }'从响应中复制
name字段的值。运行以下命令,将三个数据流(日志类型、带有收集器 ID 的日志类型和 Feed)与流水线相关联。使用
name字段的值作为{pipelineName}值。curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
创建包含三个处理器的流水线
流水线使用以下处理器:
- 过滤:根据提取标签过滤掉符合条件的日志。
- 转换:更新或插入命名空间值。
- 隐去:根据自定义正则表达式模式,从日志数据中隐去电子邮件地址和社会保障号。
如需创建流水线并将其与三个来源相关联,请执行以下操作:
运行以下命令:
curl --location 'https://abc.def.googleapis.com/v123/projects/projectabc-byop/locations/us/instances/aaaa1aa1-111a-11a1-1111-11111a1aa1aa/logProcessingPipelines' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data-raw '{ "displayName": "My Pipeline 2", "description": "My description 2", "processors": [ { "filterProcessor": { "logConditions": [ "attributes[\"labels.log_source.value\"] == \"myLogSourceToFilterOut\"" ] } }, { "transformProcessor": { "statements": [ "set(attributes[\"environment_namespace\"], \"myValue\")" ] } }, { "redactProcessor": { "blockedValues": [ "\\b\\d{3}[- ]\\d{2}[- ]\\d{4}\\b", "\\b[a-zA-Z0-9._/\\+\\-—|]+@[A-Za-z0-9\\-—|]+\\.[a-zA-Z|]{2,6}\\b" ], "allowAllKeys": true } } ] }'从响应中复制
name字段的值。运行以下命令,将三个数据流(日志类型、带有收集器 ID 的日志类型和 Feed)与流水线相关联。使用
name字段的值作为{pipelineName}值。curl --location 'https://abc.def.googleapis.com/v123/{pipelineName}:associateStreams' \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer ******' \ --data '{ "streams": [ { "logType": "MICROSOFT_SENTINEL" }, { "logType": "A10_LOAD_BALANCER", "collectorId": "dddddddd-dddd-dddd-dddd-dddddddddddd" }, { "feed": "1a1a1a1a-1a1a-1a1a-1a1a-1a1a1a1a1a1a" } ] }'
问题排查
本部分概述了性能预期,并针对常见问题提供了自助式修复方案。
延迟时间和限制
如果您使用 Ingestion API 配置代理,则低容量 Google SecOps 流水线的确认时间可能会更长。
平均延迟时间可能会从 700 毫秒增加到 2 秒。根据需要增加超时时间和内存。当数据吞吐量超过 4 MB 时,确认时间会缩短。
验证和测试
您可以在 Google SecOps 控制台中查看数据处理详情:
查看所有数据处理配置
- 在 Google SecOps 控制台中,前往 SIEM 设置 > 数据处理,您可以在其中查看所有已配置的流水线。
- 在入站数据流水线搜索栏中,搜索您构建的任何流水线。您可以按元素(例如流水线名称或组件)进行搜索。搜索结果会显示流水线的处理器及其配置摘要。
- 在流水线摘要中,您可以执行以下任一操作:
- 查看处理器配置。
- 复制配置详细信息。
- 点击 Open in Bindplane(在 Bindplane 中打开),即可直接在 Bindplane 控制台中访问和管理流水线。
查看已配置的 Feed
如需查看系统中的已配置 Feed,请执行以下操作:
- 在 Google SecOps 控制台中,前往 SIEM 设置 > Feed。Feed 页面会显示您在系统中配置的所有 Feed。
- 将指针悬停在每个行上,以显示 ⋮ 更多菜单,您可以在其中查看 Feed 详细信息、修改、停用或删除 Feed。
- 点击查看详情可查看详情窗口。
- 点击 Open in Bindplane(在 Bindplane 中打开),在 Bindplane 控制台中打开相应 Feed 的数据流配置。
查看可用日志类型的数据处理详情
如需在可用日志类型页面上查看数据处理详情(您可以在该页面上查看所有可用的日志类型),请执行以下操作:
- 在 Google SecOps 控制台中,前往 SIEM 设置 > 可用的日志类型。主页面会显示您的所有日志类型。
- 将指针悬停在每个 Feed 行上,以显示 more_vert 更多菜单。您可以通过此菜单查看、修改、停用或删除 Feed 详细信息。
- 点击查看数据处理以查看 Feed 的配置。
- 点击 Open in Bindplane(在 Bindplane 中打开),在 Bindplane 控制台中打开相应处理器的处理器配置。
需要更多帮助?获得社区成员和 Google SecOps 专业人士的解答。