

Gemini Enterprise Agent Platform 提供代管訓練服務,協助您大規模訓練模型。您可以使用 Gemini Enterprise Agent Platform,在Google Cloud 基礎架構上,根據任何機器學習 (ML) 框架執行訓練應用程式。對於下列熱門的機器學習框架,Gemini Enterprise Agent Platform 也整合了支援功能,可簡化模型訓練和服務的準備程序:
本頁面說明在 Gemini Enterprise Agent Platform 上進行無伺服器訓練的優點、相關工作流程,以及各種可用的訓練選項。
Gemini Enterprise Agent Platform 可大規模訓練模型
模型訓練作業化有幾項挑戰,包括訓練模型所需的時間和成本、管理運算基礎架構所需的技能深度,以及提供企業級安全性的需求。Gemini Enterprise Agent Platform 可解決這些挑戰,同時提供許多其他優點。
全代管運算基礎架構
|
|
在 Gemini Enterprise Agent Platform 上訓練模型是全代管服務,不需要管理實體基礎架構。您可以訓練機器學習模型,無須佈建或管理伺服器。您只需要為耗用的運算資源付費。Gemini Enterprise Agent Platform 也會處理工作記錄、排隊和監控作業。 |
講求高效能
|
|
Gemini Enterprise Agent Platform 訓練作業專為機器學習模型訓練最佳化,因此效能可能比直接在 Google Kubernetes Engine (GKE) 叢集上執行訓練應用程式更快。您也可以使用 Cloud Profiler 找出訓練工作的效能瓶頸並進行偵錯。 |
分散式訓練
|
|
Reduction Server是 Gemini Enterprise Agent Platform 中的全縮減演算法,可提高處理量,並縮短 NVIDIA 圖形處理器 (GPU) 多節點分散式訓練的延遲時間。這項最佳化功能有助於縮短完成大型訓練作業的時間,並降低成本。 |
超參數最佳化
|
|
超參數調整工作會使用不同的超參數值,對訓練應用程式執行多項試驗。您指定要測試的值範圍,Gemini Enterprise Agent Platform 會在該範圍內找出模型的最佳值。 |
企業安全
|
|
Gemini Enterprise Agent Platform 提供下列企業安全功能:
|
機器學習作業 (MLOps) 整合
|
|
Gemini Enterprise Agent Platform 提供一系列整合式 MLOps 工具和功能,可用於下列用途:
|
無伺服器訓練工作流程
下圖顯示 Gemini Enterprise Agent Platform 無伺服器訓練工作流程的概要總覽。接下來的章節將詳細說明每個步驟。
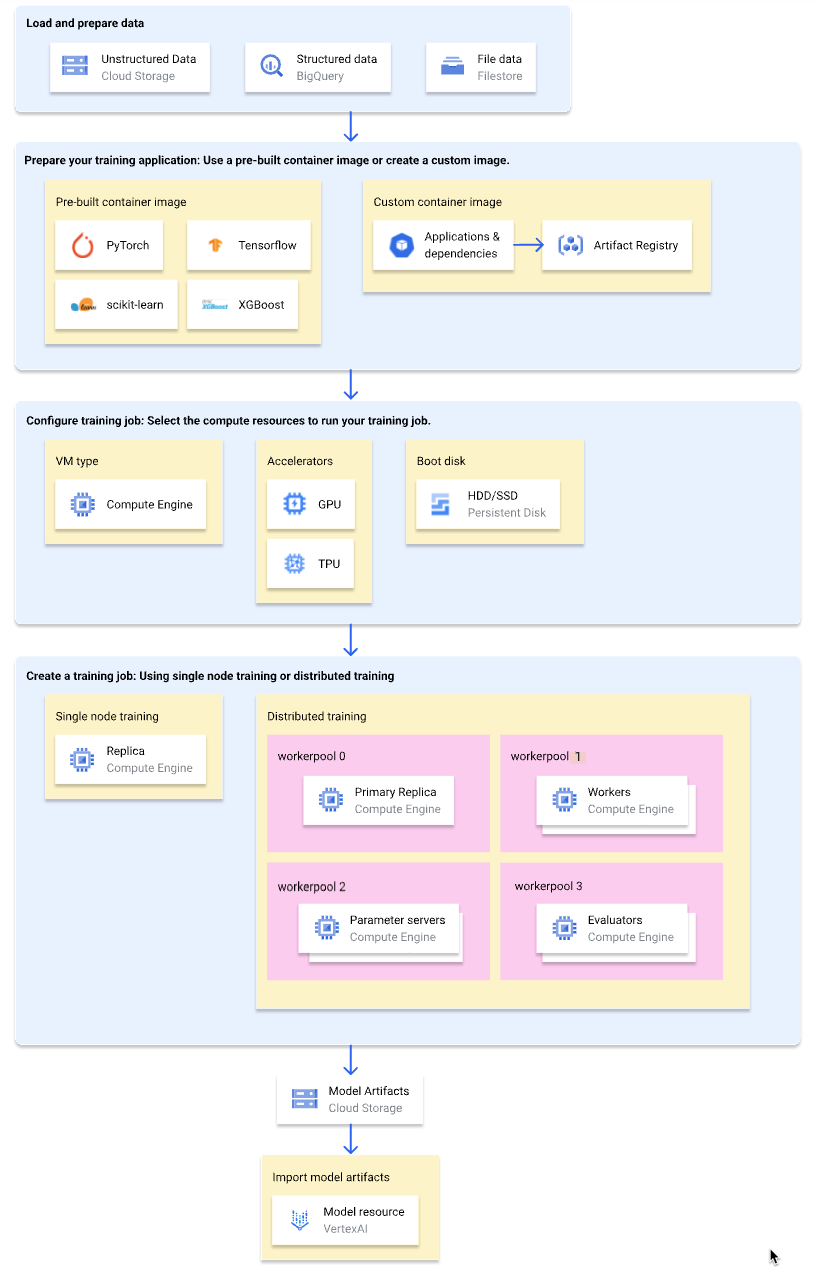
載入及準備訓練資料
為獲得最佳效能和支援服務,請使用下列 Google Cloud 其中一項服務做為資料來源:
- Cloud Storage
- BigQuery
- 高效能檔案系統,例如 Google Cloud 上的 NFS 共用,使用 Google Cloud NetApp Volumes 或 Filestore 等服務。
如要比較這些服務,請參閱「資料準備總覽」。
使用訓練管道訓練模型時,您也可以指定 Gemini Enterprise Agent Platform 管理的資料集做為資料來源。使用相同資料集訓練自訂模型和 AutoML 模型,即可比較這兩個模型的效能。
準備訓練應用程式
如要準備訓練應用程式,以便在 Gemini Enterprise Agent Platform 上使用,請按照下列步驟操作:
- 為 Gemini Enterprise Agent Platform 導入訓練程式碼最佳做法。
- 決定要使用的容器映像檔類型。
- 根據所選容器映像檔類型,將訓練應用程式封裝為支援的格式。
實作訓練程式碼最佳做法
訓練應用程式應實作 Gemini Enterprise Agent Platform 的訓練程式碼最佳做法。這些最佳做法與訓練應用程式的下列功能相關:
- 存取 Google Cloud 服務。
- 載入輸入資料。
- 啟用自動記錄功能,追蹤實驗。
- 匯出模型構件。
- 使用 Gemini Enterprise Agent Platform 的環境變數。
- 確保 VM 重新啟動後仍可正常運作。
選取容器類型
Gemini Enterprise Agent Platform 會在 Docker 容器映像檔中執行訓練應用程式。Docker 容器映像檔是獨立的軟體套件,內含程式碼和所有依附元件,幾乎可在任何運算環境中執行。您可以指定要使用的預先建構容器映像檔的 URI,也可以建立並上傳自訂容器映像檔,其中已預先安裝訓練應用程式和依附元件。
下表列出預先建構和自訂容器映像檔的差異:
| 規格 | 預先建構的容器映像檔 | 自訂容器映像檔 |
|---|---|---|
| 機器學習框架 | 每個容器映像檔都專為 ML 架構而設計。 | 使用任何機器學習架構,或不使用任何架構。 |
| 機器學習架構版本 | 每個容器映像檔都適用於特定 ML 架構版本。 | 使用任何機器學習框架版本,包括次要版本和夜間建構版本。 |
| 應用程式依附元件 | 系統會預先安裝機器學習架構的常見依附元件。您可以指定要在訓練應用程式中安裝的其他依附元件。 | 預先安裝訓練應用程式所需的依附元件。 |
| 應用程式發布格式 |
|
在自訂容器映像檔中預先安裝訓練應用程式。 |
| 設定難易度 | Low | 高 |
| 推薦學習對象 | 以機器學習架構和架構版本為基礎的 Python 訓練應用程式,且有可用的預先建構容器映像檔。 |
|
封裝訓練應用程式
決定要使用的容器映像檔類型後,請根據容器映像檔類型,將訓練應用程式封裝成下列其中一種格式:
可在預先建構的容器中使用的單一 Python 檔案
將訓練應用程式編寫為單一 Python 檔案,並使用 Agent Platform SDK for Python 建立
CustomJob或CustomTrainingJob類別。Python 檔案會封裝到 Python 來源發行套件中,並安裝到預先建構的容器映像檔。以單一 Python 檔案的形式提供訓練應用程式,適合用於原型設計。對於實際工作環境的訓練應用程式,您可能會將訓練應用程式安排到多個檔案中。用於預先建構容器的 Python 來源發行套件
將訓練應用程式封裝成一或多個 Python 來源發布套件,然後上傳至 Cloud Storage 值區。建立訓練工作時,Gemini Enterprise Agent Platform 會將來源發布內容安裝至預建的容器映像檔。
自訂容器映像檔
建立自己的 Docker 容器映像檔,預先安裝訓練應用程式和依附元件,然後上傳至 Artifact Registry。如果訓練應用程式是以 Python 編寫,您可以使用一個 Google Cloud CLI 指令執行這些步驟。
設定訓練工作
Gemini Enterprise Agent Platform 訓練工作會執行下列工作:
- 佈建一或多個虛擬機器 (VM),用於單一節點訓練或分散式訓練。
- 在佈建的 VM 上執行容器化訓練應用程式。
- 訓練工作完成後,系統會刪除 VM。
Gemini Enterprise Agent Platform 提供三種訓練工作,可執行訓練應用程式:
-
自訂工作 (
CustomJob) 會執行訓練應用程式。如果您使用預先建構的容器映像檔,模型構件會輸出至指定的 Cloud Storage 值區。如果是自訂容器映像檔,訓練應用程式也可以將模型構件輸出至其他位置。 -
超參數調整工作 (
HyperparameterTuningJob) 會使用不同的超參數值,多次執行訓練應用程式的試驗,直到產生超參數值最佳的模型構件為止。您可以指定要測試的超參數值範圍,以及要盡量提高的指標。 -
訓練管線 (
CustomTrainingJob) 會執行自訂工作或超參數調整工作,並視需要將模型構件匯出至 Gemini Enterprise Agent Platform,以建立模型資源。您可以指定 Gemini Enterprise Agent Platform 代管資料集做為資料來源。
建立訓練工作時,請指定用於執行訓練應用程式的運算資源,並設定容器。
運算設定
指定訓練工作使用的運算資源。Gemini Enterprise Agent Platform 支援單一節點訓練 (訓練工作在一個 VM 上執行),以及分散式訓練 (訓練工作在多個 VM 上執行)。
您可以為訓練工作指定下列運算資源:
VM 機型
不同機器類型提供的 CPU、記憶體大小和頻寬各不相同。
圖形處理器 (GPU)
您可以為 A2 或 N1 類型的 VM 新增一或多個 GPU。如果訓練應用程式設計為使用 GPU,新增 GPU 可大幅提升效能。
Tensor Processing Unit (TPU)
TPU 專為加速機器學習工作負載而設計。使用 TPU VM 進行訓練時,只能指定一個工作站集區。該工作站集區只能有一個副本。
開機磁碟
開機磁碟可使用 SSD (預設) 或 HDD。如果訓練應用程式會讀取及寫入磁碟,使用 SSD 可提升效能。您也可以根據訓練應用程式寫入磁碟的暫時資料量,指定開機磁碟大小。開機磁碟的大小介於 100 GiB (預設值) 至 64,000 GiB 之間。工作站集區中的所有 VM 必須使用相同類型和大小的開機磁碟。
容器設定
您需要進行的容器設定,取決於您使用的是預先建構的容器映像檔,還是自訂容器映像檔。
預先建構的容器設定:
- 指定要使用的預先建構容器映像檔 URI。
- 如果訓練應用程式封裝為 Python 來源發布套件,請指定套件所在的 Cloud Storage URI。
- 指定訓練應用程式的進入點模組。
- 選用:指定要傳遞至訓練應用程式進入點模組的指令列引數清單。
自訂容器設定:
- 指定自訂容器映像檔的 URI,可以是 Artifact Registry 或 Docker Hub 的 URI。
- 選用:覆寫容器映像檔中的
ENTRYPOINT或CMD指令。
建立訓練工作
準備好資料和訓練應用程式後,請建立下列其中一項訓練工作,執行訓練應用程式:
如要建立訓練作業,可以使用 Google Cloud 控制台、Google Cloud CLI、Agent Platform SDK for Python 或 Agent Platform API。
(選用) 將模型構件匯入 Gemini Enterprise Agent Platform
訓練應用程式可能會將一或多個模型構件輸出至指定位置,通常是 Cloud Storage bucket。如要透過模型構件在 Gemini Enterprise Agent Platform 取得推論結果,請先將模型構件匯入 Gemini Enterprise Agent Platform Model Registry。
與訓練用的容器映像檔類似,Gemini Enterprise Agent Platform 可讓您選擇使用預建或自訂的容器映像檔進行推論。如果機器學習架構和架構版本有可用的預建推論容器映像檔,建議使用預建容器映像檔。
後續步驟
- 由模型取得推論結果。
- 評估模型。
- 請參閱無伺服器訓練入門教學課程,取得在 Gemini Enterprise Agent Platform 訓練 TensorFlow Keras 圖片分類模型的逐步操作說明。