

Reinforcement learning is a powerful technique to adapt large language models (LLMs) to maximize feedback rewards provided by a user-defined reward function. The model explores many possible answers, observes a numeric reward for each, and gradually shifts its behavior so that high-reward answers become more likely and low-reward answers become less likely. This approach excels in scenarios that require multi-step reasoning, intricate decision-making, or understanding subtle nuances in prompts.
Reinforcement learning fine-tuning for Gemini lets you fine-tune Gemini by using your own prompts and self-defined reward functions. You can use it to boost the reasoning capability and output quality of Gemini models for your own use cases and agentic workflows.
How it works
Reinforcement learning fine-tuning operates iteratively to refine the behavior of the LLM. During each iteration, the model generates responses to a set of prompts. These responses are then evaluated by a user-defined reward function, which quantifies the quality of the generated output based on your desired criteria. The service uses this reward signal to update the model's parameters through reinforcement learning algorithms, to encourage behaviors that lead to higher rewards. This iterative process of generation, evaluation, and update allows the model to learn and adapt to your specific use cases.
The following diagram shows the overall reinforcement learning fine-tuning workflow:
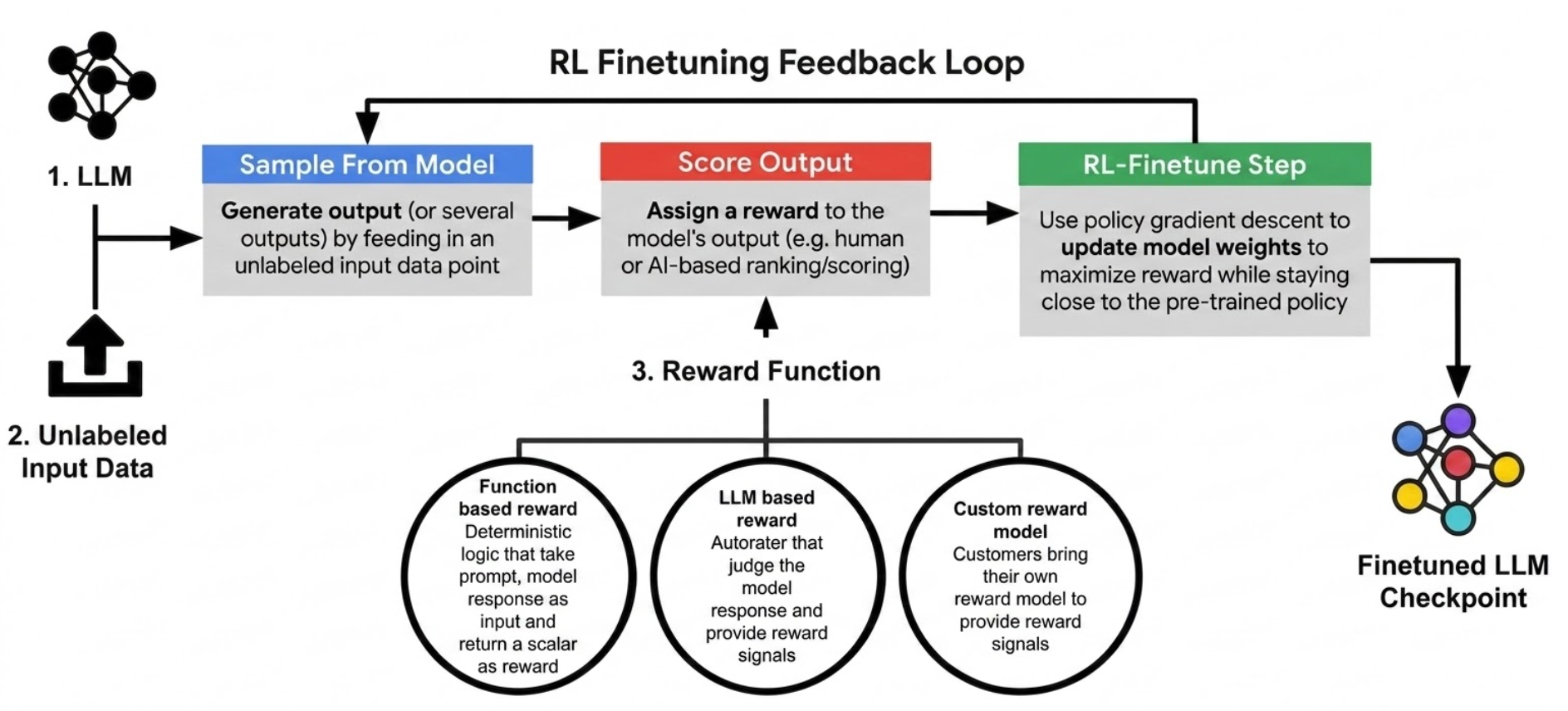
Key features
Customizable reward functions: Define your own reward functions to precisely optimize for a wide range of custom use cases and align the model's behavior with specific objectives. For details on the supported reward types, see the Reward functions page.
Adapters for efficient tuning: Reinforcement learning fine-tuning uses LoRA adapters, which enable effective adaptation while reusing the existing serving infrastructure.
Multiple thinking levels: The service supports tuning at two thinking levels,
MINIMALandHIGH(dynamic thinking), so you can choose the approach that best suits your model's learning objectives and desired response generation patterns. For details, see the Hyperparameters page.Continuous tuning: Further refine a previously tuned model by incorporating additional training examples or epochs. Using an existing tuned model or checkpoint as the foundation enables a more efficient process for tuning experimentation. For details, see the Continuous tuning page.
Multimodal datasets: Supports text, image, video, and audio data modalities.
When to use reinforcement learning fine-tuning
Reinforcement learning fine-tuning is preferred for fine-tuning LLMs in situations where optimal strategies are not obvious through supervised learning. This includes tasks where the goal is to optimize specific metrics without readily available ground truth labels, where alignment with human preferences is crucial (and a judgement method exists), and for reasoning-heavy tasks that benefit from iterative improvement and exploration.
The following are some scenarios where reinforcement learning fine-tuning is preferred:
Complex instruction following: When the model needs to follow intricate instructions where the "correct" output isn't a single answer but requires a set of checks. Reinforcement learning can help the model learn to navigate these complex instruction sets.
Creative content generation: For tasks like generating creative writing, poetry, or highly specialized code, where objective metrics are difficult to define. Reinforcement learning, with a well-designed reward function (potentially involving human feedback or expert evaluation), can guide the model toward more desirable and innovative outputs.
Reasoning tasks: For tasks that require heavy reasoning, such as solving word puzzles or mathematical problems, reinforcement learning can incentivize the model to explore different "thought" sequences to learn which patterns of reasoning are most effective at solving problems.
Supported models and regions
The following Gemini models support reinforcement learning fine-tuning:
Gemini 3.5 Flash
| Specification | Value |
|---|---|
| Supported endpoints for model tuning |
|
| Supported endpoints for tuned model serving |
|
| API version | v1beta1 only |
Supported tuning modalities
Reinforcement learning fine-tuning supports the following data modalities in your tuning datasets:
- Text
- Audio
- Image
- Video
For per-modality dataset limits (such as maximum number of files per prompt, maximum file size, and maximum total length), see the Tuning dataset page.
Continuous tuning
You can use the output of a previous tuning job as the base for a new reinforcement learning fine-tuning job. The following continuous tuning patterns are supported:
- Supervised fine-tuning → Reinforcement learning fine-tuning
- Reinforcement learning fine-tuning → Reinforcement learning fine-tuning
For configuration details, see the Continuous tuning page.
Serve the tuned model
After a successful reinforcement learning fine-tuning job on the base
Gemini model, a tuned model based on the last checkpoint is deployed
to an endpoint in your project. Tuned models use the same serving endpoint
strategy as the base model. For example, if you run a tuning job in
us-central1, the tuned model is deployed to a us multi-region endpoint
(mREP).
To retrieve the deployed tuned-model endpoint and run inference against it, see the Quick start page.
Pricing
Tuning pricing
Reinforcement learning fine-tuning for Gemini generates tokens in two phases: a sampling phase and a training phase. Tokens generated during the training phase are charged according to the "Model Tuning" section of the Gemini Enterprise Agent Platform pricing page.
Inference pricing
After tuning, inference (prediction request) costs for the tuned model still apply. For model inference starting from Gemini 3, the tuned-model endpoint prediction price is 1.5 times the price of the base model. For more information, see Available Gemini stable model versions.
If you configure the Gen AI evaluation service to run automatically during tuning, evaluations are charged as batch prediction jobs. For more information, see the "Model Tuning" section of the Gemini Enterprise Agent Platform pricing page.
What's next
- Follow the Quick start to create your first reinforcement learning fine-tuning job.
- Learn how to prepare a tuning dataset and configure reward functions.
- Learn about deploying a tuned Gemini model.