

Questo documento fornisce istruzioni per configurare un cluster Ray su Gemini Enterprise Agent Platform per soddisfare varie esigenze. Ad esempio, per creare l'immagine, vedi Immagine personalizzata. Alcune aziende possono utilizzare il networking privato. Questo documento riguarda l'interfaccia Private Service Connect per Ray su Vertex AI. Un altro caso d'uso prevede l'accesso a file remoti come se fossero locali (vedi Ray on Agent Platform Network File System).
Panoramica
Gli argomenti trattati includono:
- creare un cluster Ray su Gemini Enterprise Agent Platform
- gestione del ciclo di vita di un cluster Ray
- creando un'immagine personalizzata
- configurazione della connettività privata e pubblica (VPC)
- utilizzando l'interfaccia Private Service Connect per Ray su Agent Platform
- configurazione di Ray su Agent Platform Network File System (NFS)
- configurazione di una dashboard Ray e di una shell interattiva con VPC-SC + peering VPC
Crea un cluster Ray
Puoi utilizzare la console Google Cloud o l'SDK Agent Platform per Python per creare un cluster Ray. Un cluster può avere fino a 2000 nodi. Esiste un limite superiore di 1000 nodi all'interno di un pool di worker. Non esiste un limite al numero di pool di worker, ma un numero elevato di pool di worker, ad esempio 1000 pool di worker con un nodo ciascuno, può influire negativamente sulle prestazioni del cluster.
Prima di iniziare, leggi la panoramica di Ray su Gemini Enterprise Agent Platform e configura tutti gli strumenti prerequisiti necessari.
L'avvio di un cluster Ray su Agent Platform potrebbe richiedere 10-20 minuti dopo la creazione del cluster.
Console
In conformità con il best practice OSS Ray, l'impostazione del conteggio delle CPU logiche su 0 sul nodo head di Ray viene applicata per evitare l'esecuzione di qualsiasi workload sul nodo head.
Nella console Google Cloud , vai alla pagina Ray on Agent Platform.
Fai clic su Crea cluster per aprire il riquadro Crea cluster.
Per ogni passaggio del riquadro Crea cluster, rivedi o sostituisci le informazioni predefinite del cluster. Fai clic su Continua per completare ogni passaggio:
Per Nome e regione, specifica un Nome e scegli una Località per il cluster.
Per Impostazioni di calcolo, specifica la configurazione del cluster Ray sul nodo head di Gemini Enterprise Agent Platform, inclusi tipo di macchina, tipo e conteggio dell'acceleratore, tipo e dimensione del disco e conteggio delle repliche. (Facoltativo) aggiungi un URI immagine container personalizzato per specificare un'immagine container personalizzata per aggiungere dipendenze Python non fornite dall'immagine container predefinita. Vedi Immagine personalizzata.
Nella sezione Opzioni avanzate, puoi:
- Specifica la tua chiave di crittografia.
- Specifica un service account personalizzato.
- Disattiva la raccolta delle metriche se non devi monitorare le statistiche delle risorse del tuo workload durante l'addestramento.
(Facoltativo) Per eseguire il deployment di un endpoint privato per il cluster, il metodo consigliato è utilizzare Private Service Connect. Per ulteriori dettagli, consulta Interfaccia Private Service Connect per Ray su Vertex AI.
Fai clic su Crea.
SDK Ray on Agent Platform
In conformità con il best practice OSS Ray, l'impostazione del conteggio delle CPU logiche su 0 sul nodo head di Ray viene applicata per evitare l'esecuzione di qualsiasi workload sul nodo head.
Da un ambiente Python interattivo, utilizza quanto segue per creare il cluster Ray su Gemini Enterprise Agent Platform:
import ray import vertex_ray from google.cloud import aiplatform from vertex_ray import Resources from vertex_ray.util.resources import NfsMount # Define a default CPU cluster, machine_type is n1-standard-16, 1 head node and 1 worker node head_node_type = Resources() worker_node_types = [Resources()] # Or define a GPU cluster. head_node_type = Resources( machine_type="n1-standard-16", node_count=1, custom_image="us-docker.pkg.dev/my-project/ray-custom.2-9.py310:latest", # Optional. When not specified, a prebuilt image is used. ) worker_node_types = [Resources( machine_type="n1-standard-16", node_count=2, # Must be >= 1 accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, custom_image="us-docker.pkg.dev/my-project/ray-custom.2-9.py310:latest", # When not specified, a prebuilt image is used. )] # Optional. Create cluster with Network File System (NFS) setup. nfs_mount = NfsMount( server="10.10.10.10", path="nfs_path", mount_point="nfs_mount_point", ) aiplatform.init() # Initialize Agent Platform to retrieve projects for downstream operations. # Create the Ray cluster on Agent Platform CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, network=NETWORK, #Optional worker_node_types=worker_node_types, python_version="3.10", # Optional ray_version="2.47", # Optional cluster_name=CLUSTER_NAME, # Optional service_account=SERVICE_ACCOUNT, # Optional enable_metrics_collection=True, # Optional. Enable metrics collection for monitoring. labels=LABELS, # Optional. nfs_mounts=[nfs_mount], # Optional. )
Dove:
CLUSTER_NAME: un nome per il cluster Ray su Gemini Enterprise Agent Platform che deve essere univoco nel tuo progetto.
NETWORK: (facoltativo) il nome completo della tua rete VPC, nel formato
projects/PROJECT_ID/global/networks/VPC_NAME. Per impostare un endpoint privato anziché un endpoint pubblico per il cluster, specifica una rete VPC da utilizzare con Ray su Agent Platform. Per saperne di più, consulta la sezione Connettività privata e pubblica.VPC_NAME: (facoltativo) la VPC su cui opera la VM.
PROJECT_ID: il tuo ID progetto Google Cloud . Puoi trovare l'ID progetto nella pagina di benvenuto della console Google Cloud .
SERVICE_ACCOUNT: facoltativo: il account di servizio per eseguire le applicazioni Ray sul cluster. Concedi i ruoli richiesti.
LABELS: (facoltativo) le etichette con metadati definiti dall'utente utilizzati per organizzare i cluster Ray. I valori e le chiavi di etichetta non devono superare i 64 caratteri (punti di codice Unicode) e possono contenere solo lettere minuscole, caratteri numerici, trattini bassi e trattini. Sono consentiti caratteri internazionali. Per ulteriori informazioni ed esempi di etichette, visita la pagina https://goo.gl/xmQnxf.
Dovresti vedere il seguente output finché lo stato non cambia in RUNNING:
[Ray on Agent Platform]: Cluster State = State.PROVISIONING Waiting for cluster provisioning; attempt 1; sleeping for 0:02:30 seconds ... [Ray on Agent Platform]: Cluster State = State.RUNNING
Tieni presente quanto segue:
Il primo nodo è il nodo principale.
I tipi di macchine TPU non sono supportati.
Gestione del ciclo di vita
Durante il ciclo di vita di un cluster Ray su Gemini Enterprise Agent Platform, ogni azione è associata a uno stato. La tabella seguente riassume lo stato di fatturazione e l'opzione di gestione per ogni stato. La documentazione di riferimento fornisce una definizione per ciascuno di questi stati.
| Azione | Stato | Fatturato? | Eliminare l'azione disponibile? | Azione di annullamento disponibile? |
|---|---|---|---|---|
| L'utente crea un cluster | PROVISIONING | No | No | No |
| L'utente esegue manualmente lo scale up o lo scale down | IN FASE DI AGGIORNAMENTO | Sì, in base alle dimensioni in tempo reale | Sì | No |
| Il cluster viene eseguito | IN ESECUZIONE | Sì | Sì | Non applicabile: puoi eliminare |
| Il cluster viene scalato automaticamente | IN FASE DI AGGIORNAMENTO | Sì, in base alle dimensioni in tempo reale | Sì | No |
| L'utente elimina il cluster | FINE | No | No | Non applicabile - già in fase di arresto |
| Il cluster entra in uno stato di errore | ERRORE | No | Sì | Non applicabile: puoi eliminare |
| Non applicabile | STATE_UNSPECIFIED | No | Sì | Non applicabile |
Immagine personalizzata (facoltativa)
Le immagini predefinite sono in linea con la maggior parte dei casi d'uso. Se vuoi creare la tua immagine, utilizza le immagini predefinite di Ray su Gemini Enterprise Agent Platform come immagine di base. Consulta la documentazione di Docker per scoprire come creare le immagini da un'immagine di base.
Queste immagini di base includono un'installazione di Python, Ubuntu e Ray. Sono incluse anche dipendenze come:
- python-json-logger
- google-cloud-resource-manager
- ca-certificates-java
- libatlas-base-dev
- liblapack-dev
- g++, libio-all-perl
- libyaml-0-2.
Connettività privata e pubblica
Per impostazione predefinita, Ray su Agent Platform crea un endpoint pubblico e sicuro per lo sviluppo interattivo con il client Ray sui cluster Ray su Gemini Enterprise Agent Platform. Utilizza la connettività pubblica per lo sviluppo o per casi d'uso effimeri. Questo endpoint pubblico è accessibile tramite internet. Solo gli utenti autorizzati che dispongono, come minimo, delle autorizzazioni del ruolo utente della piattaforma di agenti Gemini Enterprise nel progetto utente del cluster Ray possono accedere al cluster.
Se hai bisogno di una connessione privata al tuo cluster o se utilizzi i Controlli di servizio VPC, il peering VPC è supportato per i cluster Ray sulla piattaforma Gemini Enterprise Agent. I cluster con un endpoint privato sono accessibili solo da un client all'interno di una rete VPC in peering con Gemini Enterprise Agent Platform.
Per configurare la connettività privata con il peering VPC per Ray su Agent Platform, seleziona una rete VPC quando crei il cluster. La rete VPC richiede una connessione di accesso privato ai servizi tra la tua rete VPC e la piattaforma Gemini Enterprise Agent. Se utilizzi Ray su Agent Platform nella console, puoi configurare la connessione di accesso privato ai servizi durante la creazione del cluster.
Se vuoi utilizzare Controlli di servizio VPC e il peering VPC con i cluster Ray su Agent Platform, è necessaria una configurazione aggiuntiva per utilizzare la dashboard Ray e la shell interattiva. Segui le istruzioni riportate in Ray Dashboard e shell interattiva con VPC-SC + peering VPC per configurare la shell interattiva con VPC-SC e peering VPC nel tuo progetto utente.
Dopo aver creato il cluster Ray su Gemini Enterprise Agent Platform, puoi connetterti al nodo head utilizzando l'SDK Agent Platform per Python. L'ambiente di connessione, ad esempio una VM Compute Engine o un'istanza Vertex AI Workbench, deve trovarsi nella rete VPC di cui è stato eseguito il peering con Gemini Enterprise Agent Platform. Tieni presente che una connessione ai servizi privati ha un numero limitato di indirizzi IP, il che potrebbe comportare l'esaurimento degli indirizzi IP. Pertanto, ti consigliamo di utilizzare connessioni private per i cluster a lunga esecuzione.
Interfaccia Private Service Connect per Ray su Gemini Enterprise Agent Platform
Interfaccia Private Service Connect L'uscita e l'ingresso dell'interfaccia Private Service Connect sono supportati sui cluster Ray sulla piattaforma Gemini Enterprise Agent.
Per utilizzare il traffico in uscita dall'interfaccia Private Service Connect, segui le istruzioni nella sezione seguente. Se i Controlli di servizio VPC non sono abilitati, i cluster con uscita dell'interfaccia Private Service Connect utilizzano l'endpoint pubblico sicuro per l'ingresso con Ray Client.
Se i Controlli di servizio VPC sono abilitati, l'ingresso dell'interfaccia Private Service Connect viene utilizzato per impostazione predefinita con l'uscita dell'interfaccia Private Service Connect. Per connetterti a Ray Client o inviare job da un notebook per un cluster con ingresso dell'interfaccia Private Service Connect, assicurati che il notebook si trovi all'interno del VPC e della subnet del progetto utente. Per maggiori dettagli su come configurare i Controlli di servizio VPC, consulta Controlli di servizio VPC con la piattaforma di agenti Gemini Enterprise.
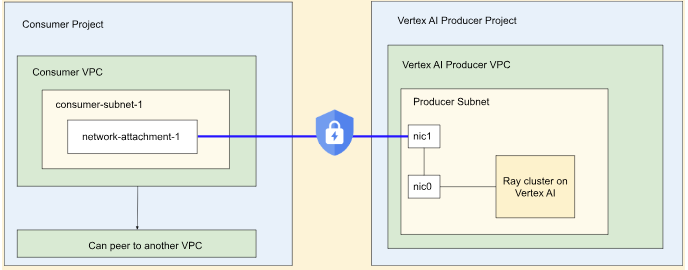
Abilita l'interfaccia Private Service Connect
Segui la guida Configurazione delle risorse per configurare l'interfaccia Private Service Connect. Dopo aver configurato le risorse, puoi abilitare l'interfaccia Private Service Connect sul cluster Ray su Gemini Enterprise Agent Platform.
Console
Durante la creazione del cluster e dopo aver specificato Nome e regione e Impostazioni di calcolo, viene visualizzata l'opzione Networking.
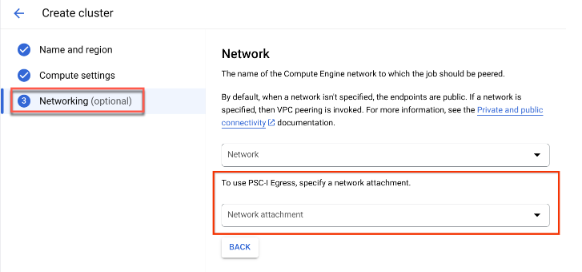
Configura un collegamento di rete eseguendo una delle seguenti operazioni:
- Utilizza il nome NETWORK_ATTACHMENT_NAME che hai specificato durante la configurazione delle risorse per Private Service Connect.
- Crea un nuovo collegamento di rete facendo clic sul pulsante Crea collegamento di rete visualizzato nel menu a discesa.
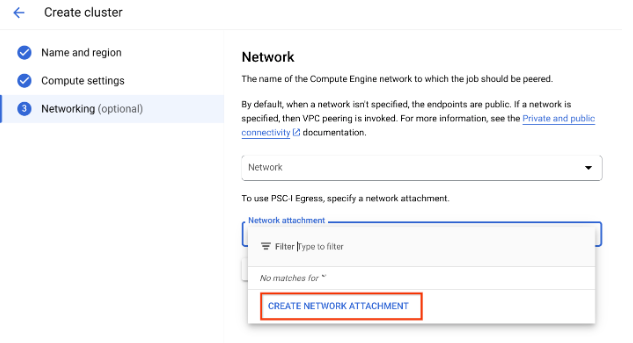
Fai clic su Crea collegamento di rete.
Nella sottoattività visualizzata, specifica un nome, una rete e una subnet per il nuovo collegamento di rete.
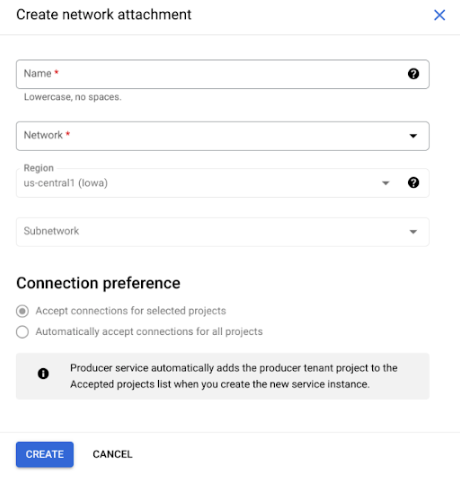
Fai clic su Crea.
SDK Ray on Agent Platform
L'SDK Ray on Agent Platform fa parte dell'SDK Agent Platform per Python. Per scoprire come installare o aggiornare l'SDK Agent Platform per Python, consulta Installare l'SDK Agent Platform per Python. Per saperne di più, consulta la documentazione di riferimento dell'API Python dell'SDK Agent Platform.
from google.cloud import aiplatform import vertex_ray # Initialization aiplatform.init() # Create a default cluster with network attachment configuration psc_config = vertex_ray.PscIConfig(network_attachment=NETWORK_ATTACHMENT_NAME) cluster_resource_name = vertex_ray.create_ray_cluster( psc_interface_config=psc_config, )
Dove:
- NETWORK_ATTACHMENT_NAME: il nome che hai specificato durante la configurazione delle risorse per Private Service Connect nel progetto utente.
Ray on Agent Platform Network File System (NFS)
Per rendere disponibili i file remoti nel cluster, monta le condivisioni Network File System (NFS). I tuoi job possono quindi accedere ai file remoti come se fossero locali, il che consente un'elevata velocità effettiva e una bassa latenza.
Configurazione VPC
Esistono due opzioni per configurare il VPC:
- Crea un collegamento di rete dell'interfaccia Private Service Connect. (Consigliato)
- Configura il peering di rete VPC.
Configura l'istanza NFS
Per maggiori dettagli su come creare un'istanza Filestore, consulta Creare un'istanza. Se utilizzi il metodo dell'interfaccia Private Service Connect, non devi selezionare la modalità di accesso privato ai servizi durante la creazione di Filestore.
Utilizzare il Network File System (NFS)
Per utilizzare il file system di rete, specifica una rete o un collegamento di rete (consigliato).
Console
Nel passaggio Networking della pagina di creazione, dopo aver specificato una rete o un collegamento di rete. Per farlo, fai clic su Aggiungi montaggio NFS nella sezione Network File System (NFS) e specifica un montaggio NFS (server, percorso e punto di montaggio).
Campo Descrizione serverL'indirizzo IP del tuo server NFS. Deve essere un indirizzo privato nel tuo VPC. pathIl percorso della condivisione NFS. Deve essere un percorso assoluto che inizia con /.mountPointIl punto di montaggio locale. Deve essere un nome di directory UNIX valido. Ad esempio, se il punto di montaggio locale è sourceData, specifica il percorso/mnt/nfs/ sourceDatadall'istanza VM di addestramento.Per saperne di più, consulta Dove specificare le risorse di calcolo.
Specifica un server, un percorso e un punto di montaggio.
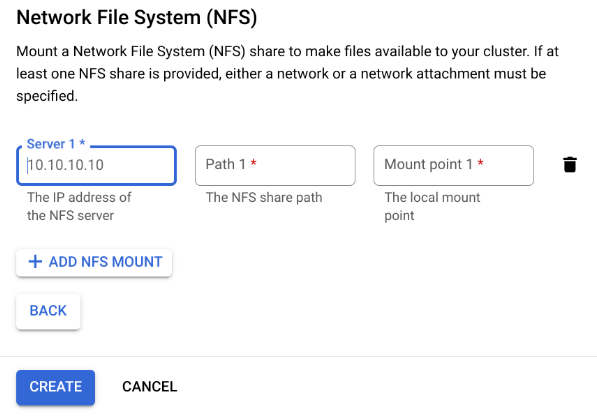
Fai clic su Crea. Viene creato il cluster Ray.
Dashboard Ray e shell interattiva con VPC-SC + peering VPC
-
Configura
peered-dns-domains.{ VPC_NAME=NETWORK_NAME REGION=LOCATION gcloud services peered-dns-domains create training-cloud \ --network=$VPC_NAME \ --dns-suffix=$REGION.aiplatform-training.cloud.google.com. # Verify gcloud beta services peered-dns-domains list --network $VPC_NAME; }
-
NETWORK_NAME: Passa alla rete in peering.
-
LOCATION: la posizione desiderata (ad esempio,
us-central1).
-
-
Configura
DNS managed zone.{ PROJECT_ID=PROJECT_ID ZONE_NAME=$PROJECT_ID-aiplatform-training-cloud-google-com DNS_NAME=aiplatform-training.cloud.google.com DESCRIPTION=aiplatform-training.cloud.google.com gcloud dns managed-zones create $ZONE_NAME \ --visibility=private \ --networks=https://www.googleapis.com/compute/v1/projects/$PROJECT_ID/global/networks/$VPC_NAME \ --dns-name=$DNS_NAME \ --description="Training $DESCRIPTION" }
-
PROJECT_ID: il tuo ID progetto. Puoi trovare questi ID nella pagina Benvenuto della console Google Cloud .
-
-
Registra la transazione DNS.
{ gcloud dns record-sets transaction start --zone=$ZONE_NAME gcloud dns record-sets transaction add \ --name=$DNS_NAME. \ --type=A 199.36.153.4 199.36.153.5 199.36.153.6 199.36.153.7 \ --zone=$ZONE_NAME \ --ttl=300 gcloud dns record-sets transaction add \ --name=*.$DNS_NAME. \ --type=CNAME $DNS_NAME. \ --zone=$ZONE_NAME \ --ttl=300 gcloud dns record-sets transaction execute --zone=$ZONE_NAME }
-
Invia un job di addestramento con la shell interattiva + VPC-SC + peering VPC abilitato.
Responsabilità condivisa
La protezione dei tuoi carichi di lavoro su Gemini Enterprise Agent Platform è una responsabilità condivisa. Sebbene Gemini Enterprise Agent Platform aggiorni regolarmente le configurazioni dell'infrastruttura per risolvere le vulnerabilità di sicurezza, Gemini Enterprise Agent Platform non esegue automaticamente l'upgrade dei cluster Ray su Vertex AI e delle risorse permanenti esistenti per evitare di interrompere i carichi di lavoro in esecuzione. Pertanto, sei responsabile di attività come le seguenti:
- Elimina e ricrea periodicamente i cluster Ray su Vertex AI e le risorse permanenti per utilizzare le versioni più recenti dell'infrastruttura. Gemini Enterprise Agent Platform consiglia di ricreare i cluster e le risorse permanenti almeno una volta ogni 30 giorni.
- Configura correttamente le immagini personalizzate che utilizzi.
Per ulteriori informazioni, consulta Responsabilità condivisa.