

Ray è un framework open source per la scalabilità di applicazioni AI e Python. Ray fornisce l'infrastruttura per eseguire il computing distribuito e l'elaborazione parallela per il tuo flusso di lavoro di machine learning (ML).
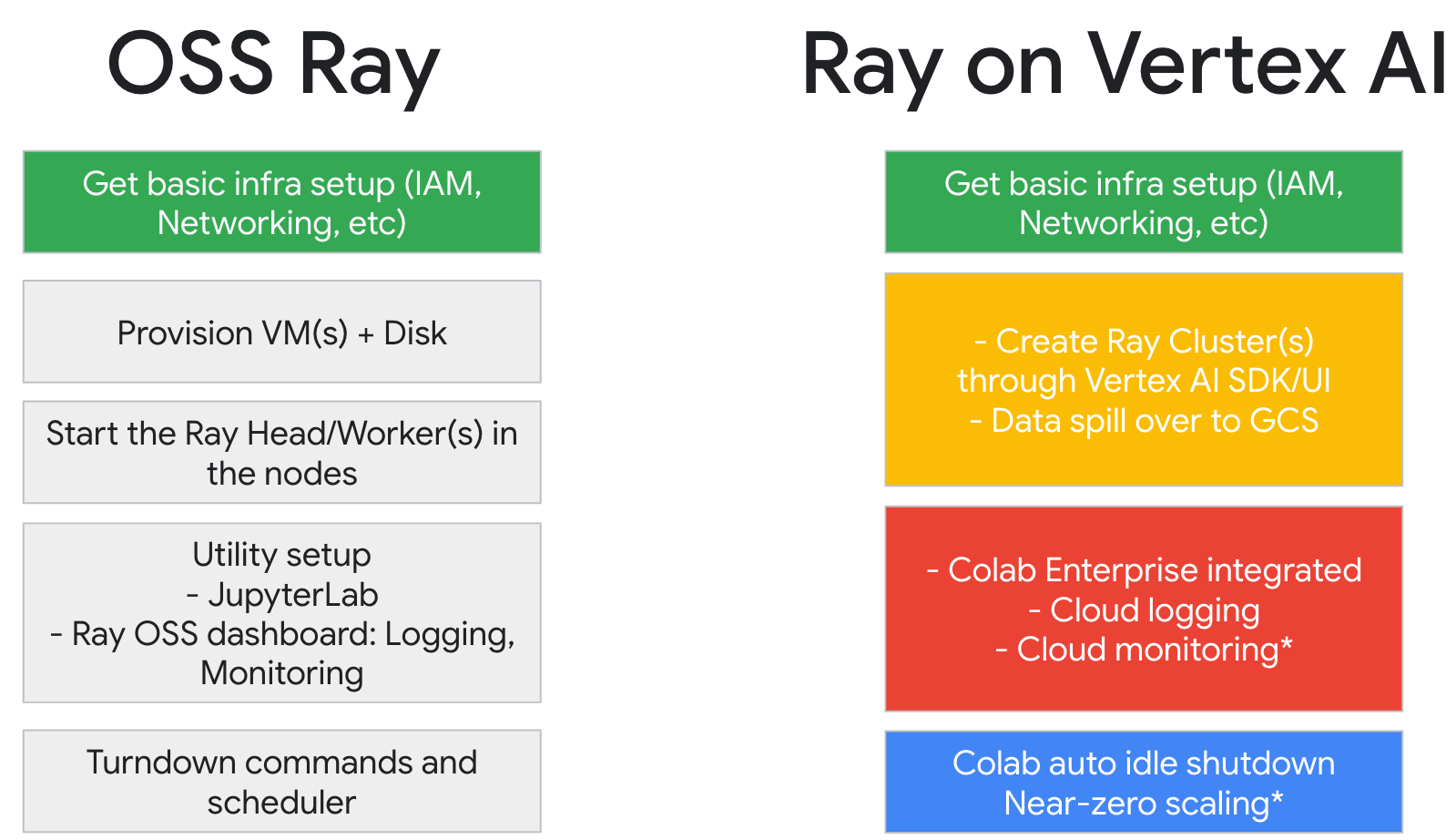
Se utilizzi già Ray, puoi utilizzare lo stesso codice Ray open source per scrivere programmi e sviluppare applicazioni su Gemini Enterprise Agent Platform con modifiche minime. Puoi quindi utilizzare le integrazioni di Gemini Enterprise Agent Platform con altri servizi Google Cloud come Vertex AI Inference e BigQuery nell'ambito del tuo flusso di lavoro di machine learning.
Se utilizzi già Gemini Enterprise Agent Platform e hai bisogno di un modo più semplice per gestire le risorse di calcolo, puoi utilizzare il codice Ray per scalare l'addestramento.
Workflow per l'utilizzo di Ray su Agent Platform
Utilizza Colab Enterprise e l'SDK Agent Platform per Python per connetterti al cluster Ray.
| Procedura | Descrizione |
|---|---|
| 1. Configurazione di Ray su Agent Platform | Configura il tuo progetto Google, installa la versione dell'SDK Agent Platform per Python che include la funzionalità di Ray Client e configura una rete di peering VPC, che è facoltativa. |
| 2. Crea un cluster Ray su Gemini Enterprise Agent Platform | Crea un cluster Ray su Gemini Enterprise Agent Platform. È necessario il ruolo Amministratore di Gemini Enterprise Agent Platform. |
| 3. Sviluppare un'applicazione Ray su Gemini Enterprise Agent Platform | Connettiti a un cluster Ray su Gemini Enterprise Agent Platform e sviluppa un'applicazione. È necessario il ruolo utente Gemini Enterprise Agent Platform. |
| 4. (Facoltativo) Utilizza Ray su Agent Platform con BigQuery | Leggi, scrivi e trasforma i dati con BigQuery. |
| 5. (Facoltativo) Esegui il deployment di un modello su Gemini Enterprise Agent Platform e ottieni inferenze | Esegui il deployment di un modello in un endpoint online di Gemini Enterprise Agent Platform e ottieni inferenze. |
| 6. Monitorare il cluster Ray su Gemini Enterprise Agent Platform | Monitora i log generati in Cloud Logging e le metriche in Cloud Monitoring. |
| 7. Eliminare un cluster Ray su Gemini Enterprise Agent Platform | Elimina un cluster Ray su Gemini Enterprise Agent Platform per evitare addebiti non necessari. |
Panoramica
I cluster Ray sono integrati per garantire la disponibilità della capacità per i workload ML critici o durante le stagioni di picco. A differenza dei job personalizzati, in cui il servizio di addestramento rilascia la risorsa al termine del job, i cluster Ray rimangono disponibili fino all'eliminazione.
Nota: utilizza cluster Ray a esecuzione prolungata in questi scenari:
- Se invii lo stesso job Ray più volte, puoi usufruire della memorizzazione nella cache di dati e immagini eseguendo i job sullo stesso cluster Ray a lunga esecuzione.
- Se esegui molti job Ray di breve durata in cui il tempo di elaborazione effettivo è inferiore al tempo di avvio del job, potrebbe essere utile avere un cluster a lunga esecuzione.
I cluster Ray su Gemini Enterprise Agent Platform possono essere configurati con connettività pubblica o privata. I seguenti diagrammi mostrano l'architettura e il flusso di lavoro per Ray su Agent Platform. Per saperne di più, consulta la sezione Connettività pubblica o privata.
Architettura con connettività pubblica
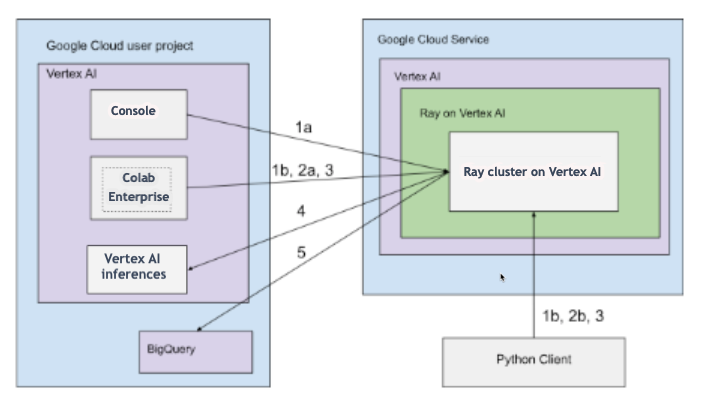
Crea il cluster Ray su Gemini Enterprise Agent Platform utilizzando le seguenti opzioni:
a. Utilizza la console Google Cloud per creare il cluster Ray su Gemini Enterprise Agent Platform.
b. Crea il cluster Ray su Gemini Enterprise Agent Platform utilizzando l'SDK Agent Platform per Python.
Connettiti al cluster Ray su Gemini Enterprise Agent Platform per lo sviluppo interattivo utilizzando le seguenti opzioni:
a. Utilizza Colab Enterprise nella console Google Cloud per una connessione senza interruzioni.
b. Utilizza qualsiasi ambiente Python accessibile a internet pubblico.
Sviluppa l'applicazione e addestra il modello sul cluster Ray su Gemini Enterprise Agent Platform:
Utilizza l'SDK Agent Platform per Python nell'ambiente che preferisci (Colab Enterprise o qualsiasi notebook Python).
Scrivi uno script Python utilizzando l'ambiente che preferisci.
Invia un job Ray al cluster Ray sulla piattaforma Gemini Enterprise Agent utilizzando l'SDK Agent Platform per Python, la CLI Ray Job o l'API Ray Job Submission.
Esegui il deployment del modello addestrato su un endpoint online di Gemini Enterprise Agent Platform per l'inferenza live.
Utilizza BigQuery per gestire i tuoi dati.
Architettura con VPC
Il seguente diagramma mostra l'architettura e il flusso di lavoro per Ray su Agent Platform dopo aver configurato il progetto Google Cloud e la rete VPC, che è facoltativa:
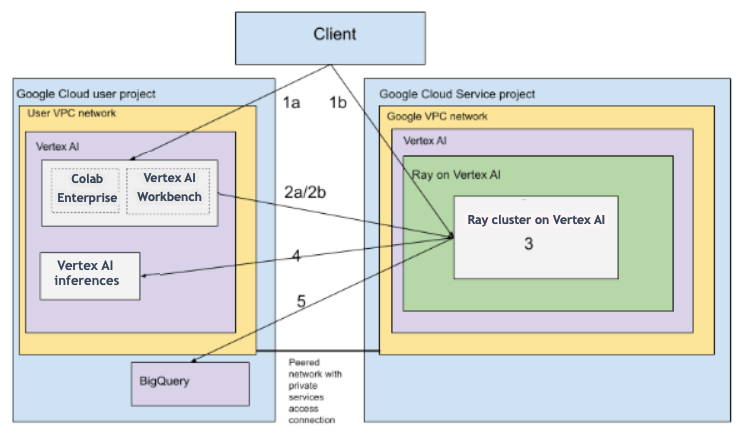
Configura (a) il progetto Google e (b) la rete VPC.
Crea il cluster Ray su Gemini Enterprise Agent Platform utilizzando le seguenti opzioni:
a. Utilizza la console Google Cloud per creare il cluster Ray su Gemini Enterprise Agent Platform.
b. Crea il cluster Ray su Gemini Enterprise Agent Platform utilizzando l'SDK Agent Platform per Python.
Connettiti al cluster Ray su Gemini Enterprise Agent Platform tramite una rete con peering VPC utilizzando le seguenti opzioni:
Utilizza Colab Enterprise nella consoleGoogle Cloud .
Utilizza un notebook Gemini Enterprise Agent Platform Workbench.
Sviluppa la tua applicazione e addestra il tuo modello sul cluster Ray su Gemini Enterprise Agent Platform utilizzando le seguenti opzioni:
Utilizza l'SDK Agent Platform per Python nell'ambiente che preferisci (Colab Enterprise o un notebook Agent Platform Workbench).
Scrivi uno script Python utilizzando l'ambiente che preferisci. Invia un job Ray al cluster Ray su Gemini Enterprise Agent Platform utilizzando l'SDK Agent Platform per Python, la CLI Ray Job o la dashboard Ray.
Esegui il deployment del modello addestrato su un endpoint online di Gemini Enterprise Agent Platform per le inferenze.
Utilizza BigQuery per gestire i tuoi dati.
Terminologia
Per un elenco completo dei termini, consulta il glossario di Agent Platform per l'IA predittiva.
-
scalabilità automatica
- La scalabilità automatica è la capacità di una risorsa di calcolo, come il pool di worker di un cluster Ray, di regolare automaticamente il numero di nodi in base alle esigenze del carico di lavoro, ottimizzando l'utilizzo delle risorse e i costi. Per saperne di più, consulta Scalare i cluster Ray su Vertex AI: scalabilità automatica.
-
inferenza batch
- L'inferenza in batch accetta un gruppo di richieste di inferenza e restituisce i risultati in un unico file. Per saperne di più, consulta Panoramica dell'ottenimento di inferenze su Vertex AI.
-
BigQuery
- BigQuery è un data warehouse aziendale serverless, completamente gestito e altamente scalabile fornito da Google Cloud, progettato per analizzare set di dati di grandi dimensioni utilizzando query SQL a velocità incredibilmente elevate. BigQuery consente di eseguire analisi e business intelligence avanzate senza richiedere agli utenti di gestire alcuna infrastruttura. Per saperne di più, consulta Da data warehouse a piattaforma di AI e dati autonomi.
-
Cloud Logging
- Cloud Logging è un servizio di logging in tempo reale completamente gestito fornito da Google Cloud che ti consente di raccogliere, archiviare, analizzare e monitorare i log di tutte le tue risorse Google Cloud, delle applicazioni on-premise e persino delle origini personalizzate. Cloud Logging centralizza la gestione dei log, semplificando la risoluzione dei problemi, l'audit e la comprensione del comportamento e dell'integrità delle applicazioni e dell'infrastruttura. Per saperne di più, consulta la panoramica di Cloud Logging.
-
Colab Enterprise
- Colab Enterprise è un ambiente di notebook Jupyter gestito e collaborativo che porta la popolare esperienza utente di Google Colab su Google Cloud, offrendo funzionalità di sicurezza e conformità di livello aziendale. Colab Enterprise offre un'esperienza incentrata sui notebook e senza configurazione, con risorse di calcolo gestite da Vertex AI e si integra con altri servizi Google Cloud come BigQuery. Per saperne di più, consulta Introduzione a Colab Enterprise.
-
immagine container personalizzata
- Un'immagine container personalizzata è un pacchetto eseguibile autonomo che include il codice dell'applicazione dell'utente, il runtime, le librerie, le dipendenze e la configurazione dell'ambiente. Nel contesto di Google Cloud, in particolare Vertex AI, consente all'utente di pacchettizzare il codice di addestramento di machine learning o l'applicazione di serving con le relative dipendenze esatte, garantendo la riproducibilità e consentendo all'utente di eseguire un carico di lavoro su servizi gestiti utilizzando versioni software specifiche o configurazioni uniche non fornite dagli ambienti standard. Per saperne di più, consulta Requisiti dei container personalizzati per l'inferenza.
-
endpoint
- Risorse in cui puoi eseguire il deployment di modelli addestrati per fornire inferenze. Per saperne di più, consulta Scegliere un tipo di endpoint.
-
Autorizzazioni Identity and Access Management (IAM)
- Le autorizzazioni Identity and Access Management (IAM) sono funzionalità granulari specifiche che definiscono chi può fare cosa su quali risorse Google Cloud. Vengono assegnati alle entità (come utenti, gruppi o service account) tramite i ruoli, consentendo un controllo preciso dell'accesso a servizi e dati all'interno di un progetto o un'organizzazione Google Cloud. Per saperne di più, consulta Controllo dell'accesso con IAM.
-
inferenza
- Nel contesto della piattaforma Vertex AI, l'inferenza si riferisce al processo di esecuzione di punti dati tramite un modello di machine learning per calcolare un output, ad esempio un singolo punteggio numerico. Questo processo è noto anche come "operazionalizzazione di un modello di machine learning" o "inserimento di un modello di machine learning in produzione". L'inferenza è un passaggio importante nel flusso di lavoro di machine learning, in quanto consente di utilizzare i modelli per fare inferenze su nuovi dati. In Vertex AI, l'inferenza può essere eseguita in vari modi, tra cui l'inferenza batch e l'inferenza online. L'inferenza batch prevede l'esecuzione di un gruppo di richieste di inferenza e la restituzione dei risultati in un unico file, mentre l'inferenza online consente inferenze in tempo reale su singoli punti dati.
-
Network File System (NFS)
- Un sistema client/server che consente agli utenti di accedere ai file su una rete e di trattarli come se si trovassero in una directory di file locale. Per saperne di più, consulta Montare una condivisione Network File System.
-
Inferenza online
- Ottenere inferenze sulle singole istanze in modo sincrono. Per saperne di più, consulta Inferenza online.
-
risorsa permanente
- Un tipo di risorsa di calcolo di Vertex AI, ad esempio un cluster Ray, che rimane allocata e disponibile fino all'eliminazione esplicita, il che è utile per lo sviluppo iterativo e riduce l'overhead di avvio tra i job. Per saperne di più, consulta Recuperare informazioni sulle risorse permanenti.
-
pipeline
- Le pipeline ML sono flussi di lavoro ML portatili e scalabili basati su container. Per saperne di più, consulta Introduzione a Vertex AI Pipelines.
-
Container predefinito
- Immagini container fornite da Vertex AI con framework e dipendenze ML comuni preinstallati, semplificando la configurazione per i job di addestramento e inferenza. Per saperne di più, consulta Container predefiniti per l'addestramento serverless .
-
Private Service Connect (PSC)
- Private Service Connect è una tecnologia che consente ai clienti di Compute Engine di mappare gli IP privati nella propria rete a un'altra rete VPC o alle API di Google. Per saperne di più, consulta Private Service Connect.
-
Cluster Ray su Vertex AI
- Un cluster Ray su Vertex AI è un cluster gestito di nodi di calcolo che può essere utilizzato per eseguire applicazioni di machine learning (ML) e Python distribuite. Fornisce l'infrastruttura per eseguire il computing distribuito e l'elaborazione parallela per il tuo flusso di lavoro ML. I cluster Ray sono integrati in Vertex AI per garantire la disponibilità di capacità per i carichi di lavoro ML critici o durante i periodi di picco. A differenza dei job personalizzati, in cui il servizio di addestramento rilascia la risorsa al termine del job, i cluster Ray rimangono disponibili fino all'eliminazione. Per saperne di più, consulta la panoramica di Ray su Vertex AI.
-
Ray su Vertex AI (RoV)
- Ray su Vertex AI è progettato in modo da poter utilizzare lo stesso codice Ray open source per scrivere programmi e sviluppare applicazioni su Vertex AI con modifiche minime. Per saperne di più, consulta la panoramica di Ray su Vertex AI.
-
SDK Vertex AI Python Ray on Vertex AI
- L'SDK Ray on Vertex AI per Python è una versione dell'SDK Vertex AI Python che include la funzionalità di Ray Client, Ray BigQuery Connector, la gestione del cluster Ray su Vertex AI e le inferenze su Vertex AI. Per ulteriori informazioni, consulta Introduzione all'SDK Vertex AI Python.
-
SDK Vertex AI Python Ray on Vertex AI
- L'SDK Ray on Vertex AI per Python è una versione dell'SDK Vertex AI Python che include la funzionalità di Ray Client, Ray BigQuery Connector, la gestione del cluster Ray su Vertex AI e le inferenze su Vertex AI. Per ulteriori informazioni, consulta Introduzione all'SDK Vertex AI per Python.
-
service account
- I service account sono speciali account Google Cloud utilizzati da applicazioni o macchine virtuali per effettuare chiamate API autorizzate ai servizi Google Cloud. A differenza degli account utente, non sono collegati a una persona, ma fungono da identità per il tuo codice, consentendo l'accesso sicuro e programmatico alle risorse senza richiedere credenziali umane. Per saperne di più, consulta Panoramica dei service account.
-
Vertex AI Workbench
- Vertex AI Workbench è un ambiente di sviluppo unificato basato su blocchi note Jupyter che supporta l'intero flusso di lavoro di data science, dall'esplorazione e l'analisi dei dati allo sviluppo, all'addestramento e al deployment dei modelli. Vertex AI Workbench fornisce un'infrastruttura gestita e scalabile con integrazioni integrate ad altri servizi Google Cloud come BigQuery e Cloud Storage, consentendo ai data scientist di eseguire in modo efficiente le attività di machine learning senza gestire l'infrastruttura sottostante. Per saperne di più, consulta Introduzione a Vertex AI Workbench.
-
nodo worker
- Un nodo worker si riferisce a una singola macchina o istanza di calcolo all'interno di un cluster responsabile dell'esecuzione di attività o del lavoro. In sistemi come i cluster Kubernetes o Ray, i nodi sono le unità di calcolo fondamentali. Per saperne di più, consulta l'articolo Che cos'è l'HPC (computing ad alte prestazioni)?
-
pool di worker
- Componenti di un cluster Ray che eseguono attività distribuite. I pool di worker possono essere configurati con tipi di macchine specifici e supportano sia la scalabilità automatica sia quella manuale. Per maggiori informazioni, consulta la sezione Struttura del cluster di addestramento.
Prezzi
I prezzi di Ray su Agent Platform vengono calcolati come segue:
Le risorse di computing che utilizzi vengono addebitate in base alla configurazione della macchina che selezioni quando crei il cluster Ray su Gemini Enterprise Agent Platform. Per i prezzi di Ray su Agent Platform, consulta la pagina dei prezzi.
Per quanto riguarda i cluster Ray, ti viene addebitato un costo solo durante gli stati RUNNING e UPDATING . Non vengono addebitati altri stati. L'importo addebitato si basa sulle dimensioni effettive del cluster al momento.
Quando esegui attività utilizzando il cluster Ray su Gemini Enterprise Agent Platform, i log vengono generati e addebitati automaticamente in base ai prezzi di Cloud Logging.
Se esegui il deployment del modello in un endpoint per le inferenze online, consulta la sezione "Previsione e spiegazione" della pagina dei prezzi di Gemini Enterprise Agent Platform.
Se utilizzi BigQuery con Ray su Agent Platform, consulta Prezzi di BigQuery.