

本頁說明如何查看及解讀模型評估結果。
查看評估結果
定義評估工作後,請執行工作以取得評估結果,步驟如下:
from vertexai.evaluation import EvalTask
eval_result = EvalTask(
dataset=DATASET,
metrics=[METRIC_1, METRIC_2, METRIC_3],
experiment=EXPERIMENT_NAME,
).evaluate(
model=MODEL,
experiment_run=EXPERIMENT_RUN_NAME,
)
EvalResult 類別代表評估作業的結果,具有下列屬性:
summary_metrics:評估執行作業的匯總評估指標字典。metrics_table:pandas.DataFrame資料表,內含評估資料集輸入內容、回應、說明和每列的指標結果。metadata:評估執行的實驗名稱和實驗執行名稱。
EvalResult 類別的定義如下:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: A dictionary of aggregated evaluation metrics for an evaluation run.
metrics_table: A pandas.DataFrame table containing evaluation dataset inputs,
responses, explanations, and metric results per row.
metadata: The experiment name and experiment run name for the evaluation run.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional["pd.DataFrame"] = None
metadata: Optional[Dict[str, str]] = None
使用輔助函式,評估結果會顯示在 Colab 筆記本中,如下所示:

以圖表呈現評估結果
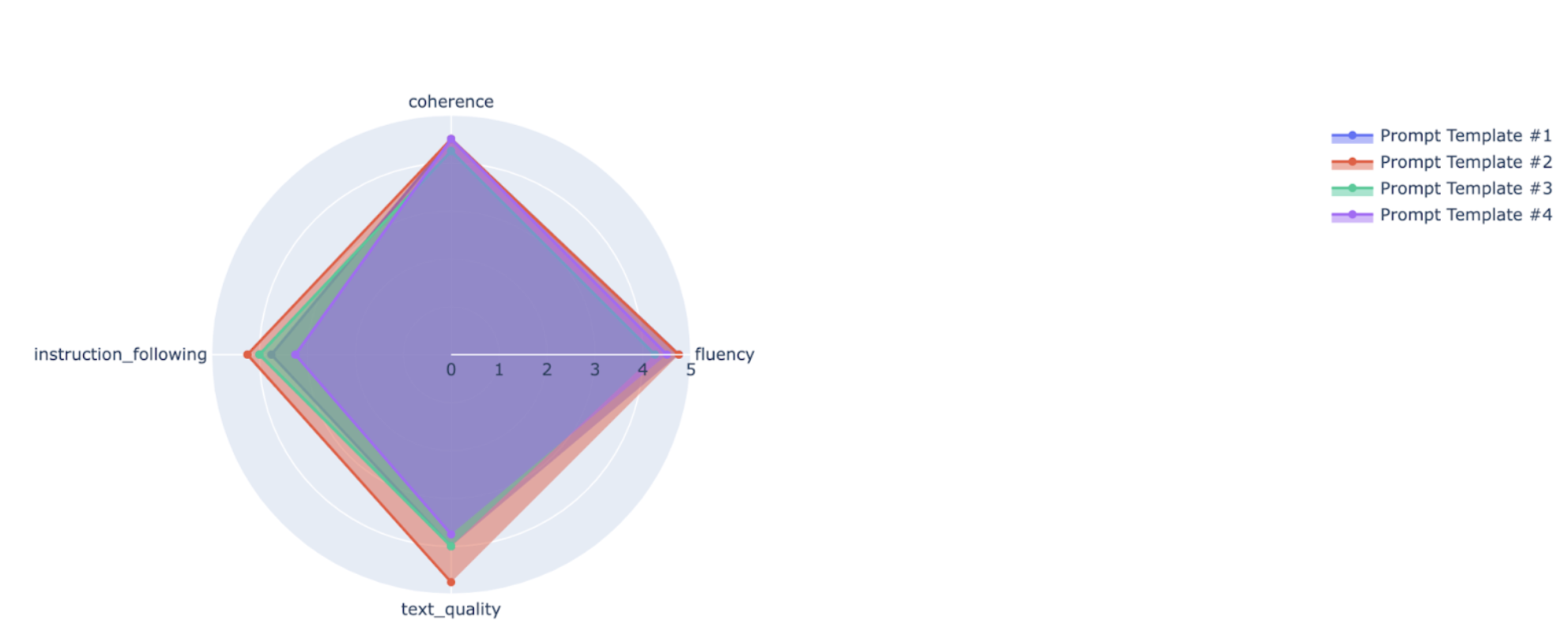
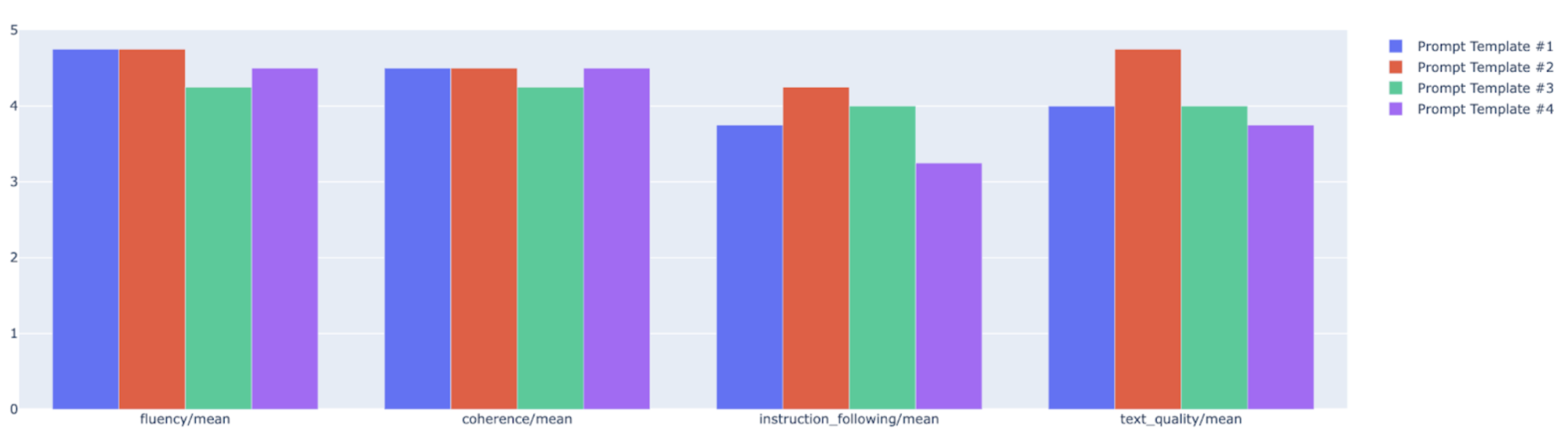
您可以在雷達圖或長條圖中繪製摘要指標,以便比較不同評估執行的結果。這項視覺化功能有助於評估不同模型和不同提示範本。
在下列範例中,我們以視覺化方式呈現四個指標 (連貫性、流暢度、遵循指令和整體文字品質),這些指標是使用四種不同提示範本生成的回應。從雷達圖和長條圖,我們可以推斷提示範本 #2 在所有四項指標中,表現都優於其他範本。這點從指令遵循和文字品質的顯著高分可見一斑。根據這項分析,在四個選項中,提示範本 #2 似乎是最有效的選擇。
瞭解指標結果
下表列出 metrics_table 和 summary_metrics 分別包含的執行個體層級和匯總結果各項元件,適用於 PointwiseMetric、PairwiseMetric 和以運算為基礎的指標:
PointwiseMetric
執行個體層級結果
| 欄 | 說明 |
|---|---|
| 回應 | 模型針對提示生成的內容。 |
| 分數 | 根據評分量表和準則給予的回覆評分。分數可以是二元值 (0 和 1)、李克特量表 (1 到 5,或 -2 到 2),或是浮點數 (0.0 到 1.0)。 |
| 說明 | 評審模型給予該分數的原因。我們使用連鎖思維推理,引導法官模型說明每項判決背後的理由。強制讓評估模型進行推論,可提高評估準確度。 |
匯總結果
| 欄 | 說明 |
|---|---|
| 平均分數 | 所有執行個體的平均分數。 |
| 標準差 | 所有分數的標準差。 |
PairwiseMetric
執行個體層級結果
| 欄 | 說明 |
|---|---|
| 回應 | 候選模型針對提示生成的回覆。 |
| baseline_model_response | 基準模型為提示生成的內容。 |
| pairwise_choice | 回覆較好的模型。可能的值為 CANDIDATE、BASELINE 或 TIE。 |
| 說明 | 法官模型選擇的原因。 |
匯總結果
| 欄 | 說明 |
|---|---|
| candidate_model_win_rate | 評估模型判定候選模型回覆較佳的回覆比例,範圍介於 0 到 1。 |
| baseline_model_win_rate | 評估模型判定基準模型回覆較佳的次數,占總回覆次數的比例。範圍介於 0 到 1 之間。 |
以運算為基礎的指標
執行個體層級結果
| 欄 | 說明 |
|---|---|
| 回應 | 正在評估模型的回覆。 |
| 參考資料 | 參考回覆。 |
| 分數 | 系統會針對每組回應和參考資料計算分數。 |
匯總結果
| 欄 | 說明 |
|---|---|
| 平均分數 | 所有執行個體的平均分數。 |
| 標準差 | 所有分數的標準差。 |
範例
本節範例說明如何解讀評估結果。
範例 1:逐點評估
以下範例顯示 TEXT_QUALITY 的逐點評估執行個體。TEXT_QUALITY 指標的逐點評估分數為 4 分 (1 到 5 分),表示回覆良好。此外,評估結果中的說明會指出評估模型認為預測結果應得 4 分的原因,而非更高或更低的分數。
資料集
prompt:以五歲小孩能理解的方式,總結下列文字:「Social Media Platform Faces Backlash Over Content Moderation Policies\nA prominent social media platform finds itself embroiled in controversy as users and content creators express discontent over its content moderation policies. 使用者指控平台審查偏頗、執法不一致,並壓制特定觀點,引發眾怒,他們認為平台正在扼殺言論自由。另一方面,該平台聲稱其政策旨在維護安全且包容的線上環境。這項爭議引發了更廣泛的問題,包括社群媒體在塑造公眾討論中的角色,以及平台在策劃線上內容時應負的責任。」response:「人們對某個網站感到不滿,因為他們認為該網站對使用者發布的內容不夠公平。有些人說該網站阻止他們暢所欲言,但網站表示他們是為了保護所有人的安全。這讓大家開始思考,網站是否應該控管使用者在網路上發表的內容。」
結果
score:4,explanation:回覆中的摘要遵循指令,以五歲兒童也能理解的方式歸納內容,並根據內容提供重要細節。不過,回覆中使用的語言有點冗長。
範例 2:逐對評估
這個範例是針對 PAIRWISE_QUESTION_ANSWERING_QUALITY 進行的成對比較評估。pairwise_choice 結果顯示,相較於基準回覆「法國是個國家」,評估模型更偏好候選回覆「法國是位於西歐的國家」,以回答提示中的問題。與逐點結果類似,系統也會提供說明,解釋為何候選人回覆比基準回覆更合適 (在本例中,候選人回覆更有幫助)。
資料集
prompt:「請根據以下段落回答法國位於何處?法國位於西歐,與比利時、盧森堡、德國、瑞士、義大利、摩納哥、西班牙和安道爾接壤。法國的海岸線沿著英吉利海峽、北海、大西洋和地中海延伸。法國以悠久的歷史、艾菲爾鐵塔等著名地標和美味佳餚聞名,是歐洲和全球的主要文化和經濟強國。」response: "法國位於西歐。",baseline_model_response: "France is a country.",
結果
pairwise_choice:CANDIDATE,explanation:BASELINE 回覆內容有根據,但未完整回答問題。不過,CANDIDATE 回覆正確,並提供法國位置的實用詳細資料。