

O Ray é um framework de código aberto para dimensionar aplicativos de IA e Python. O Ray fornece a infraestrutura para realizar computação distribuída e processamento paralelo para seu fluxo de trabalho de machine learning (ML).
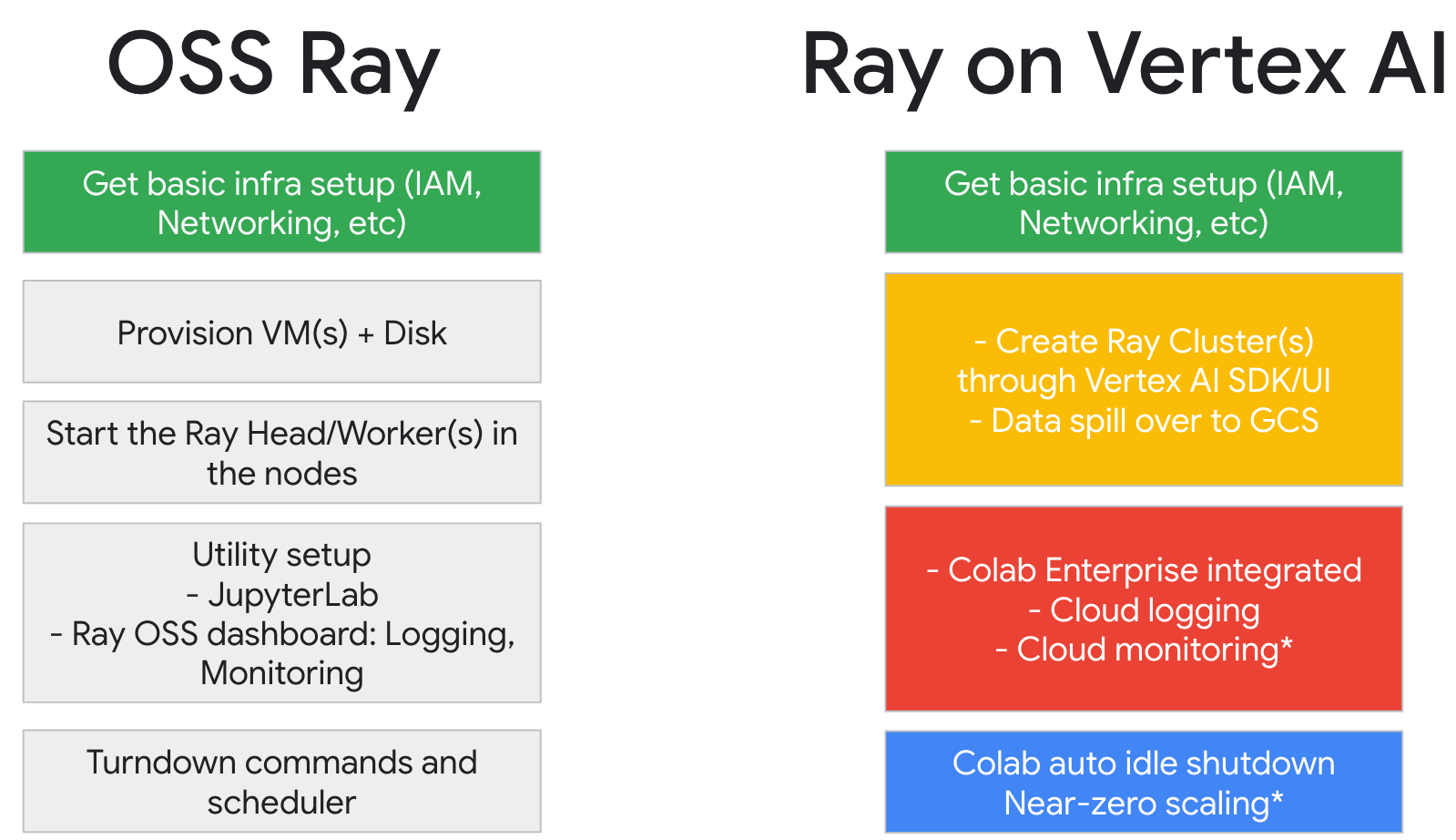
Se você já usa o Ray, pode usar o mesmo código do Ray de código aberto para criar programas e desenvolver aplicativos na Plataforma de Agentes do Gemini Enterprise com alterações mínimas. A partir daí, é possível usar as integrações da Gemini Enterprise Agent Platform com outros serviços do Google Cloud Google Cloud, como a Vertex AI Inference e o BigQuery, como parte do fluxo de trabalho de machine learning.
Se você já usa a Gemini Enterprise Agent Platform e precisa de uma maneira mais simples de gerenciar recursos de computação, use o código do Ray para dimensionar o treinamento.
Fluxo de trabalho para usar o Ray na Agent Platform
Use o Colab Enterprise e o SDK da Agent Platform para Python para se conectar ao cluster do Ray.
| Etapas | Descrição |
|---|---|
| 1. Configuração do Ray na Agent Platform | Configure seu projeto do Google, instale a versão do SDK do Agent Platform para Python que inclui a funcionalidade do Ray Client e configure uma rede de peering de VPC (opcional). |
| 2. Criar um cluster do Ray na plataforma de agentes do Gemini Enterprise | Crie um cluster do Ray na Gemini Enterprise Agent Platform. O papel de administrador da Gemini Enterprise Agent Platform é obrigatório. |
| 3. Desenvolver um aplicativo Ray na Gemini Enterprise Agent Platform | Conectar-se a um cluster do Ray na Gemini Enterprise Agent Platform e desenvolver um aplicativo. A função do usuário da Gemini Enterprise Agent Platform é obrigatória. |
| 4. (Opcional) Usar o Ray na Agent Platform com o BigQuery | Ler, gravar e transformar dados com o BigQuery. |
| 5. (Opcional) Implante um modelo na Gemini Enterprise Agent Platform e receba inferências | Implante um modelo em um endpoint on-line da Gemini Enterprise Agent Platform e receba inferências. |
| 6. Monitorar seu cluster do Ray na plataforma de agentes do Gemini Enterprise | Monitorar os registros gerados no Cloud Logging e as métricas no Cloud Monitoring. |
| 7. Excluir um cluster do Ray na Gemini Enterprise Agent Platform | Excluir um cluster do Ray na Gemini Enterprise Agent Platform para evitar faturamentos desnecessários. |
Visão geral
Os clusters Ray são integrados para garantir a disponibilidade de capacidade para ML essenciais. cargas de trabalho ou durante períodos de pico. Ao contrário dos jobs personalizados, libera o recurso após a conclusão do job, os clusters Ray permanecem disponível até a exclusão.
Observação: use clusters Ray de longa duração nestes cenários:
- Se você enviar o mesmo job do Ray várias vezes, poderá se beneficiar do armazenamento em cache de imagens e dados com a execução dos jobs no mesmo cluster do Ray de longa duração.
- Se você executar muitos jobs do Ray de curta duração em que o tempo de processamento real menor que o tempo de inicialização da tarefa, pode ser vantajoso ter um um cluster de longa duração.
Os clusters do Ray na Gemini Enterprise Agent Platform podem ser configurados com conectividade pública ou particular. Os diagramas a seguir mostram a arquitetura e o fluxo de trabalho do Ray na Agent Platform. Consulte Conectividade pública ou particular para mais informações.
Arquitetura com conectividade pública
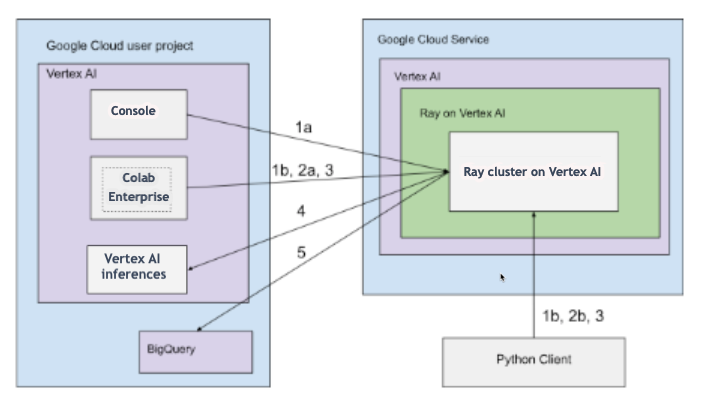
Crie o cluster do Ray na Gemini Enterprise Agent Platform usando as seguintes opções:
a. Use o Google Cloud console para criar o cluster do Ray na Gemini Enterprise Agent Platform.
b. Crie o cluster do Ray na Gemini Enterprise Agent Platform usando o SDK da Agent Platform para Python.
Conecte-se ao cluster do Ray na Gemini Enterprise Agent Platform para ter desenvolvimento interativo usando as seguintes opções:
a. Use o Colab Enterprise no console Google Cloud para uma conexão perfeita.
b. Use qualquer ambiente Python acessível à Internet pública.
Desenvolva seu aplicativo e treine o modelo no cluster Ray na Gemini Enterprise Agent Platform:
Use o SDK da Agent Platform para Python no ambiente de sua preferência (Colab Enterprise ou qualquer notebook Python).
Crie um script Python usando o ambiente de sua preferência.
Envie um job do Ray para o cluster do Ray na Gemini Enterprise Agent Platform usando o SDK da Agent Platform para Python, a CLI do Ray Job ou a API Ray Job Submission.
Implante o modelo treinado em um endpoint on-line da Gemini Enterprise Agent Platform para inferência em tempo real.
Use o BigQuery para gerenciar seus dados.
Arquitetura com VPC
O diagrama a seguir mostra a arquitetura e o fluxo de trabalho do Ray na Agent Platform depois de configurar o Google Cloud projeto e a rede VPC, o que é opcional:
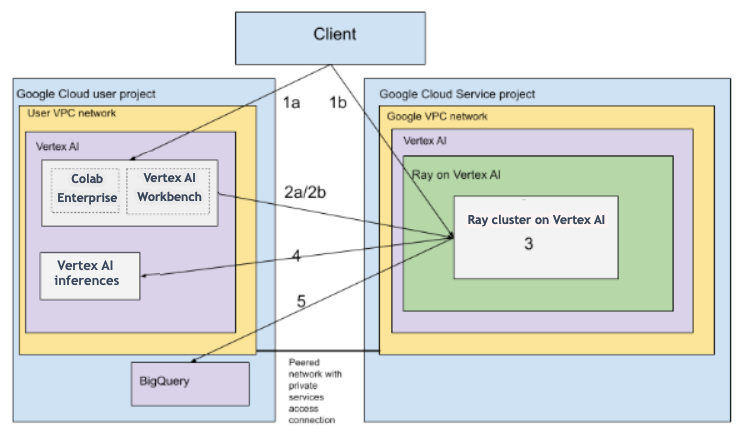
Configure (a) o projeto do Google e (b) a rede VPC.
Crie o cluster do Ray na Gemini Enterprise Agent Platform usando as seguintes opções:
a. Use o Google Cloud console para criar o cluster do Ray na Gemini Enterprise Agent Platform.
b. Crie o cluster do Ray na Gemini Enterprise Agent Platform usando o SDK da Agent Platform para Python.
Conecte-se ao cluster do Ray na Gemini Enterprise Agent Platform por uma rede com peering de VPC usando as seguintes opções:
Use o Colab Enterprise no console doGoogle Cloud .
Use um notebook do Gemini Enterprise Agent Platform Workbench.
Desenvolva seu aplicativo e treine o modelo no cluster Ray na Gemini Enterprise Agent Platform usando as seguintes opções:
Use o SDK da Agent Platform para Python no ambiente de sua preferência (notebook do Colab Enterprise ou do Agent Platform Workbench).
Crie um script Python usando o ambiente de sua preferência. Envie um job do Ray ao cluster do Ray na Gemini Enterprise Agent Platform usando o SDK da Agent Platform para Python, a CLI do job do Ray ou o painel do Ray.
Implante o modelo treinado em um endpoint on-line da Gemini Enterprise Agent Platform para fazer inferências.
Use o BigQuery para gerenciar seus dados.
Terminologia
Para uma lista completa de termos, consulte o glossário da Agent Platform para IA preditiva.
-
escalonamento automático
- O escalonamento automático é a capacidade de um recurso de computação, como um pool de trabalhadores de um cluster do Ray, ajustar automaticamente o número de nós para cima ou para baixo com base nas demandas de carga de trabalho, otimizando a utilização de recursos e o custo. Para mais informações, consulte Escalonar clusters do Ray na Vertex AI: escalonamento automático.
-
inferência em lote
- A inferência em lote usa um grupo de solicitações de inferência e gera os resultados em um arquivo. Para mais informações, consulte Visão geral de como receber inferências na Vertex AI.
-
BigQuery
- O BigQuery é um data warehouse empresarial totalmente gerenciado, sem servidor e altamente escalonável fornecido pelo Google Cloud, projetado para analisar conjuntos de dados enormes usando consultas SQL em velocidades incrivelmente altas. O BigQuery oferece Business Intelligence e análises avançadas sem exigir que os usuários gerenciem nenhuma infraestrutura. Para mais informações, consulte Do data warehouse à plataforma de IA e dados autônomos.
-
Cloud Logging
- O Cloud Logging é um serviço de geração de registros totalmente gerenciado e em tempo real fornecido pelo Google Cloud. Com ele, é possível coletar, armazenar, analisar e monitorar registros de todos os recursos do Google Cloud, aplicativos locais e até mesmo fontes personalizadas. O Cloud Logging centraliza o gerenciamento de registros, o que facilita a solução de problemas, a auditoria e a compreensão do comportamento e da integridade dos seus aplicativos e da infraestrutura. Para mais informações, consulte Visão geral do Cloud Logging.
-
Colab Enterprise
- O Colab Enterprise é um ambiente de notebook Jupyter gerenciado e colaborativo que traz a experiência do usuário do Google Colab para o Google Cloud, oferecendo recursos de segurança e compliance de nível empresarial. O Colab Enterprise oferece uma experiência centrada em notebooks e sem configuração, com recursos de computação gerenciados pela Vertex AI, e se integra a outros serviços do Google Cloud, como o BigQuery. Para mais informações, consulte Introdução ao Colab Enterprise.
-
imagem do contêiner personalizada
- Uma imagem de contêiner personalizada é um pacote executável independente que inclui o código do aplicativo do usuário, o tempo de execução, as bibliotecas, as dependências e a configuração do ambiente. No contexto do Google Cloud, principalmente da Vertex AI, ele permite que o usuário empacote o código de treinamento de machine learning ou o aplicativo de serviço com as dependências exatas, garantindo a capacidade de reprodução e permitindo que o usuário execute uma carga de trabalho em serviços gerenciados usando versões de software específicas ou configurações exclusivas não fornecidas por ambientes padrão. Para mais informações, consulte Requisitos de contêineres personalizados para inferência.
-
endpoint
- Recursos em que é possível implantar modelos treinados para disponibilizar inferências. Para mais informações, consulte Escolher um tipo de endpoint.
-
Permissões do Identity and Access Management (IAM)
- As permissões do Identity and Access Management (IAM) são recursos granulares específicos que definem quem pode fazer o quê em quais recursos do Google Cloud. Eles são atribuídos a principais (como usuários, grupos ou contas de serviço) por meio de papéis, permitindo o controle preciso do acesso a serviços e dados em um projeto na nuvem ou organização do Google Cloud. Para mais informações, consulte Controle de acesso com o IAM.
-
inferência
- No contexto da plataforma Vertex AI, a inferência se refere ao processo de execução de pontos de dados em um modelo de machine learning para calcular uma saída, como uma única pontuação numérica. Esse processo também é conhecido como "operar um modelo de machine learning" ou "colocar um modelo de machine learning em produção". A inferência é uma etapa importante no fluxo de trabalho de machine learning, porque permite que os modelos sejam usados para fazer inferências sobre novos dados. Na Vertex AI, a inferência pode ser realizada de várias maneiras, incluindo inferência em lote e inferência on-line. A inferência em lote envolve a execução de um grupo de solicitações de inferência e a geração dos resultados em um arquivo, enquanto a inferência on-line permite inferências em tempo real em pontos de dados individuais.
-
Network File System (NFS)
- Um sistema cliente/servidor que permite aos usuários acessar arquivos em uma rede e tratá-los como se estivessem em um diretório de arquivos local. Para mais informações, consulte Montar um compartilhamento do Network File System.
-
Inferência on-line
- Obter inferências em instâncias individuais de forma síncrona. Para mais informações, consulte Inferência on-line.
-
recurso permanente
- Um tipo de recurso de computação da Vertex AI, como um cluster Ray, que permanece alocado e disponível até ser excluído explicitamente. Isso é útil para o desenvolvimento iterativo e reduz a sobrecarga de inicialização entre jobs. Para mais informações, consulte Receber informações sobre recursos permanentes.
-
pipeline
- Os pipelines de ML são fluxos de trabalho de ML portáteis e escalonáveis baseados em contêineres. Para mais informações, consulte Introdução ao Vertex AI Pipelines.
-
Contêiner pré-criado
- Imagens de contêiner fornecidas pela Vertex AI que vêm pré-instaladas com frameworks e dependências comuns de ML, simplificando a configuração para jobs de treinamento e inferência. Para mais informações, consulte Contêineres pré-criados para treinamento sem servidor .
-
Private Service Connect (PSC)
- O Private Service Connect é uma tecnologia que permite que os clientes do Compute Engine mapeiem IPs particulares na rede deles para outra rede VPC ou para APIs do Google. Para mais informações, consulte Private Service Connect.
-
Cluster do Ray na Vertex AI
- Um cluster do Ray na Vertex AI é um cluster gerenciado de nós de computação que pode ser usado para executar aplicativos distribuídos de machine learning (ML) e Python. Ele fornece a infraestrutura para realizar computação distribuída e processamento paralelo para seu fluxo de trabalho de ML. Os clusters Ray são integrados à Vertex AI para garantir a disponibilidade de capacidade para cargas de trabalho essenciais de ML ou durante os períodos de pico. Ao contrário dos jobs personalizados, em que o serviço de treinamento libera o recurso após a conclusão do job, os clusters Ray permanecem disponíveis até serem excluídos. Para mais informações, consulte Visão geral do Ray na Vertex AI.
-
Ray na Vertex AI (RoV)
- O Ray na Vertex AI foi projetado para que você possa usar o mesmo código aberto Ray para escrever programas e desenvolver aplicativos na Vertex AI com alterações mínimas. Para mais informações, consulte Visão geral do Ray na Vertex AI.
-
SDK do Ray na Vertex AI para Python
- O SDK do Ray na Vertex AI para Python é uma versão do SDK da Vertex AI para Python que inclui a funcionalidade do Ray Client, do conector do Ray para BigQuery, do gerenciamento de clusters do Ray na Vertex AI e das inferências na Vertex AI. Para mais informações, consulte Introdução ao SDK da Vertex AI para Python.
-
SDK do Ray na Vertex AI para Python
- O SDK do Ray na Vertex AI para Python é uma versão do SDK da Vertex AI para Python que inclui a funcionalidade do Ray Client, do conector do Ray para BigQuery, do gerenciamento de clusters do Ray na Vertex AI e das inferências na Vertex AI. Para mais informações, consulte Introdução ao SDK da Vertex AI para Python.
-
conta de serviço
- As contas de serviço são contas especiais do Google Cloud usadas por aplicativos ou máquinas virtuais para fazer chamadas de API autorizadas para os serviços do Google Cloud. Ao contrário das contas de usuário, elas não estão vinculadas a uma pessoa, mas atuam como uma identidade para seu código, permitindo acesso seguro e programático aos recursos sem exigir credenciais humanas. Para mais informações, consulte Visão geral das contas de serviço.
-
Vertex AI Workbench
- O Vertex AI Workbench é um ambiente de desenvolvimento unificado baseado em notebook do Jupyter que oferece suporte a todo o fluxo de trabalho de ciência de dados, desde a análise e exploração de dados até o desenvolvimento, treinamento e implantação de modelos. O Vertex AI Workbench oferece uma infraestrutura gerenciada e escalonável com integrações integradas a outros serviços do Google Cloud, como BigQuery e Cloud Storage. Assim, os cientistas de dados podem realizar tarefas de machine learning com eficiência sem gerenciar a infraestrutura subjacente. Para mais informações, consulte Introdução ao Vertex AI Workbench.
-
nó de trabalho
- Um nó de trabalho se refere a uma máquina ou instância computacional individual em um cluster responsável por executar tarefas ou realizar trabalhos. Em sistemas como clusters do Kubernetes ou do Ray, os nós são as unidades fundamentais de computação. Para mais informações, consulte O que é a computação de alto desempenho (HPC)?.
-
pool de workers
- Componentes de um cluster do Ray que executam tarefas distribuídas. Os pools de workers podem ser configurados com tipos de máquinas específicos e oferecem suporte ao escalonamento automático e manual. Para mais informações, consulte Estrutura do cluster de treinamento.
Preços
O preço do Ray na Agent Platform é calculado da seguinte maneira:
Os recursos de computação que você usa são cobrados com base na configuração da máquina selecionada ao criar o cluster do Ray na Gemini Enterprise Agent Platform. Para conferir os preços do Ray na Agent Platform, consulte a página de preços.
Com relação aos clusters do Ray, você só é cobrado durante os estados de EXECUÇÃO e ATUALIZAÇÃO. Nenhum outro estado é cobrado. O valor cobrado é baseado no tamanho real do cluster no momento.
Quando você executa tarefas usando o cluster do Ray na Gemini Enterprise Agent Platform, os registros são gerados e cobrados automaticamente com base nos preços do Cloud Logging.
Se você implantar o modelo em um endpoint para receber inferências on-line, consulte a seção "Prediction e explicação" da página de preços da Gemini Enterprise Agent Platform.
Se você usa o BigQuery com o Ray na Agent Platform, consulte Preços do BigQuery.