

Questa pagina illustra l'esecuzione di previsioni dal modello di classificazione delle immagini e la visualizzazione di queste previsioni in un'app web.
Questo tutorial è composto da più pagine:Addestramento di un modello di classificazione delle immagini personalizzato.
Esecuzione di previsioni da un modello di classificazione delle immagini personalizzato.
Ogni pagina presuppone che tu abbia già eseguito le istruzioni delle pagine precedenti del tutorial.
Il resto di questo documento presuppone che tu stia utilizzando lo stesso ambiente Cloud Shell che hai creato seguendo la prima pagina di questo tutorial. Se la sessione Cloud Shell originale non è più aperta, puoi tornare all'ambiente procedendo nel seguente modo:-
Nella console Google Cloud , attiva Cloud Shell.
-
Nella sessione di Cloud Shell, esegui questo comando:
cd hello-custom-sample
Creazione di un endpoint
Per ottenere previsioni online dal modello ML che hai addestrato seguendo la pagina precedente di questo tutorial, crea un endpoint Agent Platform. Gli endpoint erogano previsioni online da uno o più modelli.
Nella console Google Cloud , nella sezione Piattaforma dell'agente, vai alla pagina Modelli.
Trova la riga del modello che hai addestrato nel passaggio precedente di questo tutorial,
hello_custom, e fai clic sul nome del modello per aprire la pagina dei dettagli.Nella scheda Deployment e test, fai clic su Deployment su endpoint per aprire il riquadro Deployment su endpoint.
Nel passaggio Definisci l'endpoint, aggiungi alcune informazioni di base per l'endpoint:
Seleziona Crea nuovo endpoint.
Nel campo Nome endpoint, inserisci
hello_custom.Nella sezione Impostazioni del modello, assicurati di visualizzare il nome del tuo modello, chiamato anche
hello_custom. Specifica le seguenti impostazioni del modello:Nel campo Suddivisione del traffico, inserisci
100. Agent Platform supporta la suddivisione del traffico per un endpoint in più modelli, ma questo tutorial non utilizza questa funzionalità.Nel campo Numero minimo di nodi di computing, inserisci
1.Nell'elenco a discesa Tipo di macchina, seleziona n1-standard-2 dalla sezione Standard.
Fai clic su Fine.
Nella sezione Logging, assicurati che entrambi i tipi di logging delle previsioni siano abilitati.
Fai clic su Continua.
Nel passaggio Dettagli endpoint, conferma che l'endpoint verrà implementato in
us-central1 (Iowa).Non selezionare la casella di controllo Utilizza una chiave di crittografia gestita dal cliente (CMEK). Questo tutorial non utilizza CMEK.
Fai clic su Esegui il deployment per creare l'endpoint ed eseguire il deployment del modello sull'endpoint.
Dopo alcuni minuti, viene visualizzato accanto al nuovo endpoint nella tabella Endpoint. Allo stesso tempo, ricevi anche un'email che indica che hai creato correttamente l'endpoint e hai eseguito il deployment del modello nell'endpoint.
Esegui il deployment di una funzione Cloud Run
Puoi ottenere previsioni dall'endpoint Agent Platform che hai appena
creato inviando richieste all'interfaccia REST dell'API Agent Platform. Tuttavia, solo i
soggetti con l'autorizzazione aiplatform.endpoints.predict possono inviare richieste di previsione online. Non puoi rendere pubblico l'endpoint in modo che chiunque possa inviare richieste, ad esempio tramite un'app web.
In questa sezione, esegui il deployment del codice in Cloud Run Functions per gestire
le richieste non autenticate. Il codice campione che hai scaricato quando hai letto la
prima pagina di questo tutorial contiene il codice per questa
funzione Cloud Run nella directory function/. (Facoltativo) Esegui il comando
seguente per esplorare il codice della funzione Cloud Run:
less function/main.py
Il deployment della funzione ha i seguenti scopi:
Puoi configurare una funzione Cloud Run per ricevere richieste non autenticate. Inoltre, le funzioni vengono eseguite utilizzando un account di servizio con il ruolo Editor per impostazione predefinita, che include l'autorizzazione
aiplatform.endpoints.predictnecessaria per ottenere le previsioni dall'endpoint di Agent Platform.Questa funzione esegue anche un'utile pre-elaborazione delle richieste. L'endpoint Agent Platform prevede che le richieste di previsione abbiano il formato del primo livello del grafico TensorFlow Keras addestrato: un tensore di numeri in virgola mobile normalizzati con dimensioni fisse. La funzione prende l'URL di un'immagine come input e pre-elabora l'immagine in questo formato prima di richiedere una previsione dall'endpoint Agent Platform.
Per eseguire il deployment della funzione Cloud Run:
Nella console Google Cloud , nella sezione Piattaforma dell'agente, vai alla pagina Endpoint.
Trova la riga dell'endpoint che hai creato nella sezione precedente, denominata
hello_custom. In questa riga, fai clic su Richiesta di esempio per aprire il riquadro Richiesta di esempio.Nel riquadro Richiesta di esempio, individua la riga di codice shell che corrisponde al seguente pattern:
ENDPOINT_ID="ENDPOINT_ID"
ENDPOINT_ID è un numero che identifica questo particolare endpoint.
Copia questa riga di codice ed eseguila nella sessione di Cloud Shell per impostare la variabile
ENDPOINT_ID.Esegui questo comando nella sessione di Cloud Shell per eseguire il deployment della funzione Cloud Run:
gcloud functions deploy classify_flower \ --region=us-central1 \ --source=function \ --runtime=python37 \ --memory=2048MB \ --trigger-http \ --allow-unauthenticated \ --set-env-vars=ENDPOINT_ID=${ENDPOINT_ID}
Esegui il deployment di un'app web per inviare richieste di previsione
Infine, ospita un'app web statica su Cloud Storage per ottenere previsioni dal modello di ML addestrato. L'app web invia richieste alla tua funzione Cloud Run, che le pre-elabora e ottiene previsioni dall'endpoint della piattaforma Agent.
La directory webapp del codice campione che hai scaricato contiene un'app web di esempio. Nella sessione di Cloud Shell, esegui questi comandi per preparare ed eseguire il deployment dell'app web:
Imposta alcune variabili shell da utilizzare per i comandi nei passaggi successivi:
PROJECT_ID=PROJECT_ID BUCKET_NAME=BUCKET_NAMESostituisci quanto segue:
- PROJECT_ID: il tuo Google Cloud ID progetto.
- BUCKET_NAME: il nome del bucket Cloud Storage che hai creato seguendo la prima pagina di questo tutorial.
Modifica l'app per fornirle l'URL di attivazione della tua funzione Cloud Run:
echo "export const CLOUD_FUNCTION_URL = 'https://us-central1-${PROJECT_ID}.cloudfunctions.net/classify_flower';" \ > webapp/function-url.jsCarica la directory
webappnel bucket Cloud Storage:gcloud storage cp webapp gs://${BUCKET_NAME}/ --recursiveRendi pubblicamente leggibili i file dell'app web che hai appena caricato:
gcloud storage objects update gs://${BUCKET_NAME}/webapp/** --add-acl-grant=entity=allUsers,role=READEROra puoi andare al seguente URL per aprire l'app web e ricevere previsioni:
https://storage.googleapis.com/BUCKET_NAME/webapp/index.html
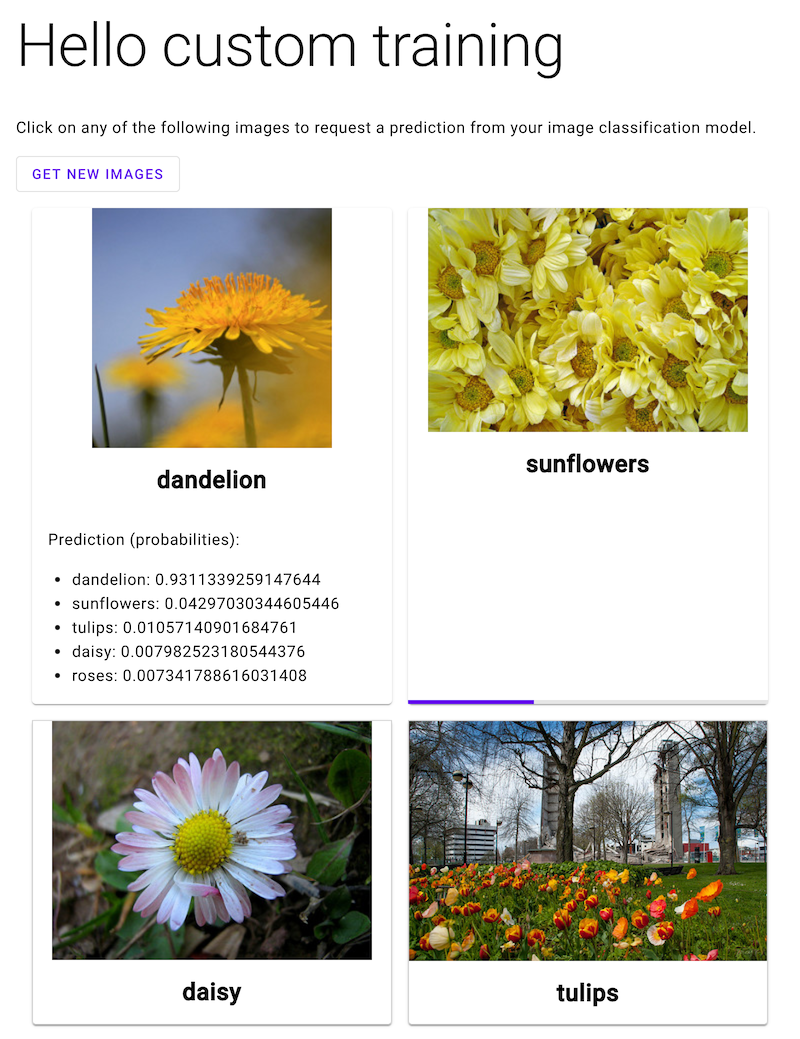
Apri l'app web e fai clic sull'immagine di un fiore per vedere la classificazione del tipo di fiore nel modello ML. L'app web mostra la previsione sotto forma di elenco di tipi di fiori e la probabilità che l'immagine contenga ciascun tipo di fiore.
Nello screenshot seguente, l'app web ha già ricevuto una previsione e sta inviando un'altra richiesta di previsione.
Passaggi successivi
Segui le istruzioni riportate nell'ultima pagina del tutorial per liberare spazio dalle risorse che hai creato.