

生成式 AI 評估服務提供企業級工具,可客觀、資料導向的方式評估生成式 AI 模型,並支援及輔助多項開發工作,例如模型遷移、提示編輯和微調。
Gen AI Evaluation Service 功能
Gen AI Evaluation Service 的定義特徵是能夠使用調整型評分量表,針對每個提示詞進行一組量身打造的通過或失敗測試。評估評分量表類似於軟體開發中的單元測試,旨在提升模型在各種工作中的效能。
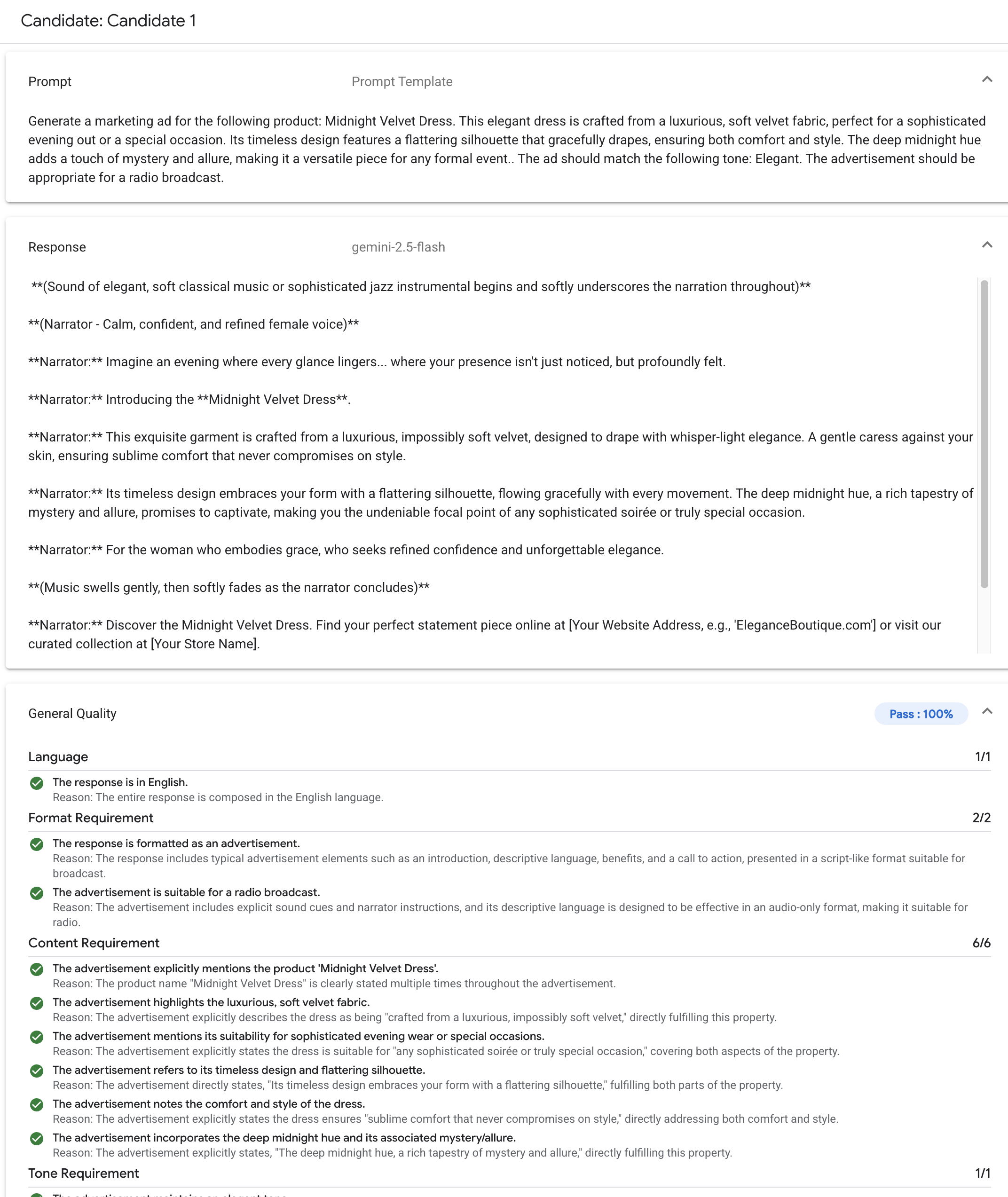
Gen AI Evaluation Service 支援下列常見的評估方法:
自適性評量表 (建議):為資料集中的每個提示生成一組專屬的及格/不及格評量表。
靜態評分標準:為所有提示套用一組固定的評分標準。
以運算為基礎的指標:如有真值,請使用確定性演算法,例如
ROUGE或BLEU。自訂函式:在 Python 中定義自己的評估邏輯,以滿足特殊需求。
生成評估用資料集
您可以透過下列方法建立評估資料集:
上傳檔案,內含完整的提示例項,或提供提示範本和相應的變數值檔案,以填入完整的提示。
直接從正式版記錄檔取樣,評估模型的實際使用情形。
使用合成資料生成功能,為任何提示範本生成大量一致的範例。
支援的介面
您可以使用下列介面定義及執行評估:
Google Cloud 控制台:網頁版使用者介面,提供導覽式端對端工作流程。管理資料集、執行評估,以及深入瞭解互動式報表和視覺化內容。請參閱「使用控制台執行評估」。
Python SDK:在 Colab 或 Jupyter 環境中,以程式輔助方式執行評估,並直接並列比較模型。請參閱「使用 Agent Platform SDK 中的 GenAI 用戶端執行評估」
用途
透過 Gen AI 評估服務,您可以瞭解模型在特定工作和獨特標準方面的表現,並取得無法從公開排行榜和一般基準獲得的寶貴洞察。這項服務可支援重要的開發工作,包括:
模型遷移:比較模型版本,瞭解行為差異,並據此微調提示和設定。
找出最佳模型:直接比較 Google 和第三方模型在您資料上的成效,建立成效基準,並找出最適合您用途的模型。
改善提示:根據評估結果調整自訂作業。重新執行評估會建立緊密的意見回饋循環,針對變更提供即時量化意見回饋。
模型微調:對每次執行作業套用一致的評估條件,評估微調模型的品質。
代理評估:使用代理專屬指標 (例如代理追蹤記錄和回覆品質),評估代理的效能。
評估工作流程
完成評估通常需要經過下列步驟:
建立評估資料集:彙整反映特定用途的提示執行個體資料集。如果您打算使用以運算為基礎的指標,可以加入參考答案 (真值)。
定義評估指標:選擇要用來評估模型效能的指標。
生成模型回覆:選取一或多個模型,為資料集生成回覆。Agent Platform SDK 支援透過
LiteLLM呼叫的任何模型,而控制台則支援 Google Gemini 模型。執行評估:執行評估工作,根據所選指標評估各個模型的回覆。
解讀結果:查看匯總分數和個別回覆,分析模型效能。
評估指標
以下是與評估指標相關的核心概念:
評量表:評估 LLM 模型或應用程式回覆的標準。
指標:根據評分標準評估模型輸出內容的分數。
Gen AI Evaluation Service 提供下列類別的指標:
以評分量表為基礎的指標:將 LLM 納入評估工作流程,評估模型回覆品質。以評量表為準的評估方式適用於各種工作,特別是寫作品質、安全性及指令遵循程度,這些通常難以透過確定性演算法評估。
調整型評分量表 (建議使用):系統會針對每個提示詞動態生成評分量表,就像單元測試一樣。系統會針對資料集中每個提示詞,使用一組專屬的通過或未通過測試來評估回覆。評分量表可確保評估內容與所要求的工作有關,並提供客觀、可解釋且一致的結果。
自動調整評分量表通常是開始評估的最快方式,可確保每次評估都與評估的特定工作相關。
靜態評量表:明確定義評量表,並將同一份評量表套用至所有提示。系統會使用同一組以分數為依據的評估人員,評估回覆。每個提示的單一數值分數 (例如 1 到 5 分)。如果需要評估非常具體的維度,或是所有提示都必須使用完全相同的評量表,請使用靜態評量表。
以運算為基礎的指標:使用確定性演算法評估回覆,通常會使用基準真相。每個提示都會獲得一個數值分數 (例如 0.0 到 1.0)。適用於有基準真相,且可透過確定性方法比對的情況。
自訂函式指標 (僅限 Agent Platform SDK):透過 Python 函式定義自己的指標。
自動調整評分量表範例
每個提示的評估程序都採用兩階段系統:
生成評量表:這項服務會先分析提示,然後生成一份可驗證的具體測試清單 (即評量表),列出優質回覆應符合的條件。
評量表驗證:模型生成回覆後,這項服務會根據各項評量表評估回覆,並提供清楚的
Pass或Fail判決和理由。
最終結果會顯示匯總通過率,以及模型通過的評量標準詳細分類,提供可據以行動的洞察資料,協助您診斷問題及評估改善成效。
從高階主觀評分轉向細部客觀的測試結果,您就能採用評估導向的開發週期,並在建構生成式 AI 應用程式的過程中,導入軟體工程最佳做法。
以下範例顯示為一組提示生成的自動調整式評分標準:
使用者提示:Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
針對這項提示,評分量表生成步驟可能會產生下列評分量表:
評分量表 1:回覆內容是所提供文章的摘要。
評分量表 2:回應包含四個句子。
評分量表 3:回覆內容維持樂觀的語氣。
模型可能會產生以下回應:The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
在評分量表驗證期間,Gen AI Evaluation Service 會根據每個評分量表評估回覆:
評分量表 1:回覆內容是所提供文章的摘要。
認定結果:
Pass原因:回覆內容準確歸納出重點。
評分量表 2:回應包含四個句子。
認定結果:
Pass原因:回覆由四個不同的句子組成
評分量表 3:回覆內容維持樂觀的語氣。
認定結果:
Fail原因:最後一句帶入負面觀點,破壞了樂觀的語氣。
這項回覆的最終通過率為 66.7%。如要比較兩個模型,您可以針對同一組產生的測試評估模型回覆,並比較整體通過率。
開始進行評估
您可以使用控制台開始評估。
或者,您也可以使用 Agent Platform SDK 中的 GenAI 用戶端完成評估,如下列程式碼所示:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Agent Platform",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Gen AI Evaluation Service 提供兩種 Agent Platform SDK 介面:
Agent Platform SDK 中的 GenAI 用戶端 (建議使用) (搶先版)
from vertexai import client建議您使用 GenAI Client 進行評估,這個較新的介面可透過統一的 Client 類別存取,支援所有評估方法,並適用於包含模型比較、筆記本內視覺化和模型自訂洞察資訊的工作流程。
Agent Platform SDK 中的評估模組 (正式版)
from vertexai.evaluation import EvalTask評估模組是舊版介面,維護這個模組是為了回溯相容現有工作流程,但我們不再積極開發相關功能。可透過
EvalTask類別存取。這個方法支援標準 LLM 評估和以運算為基礎的指標,但不支援自適性評分標準等較新的評估方法。
支援的地區
Gen AI Evaluation Service 支援下列地區:
愛荷華州 (
us-central1)北維吉尼亞州 (
us-east4)奧勒岡州 (
us-west1)內華達州拉斯維加斯 (
us-west4)比利時 (
europe-west1)荷蘭 (
europe-west4)法國巴黎 (
europe-west9)
可用的筆記本
| 筆記本連結 | 說明 |
|---|---|
| 開始使用:快速評估生成式 AI | 簡介 Gen AI Evaluation Service。 |
| 使用 Gen AI Evaluation Service 評估第三方模型 | 示範如何使用 **Agent Platform SDK** 評估各種第三方模型,包括透過 API 存取的模型 (例如 OpenAI、Anthropic)、Vertex Model Garden 的模型即服務 (MaaS),以及自備模型 (BYOM) 端點。 |
| 使用 Gen AI Evaluation Service 遷移模型 | 說明如何使用 **Agent Platform SDK** 的 Gen AI 評估服務,比較兩個第一方模型 (例如 Gemini 2.0 Flash 與 Gemini 2.5 Flash)。重點包括使用預先定義的自適應評分標準指標,以及評估結果如何引導提示詞最佳化。此外,也涵蓋多候選項目評估、筆記本內視覺化和非同步批次評估等重要功能。 |
| 使用 Gen AI Evaluation Service 評估文字轉圖像品質 | 說明如何使用 Vertex AI SDK for Gen AI Evaluation Service,根據文字提示評估生成的圖片品質。本範例會示範如何使用預先定義的自適應評分標準 Gecko 指標。 |
| 使用 Gen AI Evaluation Service 評估文字轉影片品質 | 說明如何使用 Gen AI Evaluation Service 的 **Agent Platform SDK**,根據文字提示評估生成的影片品質。本範例會示範如何使用預先定義的自適應評分標準 Gecko 指標。 |