

這份入門指南將介紹如何透過 Gemini Enterprise Agent Platform 上的自訂模型取得推論結果。
學習目標
Gemini Enterprise Agent Platform 經驗程度:初學者
預估閱讀時間:15 分鐘
學習內容:
- 使用代管推論服務的好處。
- Gemini Enterprise Agent Platform 的批次推論運作方式。
- 瞭解 Agent Platform 的線上推論運作方式。
為什麼要使用代管推論服務?
假設您負責建立模型,輸入植物圖片並預測物種。您可能會先在筆記本中訓練模型,嘗試不同的超參數和架構。訓練好模型後,您可以在自選的 ML 框架中呼叫 predict 方法,測試模型品質。
這個工作流程非常適合用於實驗,但如果您想使用模型推論大量資料,或即時取得低延遲推論結果,就必須使用筆記本以外的工具。舉例來說,假設您想測量特定生態系統的生物多樣性,但不想讓人類手動識別和計算野外的植物物種,而是想使用這個機器學習模型分類大量圖片。如果您使用筆記本,可能會遇到記憶體限制。此外,取得所有資料的推論結果可能需要長時間執行工作,筆記本可能會逾時。
或者,如果想在應用程式中使用這個模型,讓使用者上傳植物圖片並立即辨識,該怎麼做?您需要將模型代管在筆記本以外的位置,供應用程式呼叫以進行推論。此外,您的模型不太可能會有穩定的流量,因此您需要一個可在必要時自動調度資源的服務。
在上述所有情況下,受管理推論服務都能減少託管及使用 ML 模型時的摩擦。本指南將介紹如何透過 Gemini Enterprise Agent Platform 從 ML 模型取得推論結果。請注意,本指南未涵蓋其他自訂項目、功能和服務介面。本指南僅提供概覽。如需更多資訊,請參閱 Gemini Enterprise Agent Platform 推論功能說明文件。
代管推論服務總覽
Agent Platform 支援批次和線上推論。
批次推論為非同步要求。如果您不需要立即取得回覆,並想透過單一要求處理累積的資料,就適合使用這類工作。在簡介中討論的範例中,這會是生物多樣性特徵化用途。
如要從傳遞至模型的資料即時取得低延遲推論結果,可以使用線上推論。在簡介中討論的範例中,這會是您想將模型嵌入應用程式的用途,協助使用者立即識別植物物種。
將模型上傳至 Gemini Enterprise Agent Platform Model Registry
如要使用推論服務,第一步是將訓練好的機器學習模型上傳至Model Registry。您可以在這個登錄中管理模型的生命週期。
建立模型資源
使用 Gemini Enterprise Agent Platform 自訂訓練服務訓練模型時,訓練作業完成後,模型會自動匯入登錄檔。如果略過這個步驟,或是在 Gemini Enterprise Agent Platform 以外訓練模型,可以透過 Google Cloud 控制台或 Agent Platform SDK for Python 手動上傳模型,方法是指定儲存模型構件的 Cloud Storage 位置。這些模型構件的格式可能是 savedmodel.pb、model.joblib 等,視您使用的機器學習架構而定。
將構件上傳至 Gemini Enterprise Agent Platform Model Registry 會建立 Model 資源,該資源會顯示在 Google Cloud 控制台中:
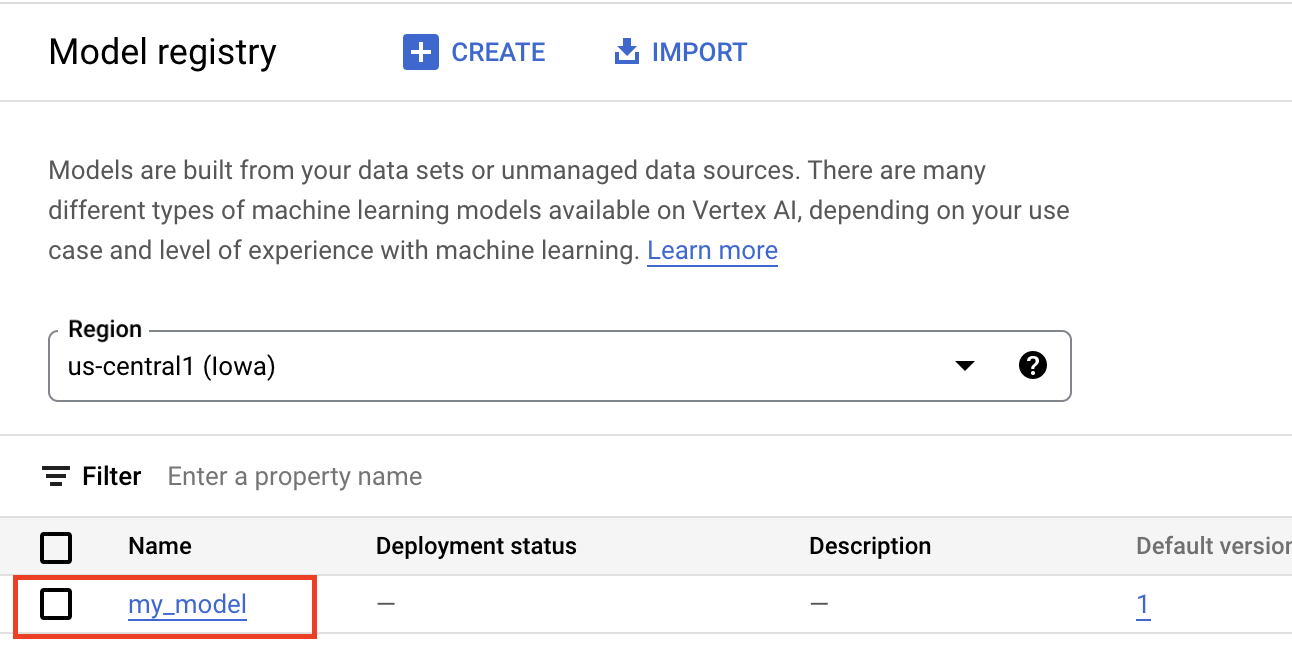
選取容器
將模型匯入 Gemini Enterprise Agent Platform Model Registry 時,您必須將模型與容器建立關聯,Gemini Enterprise Agent Platform 才能處理推論要求。
預先建構的容器
Gemini Enterprise Agent Platform 提供預先建構的容器,可用於推論。預先建構的容器會依機器學習框架和框架版本分類,並提供 HTTP 推論伺服器,方便您以最少的設定提供推論服務。這些模型只會執行機器學習架構的推論作業,因此如要預先處理資料,必須在提出推論要求前完成。同樣地,任何後續處理作業都必須在您執行推論要求後進行。如需使用預先建構容器的範例,請參閱「在 Agent Platform 上使用預先建構容器提供 PyTorch 圖片模型」筆記本。
自訂容器
如果您的用途需要預先建構容器未提供的程式庫,或是您想在推論要求中執行自訂資料轉換,可以使用您建構並推送至 Artifact Registry 的自訂容器。自訂容器可提供更完善的自訂功能,但容器必須執行 HTTP 伺服器。具體來說,容器必須監聽並回應即時檢查、健康狀態檢查和推論要求。在大多數情況下,建議盡可能使用預先建構的容器,因為這是較簡單的選項。如需使用自訂容器的範例,請參閱筆記本「使用 Vertex Training 和自訂容器,以單一 GPU 執行 PyTorch 圖片分類」。
自訂推論處理常式
如果您的用途需要自訂前置和後置處理轉換,但您不想負擔建構及維護自訂容器的成本,可以使用自訂推論處理常式。透過自訂推論處理常式,您可以將資料轉換作業以 Python 程式碼的形式提供,而 Python 適用的 Agent Platform SDK 會在幕後建構自訂容器,供您在本機測試及部署至 Gemini Enterprise Agent Platform。如需使用自訂推論處理常式的範例,請參閱「使用 Sklearn 的自訂推論處理常式」筆記本。
取得批次推論結果
模型進入 Gemini Enterprise Agent Platform Model Registry 後,您就可以透過 Google Cloud 控制台或 Agent Platform SDK for Python 提交批次推論工作。您將指定來源資料的位置,以及要將結果儲存到 Cloud Storage 或 BigQuery 的位置。您也可以指定要執行這項工作的機型,以及任何選用的加速器。由於推論服務是全代管服務,Gemini Enterprise Agent Platform 會自動佈建運算資源、執行推論工作,並在推論工作完成後刪除運算資源。您可以在 Google Cloud 控制台中追蹤批次推論工作的狀態。
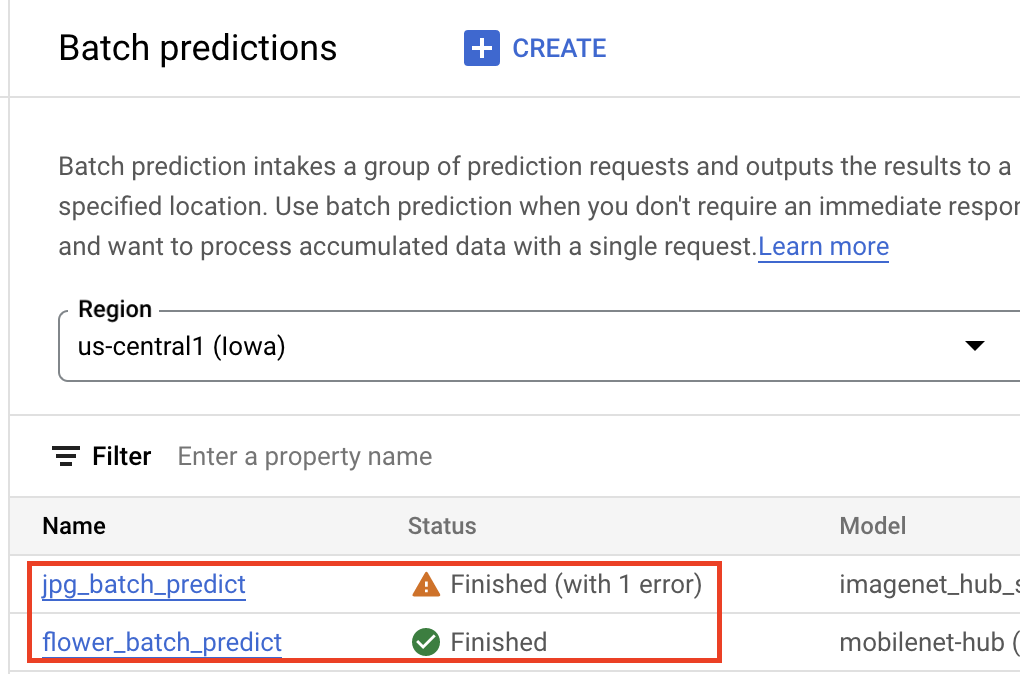
取得線上推論結果
如要取得線上推論結果,您需要採取額外步驟,將模型部署至 Gemini Enterprise Agent Platform 端點。這項操作會將模型構件與實體資源建立關聯,以提供低延遲的服務,並建立 DeployedModel 資源。
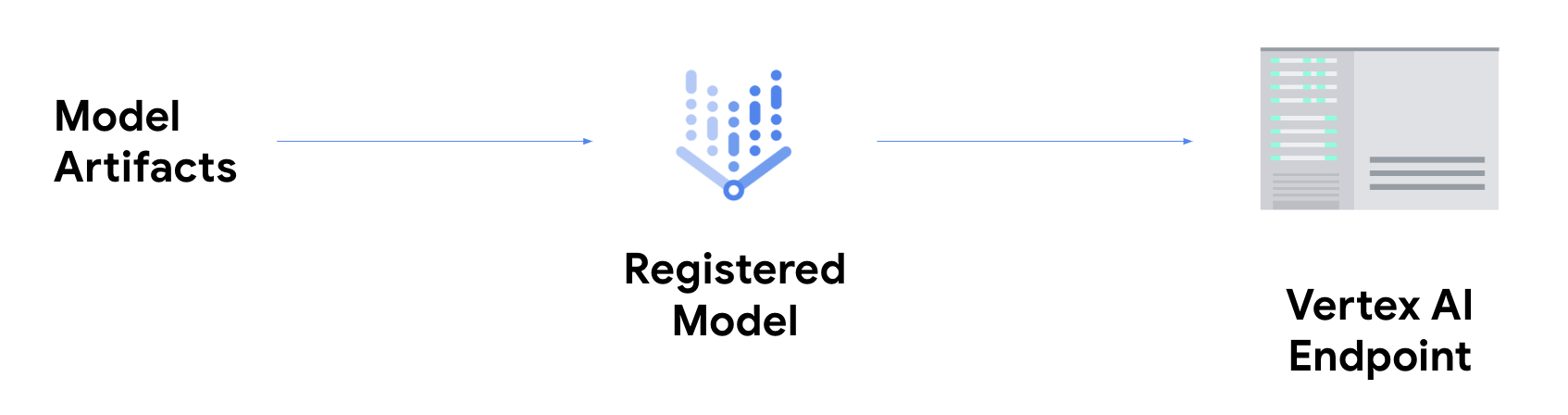
模型部署至端點後,就會像其他 REST 端點一樣接受要求,因此您可以從 Cloud Run 函式、聊天機器人、網頁應用程式等呼叫模型。請注意,您可以將多個模型部署至單一端點,並在這些模型之間拆分流量。舉例來說,如果您想推出新版模型,但不想立即將所有流量導向新模型,這項功能就非常實用。您也可以將相同模型部署至多個端點。
透過 Agent Platform 取得自訂模型推論結果的資源
如要進一步瞭解如何在 Agent Platform 上代管及提供模型,請參閱下列資源或 Agent Platform 範例 GitHub 存放區。
- 「預測」影片
- 使用預先建構的容器訓練及提供 TensorFlow 模型
- 在 Agent Platform 上使用預建容器提供 PyTorch 圖像模型
- 使用預先建構的容器提供 Stable Diffusion 擴散模型
- 使用 Sklearn 的自訂推論常式