
הכלי למעקב אחרי שאילתות בניתוח והחלונית ביצועים בניתוח מספקים נתוני ביצועים מפורטים של שאילתות בניתוח. הנתונים האלה יכולים לעזור לכם לזהות נקודות כניסה מרכזיות לפתרון בעיות ולשפר את הביצועים של שאילתות, וגם לספק המלצות לשיפורים.
בדיקת שאילתות באמצעות כלי המעקב
בכלי למעקב אחרי שאילתות ב-Explore מוצגת ההתקדמות של שאילתת Explore לאורך שלושת השלבים של השאילתה בזמן שהשאילתה פועלת.
![]()
אם לוקח הרבה זמן להריץ שאילתה, הכלי למעקב אחרי שאילתות יכול להצביע על השלב בשאילתה שגורם לבעיית הביצועים. המידע הזה שימושי לזיהוי המקומות שבהם עלולות להתרחש בעיות בביצועים, ולזיהוי המקומות שבהם מאמצי האופטימיזציה יכולים להיות הכי יעילים.
הכלי למעקב אחרי שאילתות מוצג כשניתוח פועל, כל עוד פתוחה החלונית Visualization של ניתוח או החלונית Data של ניתוח.
עיון בחלונית ביצועים
כדי לראות את החלונית ביצועים ב'ניתוח נתונים', לוחצים על הקישור הצגת פרטי ביצועים, שזמין בכל שאילתת ניתוח נתונים שהופעלה.

בחלונית ביצועים מוצג הזמן שחלף במהלך כל אחד משלושת השלבים של השאילתה, ומופיעים בה קישורים למסמכי מידע על ביצועים וללוח הבקרה של פעילות המערכת בנושא היסטוריית השאילתות, שבו מוצגים נתוני הביצועים הנוכחיים וההיסטוריים של השאילתה ושל התכונה 'חיפוש וניתוח נתונים' ששימשה ליצירת השאילתה.
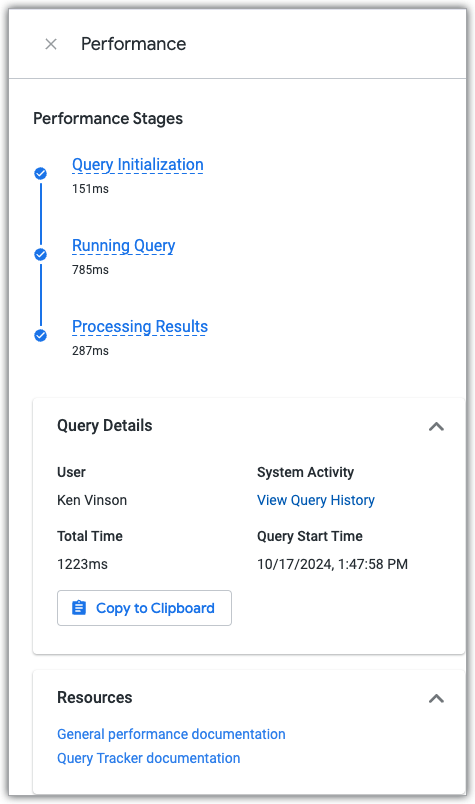
שלבי השאילתה
כשמריצים שאילתת מסד נתונים ב-Explore ב-Looker, השאילתה מופעלת בשלושה שלבים:
שלב ההפעלה של השאילתה
במהלך השלב Query Initialization, Looker מבצע את כל המשימות שנדרשות לפני שהשאילתה נשלחת למסד הנתונים. השלב Query Initialization כולל את המשימות הבאות:
- קומפילציה של מודל LookML
- מתבצעת בדיקה אם צריך ליצור טבלאות נגזרות מתמידות (PDT)
- יצירת ה-SQL של השאילתה
- קבלת חיבור למסד הנתונים
בדף התיעוד הסבר על מדדי ביצועים של שאילתות מוסבר איך להשתמש במדדי ביצועים של שאילתות בפעילות המערכת כדי לראות פירוטים של שאילתה. השלב Query initialization בכלי למעקב אחרי שאילתות כולל את האירועים שמתוארים בשלבים Asynchronous worker phase, Initialization phase ו-Connection handling phase בדוח Query Performance Metrics ב-Explore.
שלב הרצת השאילתה
בשלב הפעלת שאילתה, Looker יוצר קשר עם מסד הנתונים ושולח אליו שאילתה, ומחזיר את תוצאות השאילתה. בעיות בביצועים בשלב הזה יכולות להעיד על בעיה במסד הנתונים החיצוני, כמו PDTs שלוקח להם הרבה זמן להיבנות מחדש וצריך לבצע בהם אופטימיזציה, או טבלאות במסד הנתונים החיצוני שצריך לבצע בהן אופטימיזציה. השלב הפעלת שאילתה כולל את המשימות הבאות:
- יצירת PDTs במסד הנתונים שנדרשים לשאילתת Explore
- השאילתה המבוקשת מורצת במסד הנתונים
בדף התיעוד הסבר על מדדי ביצועים של שאילתות מוסבר איך להשתמש במדדי ביצועים של שאילתות בפעילות המערכת כדי לראות פירוטים של שאילתה. השלב Running query בכלי למעקב אחר שאילתות כולל את האירועים שמתוארים בשלב Main queries בכלי Query Performance Metrics.
אם נתקלים בבעיות בביצועים במהלך השלב הזה, אפשר לנסות את הפעולות הבאות:
- בונים את הניתוחים באמצעות צירופים (joins) של
many_to_oneכשזה אפשרי. בדרך כלל, כדי לקבל את הביצועים הטובים ביותר של השאילתה, כדאי לצרף תצוגות מהרמה המפורטת ביותר לרמה הכי גבוהה של הפרטים (many_to_one). - כדאי להשתמש במקסימום מטמון כדי לסנכרן עם מדיניות ה-ETL שלכם בכל מקום שאפשר, וכך להפחית את תנועת השאילתות במסד הנתונים. כברירת מחדל, Looker שומר במטמון שאילתות למשך שעה אחת. אתם יכולים לשלוט במדיניות השמירה במטמון ולסנכרן את רענון הנתונים ב-Looker עם תהליך ה-ETL באמצעות קבוצות נתונים בתוך כלי הניתוחים, באמצעות הפרמטר
persist_with. אופטימיזציה של השימוש במטמון מאפשרת ל-Looker להשתלב בצורה הדוקה יותר עם צינור הנתונים של ה-Backend, כך שאפשר להשתמש במטמון בצורה אופטימלית בלי לסכן את הניתוח של נתונים לא עדכניים. אפשר להחיל מדיניות שמירה במטמון עם שם על מודל שלם או על רכיבי Explore וטבלאות נגזרות קבועות (PDT) ספציפיים. - כדאי להשתמש בתכונה מודעות מצטברת של Looker כדי ליצור סיכומי נתונים או טבלאות סיכום ש-Looker יכול להשתמש בהן לשאילתות כשאפשר, במיוחד לשאילתות נפוצות של מסדי נתונים גדולים. אפשר גם להשתמש במודעות מצטברת כדי לשפר באופן משמעותי את הביצועים של לוחות בקרה שלמים. מידע נוסף זמין במדריך בנושא מודעות מצטברת.
- כדי להריץ שאילתות מהר יותר, כדאי להשתמש בPDT. כדאי להמיר ניתוחים מתקדמים עם הרבה הצטרפויות מורכבות או לא יעילות, או מאפיינים עם שאילתות משנה או בחירות משנה, לטבלאות PDT כדי שהתצוגות המפורטות יהיו מוכנות לפני זמן הריצה.
- אם ניב מסד הנתונים תומך ב-PDT מצטבר, כדאי להגדיר PDT מצטבר כדי לקצר את הזמן ש-Looker משקיע בבנייה מחדש של טבלאות PDT.
- אל תצטרפו לתצוגות ב-Explores על מפתחות ראשיים משורשרים שמוגדרים ב-Looker. במקום זאת, מצטרפים לשדות הבסיס שמרכיבים את המפתח הראשי המשורשר מהתצוגה. אפשרות אחרת היא ליצור מחדש את התצוגה כ-PDT עם המפתח הראשי המשורשר שהוגדר מראש בהגדרת ה-SQL של הטבלה, ולא ב-LookML של התצוגה.
- כדי לבצע השוואה בין ביצועים, אפשר להשתמש בכלי Explain in SQL Runner.
EXPLAINיוצר סקירה כללית של תוכנית ההרצה של שאילתת מסד הנתונים עבור שאילתת SQL נתונה, ומאפשר לכם לזהות רכיבי שאילתה שאפשר לבצע בהם אופטימיזציה. מידע נוסף זמין בפוסט לקהילה איך לבצע אופטימיזציה של SQL באמצעותEXPLAIN. - הצהרה על אינדקסים. אפשר לראות את האינדקסים של כל טבלה ישירות ב-Looker מתוך SQL Runner. לשם כך, לוחצים על סמל גלגל השיניים בטבלה ואז בוחרים באפשרות הצגת אינדקסים.
העמודות הנפוצות ביותר שיכולות להפיק תועלת מאינדקסים הן תאריכים חשובים ומפתחות זרים. הוספת אינדקסים לעמודות האלה תשפר את הביצועים של כמעט כל השאילתות. הדבר נכון גם לגבי PDT. אפשר להחיל פרמטרים של LookML, כמו
indexes,sort keysו-distribution, בצורה מתאימה.
השלב של תוצאות העיבוד
במהלך השלב Processing Results (עיבוד התוצאות), Looker מעבד ומציג את תוצאות השאילתה. השלב עיבוד התוצאות כולל את המשימות הבאות:
- הזרמת תוצאות של שאילתות אל המטמון
- פתרון בעיות שקשורות לחישובים בטבלה
- עיצוב התוצאות של שפת התבניות Liquid
- מיזוג שאילתות
- חישוב סכומים כוללים וסכומי ביניים
בדף התיעוד הסבר על מדדי ביצועים של שאילתות מוסבר איך להשתמש במדדי ביצועים של שאילתות בפעילות המערכת כדי לראות פירוטים של שאילתה. השלב Processing Results בכלי למעקב אחרי שאילתות כולל את האירועים שמתוארים בשלב אחרי השאילתה ב-Explore Query Performance Metrics.
אם נתקלים בבעיות בביצועים בשלב הזה, אפשר לנסות את הפתרונות הבאים:
- מומלץ להשתמש בתכונות כמו מיזוג תוצאות, שדות בהתאמה אישית וחישובים בטבלה במשורה. התכונות האלה נועדו לשמש כהוכחות לקונספט, כדי לעזור לכם לתכנן את המודל. מומלץ להשתמש בקידוד קשיח לחישובים ולפונקציות שבהם משתמשים לעיתים קרובות ב-LookML. כך ייווצר קוד SQL שיעבור עיבוד במסד הנתונים. חישובים מוגזמים יכולים להתחרות על זיכרון Java במופע Looker, ולגרום למופע Looker להגיב לאט יותר.
- אם יש מספר גדול של קבצים של תצוגות, כדאי להגביל את מספר התצוגות שכוללים במודל. הכללת כל התצוגות במודל יחיד עלולה להאט את הביצועים. אם יש מספר גדול של תצוגות בפרויקט, כדאי לכלול בכל מודל רק את קובצי התצוגה שנדרשים. כדאי להשתמש במוסכמות מתן שמות אסטרטגיות לשמות של קובצי תצוגות כדי לאפשר הכללה של קבוצות של תצוגות במודל. דוגמה מפורטת מופיעה בתיעוד של הפרמטר
includes. - כדי להימנע מהחזרת מספר גדול של נקודות נתונים כברירת מחדל בלוחות בקרה ובמבטים. שאילתות שמחזירות אלפי נקודות נתונים יצרכו יותר זיכרון. כדי להגביל את הנתונים ככל האפשר, כדאי להחיל
מסננים בחלק הקדמי של מרכזי הבקרה, ה-Looks והניתוחים, וברמת LookML באמצעות הפרמטרים
required filters, conditionally_filterו-sql_always_where. - מומלץ להשתמש באפשרות כל התוצאות להורדה או להעברה של שאילתות רק לעיתים רחוקות, כי חלק מהשאילתות יכולות להיות גדולות מאוד ולגרום לעומס יתר על שרת Looker בזמן העיבוד.