
סקירה כללית
Looker משתמש בלוגיקה של מודעות למצטברים כדי למצוא את הטבלה הכי קטנה ויעילה שזמינה במסד הנתונים שלכם להרצת שאילתה, תוך שמירה על דיוק.
בטבלאות גדולות מאוד במסד הנתונים, מפתחי Looker יכולים ליצור טבלאות מסכמות קטנות יותר של נתונים, שמקובצים לפי שילובים שונים של מאפיינים. הטבלאות המסכמות משמשות כטבלאות סיכום ש-Looker יכול להשתמש בהן לשאילתות כשאפשר, במקום בטבלה המקורית הגדולה. כשמיישמים את התכונה הזו באופן אסטרטגי, היא יכולה להאיץ את השאילתה הממוצעת בסדרי גודל.
לדוגמה, יכול להיות שיש לכם טבלת נתונים בגודל פטה-בייט עם שורה אחת לכל הזמנה שבוצעה באתר שלכם. מתוך מסד הנתונים הזה, אפשר ליצור טבלה מסכמת עם סכומי המכירות היומיים. אם באתר שלכם מתקבלות 1,000 הזמנות מדי יום, בטבלה היומית המצטברת יוצג כל יום עם 999 שורות פחות מאשר בטבלה המקורית. אפשר ליצור טבלת צבירה נוספת עם סכומי מכירות חודשיים שתהיה יעילה עוד יותר. לכן, אם משתמש יריץ שאילתה לגבי מכירות יומיות או שבועיות, Looker ישתמש בטבלה של סך המכירות היומיות. אם משתמש מריץ שאילתה לגבי מכירות שנתיות ואין לכם טבלת צבירה שנתית, Looker ישתמש בטבלה הכי מתאימה, שהיא במקרה הזה טבלת צבירה של מכירות חודשיות.
מערכת Looker עונה על שאלות של משתמשים באמצעות הטבלאות המצטברות הקטנות ביותר, בכל הזדמנות. לדוגמה:
- לשאילתה לגבי סה"כ המכירות החודשיות, Looker משתמש בטבלה מסכמת על סמך נתוני המכירות החודשיות (
sales_monthly_aggregate_table). - אם מריצים שאילתה לגבי סכום כל מכירה ביום מסוים, אין טבלת צבירה עם רמת הפירוט הזו, ולכן Looker מקבל את תוצאות השאילתה מטבלת מסד הנתונים המקורית (
orders_database). (עם זאת, אם המשתמשים מריצים שאילתות מהסוג הזה לעיתים קרובות, אפשר ליצור בשבילן טבלת צבירה). - אם השאילתה היא לגבי מכירות שבועיות, אין טבלת צבירה שבועית, ולכן Looker משתמש בטבלה הכי מתאימה, שהיא טבלת הצבירה שמבוססת על מכירות יומיות (
sales_daily_aggregate_table).
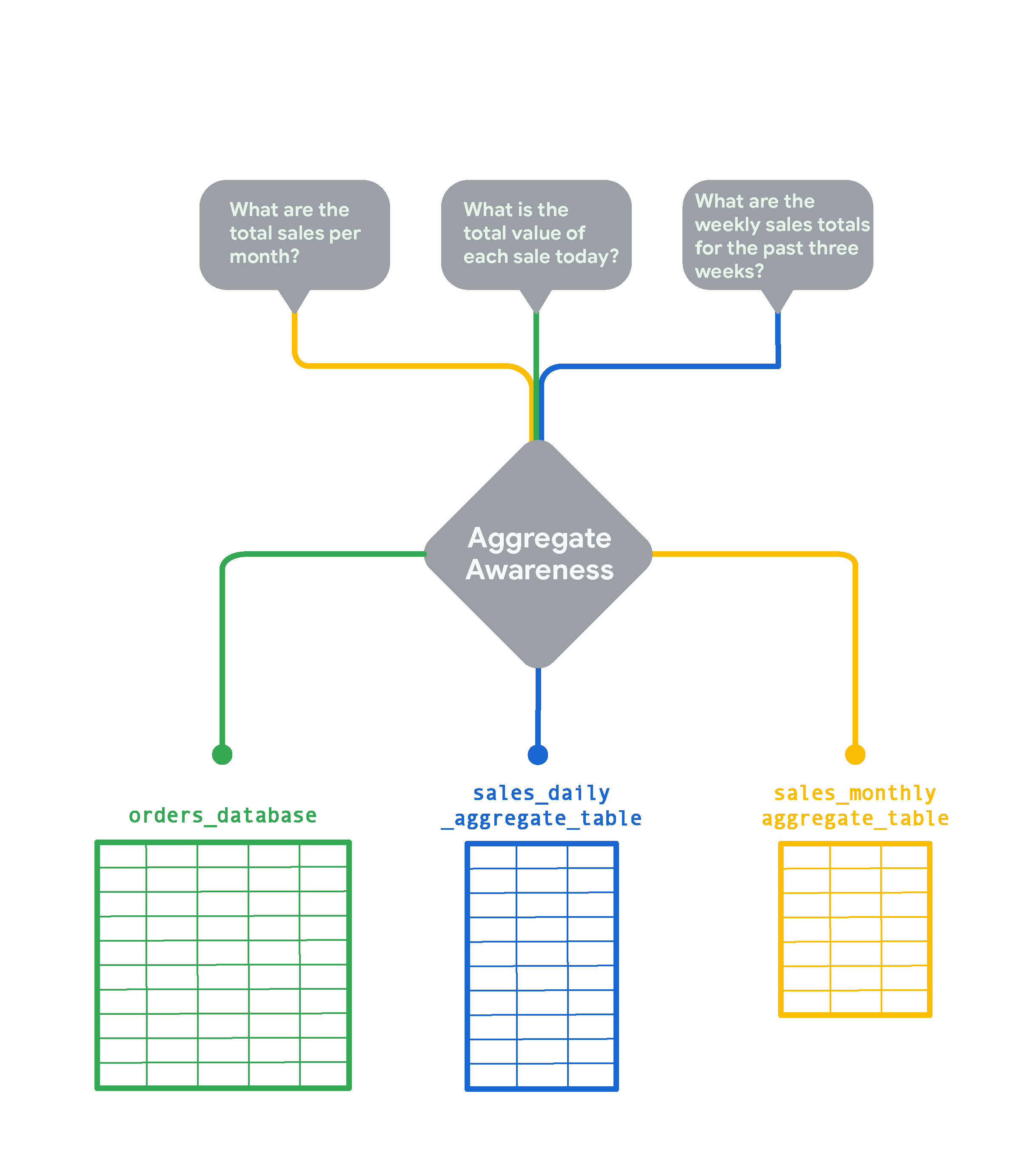
באמצעות לוגיקה של מודעות מצטברת, Looker ישלח שאילתה לטבלה המסכמת הקטנה ביותר האפשרית כדי לענות על השאלות של המשתמשים. הטבלה המקורית תשמש רק לשאילתות שדורשות רמת פירוט גבוהה יותר מזו שאפשר לקבל מטבלאות הצבירה.
אין צורך להצטרף לטבלאות מצטברות או להוסיף אותן לניתוח נפרד ב-Explore. במקום זאת, Looker מתאים באופן דינמי את סעיף ה-FROM של שאילתת הניתוח כדי לגשת לטבלת הצבירה הכי טובה עבור השאילתה. המשמעות היא שהניתוחים המפורטים שלכם נשמרים ואפשר לאחד את הניתוחים ב-Explore. בעזרת מודעות לצבירה, דוח אחד ב-Explore יכול להשתמש אוטומטית בטבלאות צבירה, אבל עדיין להתעמק בנתונים ברמת הגרנולריות אם צריך.
אפשר גם להשתמש בטבלאות מצטברות כדי לשפר באופן משמעותי את הביצועים של לוחות הבקרה, במיוחד כשמדובר במשבצות שמבצעות שאילתות על קבוצות נתונים גדולות. פרטים נוספים מופיעים בקטע קבלת טבלת LookML מצטברת מלוח בקרה בדף התיעוד של הפרמטר aggregate_table.
הוספת טבלאות מצטברות לפרויקט
מפתחי Looker יכולים ליצור טבלאות מצטברות אסטרטגיות שיצמצמו את מספר השאילתות שנדרשות בטבלאות הגדולות במסד נתונים. צריך לשמור את הטבלאות המצטברות במסד הנתונים כדי שאפשר יהיה לגשת אליהן לצורך מודעות מצטברת. לכן, טבלאות מסכמות הן סוג של טבלה נגזרת מתמידה (PDT).
טבלת צבירה מוגדרת באמצעות הפרמטר aggregate_table מתחת לפרמטר explore בפרויקט של LookML.
דוגמה ל-explore עם טבלה מסכמת ב-LookML:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
כדי ליצור טבלה מסכמת, אפשר לכתוב את קוד ה-LookML מאפס, או לקבל קוד LookML של טבלה מסכמת מ-Explore או מלוח בקרה. פרטים ספציפיים על הפרמטר aggregate_table והפרמטרים המשניים שלו זמינים בדף התיעוד של הפרמטר aggregate_table.
עיצוב טבלאות מסכמות
כדי ששאילתת Explore תוכל להשתמש בטבלה מסכמת, הטבלה המסכמת צריכה לספק נתונים מדויקים לשאילתת Explore. Looker יכול להשתמש בטבלה מסכמת לשאילתת Explore אם כל התנאים הבאים מתקיימים:
- השדות של שאילתת הניתוח הם קבוצת משנה של השדות בטבלת הצבירה (אפשר לעיין בקטע גורמים שקשורים לשדות בדף הזה). לחלופין, כשמדובר במסגרות זמן, אפשר לגזור את מסגרות הזמן של שאילתת הניתוח ממסגרות הזמן בטבלת הצבירה (ראו את הקטע גורמים שקשורים למסגרת זמן בדף הזה).
- שאילתת הניתוח מכילה סוגי מדדים שנתמכים על ידי מודעות מצטברות (ראו את הקטע גורמים שמשפיעים על סוג המדד בדף הזה), או שלשאילתת הניתוח יש טבלת צבירה שהיא התאמה מדויקת (ראו את הקטע יצירת טבלאות צבירה שתואמות בדיוק לשאילתות ניתוח בדף הזה).
- אזור הזמן של שאילתת הניתוח זהה לאזור הזמן שמוגדר בטבלה המצטברת (ראו את הקטע גורמים שקשורים לאזור הזמן בדף הזה).
- המסננים של השאילתה ב-Explore מפנים לשדות שזמינים כמאפיינים בטבלה מסכמת, או שכל אחד מהמסננים של השאילתה ב-Explore תואם למסנן בטבלה מסכמת (ראו את הקטע גורמים שמשפיעים על סינון בדף הזה).
דרך אחת לוודא שטבלת צבירה יכולה לספק נתונים מדויקים לשאילתת ניתוח היא ליצור טבלת צבירה שתואמת בדיוק לשאילתת ניתוח. פרטים נוספים זמינים בקטע יצירת טבלאות מצטברות שתואמות בדיוק לשאילתות ב-Explore בדף הזה.
גורמים בשדה
כדי להשתמש בטבלה מסכמת בשאילתת Explore, הטבלה צריכה לכלול את כל המאפיינים והמדדים שנדרשים לשאילתת ה-Explore, כולל השדות שמשמשים למסננים בשאילתת ה-Explore. אם שאילתת ניתוח ב-Explore מכילה מאפיין או מדד שלא נמצאים בטבלה מסכמת, מערכת Looker לא יכולה להשתמש בטבלה המסכמת ותשתמש במקום זאת בטבלת הבסיס.
לדוגמה, אם שאילתה מקבצת לפי המאפיינים A ו-B, מבצעת צבירה לפי המדד C ומסננת לפי המאפיין D, אז בטבלת הצבירה צריכים להיות לפחות המאפיינים A, B ו-D והמדד C.
הטבלה המצטברת יכולה לכלול גם שדות אחרים, אבל היא חייבת לכלול לפחות את השדות של שאילתת הניתוח כדי שאפשר יהיה לבצע אופטימיזציה. החריג היחיד הוא מאפייני מסגרת זמן, כי אפשר לגזור מסגרות זמן עם רמת פירוט גסה יותר ממסגרות זמן עם רמת פירוט מדויקת יותר.
בגלל השיקולים האלה לגבי השדות, טבלה מסכמת היא ספציפית ל-Explore שבו היא מוגדרת. טבלה מסכמת שהוגדרה ב-Explore אחד לא תשמש לשאילתות ב-Explore אחר.
גורמים שקשורים למסגרת הזמן
הלוגיקה של Looker לגבי מוּדעוּת מצטברת מאפשרת להסיק מסגרת זמן אחת מתוך מסגרת זמן אחרת. אפשר להשתמש בטבלה מצטברת לשאילתה כל עוד מסגרת הזמן של הטבלה המצטברת כוללת רמת פירוט גבוהה יותר (או שווה) מזו של שאילתת הניתוח. לדוגמה, אפשר להשתמש בטבלת צבירה שמבוססת על נתונים יומיים לשאילתת ניתוח שמבקשת מסגרות זמן אחרות, כמו שאילתות של נתונים יומיים, חודשיים ושנתיים, או אפילו נתונים של היום בחודש, היום בשנה והשבוע בשנה. אבל אי אפשר להשתמש בטבלה מסכמת שנתית בשאילתת ניתוח שמבקשת נתונים ברזולוציה שעתית, כי הנתונים בטבלה המסכמת לא מספיק מפורטים בשביל שאילתת הניתוח.
אותו עיקרון חל על קבוצות משנה של טווחי זמן. לדוגמה, אם יש לכם טבלת צבירה שמסוננת לפי שלושת החודשים האחרונים, ומשתמש שולח שאילתה לנתונים עם מסנן לשני החודשים האחרונים, Looker יוכל להשתמש בטבלת הצבירה בשביל השאילתה הזו.
בנוסף, אותה לוגיקה חלה על שאילתות עם מסנני טווח זמן: אפשר להשתמש בטבלה מסכמת בשאילתה עם מסנן טווח זמן, כל עוד טווח הזמן של הטבלה המסכמת הוא ברמת פירוט גבוהה יותר (או שווה) מזו של מסנן טווח הזמן שבו נעשה שימוש בשאילתת הניתוח. לדוגמה, אפשר להשתמש בטבלת צבירה עם מאפיין של מסגרת זמן יומית לשאילתת חיפוש ב-Explore שמסננת לפי יום, שבוע או חודש.
גורמים של סוג המדידה
כדי ששאילתת Explore תשתמש בטבלה מסכמת, המדדים בטבלה המסכמת צריכים לספק נתונים מדויקים לשאילתת Explore.
לכן, המערכת תומכת רק בסוגים מסוימים של מדדים, כפי שמתואר בקטעים הבאים:
- מדדים עם סוגי מדדים נתמכים
- מדדים שמוגדרים על ידי ביטויי SQL
- מדדים שלא מוגדרים באמצעות
${TABLE} - מדדים שמספקים קירוב לספירות נפרדות
אם שאילתת ניתוח כוללת סוג אחר של מדד, Looker ישתמש בטבלה המקורית ולא בטבלת הצבירה כדי להחזיר תוצאות. החריג היחיד הוא אם שאילתת החיפוש ב-Explore היא התאמה מדויקת לשאילתת טבלת צבירה, כפי שמתואר בקטע יצירת טבלאות צבירה שתואמות בדיוק לשאילתות ב-Explore.
אחרת, Looker ישתמש בטבלה המקורית ולא בטבלת הצבירה כדי להחזיר תוצאות.
מדדים עם סוגי מדדים נתמכים
אפשר להשתמש במודעות מצטברת בשאילתות ב-Explore שמשתמשות במדדים עם סוגי המדדים הבאים:
כדי להשתמש בטבלת צבירה בשאילתת ניתוח, מערכת Looker צריכה להיות מסוגלת לבצע פעולות על המדדים של טבלת הצבירה כדי לספק נתונים מדויקים בשאילתת הניתוח. לדוגמה, אפשר להשתמש במדד עם type: sum כדי לנתח את המודעות המצטברות, כי אפשר לסכם כמה סכומים: אפשר לחבר בין סכומים שבועיים בטבלה מצטברת כדי לקבל סכום חודשי מדויק. באופן דומה, אפשר להשתמש במדד עם type: max כי אפשר להשתמש בטבלה מסכמת של ערכים מקסימליים יומיים כדי למצוא את הערך המקסימלי השבועי המדויק.
במקרה של מדדים עם type: average, נתמכת צבירה של נתוני מודעות כי Looker משתמש בנתוני סכום וספירה כדי לגזור במדויק ערכים ממוצעים מטבלאות צבירה.
מדדים שמוגדרים באמצעות ביטויי SQL
אפשר להשתמש בסיכום המודעות גם עם מדדים שמוגדרים באמצעות ביטויים בפרמטר sql. כשמגדירים אותם באמצעות ביטויי SQL, נתמכים גם סוגי המדדים הבאים:
התכונה 'מודעות מצטברת' נתמכת במדדים שמוגדרים כשילובים של מדדים אחרים, כמו בדוגמה הבאה:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
יש גם תמיכה במודעות מצטברת למדדים שבהם החישובים מוגדרים בפרמטר sql, כמו המדד הזה:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
בנוסף, יש תמיכה במדדים שמוגדרים בהם פעולות MIN, MAX ו-COUNT בפרמטר sql, כמו המדד הזה:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
מדדים שמפנים לשדות LookML
כשמשתמשים בביטויים של sql במדדים, התכונה 'מודעות מצטברת' תומכת בסוגים הבאים של הפניות לשדות:
- הפניות בפורמט
${view_name.field_name}, שמציין שדות בתצוגות אחרות - הפניות בפורמט
${field_name}, שמציין שדות באותה תצוגה
אין תמיכה במודעות לנתונים מצטברים במדדים שמוגדרים באמצעות הפורמט ${TABLE}.column_name, שמציין עמודה בטבלה. (סקירה כללית על שימוש בהפניות ב-LookML מופיעה במאמר שילוב של SQL והפניה לאובייקטים של LookML).
לדוגמה, מדד שמוגדר עם הפרמטר sql הזה לא ייתמך בטבלה מסכמת, כי הוא משתמש בפורמט ${TABLE}.column_name:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
אם רוצים לכלול את המדד הזה בטבלה מסכמת, אפשר ליצור במקום זאת מאפיין שמוגדר בפורמט ${TABLE}.column_name, ואז ליצור מדד שמפנה למאפיין, כך:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
עכשיו אפשר להשתמש במדד wholesale_value בטבלה המסכמת.
מדדים שמספקים קירוב לספירות נפרדות
באופן כללי, ספירות נפרדות לא נתמכות עם מודעות לאגרגציה, כי אי אפשר לקבל נתונים מדויקים אם מנסים לצבור ספירות נפרדות. לדוגמה, אם אתם סופרים את המשתמשים הייחודיים באתר, יכול להיות שמשתמש מסוים הגיע לאתר פעמיים, בהפרש של שלושה שבועות. אם ניסיתם להחיל טבלת צבירה שבועית כדי לקבל ספירה חודשית של משתמשים ייחודיים באתר שלכם, המשתמש הזה ייספר פעמיים בשאילתת הספירה החודשית של משתמשים ייחודיים, והנתונים יהיו שגויים.
פתרון עקיף אפשרי הוא ליצור טבלת צבירה שתואמת בדיוק לשאילתת חיפוש ב-Explore, כמו שמתואר בקטע יצירת טבלאות צבירה שתואמות בדיוק לשאילתות חיפוש ב-Explore בדף הזה. כששאילתת הניתוח ושאילתת הטבלה המצטברת זהות, מדדי הספירה הייחודית מספקים נתונים מדויקים, ולכן אפשר להשתמש בהם כדי להבין את הנתונים המצטברים.
אפשרות נוספת היא להשתמש בקירובים לספירות נפרדות. בניבים שבהם יש תמיכה בסקיצות של HyperLogLog, Looker יכול להשתמש באלגוריתם HyperLogLog כדי להעריך את מספר הערכים הייחודיים בטבלאות מצטברות.
ידוע שאלגוריתם HyperLogLog כולל שגיאה של כ-2%. הפרמטר allow_approximate_optimization: yes מחייב את מפתחי Looker שלכם לאשר שאין בעיה להשתמש בנתונים משוערים למדד, כדי שהמדד יוכל להיות מחושב בקירוב מטבלאות מצטברות.
מידע נוסף ורשימת הניבים שתומכים בספירת ערכים ייחודיים באמצעות HyperLogLog זמינים בדף התיעוד של הפרמטר allow_approximate_optimization.
גורמים שקשורים לאזור הזמן
במקרים רבים, אדמינים של מסדי נתונים משתמשים ב-UTC כאזור הזמן של מסדי הנתונים. עם זאת, יכול להיות שהרבה משתמשים לא נמצאים באזור הזמן UTC. ל-Looker יש כמה אפשרויות להמרת אזורי זמן, כדי שהמשתמשים יקבלו את תוצאות השאילתות באזור הזמן שלהם:
- אזור זמן של השאילתה, הגדרה שחלה על כל השאילתות בחיבור למסד הנתונים. אם כל המשתמשים נמצאים באותו אזור זמן, אפשר להגדיר אזור זמן יחיד לשאילתות, כך שכל השאילתות יומרו מאזור הזמן של מסד הנתונים לאזור הזמן של השאילתות.
- אזורי זמן ספציפיים למשתמש, שבהם אפשר להקצות אזורי זמן למשתמשים ולבחור אותם בנפרד. במקרה כזה, השאילתות מומרות מאזור הזמן של מסד הנתונים לאזור הזמן של המשתמש הספציפי.
מידע נוסף על האפשרויות האלה זמין בדף התיעוד בנושא שימוש בהגדרות אזור הזמן.
המושגים האלה חשובים להבנת המודעות המצטברת, כי כדי שאפשר יהיה להשתמש בטבלת צבירה לשאילתה עם מימדי תאריך או מסנני תאריך, אזור הזמן בטבלת הצבירה צריך להיות זהה להגדרת אזור הזמן שבה נעשה שימוש בשאילתה המקורית.
בטבלאות מצטברות נעשה שימוש באזור הזמן של מסד הנתונים אם לא מצוין ערך של timezone. חיבור מסד הנתונים יתבסס גם על אזור הזמן של מסד הנתונים אם מתקיים אחד מהתנאים הבאים:
- מסד הנתונים שלכם לא תומך באזורי זמן.
- אזור הזמן של השאילתה בחיבור למסד הנתונים מוגדר לאותו אזור זמן כמו אזור הזמן של מסד הנתונים.
- בחיבור למסד הנתונים לא צוין אזור זמן לשאילתה ולא צוינו אזורי זמן ספציפיים למשתמש. במקרה כזה, חיבור מסד הנתונים ישתמש באזור הזמן של מסד הנתונים.
אם אחד מהתנאים האלה מתקיים, אפשר להשמיט את הפרמטר timezone מטבלאות האגרגציה.
אחרת, צריך להגדיר את אזור הזמן של הטבלה המסכמת כך שיתאים לשאילתות אפשריות, כדי שהמערכת תשתמש בטבלה המסכמת:
- אם חיבור מסד הנתונים שלכם משתמש באזור זמן יחיד של שאילתות, אתם צריכים להתאים את הערך של
timezoneבטבלת הצבירה לערך של אזור הזמן של השאילתות. - אם החיבור למסד הנתונים משתמש באזורי זמן ספציפיים למשתמש, צריך ליצור טבלאות צבירה זהות, שלכל אחת מהן יש ערך
timezoneשונה בהתאם לאזורי הזמן האפשריים של המשתמשים.
גורמי סינון
חשוב להיזהר כשכוללים מסננים בטבלה המסכמת. מסננים בטבלה מסכמת יכולים לצמצם את התוצאות עד כדי כך שאי אפשר להשתמש בטבלה המסכמת. לדוגמה, נניח שאתם יוצרים טבלה מסכמת של ספירת הזמנות יומית, ובטבלה המסכמת מוגדר סינון רק של הזמנות משקפי שמש שמגיעות מאוסטרליה. אם משתמש מריץ שאילתה ב-Explore כדי לראות את מספר ההזמנות היומי של משקפי שמש ברחבי העולם, Looker לא יכול להשתמש בטבלה מסכמת בשביל השאילתה הזו, כי בטבלה מסכמת יש רק נתונים לגבי אוסטרליה. הטבלה המצטברת מסננת את הנתונים בצורה מצומצמת מדי, ולכן אי אפשר להשתמש בה בשאילתת הניתוח.
בנוסף, חשוב לשים לב למסננים שמפתחי Looker אולי הטמיעו בכלי הניתוחים, כמו:
-
access_filters: חלות הגבלות על נתונים ספציפיים למשתמש. -
always_filter: דרישה מהמשתמשים לכלול קבוצה מסוימת של מסננים בשאילתת Explore. המשתמשים יכולים לשנות את ערך ברירת המחדל של המסנן בשאילתה שלהם, אבל הם לא יכולים להסיר את המסנן לגמרי. -
conditionally_filter: מגדיר קבוצה של מסנני ברירת מחדל שהמשתמשים יכולים לבטל אם הם מפעילים לפחות מסנן אחד מרשימה שנייה שמוגדרת גם היא ב'ניתוח נתונים'.
סוגי המסננים האלה מבוססים על שדות ספציפיים. אם במסנן Explore יש את המסננים האלה, צריך לכלול את השדות שלהם בפרמטר dimensions של התג aggregate_table.
לדוגמה, הנה ניתוח ב'ניתוח נתונים' עם מסנן גישה שמבוסס על השדה orders.region:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
כדי ליצור טבלה מסכמת שתשמש ל-Explore הזה, הטבלה המסכמת צריכה לכלול את השדה שעליו מבוסס מסנן הגישה. בדוגמה הבאה, מסנן הגישה מבוסס על השדה orders.region, ואותו שדה נכלל כמאפיין בטבלת הצבירה:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
מכיוון ששאילתת הטבלה המצטברת כוללת את המאפיין orders.region, Looker יכול לסנן באופן דינמי את הנתונים בטבלה המצטברת כך שיתאימו למסנן משאילתת הניתוח. לכן, Looker עדיין יכול להשתמש בטבלה מסכמת לשאילתות של ה-Explore, גם אם ב-Explore יש מסנן גישה.
ההגדרה הזו חלה גם על שאילתות ב-Explore שמשתמשות בטבלה נגזרת מבוססת LookML (NDT) שהוגדרה עם bind_filters. הפרמטר bind_filters מעביר מסננים שצוינו משאילתת Explore אל שאילתת המשנה של הטבלה הנגזרת מבוססת LookML (NDT). במקרה של מודעות מצטברות, אם שאילתת הניתוח באמצעות Explore דורשת טבלה נגזרת מבוססת LookML (NDT) שמשתמשת ב-bind_filters, שאילתת הניתוח באמצעות Explore יכולה להשתמש בטבלה מסכמת רק אם לכל השדות שמשמשים בפרמטר bind_filters של טבלת הנתונים הנגזרת המקורית יש את אותם ערכי מסנן בדיוק בשאילתת הניתוח באמצעות Explore כמו בטבלה המסכמת.
יצירת טבלאות מצטברות שתואמות בדיוק לשאילתות בכלי הניתוחים
דרך אחת לוודא שאפשר להשתמש בטבלת צבירה בשאילתת Explore היא ליצור טבלת צבירה שתואמת בדיוק לשאילתת Explore. אם השאילתה ב'ניתוח מעמיק' והטבלה המצטברת משתמשות באותם מדדים, מאפיינים, מסננים, אזורי זמן ופרמטרים אחרים, אז בהגדרה התוצאות של הטבלה המצטברת יחולו על השאילתה ב'ניתוח מעמיק'. אם טבלת צבירה היא התאמה מדויקת לשאילתת ניתוח, Looker יכול להשתמש בטבלאות צבירה שכוללות כל סוג של מדד.
אפשר ליצור טבלת צבירה מניתוח באמצעות האפשרות Get LookML מתפריט גלגל השיניים של ניתוח. אפשר גם ליצור התאמות מדויקות לכל המשבצות בלוח הבקרה באמצעות האפשרות Get LookML (קבלת LookML) מתפריט גלגל השיניים של לוח הבקרה.
איך קובעים איזו טבלת צבירה משמשת לשאילתה
משתמשים עם הרשאות see_sql יכולים להשתמש בתגובות בכרטיסייה SQL של Explore כדי לראות באיזו טבלה מסכמת תתבצע שאילתה. התגובות בכרטיסייה SQL מוצגות גם במצב פיתוח, כך שמפתחים יכולים לבדוק טבלאות צבירה חדשות כדי לראות איך Looker משתמש בהן לפני שמעבירים טבלאות חדשות לייצור.
לדוגמה, על סמך טבלת הצבירה החודשית לדוגמה שמוצגת למעלה, אפשר לעבור אל 'ניתוח נתונים' ולהריץ שאילתה לגבי סכומי המכירות השנתיים. אחר כך לוחצים על הכרטיסייה SQL כדי לראות את פרטי השאילתה שנוצרה ב-Looker. אם אתם במצב פיתוח, Looker מציג הערות שמציינות את הטבלה המסכמת שבה נעשה שימוש בשאילתה.
מההערות הבאות בכרטיסייה SQL אפשר לראות ש-Looker משתמש בטבלה מסכמת sales_monthly בשאילתה הזו, ומידע על הסיבות לכך שטבלאות מסכמות אחרות לא שימשו בשאילתה:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
בקטע פתרון בעיות בדף הזה מפורטות תגובות אפשריות שיוצגו בכרטיסייה SQL, והצעות לפתרון שלהן.
אומדנים של חיסכון בחישובים לשימוש בתובנות מצטברות
אם חיבור מסד הנתונים תומך באומדני עלויות ואפשר להשתמש בטבלה מסכמת לשאילתה, בחלון 'ניתוח' יוצגו החיסכון בעלויות החישוב כתוצאה משימוש בטבלה המסכמת במקום בשליחת שאילתה ישירה של מסד הנתונים. החיסכון המצטבר במודעות להגברת המודעות למותג מוצג לצד הלחצן הפעלה בכלי 'ניתוח נתונים' לפני הפעלת השאילתה.
לפני שמריצים את השאילתה, אם רוצים לראות באיזו טבלה מסכמת תתבצע השאילתה, אפשר ללחוץ על הכרטיסייה SQL, כמו שמתואר בקטע קביעה של טבלה מסכמת שבה תתבצע השאילתה בדף התיעוד הזה.
אחרי שמריצים את השאילתה, בחלון 'ניתוח נתונים' מוצגת הטבלה המצטברת ששימשה למענה על השאילתה, לצד הלחצן הפעלה.
החיסכון המצטבר במידת ההיכרות עם המותג מוצג עבור חיבורי מסד נתונים שהופעלו בהם אומדני עלויות. מידע נוסף זמין בדף התיעוד בנושא בדיקת נתונים ב-Looker .
Looker מאחד נתונים חדשים עם טבלאות הצבירה
בטבלאות מצטברות עם מסנני זמן, Looker יכול לאחד נתונים עדכניים עם הטבלה המצטברת. יכול להיות שיש לכם טבלת צבירה שכוללת נתונים משלושת הימים האחרונים, אבל יכול להיות שהטבלה הזו נוצרה אתמול. בטבלה המצטברת לא יופיע מידע מהיום, ולכן לא כדאי להשתמש בה לשאילתת ניתוח של המידע היומי העדכני ביותר.
עם זאת, Looker עדיין יכול להשתמש בנתונים בטבלה המסכמת הזו בשביל השאילתה, כי Looker יריץ שאילתה על הנתונים העדכניים ביותר, ואז יאחד את התוצאות עם התוצאות בטבלה המסכמת.
Looker יכול לאחד נתונים חדשים עם הנתונים בטבלת הצבירה שלכם, בתנאים הבאים:
- בטבלה המסכמת יש מסנן זמן.
- הטבלה המצטברת כוללת מאפיין שמבוסס על אותו שדה זמן כמו מסנן הזמן.
לדוגמה, בטבלה מסכמת הבאה יש מאפיין שמבוסס על השדה orders.created_date ומסנן זמן ("3 days") שמבוסס על אותו שדה:
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
אם הטבלה המצטברת הזו נוצרה אתמול, Looker יאחזר את הנתונים העדכניים ביותר שעדיין לא נכללים בטבלה המצטברת, ואז יאחד את התוצאות העדכניות עם התוצאות מהטבלה המצטברת. המשמעות היא שהמשתמשים יקבלו את הנתונים העדכניים ביותר, ועדיין יוכלו לשפר את הביצועים באמצעות מודעות מצטברת.
אם אתם במצב פיתוח, אתם יכולים ללחוץ על הכרטיסייה SQL של ניתוח נתונים כדי לראות את טבלת הצבירה ש-Looker השתמש בה לשאילתה, ואת ההצהרה UNION ש-Looker השתמש בה כדי להציג נתונים חדשים שלא נכללו בטבלת הצבירה.
צריך לשמור את הטבלאות המסכמות
כדי שהטבלה המצטברת תהיה נגישה לצורך מודעות מצטברת, היא צריכה להיות קבועה במסד הנתונים. אסטרטגיית השמירה מצוינת בפרמטר materialization של הטבלה המצטברת. טבלאות מסכמות הן סוג של טבלה נגזרת מתמידה (PDT), ולכן יש להן את אותן דרישות כמו לטבלאות PDT. פרטים נוספים זמינים בדף התיעוד בנושא טבלאות נגזרות ב-Looker.
אם הניב שלכם תומך ב-PDT מצטבר, אתם יכולים ליצור PDT מצטבר בפרויקט. Looker יוצר טבלאות PDT מצטברות על ידי הוספת נתונים חדשים לטבלה, במקום לבנות מחדש את הטבלה כולה. מכיוון שטבלאות מצטברות הן בעצמן סוג של PDT, אפשר ליצור גם טבלאות מצטברות מצטברות. מידע נוסף על PDT מצטבר זמין בדף התיעוד בנושא PDT מצטבר. בדף התיעוד של הפרמטר increment_key מופיעה דוגמה לטבלת צבירה מצטברת.
משתמש עם הרשאה develop יכול לבטל את הגדרות השמירה ולבנות מחדש את כל טבלאות הצבירה של שאילתה כדי לקבל את הנתונים העדכניים ביותר. כדי לבנות מחדש את הטבלאות של שאילתה, בוחרים באפשרות בנייה מחדש של טבלאות נגזרות והרצה בתפריט ההגדרות (סמל גלגל השיניים) של פעולות ב-Explore.
כדי שהאפשרות הזו תהיה זמינה, צריך להמתין עד שהשאילתה ב'ניתוח נתונים' תיטען.
האפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה) בונה מחדש את כל הטבלאות הנגזרות שההפניה אליהן מופיעה בשאילתה, וגם את כל הטבלאות הנגזרות שהטבלאות בשאילתה תלויות בהן. הם כוללים טבלאות מצטברות, שהן בעצמן סוג של טבלה נגזרת מתמידה (PDT).
אם משתמש יבחר באפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה), השאילתה תמתין עד שהטבלאות ייבנו מחדש לפני שהתוצאות ייטענו. השאילתות של משתמשים אחרים עדיין ישתמשו בטבלאות הקיימות. אחרי שהטבלאות הקבועות ייבנו מחדש, כל המשתמשים ישתמשו בטבלאות שנבנו מחדש.
פרטים נוספים על האפשרות Rebuild Derived Tables & Run זמינים בדף התיעוד בנושא טבלאות נגזרות ב-Looker.
פתרון בעיות
כפי שמתואר בקטע קביעה של טבלת הצבירה שמשמשת לשאילתה, אם אתם נמצאים במצב פיתוח, אתם יכולים להריץ שאילתות בכלי הניתוח וללחוץ על הכרטיסייה SQL כדי לראות הערות לגבי טבלת הצבירה שמשמשת לשאילתה, אם יש כאלה.
בכרטיסייה SQL מופיעים גם הערות לגבי הסיבות לכך שלא נעשה שימוש בטבלאות מצטברות בשאילתה, אם זה המקרה. בטבלאות מצטברות שלא נעשה בהן שימוש, התגובה תתחיל במילים:
Did not use [explore name]::[aggregate table name];
לדוגמה, הנה הערה שמסבירה למה הטבלה המצטברת sales_daily שהוגדרה בorder_items Explore לא שימשה לשאילתה:
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
במקרה הזה, המסננים בשאילתה מנעו את השימוש בטבלה המסכמת.
בטבלה הבאה מפורטות סיבות אפשריות נוספות לכך שלא ניתן להשתמש בטבלה מסכמת, וגם שלבים שאפשר לבצע כדי לשפר את השימושיות של הטבלה המסכמת.
| הסיבה לכך שלא נעשה שימוש בטבלה המסכמת | הסבר ושלבים אפשריים |
|---|---|
| אין שדה כזה בניתוח. | יש שגיאה בסוג האימות של LookML. הסיבה לכך היא כנראה שהטבלה המצטברת לא הוגדרה בצורה נכונה, או שהייתה שגיאת הקלדה ב-LookML של הטבלה המצטברת. הגורם הסביר ביותר לבעיה הוא שם שדה שגוי או משהו דומה.כדי לפתור את הבעיה, מוודאים שהמאפיינים והמדדים בטבלה המסכמת תואמים לשמות השדות ב-Explore. מידע נוסף על הגדרת טבלה מסכמת מופיע בדף התיעוד של הפרמטר aggregate_table. |
| הטבלה המצטברת לא כוללת את השדות הבאים בשאילתה. | כדי להשתמש בטבלה מסכמת בשאילתת Explore, הטבלה צריכה לכלול את כל המאפיינים והמדדים שנדרשים לשאילתת ה-Explore, כולל השדות שמשמשים למסננים בשאילתת ה-Explore. אם שאילתת ניתוח ב-Explore מכילה מאפיין או מדד שלא נמצאים בטבלה מסכמת, מערכת Looker לא יכולה להשתמש בטבלה המסכמת ותשתמש במקום זאת בטבלת הבסיס. פרטים נוספים מופיעים בקטע גורמים שמשפיעים על השדות בדף הזה. החריג היחיד הוא מאפייני מסגרת זמן, כי אפשר לגזור מסגרות זמן עם רמת פירוט גסה יותר ממסגרות זמן עם רמת פירוט מדויקת יותר. כדי לפתור את הבעיה, מוודאים שהשדות של שאילתת ה-Explore כלולים בהגדרת טבלה מסכמת. |
| השאילתה הכילה את המסננים הבאים שלא נכללו כשדות ולא תאמו בדיוק למסננים בטבלה המסכמת. | המסננים בשאילתת ה-Explore מונעים מ-Looker להשתמש בטבלה מסכמת. כדי לפתור את הבעיה, אפשר לבצע אחת מהפעולות הבאות:
|
| השאילתה מכילה את המדדים הבאים שלא ניתן לצבור. | השאילתה מכילה סוג אחד או יותר של מדדים שלא נתמכים בחישובים מצטברים, כמו ספירה של ערכים ייחודיים, ערך חציוני או אחוזון.כדי לפתור את הבעיה, צריך לבדוק את הסוג של כל מדד בשאילתה ולוודא שהוא אחד מסוגי המדדים הנתמכים. בנוסף, אם יש הצטרפות ב-Explore, צריך לוודא שהמדדים לא מומרים למדדים נפרדים (צבירות סימטריות) באמצעות הצטרפות מפוצלת. הסבר מופיע בקטע מצטברים סימטריים ב-Explores עם הצטרפויות בדף הזה. |
| טבלה מסכמת אחרת התאימה יותר לאופטימיזציה. | היו כמה טבלאות מסכמות מתאימות לשאילתה, ומערכת Looker מצאה טבלה מסכמת אופטימלית יותר לשימוש במקום זאת. במקרה כזה לא צריך לעשות כלום. |
Looker לא ביצע שום קיבוץ (בגלל פרמטר primary_key או cancel_grouping_fields) ולכן אי אפשר לצמצם את השאילתה. |
השאילתה מפנה למאפיין שלא מאפשר לה להכיל פסוקית GROUP BY, ולכן Looker לא יכול להשתמש בשום טבלה מסכמת בשביל השאילתה.
כדי לפתור את הבעיה, מוודאים שהפרמטר primary_key של התצוגה והפרמטר cancel_grouping_fields של הכלי'ניתוח נתונים' מוגדרים בצורה נכונה. |
| הטבלה המסכמת הכילה מסננים שלא נכללו בשאילתה. | בטבלה מסכמת יש מסנן שאינו מסנן זמן, שלא מופיע בשאילתה.כדי לפתור את הבעיה, אפשר להסיר את המסנן מטבלה מסכמת. פרטים נוספים מופיעים בקטע גורמים לסינון בדף הזה. |
שדה מוגדר כשדה סינון בלבד בשאילתת הניתוח, אבל הוא מופיע בפרמטר dimensions של הטבלה המצטברת. |
הפרמטר dimensions בטבלת הצבירה מציג שדה שמוגדר רק כשדה filter בשאילתת הניתוח.כדי לפתור את הבעיה, צריך להסיר את השדה מהרשימה dimensions של הטבלה המצטברת. אם השדה הזה נדרש לטבלת הצבירה, מוסיפים אותו לרשימה filters בשאילתת טבלת הצבירה. |
| כלי האופטימיזציה לא יכול לקבוע למה לא נעשה שימוש בטבלה מסכמת. | ההערה הזו שמורה למקרים חריגים. אם אתם רואים את ההודעה הזו לגבי שאילתת Explore שמשמשת אתכם לעיתים קרובות, אתם יכולים ליצור טבלה מסכמת שתהיה זהה לשאילתת ה-Explore. אפשר לקבל LookML של טבלה מצטברת מתוך ניתוח, כמו שמתואר בדף הפרמטר aggregate_table. |
דברים שכדאי לקחת בחשבון
צבירות סימטריות ל-Explores עם שאילתות איחוד (join)
חשוב לדעת שבניתוח נתונים (Explore) שמצטרפות אליו כמה טבלאות של מסד נתונים, Looker יכול להציג מדדים מסוג SUM, COUNT ו-AVERAGE בתור SUM DISTINCT, COUNT DISTINCT ו-AVERAGE DISTINCT, בהתאמה. Looker עושה את זה כדי למנוע טעויות בחישובים של fanout. לדוגמה, מדד count מוצג כסוג מדד count_distinct. הסיבה לכך היא למנוע חישובים שגויים של fanout בשאילתות איחוד (join), והיא חלק מהפונקציונליות של צבירות סימטריות ב-Looker. בדף השיטות המומלצות בנושא צבירות סימטריות מוסבר על התכונה הזו של Looker.
הפונקציונליות של צבירות סימטריות מונעת חישובים שגויים, אבל היא גם יכולה למנוע שימוש בטבלאות צבירה במקרים מסוימים, ולכן חשוב להבין אותה.
לגבי סוגי המדדים שנתמכים על ידי מודעות מצטברת, זה רלוונטי ל-sum, ל-count ול-average. Looker יציג את סוגי המדדים האלה כ-DISTINCT אם:
- המדד מגיע מהתצוגה 'אחד' של הצטרפות מסוג רבים לאחד או אחד לרבים.
- המדד מחושב מתוך כל אחת מהתצוגות של צירוף many-to-many.
בrelationship דף התיעוד של הפרמטר יש הסבר על סוגי ההצטרפות האלה.
אם אתם מגלים שהטבלה המצטברת לא נמצאת בשימוש בגלל הסיבה הזו, אתם יכולים ליצור טבלה מצטברת שתתאים בדיוק לשאילתת ניתוח כדי להשתמש בסוגי המדדים האלה בניתוח עם הצטרפות. מידע נוסף זמין בקטע יצירת טבלאות מצטברות שתואמות בדיוק לשאילתות ב-Explore בדף הזה.
בנוסף, אם יש לכם ניב SQL שתומך בסקיצות של HyperLogLog, אתם יכולים להוסיף את הפרמטר allow_approximate_optimization: yes למדד. כשמדד ספירה מוגדר עם allow_approximate_optimization: yes, Looker יכול להשתמש במדד למודעות מצטברת, גם אם הוא מוצג כספירה נפרדת.
פרטים נוספים ורשימה של ניבי SQL שתומכים בסקיצות של HyperLogLog זמינים בדף התיעוד של הפרמטר allow_approximate_optimization.
תמיכה בניבים להבנה של נתונים מצטברים
האפשרות להשתמש ב-Aggregate Awareness תלויה בדיאלקט של מסד הנתונים שבו משתמש החיבור שלכם ל-Looker. בגרסה האחרונה של Looker, הדיאלקטים הבאים תומכים ב-Aggregate Awareness:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
תמיכה בדיאלקטים לבנייה מצטברת של טבלאות מסכמות
כדי ש-Looker יתמוך בטבלאות מצטברות מצטברות בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בהן גם כן. בטבלה הבאה מפורטים הניבים שתומכים בבנייה מצטברת של PDT בגרסה האחרונה של Looker:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |