בדף הזה מוגדרים המונחים והמושגים הבסיסיים הבאים, שסביר להניח שתיתקלו בהם לעיתים קרובות במהלך פיתוח LookML:
- פרויקטים של LookML
- מבנים עיקריים של LookML (כמו מודלים, תצוגות ו-Explores)
- טבלאות נגזרות
- חיבורים למסד נתונים
- תלות באותיות רישיות
מראה ולוחות בקרה בהגדרה אישית לא מתוארים בדף הזה, כי משתמשים יוצרים אותם בלי להשתמש ב-LookML. עם זאת, השאילתות שלהם מסתמכות על רכיבי LookML בסיסיים שמוסברים בדף הזה.
במילון המונחים של Looker מופיעה רשימה מקיפה של מונחים והגדרות שמשמשים ב-Looker. סקירה מקיפה של פרמטרים של LookML שאפשר להשתמש בהם בפרויקט LookML מופיעה בדף LookML – הפניה מהירה.
במאמר מונחים ומושגים משותפים ב-Looker וב-Data Studio מוסבר על ההבדלים בין מונחים ומושגים דומים ב-Looker וב-Data Studio.
פרויקט של LookML
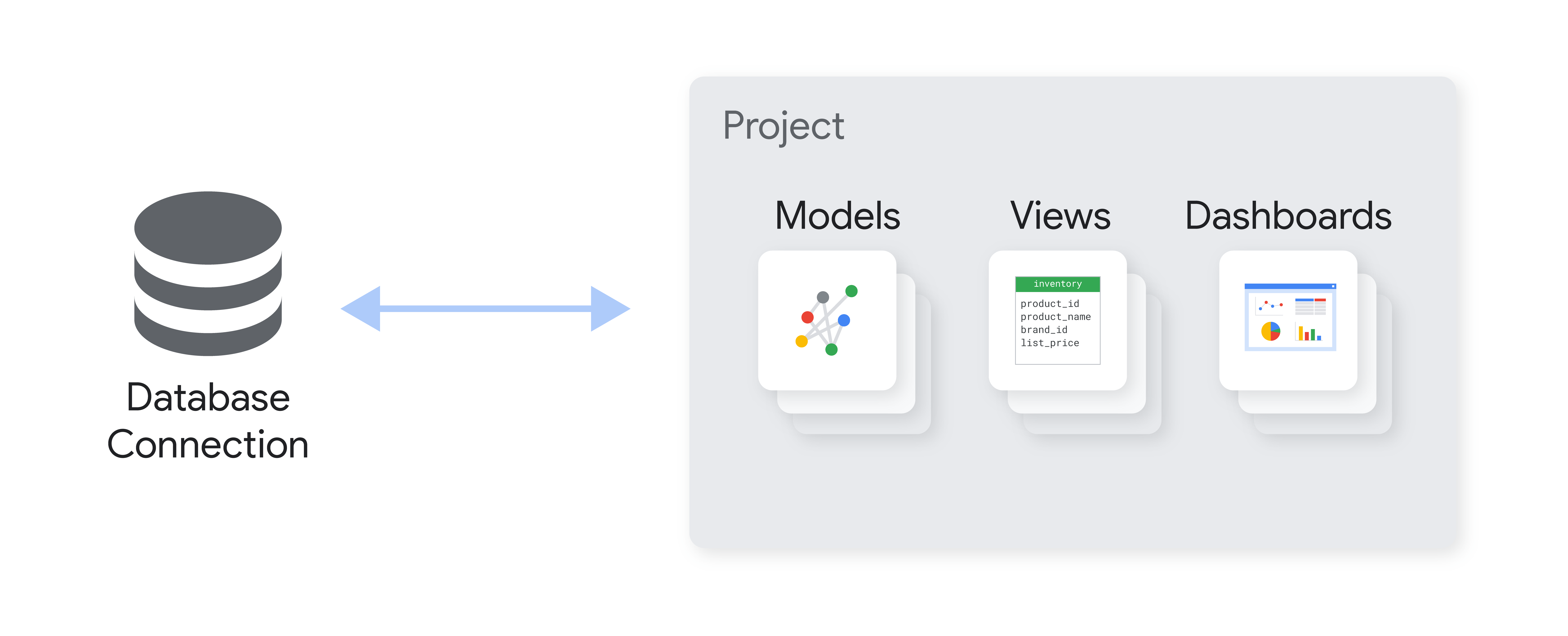
ב-Looker, פרויקט הוא אוסף של קבצים שמתארים את האובייקטים, את החיבורים למסד הנתונים ואת רכיבי ממשק המשתמש שישמשו לביצוע שאילתות SQL. ברמה הבסיסית ביותר, הקבצים האלה מתארים את הקשר בין הטבלאות במסד הנתונים ואת האופן שבו Looker צריך לפרש אותן. יכול להיות שהקבצים יכללו גם פרמטרים של LookML שמגדירים או משנים את האפשרויות שמוצגות בממשק המשתמש של Looker. כל פרויקט של LookML נמצא במאגר Git משלו לצורך ניהול גרסאות.
אחרי חיבור Looker למסד הנתונים, אפשר לציין את החיבור למסד הנתונים שבו רוצים להשתמש בפרויקט Looker.
אפשר לגשת לפרויקטים דרך התפריט פיתוח ב-Looker (פרטים ואפשרויות נוספות זמינים במאמר גישה לקבצי פרויקט).
מידע על יצירת פרויקט חדש זמין בדף התיעוד בנושא יצירת מודל. מידע על גישה לפרויקטים קיימים של LookML וביצוע שינויים בהם זמין בדף התיעוד בנושא גישה לפרטי פרויקט ועריכה שלהם.
חלקים של פרויקט
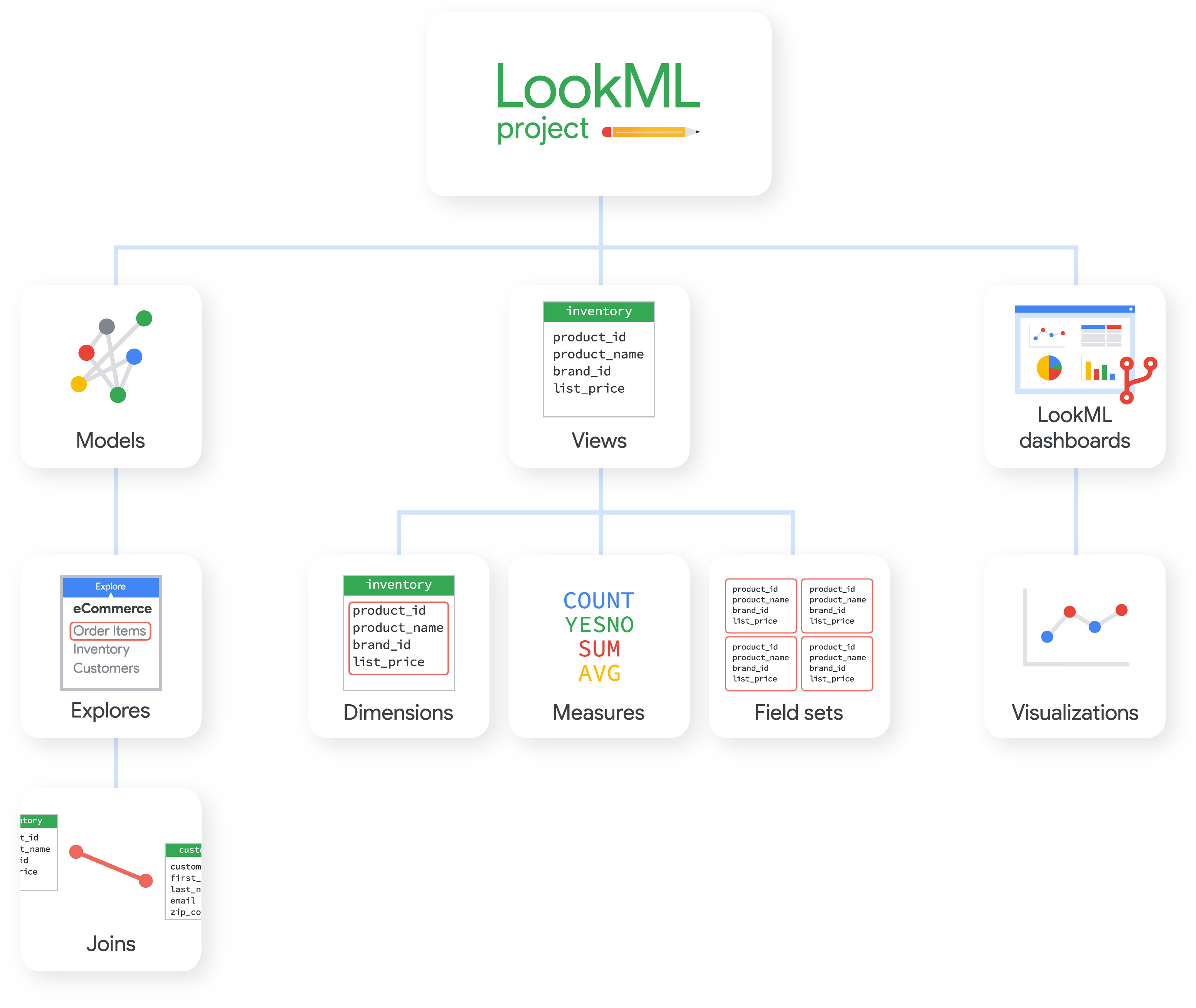
כפי שמוצג בדיאגרמה, אלה כמה מסוגי הקבצים הנפוצים יותר בפרויקט של LookML:
- מודל מכיל מידע על הטבלאות שבהן צריך להשתמש ועל האופן שבו צריך לצרף אותן. בדרך כלל מגדירים כאן את המודל, את ה-Explores שלו ואת ה-Joins שלו.
- תצוגה מכילה מידע על אופן הגישה למידע מכל טבלה (או ממספר טבלאות שמצורפות יחד) או על אופן החישוב של המידע הזה. בדרך כלל מגדירים כאן את התצוגה, את המאפיינים והמדדים שלה ואת קבוצות השדות שלה.
- הגדרת Explore מתבצעת בדרך כלל בקובץ מודל, אבל לפעמים צריך קובץ Explore נפרד לצורך טבלה נגזרת או כדי להרחיב או לשפר Explore במודלים שונים.
- קובץ מניפסט יכול להכיל הוראות לשימוש בקבצים שייובאו מפרויקט אחר או בהגדרות הלוקליזציה של הפרויקט.
בנוסף לקבצים של מודלים, תצוגות, ניתוחים ומניפסטים, פרויקט יכול לכלול סוגים אחרים של קבצים שקשורים לדברים כמו לוחות בקרה מובנים, תיעוד, לוקליזציה ועוד. מידע נוסף על סוגי הקבצים האלה ועל סוגי קבצים אחרים שיכולים להיות בפרויקט של LookML זמין בדף התיעוד בנושא קבצים בפרויקט LookML.
הקבצים האלה ביחד יוצרים פרויקט אחד. אם אתם משתמשים ב-Git לניהול גרסאות, בדרך כלל כל פרויקט מגובה על ידי מאגר Git משלו.
מאיפה מגיעים פרויקטים וקבצים של LookML?
הדרך הנפוצה ביותר ליצור קובצי LookML היא יצירת פרויקט של LookML ממסד הנתונים. אפשר גם ליצור פרויקט ריק וליצור באופן ידני את קובצי ה-LookML שלו.
כשיוצרים פרויקט חדש ממסד הנתונים, Looker יוצר קבוצת קבצים בסיסית שאפשר להשתמש בה כתבנית לבניית הפרויקט:
- כמה קבצים של תצוגה, קובץ אחד לכל טבלה במסד הנתונים.
- קובץ מודל אחד. קובץ המודל מכריז על Explore לכל תצוגה. כל הצהרת Explore כוללת לוגיקה של
joinלצירוף של כל תצוגה ש-Looker יכול לקבוע שהיא קשורה ל-Explore.
מכאן אפשר להתאים אישית את הפרויקט על ידי הסרת תצוגות וניתוחים לא רצויים והוספה של מאפיינים ומדדים מותאמים אישית.
מבנים עיקריים של LookML
כפי שמוצג בתרשים של חלקי פרויקט, פרויקט מכיל בדרך כלל קובץ מודל אחד או יותר, שמכילים פרמטרים שמגדירים מודל, את ה-Explores וה-joins שלו. בנוסף, פרויקטים מכילים בדרך כלל קובץ תצוגה אחד או יותר, שכל אחד מהם מכיל פרמטרים שמגדירים את התצוגה ואת השדות שלה (כולל מאפיינים ומדדים) וקבוצות של שדות. הפרויקט יכול להכיל גם קובץ מניפסט של הפרויקט, שמאפשר להגדיר הגדרות ברמת הפרויקט. בקטע הזה מתוארים המבנים העיקריים האלה.
דגם
מודל הוא פורטל מותאם אישית למסד הנתונים, שנועד לספק למשתמשים עסקיים ספציפיים ניתוח נתונים אינטואיטיבי. יכולים להיות כמה מודלים לאותו חיבור למסד נתונים בפרויקט של LookML אחד. כל מודל יכול לחשוף נתונים שונים למשתמשים שונים. לדוגמה, סוכני מכירות צריכים נתונים שונים מאלה שדרושים למנהלים בחברה, ולכן כדאי לפתח שני מודלים כדי להציג תצוגות של מסד הנתונים שמתאימות לכל משתמש.
מודל מציין חיבור למסד נתונים יחיד. מפתח גם מגדיר ניתוחים של מודל בקובץ המודל. כברירת מחדל, ניתוחים מתארגנים לפי שם המודל שבו הם מוגדרים. המשתמשים שלכם רואים את המודלים ברשימה בתפריט חיפוש והצגה.
מידע נוסף על קובצי מודלים, כולל המבנה והתחביר הכללי של קובצי מודלים, זמין בדף התיעוד בנושא סוגי קבצים בפרויקט של LookML.
פרטים על פרמטרים של LookML שאפשר להשתמש בהם בקובץ מודל מופיעים בדף התיעוד פרמטרים של מודל.
הצגה
הצהרת תצוגה מגדירה רשימה של שדות (מאפיינים או מדדים) והקישור שלהם לטבלה בסיסית או לטבלה נגזרת. ב-LookML, תצוגה מפנה בדרך כלל לטבלת מסד נתונים בסיסית, אבל היא יכולה גם לייצג טבלה נגזרת.
תצוגה מפורטת יכולה להצטרף לתצוגות מפורטות אחרות. הקשר בין התצוגות מוגדר בדרך כלל כחלק מהצהרת הניתוח בקובץ מודל.
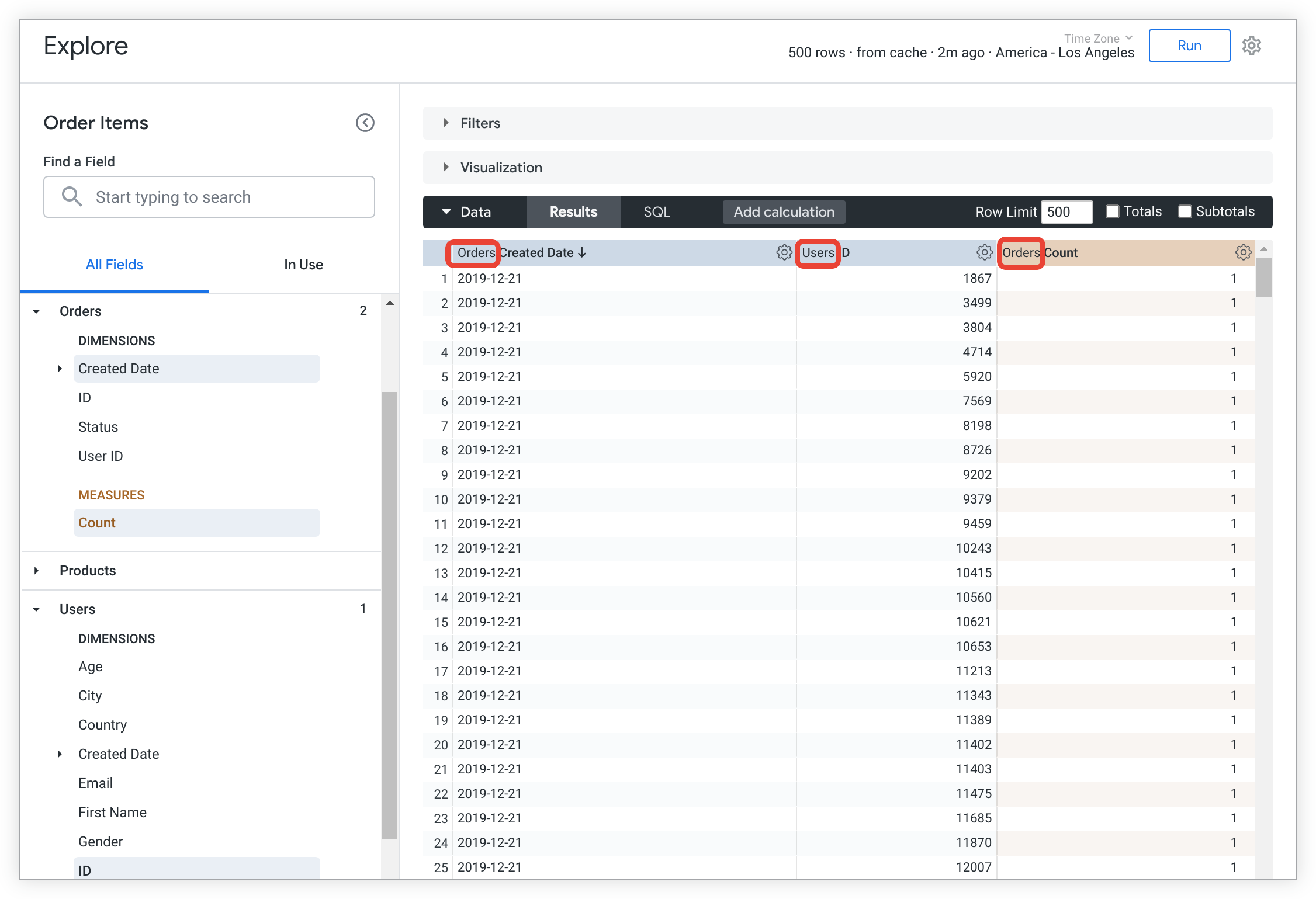
כברירת מחדל, שמות התצוגות מופיעים בתחילת השמות של המאפיינים והמדדים בטבלת הנתונים של הניתוח. מוסכמת השמות הזו מאפשרת לדעת בבירור לאיזה תצוגה שדה שייך. בדוגמה הבאה, שמות התצוגות Orders ו-Users מופיעים לפני שמות השדות בטבלת הנתונים:
למידע נוסף על קובצי תצוגה, כולל המבנה והתחביר הכללי של קובצי תצוגה, אפשר לעיין במאמר בנושא סוגי קבצים בפרויקט של LookML.
במאמר פרמטרים של תצוגה מפורטים הפרמטרים של LookML שאפשר להשתמש בהם בקובץ תצוגה.
שלב שני
ניתוח נתונים הוא תצוגה שמשתמשים יכולים להריץ עליה שאילתות. אפשר לחשוב על הכלי 'ניתוח נתונים' כנקודת התחלה לשאילתה, או במונחי SQL, כ-FROM בהצהרת SQL. לא כל הצפיות הן חיפושים, כי לא כל הצפיות מתארות ישות שמעניינת את המשתמש. לדוגמה, תצוגה של מדינות שתואמת לטבלת בדיקה של שמות מדינות לא מצדיקה יצירת ניתוח, כי משתמשים עסקיים אף פעם לא צריכים לשלוח אליה שאילתה ישירות. לעומת זאת, משתמשים עסקיים כנראה ירצו להריץ שאילתות בתצוגה Orders, ולכן הגיוני להגדיר Explore עבור Orders. בדף התיעוד בנושא צפייה ב-Explores ואינטראקציה איתם ב-Looker מוסבר איך משתמשים מקיימים אינטראקציה עם Explores כדי לשלוח שאילתות לנתונים.
ב-Looker, המשתמשים יכולים לראות את הניתוחים ברשימה בתפריט ניתוח. הניתוחים מופיעים מתחת לשמות של המודלים שאליהם הם משתייכים.
לפי המוסכמה, הצהרות על ניתוחים מתבצעות בקובץ המודל באמצעות הפרמטר explore. בדוגמה הבאה של קובץ מודל, רכיב ה-Explore orders למסד נתונים של מסחר אלקטרוני מוגדר בקובץ המודל. התצוגות orders ו-customers שאליהן יש הפניה בהצהרה explore מוגדרות במקום אחר, בקובצי התצוגה המתאימים.
connection: order_database
include: "filename_pattern"
explore: orders {
join: customers {
sql_on: ${orders.customer_id} = ${customers.id} ;;
}
}
בדוגמה הזו, הפרמטר connection משמש לציון החיבור למסד הנתונים של המודל, והפרמטר include משמש לציון הקבצים שהמודל יוכל להפנות אליהם.
ההצהרה explore בדוגמה הזו מציינת גם קשרי צירוף בין תצוגות. פרטים על הצהרות join זמינים בקטע על צירופים בדף הזה. במאמר בנושא פרמטרים של צירוף מפורטים פרמטרים של LookML שאפשר להשתמש בהם עם הפרמטר join.
שדות של מאפיינים ומדדים
תצוגות מכילות שדות, בעיקר מאפיינים ומדדים, שהם אבני הבניין הבסיסיות לשאילתות ב-Looker.
ב-Looker, מאפיין הוא שדה שאפשר לקבץ, ואפשר להשתמש בו כדי לסנן תוצאות של שאילתות. הוא יכול להיות כל אחת מהאפשרויות הבאות:
- מאפיין שמשויך ישירות לעמודה בטבלה בסיסית
- עובדה או ערך מספרי
- ערך נגזר שמחושב על סמך הערכים של שדות אחרים בשורה אחת
ב-Looker, מאפיינים תמיד מופיעים בסעיף GROUP BY של ה-SQL שנוצר על ידי Looker.
לדוגמה, מאפיינים בתצוגה מוצרים יכולים לכלול את שם המוצר, דגם המוצר, צבע המוצר, מחיר המוצר, תאריך יצירת המוצר ותאריך סיום חיי המוצר.
מדד הוא שדה שמשתמש בפונקציית צבירה של SQL, כמו COUNT, SUM, AVG, MIN או MAX. כל שדה שמחושב על סמך ערכים של מדדים אחרים הוא גם מדד. אפשר להשתמש במדדים כדי לסנן ערכים מקובצים. לדוגמה, המדדים בתצוגה מכירות יכולים לכלול את מספר הפריטים הכולל שנמכרו (ספירה), את מחיר המכירה הכולל (סכום) ואת מחיר המכירה הממוצע (ממוצע).
ההתנהגות והערכים הצפויים של שדה תלויים בסוג המוצהר שלו, כמו string, number או time. לגבי מדדים, הסוגים כוללים פונקציות צבירה, כמו sum ו-percent_of_previous. פרטים נוספים זמינים במאמרים בנושא סוגי מאפיינים וסוגי מדדים.
ב-Looker, השדות מופיעים בדף ניתוח בבורר השדות בצד ימין של הדף. אפשר להרחיב תצוגה בבוחר השדות כדי לראות את רשימת השדות שאפשר לשלוף מהתצוגה הזו.
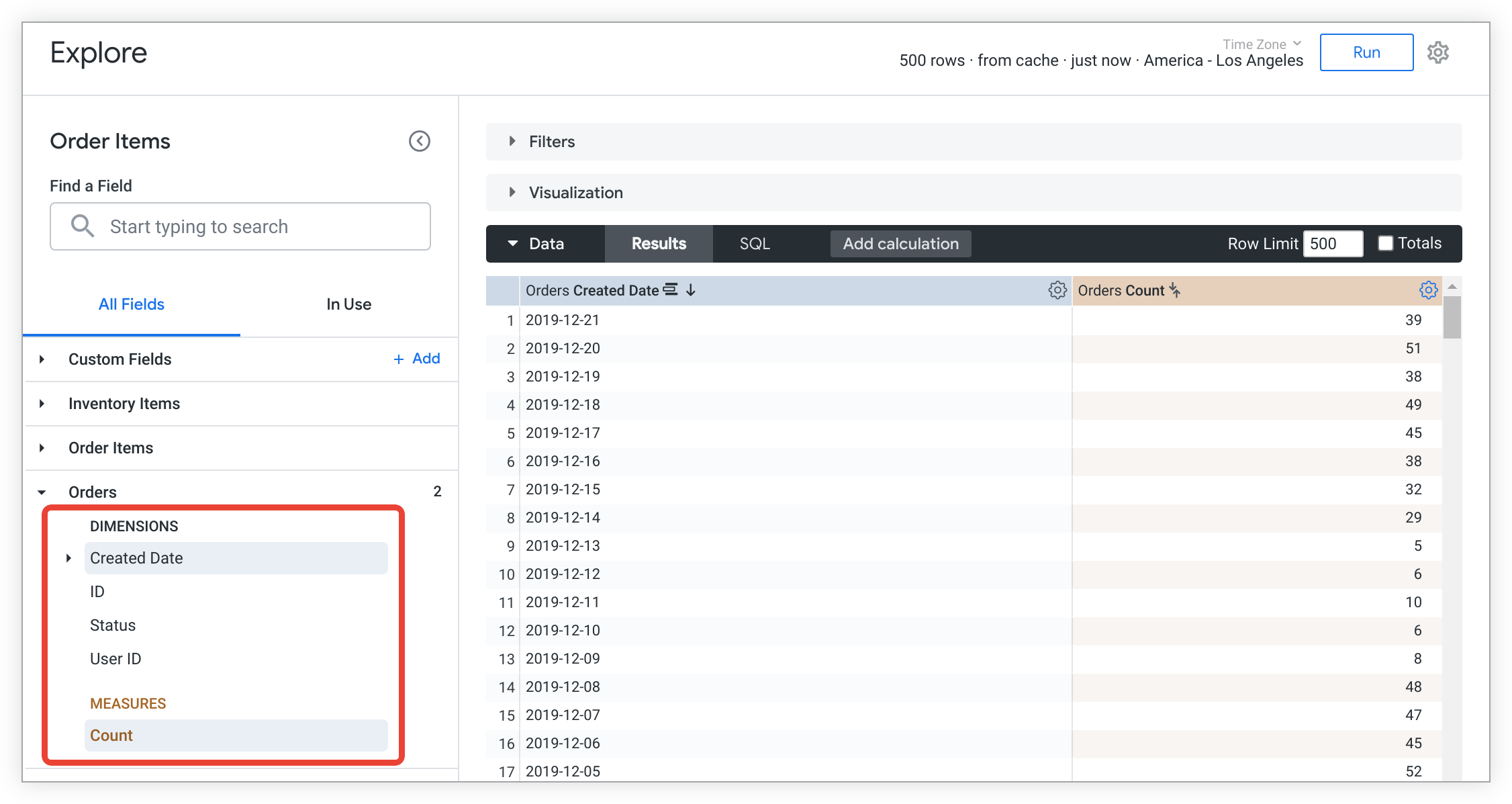
לפי המוסכמה, שדות מוצהרים כחלק מהתצוגה שאליה הם שייכים, ומאוחסנים בקובץ תצוגה. בדוגמה הבאה מוצגות כמה הצהרות על מאפיינים ומדדים. שימו לב לשימוש באופרטור ההחלפה ($) כדי להפנות לשדות בלי להשתמש בשם עמודת SQL עם היקף מלא.
ריכזנו כאן כמה דוגמאות להצהרות על מאפיינים ומדדים:
view: orders {
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;;
}
dimension: customer_id {
sql: ${TABLE}.customer_id ;;
}
dimension: amount {
type: number
value_format: "0.00"
sql: ${TABLE}.amount ;;
}
dimension_group: created {
type: time
timeframes: [date, week]
sql: ${TABLE}.created_at ;;
}
measure: count {
type: count # creates sql COUNT(orders.id)
sql: ${id} ;;
}
measure: total_amount {
type: sum # creates sql SUM(orders.amount)
sql: ${amount} ;;
}
}
אפשר גם להגדיר dimension_group, שיוצר כמה מאפיינים שקשורים לזמן בבת אחת, ושדות filter, שמתאימים למגוון תרחישי שימוש מתקדמים כמו מסננים מבוססי-תבניות.
בדף התיעוד בנושא פרמטרים של שדות מפורטים כל הפרטים על הצהרה על שדות ועל ההגדרות השונות שאפשר להחיל עליהם.
הצטרפויות
כחלק מהצהרת explore, כל הצהרת join מציינת תצוגה שאפשר לצרף לניתוח. כשמשתמש יוצר שאילתה שכוללת שדות מכמה תצוגות, Looker יוצר באופן אוטומטי לוגיקה של צירוף SQL כדי להביא את כל השדות בצורה נכונה.
דוגמה לצירוף בהצהרת explore:
# file: ecommercestore.model.lookml
connection: order_database
include: "filename_pattern" # include all the views
explore: orders {
join: customers {
sql_on: ${orders.customer_id} = ${customers.id} ;;
}
}
פרטים נוספים זמינים בדף התיעוד בנושא עבודה עם הצטרפויות ב-LookML.
קובצי מניפסט של פרויקטים
יכול להיות שהפרויקט שלכם יכיל קובץ מניפסט של הפרויקט, שמשמש להגדרות ברמת הפרויקט, כמו הגדרות לציון פרויקטים אחרים שרוצים לייבא לפרויקט הנוכחי, להגדרת קבועים של LookML, לציון הגדרות לוקליזציה של מודלים ולהוספת תוספים ותצוגות חזותיות בהתאמה אישית לפרויקט.
לכל פרויקט יכול להיות רק קובץ מניפסט אחד. שם הקובץ צריך להיות manifest.lkml והוא צריך להיות ממוקם ברמת השורש של מאגר ה-Git. כשמשתמשים בתיקיות בסביבת הפיתוח המשולבת, חשוב לוודא שקובץ manifest.lkml נשמר ברמת השורש של מבנה התיקיות של הפרויקט.
כדי לייבא קובצי LookML מפרויקט אחר, משתמשים בקובץ המניפסט של הפרויקט כדי לציין שם לפרויקט הנוכחי ואת המיקום של פרויקטים חיצוניים, שיכולים להיות מאוחסנים באופן מקומי או מרחוק. לדוגמה:
# This project
project_name: "my_project"
# The project to import
local_dependency: {
project: "my_other_project"
}
remote_dependency: ga_360_block {
url: "https://github.com/llooker/google_ga360"
ref: "4be130a28f3776c2bf67a9acc637e65c11231bcc"
}
אחרי שמגדירים את הפרויקטים החיצוניים בקובץ המניפסט של הפרויקט, אפשר להשתמש בפרמטר include בקובץ המודל כדי להוסיף קבצים מהפרויקטים החיצוניים האלה לפרויקט הנוכחי. לדוגמה:
include: "//my_other_project/imported_view.view"
include: "//ga_360_block/*.view"
מידע נוסף זמין במאמר בנושא ייבוא קבצים מפרויקטים אחרים.
כדי להוסיף לוקליזציה למודל, משתמשים בקובץ המניפסט של הפרויקט כדי לציין הגדרות לוקליזציה שמוגדרות כברירת מחדל. לדוגמה:
localization_settings: {
default_locale: en
localization_level: permissive
}
הגדרת ברירת מחדל של הגדרות לוקליזציה היא שלב אחד בתהליך הלוקליזציה של המודל. מידע נוסף זמין במאמר בנושא לוקליזציה של מודל LookML.
ערכות
ב-Looker, set היא רשימה שמגדירה קבוצה של שדות שמשמשים יחד. בדרך כלל, משתמשים בקבוצות כדי לציין אילו שדות יוצגו אחרי שמשתמש מציג פירוט של הנתונים. הגדרות של קבוצות לניתוח מעמיק מצוינות ברמת השדה, כך שאתם מקבלים שליטה מלאה על הנתונים שמוצגים כשמשתמש לוחץ על ערך בטבלה או בלוח בקרה. אפשר להשתמש בקבוצות גם כמאפיין אבטחה כדי להגדיר קבוצות של שדות שגלויות למשתמשים ספציפיים.
בדוגמה הבאה מוצגת הצהרה על קבוצה בתצוגה המפורטת order_items, שבה מוגדרים שדות שמפרטים פרטים רלוונטיים על פריט שנרכש. שימו לב שאפשר להגדיר את שדות ההפניות מתוך תצוגות אחרות על ידי ציון היקף.
set: order_items_stats_set {
fields: [
id, # scope defaults to order_items view
orders.created_date, # scope is "orders" view
orders.id,
users.name,
users.history, # show all products this user has purchased
products.item_name,
products.brand,
products.category,
total_sale_price
]
}
פרטים מלאים על השימוש בערכות מופיעים בדף התיעוד של הפרמטר set.
הצגת פירוט
ב-Looker, אפשר להגדיר שדה כך שהמשתמשים יוכלו לבצע ניתוח מעמיק יותר של הנתונים. אפשר להשתמש בתכונה 'פירוט' גם בטבלאות של תוצאות שאילתות וגם בלוחות בקרה. התעמקות בנתונים מתחילה שאילתה חדשה שמוגבלת על ידי הערך שעליו לוחצים.
ההתנהגות של ההתעמקות בנתונים שונה עבור מאפיינים ומדדים:
- כשמבצעים Drill Down על מאפיין, השאילתה החדשה מסננת לפי הערך של ה-Drill Down. לדוגמה, אם תלחצו על תאריך ספציפי בשאילתה של הזמנות לקוחות לפי תאריך, בשאילתה החדשה יוצגו הזמנות רק בתאריך הספציפי הזה.
- כשמבצעים Drill-down במדד, השאילתה החדשה תציג את מערך הנתונים שתורם למדד. לדוגמה, כשמבצעים פירוט של ספירה, השאילתה החדשה תציג את השורות שמשמשות לחישוב הספירה הזו. כשמבצעים פירוט של מדדים כמו מקסימום, מינימום וממוצע, הפירוט עדיין מציג את כל השורות שתרמו למדד הזה. כלומר, כשמבצעים פירוט של מדד מקסימלי, למשל, מוצגות כל השורות ששימשו לחישוב הערך המקסימלי, ולא רק שורה אחת של הערך המקסימלי.
אפשר להגדיר את השדות שיוצגו בשאילתת ההסתעפות החדשה באמצעות set, או באמצעות הפרמטר drill_fields (לשדות) או הפרמטר drill_fields (לתצוגות).
טבלאות נגזרות
טבלה נגזרת היא שאילתה שהתוצאות שלה משמשות כאילו היא טבלה בפועל במסד הנתונים. טבלאות נגזרות נוצרות באמצעות הפרמטר derived_table בהצהרה view. Looker ניגש לטבלאות נגזרות כאילו היו טבלאות פיזיות עם קבוצת עמודות משלהן. טבלה נגזרת מוצגת כתצוגה משלה, ומגדירה מאפיינים ומדדים באותו אופן כמו תצוגות רגילות. אפשר להריץ שאילתות על התצוגה של טבלה נגזרת ולצרף אותה לתצוגות אחרות, בדיוק כמו כל תצוגה אחרת.
אפשר גם להגדיר טבלאות נגזרות כטבלאות נגזרות מתמידות (PDT). אלה טבלאות נגזרות שנכתבות לסכימת גירוד במסד הנתונים שלכם, ונוצרות מחדש באופן אוטומטי לפי לוח הזמנים שאתם מציינים באמצעות אסטרטגיית התמדה.
מידע נוסף זמין בדף התיעוד בנושא טבלאות נגזרות ב-Looker.
חיבור למסד נתונים
רכיב חשוב נוסף בפרויקט של LookML הוא חיבור למסד נתונים ש-Looker משתמש בו כדי להריץ שאילתות במסד הנתונים. אדמין ב-Looker משתמש בדף Connections כדי להגדיר חיבורים למסד נתונים, ומפתחי LookML משתמשים בפרמטר connection בקובץ מודל כדי לציין באיזה חיבור להשתמש עבור המודל. אם יוצרים פרויקט של LookML ממסד הנתונים, Looker מאכלס אוטומטית את הפרמטר connection בקובץ המודל.
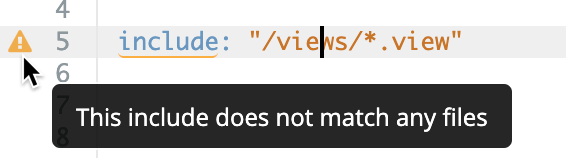
תלות באותיות רישיות (Case sensitivity)
LookML תלוי באותיות רישיות, לכן חשוב להקפיד על התאמה בין האותיות כשמפנים לרכיבי LookML. Looker מתריע אם הפניתם לאלמנט שלא קיים.
לדוגמה, נניח שיש לכם Explore בשם e_flights_pdt, ומפתח LookML משתמש באותיות רישיות לא נכונות (e_FLIGHTS_pdt) כדי להפנות אל ה-Explore הזה. בדוגמה הזו, בסביבת הפיתוח המשולבת של Looker מוצגת אזהרה שהתכונה 'ניתוח נתונים' e_FLIGHTS_pdt לא קיימת. בנוסף, סביבת ה-IDE מציעה את השם של אפשרויות נוספות קיימות, e_flights_pdt:

עם זאת, אם הפרויקט שלכם הכיל גם את e_FLIGHTS_pdt וגם את e_flights_pdt, סביבת הפיתוח המשולבת של Looker לא תוכל לתקן אתכם, ולכן תצטרכו לוודא איזו גרסה התכוונתם להשתמש. בדרך כלל, מומלץ להשתמש באותיות קטנות כשנותנים שמות לאובייקטים של LookML.
גם שמות של תיקיות IDE הם תלויי אותיות רישיות. כשמציינים נתיבי קבצים, צריך להקפיד על אותיות רישיות וקטנות בשמות התיקיות. לדוגמה, אם יש לכם תיקייה בשם Views, אתם צריכים להשתמש באותיות רישיות זהות בפרמטר include. שוב, סביבת הפיתוח המשולבת (IDE) של Looker תציין שגיאה אם האותיות הרישיות לא תואמות לתיקייה קיימת בפרויקט: