
ב-Looker, טבלה נגזרת היא שאילתה שהתוצאות שלה משמשות כאילו השאילתה הייתה טבלה בפועל במסד הנתונים.
לדוגמה, יכול להיות שיש לכם טבלת מסד נתונים בשם orders עם הרבה עמודות. אתם רוצים לחשב מדדים מצטברים ברמת הלקוח, כמו מספר ההזמנות שכל לקוח ביצע או מועד ההזמנה הראשונה של כל לקוח. באמצעות טבלה נגזרת מבוססת LookML (NDT) או טבלה נגזרת שמבוססת על SQL, אפשר ליצור טבלת מסד נתונים חדשה בשם customer_order_summary שכוללת את המדדים האלה.
אחרי זה אפשר לעבוד עם customer_order_summary הטבלה הנגזרת כאילו הייתה כל טבלה אחרת במסד הנתונים.
תרחישי שימוש פופולריים בטבלאות נגזרות מפורטים במאמר ספרי מתכונים של Looker: שימוש אופטימלי בטבלאות נגזרות ב-Looker.
טבלאות נגזרות מבוססות LookML וטבלאות נגזרות מבוססות SQL
כדי ליצור טבלה נגזרת בפרויקט Looker, משתמשים בפרמטר derived_table מתחת לפרמטר view. בתוך הפרמטר derived_table, אפשר להגדיר את השאילתה לטבלה הנגזרת באחת משתי דרכים:
- בטבלה נגזרת מבוססת LookML, מגדירים את הטבלה הנגזרת באמצעות שאילתה מבוססת LookML.
- במקרה של טבלה נגזרת שמבוססת על SQL, מגדירים את הטבלה הנגזרת באמצעות שאילתת SQL.
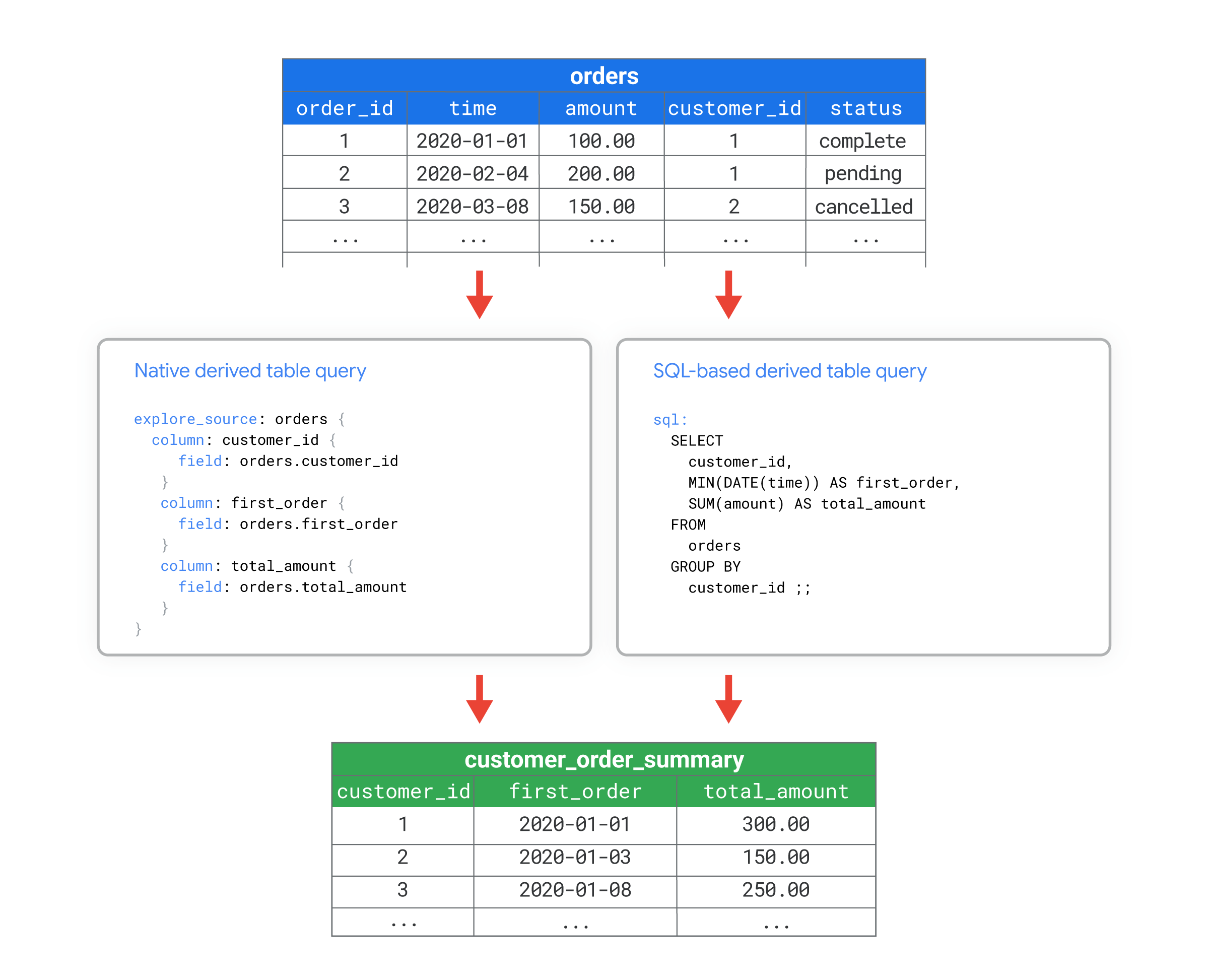
לדוגמה, קובצי התצוגה הבאים מראים איך אפשר להשתמש ב-LookML כדי ליצור תצוגה מטבלת customer_order_summary נגזרת. שתי הגרסאות של LookML ממחישות איך אפשר ליצור טבלאות נגזרות שוות ערך באמצעות LookML או SQL כדי להגדיר את השאילתה של הטבלה הנגזרת:
- הטבלה הנגזרת מבוססת LookML מגדירה את השאילתה באמצעות LookML בפרמטר
explore_source. בדוגמה הזו, השאילתה מבוססת על תצוגתordersקיימת, שמוגדרת בקובץ נפרד שלא מוצג בדוגמה הזו. השאילתהexplore_sourceבטבלה הנגזרת מבוססת LookML (NDT) מביאה את השדותcustomer_id,first_orderו-total_amountמקובץ התצוגהorders. - הטבלה הנגזרת שמבוססת על SQL מגדירה את השאילתה באמצעות SQL בפרמטר
sql. בדוגמה הזו, שאילתת ה-SQL היא שאילתה ישירה של הטבלהordersבמסד הנתונים.
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
שתי הגרסאות יוצרות תצוגה בשם customer_order_summary שמבוססת על הטבלה orders, עם העמודות customer_id, first_order, ו-total_amount.
מלבד הפרמטר derived_table ותתי הפרמטרים שלו, התצוגה customer_order_summary הזו פועלת בדיוק כמו כל קובץ תצוגה אחר. בין אם מגדירים את השאילתה של הטבלה הנגזרת באמצעות LookML או באמצעות SQL, אפשר ליצור מדדים ומאפיינים של LookML שמבוססים על העמודות של הטבלה הנגזרת.
אחרי שמגדירים את הטבלה הנגזרת, אפשר להשתמש בה כמו בכל טבלה אחרת במסד הנתונים.
טבלאות נגזרות מבוססות LookML (NDT)
טבלאות נגזרות מקוריות מבוססות על שאילתות שאתם מגדירים באמצעות מונחי LookML. כדי ליצור טבלה נגזרת מבוססת LookML (NDT), משתמשים בפרמטר explore_source בתוך הפרמטר derived_table של הפרמטר view. כדי ליצור את העמודות של הטבלה הנגזרת מבוססת LookML (NDT), צריך להפנות למאפייני LookML או למדדים במודל. אפשר לראות את הקובץ של תצוגת הטבלה הנגזרת המקורית בדוגמה הקודמת.
בהשוואה לטבלאות נגזרות שמבוססות על SQL, טבלאות נגזרות מקוריות קלות יותר לקריאה ולהבנה כשמבצעים מודלים של הנתונים.
לפרטים נוספים על יצירת טבלאות נגזרות מקוריות, אפשר לעיין בדף התיעוד בנושא יצירת טבלאות נגזרות מקוריות.
טבלאות נגזרות שמבוססות על SQL
כדי ליצור טבלה נגזרת שמבוססת על SQL, מגדירים שאילתה במונחי SQL ויוצרים עמודות בטבלה באמצעות שאילתת SQL. אי אפשר להפנות למאפיינים ולמדדים של LookML בטבלה נגזרת שמבוססת על SQL. אפשר לראות את קובץ התצוגה של הטבלה הנגזרת שמבוססת על SQL בדוגמה הקודמת.
בדרך כלל, מגדירים את שאילתת ה-SQL באמצעות הפרמטר sql בתוך הפרמטר derived_table של הפרמטר view.
קיצור דרך שימושי ליצירת שאילתות שמבוססות על SQL ב-Looker הוא שימוש ב-SQL Runner כדי ליצור את שאילתת ה-SQL ולהפוך אותה להגדרת טבלה נגזרת.
במקרים מסוימים, לא ניתן להשתמש בפרמטר sql. במקרים כאלה, Looker תומך בפרמטרים הבאים להגדרת שאילתת SQL עבור טבלאות נגזרות מתמידות (PDT):
-
create_process: כשמשתמשים בפרמטרsqlעבור PDT, ברקע Looker עוטף אתCREATE TABLEההצהרה של שפת הגדרת הנתונים (DDL) של הניב בשאילתה כדי ליצור את ה-PDT משאילתת ה-SQL. חלק מהדיאלקטים לא תומכים בהצהרת SQLCREATE TABLEבשלב אחד. בניבים האלה, אי אפשר ליצור PDT עם הפרמטרsql. במקום זאת, אפשר להשתמש בפרמטרcreate_processכדי ליצור PDT בכמה שלבים. מידע ודוגמאות מופיעים בדף התיעוד של הפרמטרcreate_process. sql_create: אם תרחיש השימוש שלכם דורש פקודות DDL בהתאמה אישית, והדיאלקט שלכם תומך ב-DDL (לדוגמה, BigQuery ML של Google לחיזוי), אתם יכולים להשתמש בפרמטרsql_createכדי ליצור PDT במקום להשתמש בפרמטרsql. מידע ודוגמאות מופיעים בדף התיעוד בנושאsql_create.
לא משנה אם משתמשים בפרמטר sql, create_process או sql_create, בכל המקרים האלה מגדירים את הטבלה הנגזרת באמצעות שאילתת SQL, ולכן כל אלה נחשבות לטבלאות נגזרות שמבוססות על SQL.
כשמגדירים טבלה נגזרת שמבוססת על SQL, חשוב לתת לכל עמודה כינוי ברור באמצעות AS. הסיבה לכך היא שתצטרכו להפנות לשמות העמודות של קבוצת התוצאות במאפיינים, כמו ${TABLE}.first_order. לכן, בדוגמה הקודמת נעשה שימוש ב-MIN(DATE(time)) AS first_order במקום רק ב-MIN(DATE(time)).
טבלאות נגזרות זמניות וטבלאות נגזרות מתמידות (PDT)
בנוסף להבחנה בין טבלאות נגזרות מבוססות LookML לבין טבלאות נגזרות מבוססות SQL, יש גם הבחנה בין טבלה נגזרת זמנית – שלא נכתבת למסד הנתונים – לבין טבלה נגזרת מתמידה (PDT) – שנכתבת לסכימה במסד הנתונים.
טבלאות נגזרות מבוססות LookML וטבלאות נגזרות מבוססות SQL יכולות להיות זמניות או מתמידות.
טבלאות נגזרות זמניות
הטבלאות הנגזרות שמוצגות למעלה הן דוגמאות לטבלאות נגזרות זמניות. הם זמניים כי לא מוגדר אסטרטגיית התמדה בפרמטר derived_table.
טבלאות נגזרות זמניות לא נכתבות במסד הנתונים. כשמשתמש מריץ שאילתת ניתוח שכוללת טבלה נגזרת אחת או יותר, Looker בונה שאילתת SQL באמצעות שילוב ספציפי לניב של ה-SQL של הטבלאות הנגזרות, בתוספת השדות המבוקשים, שאילתות האיחוד(join) וערכי המסננים. אם השילוב הופעל בעבר והתוצאות עדיין תקפות במטמון, Looker משתמש בתוצאות שבמטמון. מידע נוסף על שמירת שאילתות במטמון ב-Looker זמין בדף העזרה בנושא שמירת שאילתות במטמון.
אחרת, אם Looker לא יכול להשתמש בתוצאות שנשמרו במטמון, הוא צריך להריץ שאילתה חדשה במסד הנתונים בכל פעם שמשתמש מבקש נתונים מטבלה זמנית נגזרת. לכן, חשוב לוודא שהטבלאות הזמניות הנגזרות פועלות בצורה יעילה ולא יגרמו לעומס יתר על מסד הנתונים. במקרים שבהם ייקח זמן להריץ את השאילתה, בדרך כלל עדיף להשתמש בPDT.
ניבי SQL נתמכים של מסדי נתונים לטבלאות נגזרות זמניות
כדי ש-Looker יתמוך בטבלאות נגזרות בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בהן גם כן. בטבלה הבאה מפורטים הניבים שתומכים בטבלאות נגזרות בגרסה האחרונה של Looker:
אפשר ללחוץ כאן כדי להציג את הטבלה.
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
טבלאות נגזרות מתמידות (PDT)
טבלה נגזרת מתמידה (PDT) היא טבלה נגזרת שנכתבת לסכימת גירוד במסד הנתונים שלכם, ונוצרת מחדש לפי לוח הזמנים שאתם מציינים באמצעות אסטרטגיית התמדה.
טבלת PDT יכולה להיות טבלה נגזרת מבוססת LookML או טבלה נגזרת שמבוססת על SQL.
דרישות ל-PDT
כדי להשתמש בטבלאות נגזרות קבועות (PDT) בפרויקט Looker, צריך:
- ניב של מסד נתונים שתומך ב-PDT. בהמשך הדף מופיע הקטע דיאלקטים נתמכים של מסדי נתונים ל-PDT, שבו מפורטות רשימות של דיאלקטים שתומכים בטבלאות נגזרות מתמידות שמבוססות על SQL ובטבלאות נגזרות מתמידות מקוריות.
סכימה זמנית במסד הנתונים. זו יכולה להיות כל סכימה במסד הנתונים, אבל מומלץ ליצור סכימה חדשה שתשמש רק למטרה הזו. אדמין מסד הנתונים צריך להגדיר את הסכימה עם הרשאת כתיבה למשתמש מסד הנתונים של Looker.
חיבור Looker שמוגדר עם המתג הפעלת PDT במצב מופעל. ההגדרה Enable PDTs (הפעלת PDT) מוגדרת בדרך כלל כשמגדירים את החיבור ל-Looker בפעם הראשונה (הוראות להגדרת הדיאלקט של מסד הנתונים מופיעות בדף התיעוד בנושא דיאלקטים של Looker), אבל אפשר גם להפעיל PDT לחיבור אחרי ההגדרה הראשונית.
ניבים נתמכים של מסדי נתונים ל-PDT
כדי ש-Looker יתמוך ב-PDT בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בהם גם כן.
כדי לתמוך בכל סוג של PDT (מבוסס LookML או מבוסס SQL), הדיאלקט צריך לתמוך בכתיבה למסד הנתונים, בין היתר. יש כמה הגדרות של מסדי נתונים לקריאה בלבד שלא מאפשרות את פעולת ההתמדה (בדרך כלל מסדי נתונים של רפליקות להחלפה חמה של Postgres). במקרים כאלה, אפשר להשתמש בטבלאות נגזרות זמניות במקום זאת.
בטבלה הבאה מפורטים הניבים שתומכים בטבלאות נגזרות מתמידות שמבוססות על SQL בגרסה האחרונה של Looker:
אפשר ללחוץ כאן כדי להציג את הטבלה.
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
כדי לתמוך בטבלאות נגזרות מתמידות מבוססות LookML (שכוללות שאילתות שמבוססות על LookML), הדיאלקט צריך לתמוך גם בפונקציית CREATE TABLE DDL. בגרסה האחרונה של Looker, הניבים הבאים תומכים בטבלאות נגזרות מתמידות מבוססות LookML:
אפשר ללחוץ כאן כדי להציג את הטבלה.
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
בנייה הדרגתית של PDT
טבלת PDT מצטברת היא טבלה נגזרת מתמידה ש-Looker בונה על ידי הוספת נתונים חדשים לטבלה, במקום לבנות אותה מחדש באופן מלא.
אם הניב שלכם תומך ב-PDT מצטבר, וה-PDT משתמש באסטרטגיית התמדה מבוססת-טריגר (datagroup_trigger, sql_trigger_value או interval_trigger), אתם יכולים להגדיר את ה-PDT כ-PDT מצטבר.
מידע נוסף זמין בדף התיעוד בנושא טבלאות PDT מצטברות.
ניבים נתמכים של מסדי נתונים ל-PDT מצטבר
כדי ש-Looker יתמוך בטבלאות PDT מצטברות בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בהן גם כן. בטבלה הבאה מפורטים הניבים שתומכים ב-PDT מצטבר בגרסה האחרונה של Looker:
אפשר ללחוץ כאן כדי להציג את הטבלה.
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
יצירת PDT
כדי להפוך טבלה נגזרת לטבלה נגזרת מתמידה (PDT), מגדירים אסטרטגיית התמדה לטבלה. כדי לבצע אופטימיזציה של הביצועים, כדאי גם להוסיף אסטרטגיית אופטימיזציה.
אסטרטגיות של התמדה
אפשר לנהל את ההתמדה של טבלה נגזרת באמצעות Looker, או באמצעות מסד הנתונים באמצעות תצוגות חומריות, בניבים שתומכים בתצוגות חומריות.
כדי להפוך טבלה נגזרת לטבלה קבועה, מוסיפים את אחד מהפרמטרים הבאים להגדרה של derived_table:
- פרמטרים של התמדה שמנוהלים על ידי Looker:
- פרמטרים של התמדה שמנוהלים על ידי מסד הנתונים:
באמצעות אסטרטגיות של שמירה על נתונים שמבוססות על טריגרים (datagroup_trigger, sql_trigger_value ו-interval_trigger), Looker שומר את ה-PDT במסד הנתונים עד להפעלת ה-PDT לצורך בנייה מחדש. כשה-PDT מופעל, Looker בונה מחדש את ה-PDT כדי להחליף את הגרסה הקודמת. המשמעות היא שעם PDT מבוססי-טריגר, המשתמשים לא צריכים לחכות עד שה-PDT ייווצר כדי לקבל תשובות לשאילתות ב'ניתוח נתונים' מה-PDT.
datagroup_trigger
קבוצות נתונים הן השיטה הכי גמישה ליצירת התמדה. אם הגדרתם קבוצת נתונים עם sql_trigger או interval_trigger, אתם יכולים להשתמש בפרמטר datagroup_trigger כדי להתחיל לבנות מחדש את הטבלאות הנגזרות הקבועות (PDT).
Looker שומר את ה-PDT במסד הנתונים עד שקבוצת הנתונים שלו מופעלת. כשקבוצת הנתונים מופעלת, Looker בונה מחדש את ה-PDT כדי להחליף את הגרסה הקודמת. המשמעות היא שברוב המקרים, המשתמשים לא יצטרכו לחכות עד שה-PDT ייבנה. אם משתמש מבקש נתונים מ-PDT בזמן שהוא נוצר ותוצאות השאילתה לא נמצאות במטמון, Looker יחזיר נתונים מ-PDT קיים עד שייווצר ה-PDT החדש. במאמר שמירת שאילתות במטמון מוסבר על קבוצות נתונים.
מידע נוסף על האופן שבו הכלי ליצירה מחדש יוצר טבלאות PDT זמין בקטע הכלי ליצירה מחדש של Looker.
sql_trigger_value
הפרמטר sql_trigger_value מפעיל יצירה מחדש של טבלה נגזרת מתמידה (PDT) שמבוססת על הצהרת SQL שאתם מספקים. אם התוצאה של הצהרת ה-SQL שונה מהערך הקודם, ה-PDT נוצר מחדש. אחרת, ה-PDT הקיים נשמר במסד הנתונים. המשמעות היא שברוב המקרים, המשתמשים לא יצטרכו לחכות עד שה-PDT ייבנה. אם משתמש מבקש נתונים מ-PDT בזמן שהיא נוצרת, ותוצאות השאילתה לא נמצאות במטמון, Looker יחזיר נתונים מה-PDT הקיימת עד שה-PDT החדשה תיווצר.
מידע נוסף על האופן שבו הכלי ליצירה מחדש יוצר טבלאות PDT זמין בקטע הכלי ליצירה מחדש של Looker.
interval_trigger
הפרמטר interval_trigger מפעיל את היצירה מחדש של טבלה נגזרת מתמידה (PDT) על סמך מרווח זמן שאתם מספקים, כמו "24 hours" או "60 minutes". בדומה לפרמטר sql_trigger, המשמעות היא שבדרך כלל ה-PDT יהיה מוכן מראש כשהמשתמשים יפעילו עליו שאילתה. אם משתמש מבקש נתונים מ-PDT בזמן שהיא נוצרת, ותוצאות השאילתה לא נמצאות במטמון, Looker יחזיר נתונים מה-PDT הקיימת עד שה-PDT החדשה תיווצר.
persist_for
אפשרות נוספת היא להשתמש בפרמטר persist_for כדי להגדיר את משך הזמן שבו הטבלה הנגזרת תאוחסן לפני שהיא תסומן כטבלה שתוקף השימוש בה פג, כך שהיא לא תשמש יותר לשאילתות ותוסר מהמסד.
persist_forטבלת נתונים נגזרים קבועה (PDT) נוצרת כשמשתמש מריץ עליה שאילתה בפעם הראשונה. לאחר מכן, Looker שומר את ה-PDT במסד הנתונים למשך הזמן שצוין בפרמטר persist_for של ה-PDT. אם משתמש מריץ שאילתה ב-PDT בתוך persist_for, Looker משתמש בתוצאות שנשמרו במטמון אם אפשר, או מריץ את השאילתה ב-PDT.
אחרי persist_for זמן, Looker מוחק את ה-PDT מהמסד הנתונים, וה-PDT ייבנה מחדש בפעם הבאה שמשתמש יפעיל עליו שאילתה. כלומר, השאילתה תצטרך לחכות לבנייה מחדש.
מערכת Looker regenerator לא בונה מחדש באופן אוטומטי PDTs שמשתמשים ב-persist_for, אלא אם מדובר בcascade של PDTs עם תלות. כשpersist_for טבלה היא חלק מקסקדה של תלויות עם PDT מבוסס-טריגר (PDT שמשתמש באסטרטגיית שמירה של datagroup_trigger, interval_trigger או sql_trigger_value), הגנרטור יעקוב אחרי הטבלה persist_for ויבנה אותה מחדש כדי לבנות מחדש טבלאות אחרות בקסקדה. מידע נוסף מופיע בקטע איך Looker יוצר טבלאות נגזרות מדורגות בדף הזה.
materialized_view: yes
תצוגות חומריות מאפשרות לכם להשתמש בפונקציונליות של מסד הנתונים כדי לשמור טבלאות נגזרות בפרויקט Looker. אם הדיאלקט של מסד הנתונים תומך בתצוגות מהותיות והחיבור ל-Looker מוגדר עם המתג הפעלת PDT במצב מופעל, אפשר ליצור תצוגה מהותית על ידי ציון materialized_view: yes לטבלה נגזרת. תצוגות חומריות נתמכות גם בטבלאות נגזרות מבוססות LookML (NDT) וגם בטבלאות נגזרות שמבוססות על SQL.
בדומה לטבלה נגזרת מתמידה (PDT), תצוגה חומרית היא תוצאה של שאילתה שמאוחסנת כטבלה בסכימת ה-scratch של מסד הנתונים. ההבדל העיקרי בין PDT לבין תצוגה חומרית הוא באופן הרענון של הטבלאות:
- ב-PDT, אסטרטגיית ההתמדה מוגדרת ב-Looker, וההתמדה מנוהלת על ידי Looker.
- במקרה של תצוגות חומריות, מסד הנתונים אחראי לתחזוקה ולרענון של הנתונים בטבלה.
לכן, כדי להשתמש בפונקציונליות של תצוגה חומרית, צריך ידע מתקדם בניב ובמאפיינים שלו. ברוב המקרים, מסד הנתונים ירענן את התצוגה החומרית בכל פעם שמסד הנתונים יזהה נתונים חדשים בטבלאות שנשלחות לתצוגה החומרית. תצוגות חומריות הן אופטימליות לתרחישים שבהם נדרשים נתונים בזמן אמת.
מידע על תמיכה בדיאלקטים, דרישות ושיקולים חשובים זמין בדף התיעוד של הפרמטר materialized_view.
אסטרטגיות אופטימיזציה
מכיוון שטבלאות נגזרות קבועות (PDT) מאוחסנות במסד הנתונים, כדאי לבצע אופטימיזציה של ה-PDT באמצעות האסטרטגיות הבאות, בהתאם לדיאלקט שנתמך:
לדוגמה, כדי להוסיף התמדה לטבלת הנתונים הנגזרים, אפשר להגדיר שהיא תיבנה מחדש כשמופעל טריגר של קבוצת הנתונים orders_datagroup, ולהוסיף אינדקסים גם ל-customer_id וגם ל-first_order, כך:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
אם לא תוסיפו אינדקס (או מקבילה בשפה שלכם), Looker יציג אזהרה שמומלץ לעשות זאת כדי לשפר את ביצועי השאילתות.
תרחישים לדוגמה לשימוש ב-PDT
טבלאות נגזרות מתמשכות (PDT) הן שימושיות כי הן יכולות לשפר את הביצועים של שאילתה על ידי שמירת התוצאות של השאילתה בטבלה.
כשיטה מומלצת כללית, מפתחים צריכים לנסות ליצור מודלים של נתונים בלי להשתמש ב-PDT עד שאין ברירה אחרת.
במקרים מסוימים, אפשר לבצע אופטימיזציה של הנתונים באמצעים אחרים. לדוגמה, הוספת אינדקס או שינוי סוג הנתונים של עמודה עשויים לפתור בעיה בלי ליצור PDT. חשוב לנתח את תוכניות הביצוע של שאילתות איטיות באמצעות הכלי Explain from SQL Runner.
בנוסף לקיצור זמן השאילתה והפחתת העומס על מסד הנתונים בשאילתות שמופעלות לעיתים קרובות, יש כמה תרחישי שימוש נוספים ב-PDT, כולל:
אפשר גם להשתמש ב-PDT כדי להגדיר מפתח ראשי במקרים שבהם אין דרך סבירה לזהות שורה ייחודית בטבלה כמפתח ראשי.
שימוש ב-PDT לבדיקת אופטימיזציות
אתם יכולים להשתמש ב-PDT כדי לבדוק אפשרויות שונות של יצירת אינדקסים, הפצות ואפשרויות אופטימיזציה אחרות, בלי שתצטרכו לקבל תמיכה רבה ממנהל מסד הנתונים או ממפתחי ה-ETL.
נניח שיש לכם טבלה ואתם רוצים לבדוק אינדקסים שונים. קובץ ה-LookML הראשוני של התצוגה עשוי להיראות כך:
view: customer {
sql_table_name: warehouse.customer ;;
}
כדי לבדוק אסטרטגיות אופטימיזציה, אפשר להשתמש בפרמטר indexes כדי להוסיף אינדקסים ל-LookML באופן הבא:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
מריצים שאילתה בתצוגה פעם אחת כדי ליצור את ה-PDT. לאחר מכן מריצים את שאילתות הבדיקה ומשווים את התוצאות. אם התוצאות טובות, אפשר לבקש מצוות ה-DBA או ה-ETL להוסיף את האינדקסים לטבלה המקורית.
חשוב לזכור לשנות את קוד התצוגה בחזרה כדי להסיר את ה-PDT.
שימוש ב-PDT כדי לבצע איחוד מראש או צבירה של נתונים
יכול להיות שיהיה לכם שימושי לבצע מראש צירוף או צבירה של נתונים כדי להתאים את האופטימיזציה של השאילתות לנפחים גדולים או לכמה סוגים של נתונים.
לדוגמה, נניח שאתם רוצים ליצור שאילתה לגבי לקוחות לפי קבוצה בעלת עניין משותף, על סמך המועד שבו הם ביצעו את ההזמנה הראשונה. יכול להיות שעלות ההפעלה של השאילתה הזו כמה פעמים בכל פעם שצריך את הנתונים בזמן אמת תהיה גבוהה, אבל אפשר לחשב את השאילתה רק פעם אחת ואז להשתמש שוב בתוצאות באמצעות PDT:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
טבלאות נגזרות מדורגות
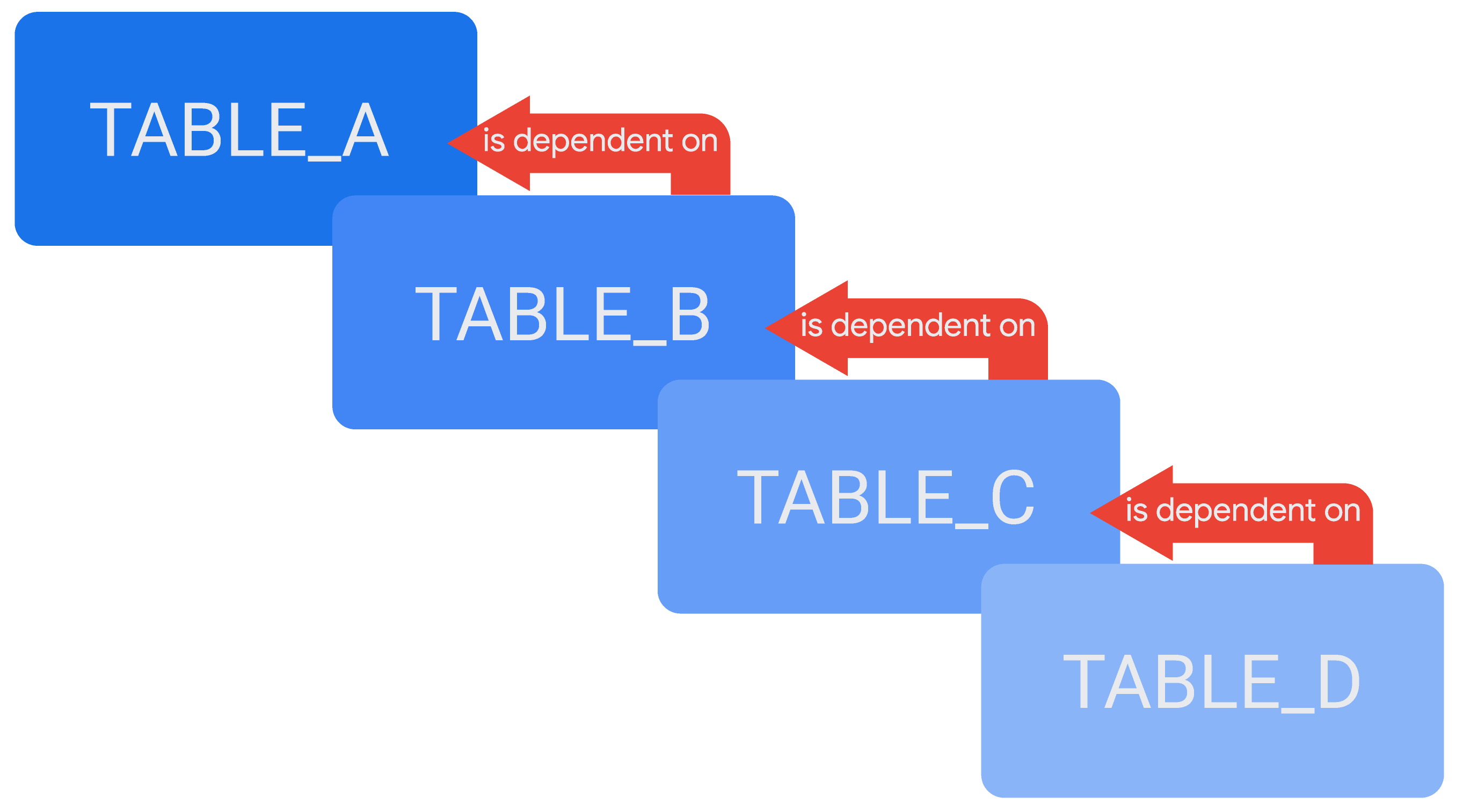
אפשר להפנות לטבלת נתונים נגזרת אחת בהגדרה של טבלת נתונים נגזרת אחרת, וכך ליצור שרשרת של טבלאות נתונים נגזרות מדורגות או של טבלאות נתונים נגזרות מדורגות (PDT), בהתאם למקרה. דוגמה לטבלאות נגזרות מדורגות היא טבלה, TABLE_D, שתלויה בטבלה אחרת, TABLE_C, כש-TABLE_C תלויה ב-TABLE_B, ו-TABLE_B תלויה ב-TABLE_A.
תחביר להפניה לטבלה נגזרת
כדי להפנות לטבלה נגזרת בטבלה נגזרת אחרת, משתמשים בתחביר הזה:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
בפורמט הזה, SQL_TABLE_NAME הוא מחרוזת מילולית. לדוגמה, אפשר להפנות לטבלת הנגזרת clean_events באמצעות התחביר הבא:
`${clean_events.SQL_TABLE_NAME}`
אפשר להשתמש באותו תחביר כדי להפנות לתצוגת LookML. גם כאן, SQL_TABLE_NAME הוא מחרוזת מילולית.
בדוגמה הבאה, נוצר PDT clean_events מהטבלה events במסד הנתונים. ה-PDT clean_events משמיט שורות לא רצויות מטבלת מסד הנתונים events. אחר כך מוצג PDT שני, שהוא סיכום של ה-PDT הראשון.event_summaryclean_events הטבלה event_summary נוצרת מחדש בכל פעם שמוסיפים שורות חדשות לטבלה clean_events.
event_summary PDT ו-clean_events PDT הם PDTs מדורגים, כאשר event_summary תלוי ב-clean_events (כי event_summary מוגדר באמצעות clean_events PDT). אפשר לבצע את הפעולה בדוגמה הזו בצורה יעילה יותר באמצעות PDT אחד, אבל היא שימושית להדגמת הפניות לטבלאות נגזרות.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
למרות שלא תמיד נדרש לעשות זאת, כשמתייחסים לטבלה נגזרת באופן הזה, לעיתים קרובות כדאי ליצור כינוי לטבלה באמצעות הפורמט הזה:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
בדוגמה הקודמת:
${clean_events.SQL_TABLE_NAME} AS clean_events
מומלץ להשתמש בשם בדוי כי מאחורי הקלעים, שמות ה-PDT הם קודים ארוכים במסד הנתונים. במקרים מסוימים (במיוחד עם סעיפי ON), אפשר לשכוח שצריך להשתמש בתחביר ${derived_table_or_view_name.SQL_TABLE_NAME} כדי לאחזר את השם הארוך הזה. כינוי יכול לעזור למנוע טעויות כאלה.
איך Looker יוצר טבלאות נגזרות מדורגות
במקרה של טבלאות נגזרות זמניות מדורגות, אם תוצאות השאילתה של המשתמש לא נמצאות במטמון, Looker יבנה את כל הטבלאות הנגזרות שנדרשות לשאילתה. אם יש לכם TABLE_D שההגדרה שלו מכילה הפניה אל TABLE_C, אז TABLE_D תלוי ב-TABLE_C. המשמעות היא שאם תריצו שאילתה על TABLE_D והשאילתה לא נמצאת במטמון של Looker, Looker יבנה מחדש את TABLE_D. אבל קודם צריך ליצור מחדש את TABLE_C.
נניח שיש תרחיש עם טבלאות נגזרות זמניות מדורגות, שבו TABLE_D תלויה ב-TABLE_C, שבתורה תלויה ב-TABLE_B, שבתורה תלויה ב-TABLE_A. אם אין ל-Looker תוצאות תקפות לשאילתה ב-TABLE_C במטמון, Looker יבנה את כל הטבלאות שהוא צריך לשאילתה. לכן Looker ייצור את TABLE_A, ואז את TABLE_B, ואז את TABLE_C:
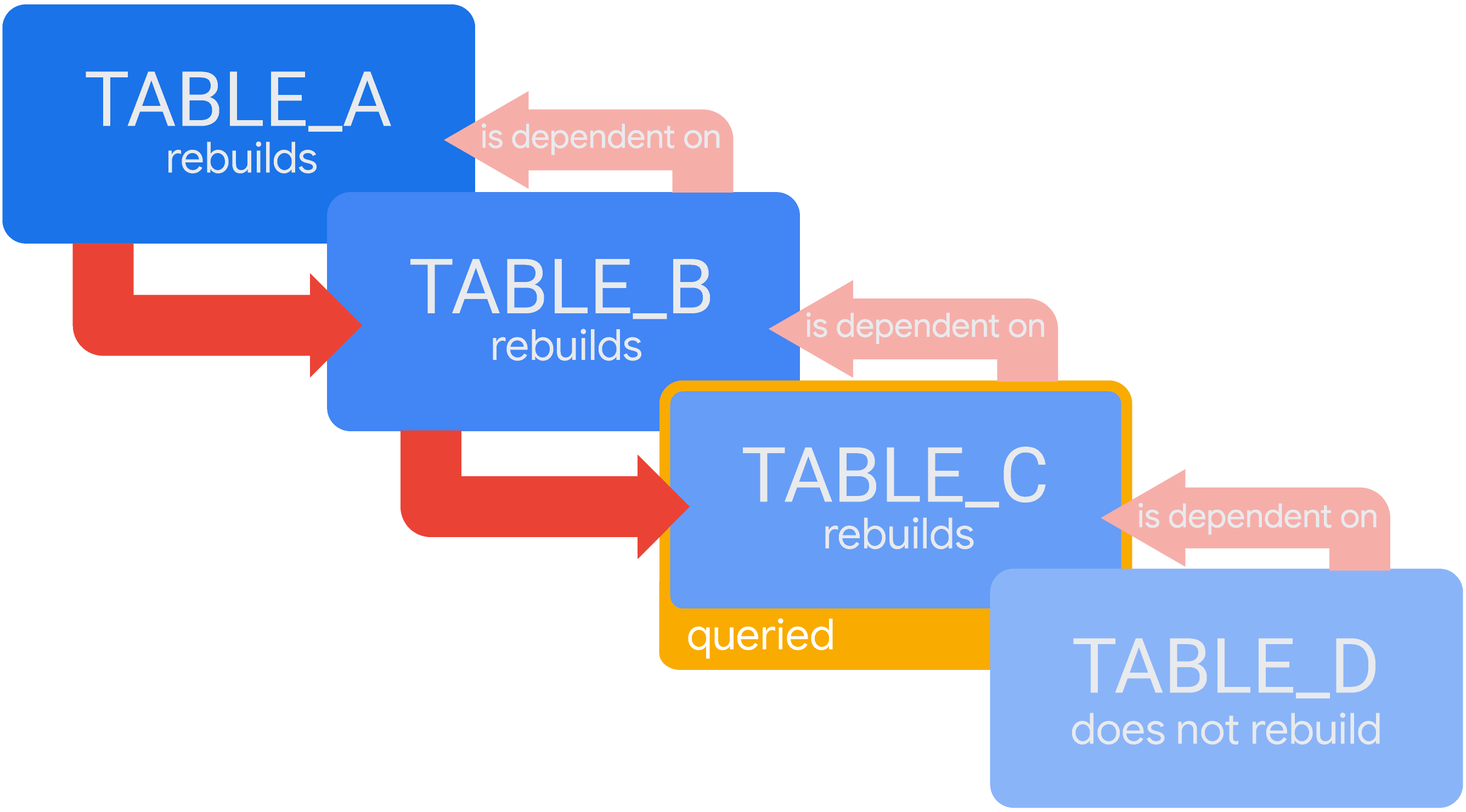
בתרחיש הזה, TABLE_A צריך לסיים את היצירה לפני ש-Looker יכול להתחיל ליצור את TABLE_B, ו-TABLE_B צריך לסיים את היצירה לפני ש-Looker יכול להתחיל ליצור את TABLE_C. בסיום של TABLE_C, Looker יציג את תוצאות השאילתה. (מכיוון שלא צריך את TABLE_D כדי לענות על השאילתה הזו, Looker לא יבנה מחדש את TABLE_D בשלב הזה).
בדף התיעוד של הפרמטר datagroup יש תרחיש לדוגמה של PDTs מדורגים שמשתמשים באותה קבוצת נתונים.
אותה לוגיקה בסיסית חלה על PDT: Looker יבנה כל טבלה שנדרשת כדי לענות על שאילתה, לאורך כל שרשרת התלות. אבל ב-PDT, הרבה פעמים הטבלאות כבר קיימות ואין צורך לבנות אותן מחדש. כשמשתמשים מריצים שאילתות רגילות על טבלאות PDT מדורגות, Looker בונה מחדש את הטבלאות בשרשרת רק אם אין בבסיס הנתונים גרסה תקפה של הטבלאות. אם רוצים לכפות בנייה מחדש של כל ה-PDT בשרשור, אפשר לבנות מחדש את הטבלאות של שאילתה באופן ידני דרך 'ניתוח נתונים'.
נקודה חשובה להבנה היא שבמקרה של קסקדה של PDT, PDT שתלוי ב-PDT אחר בעצם שולח שאילתה ל-PDT שהוא תלוי בו. זה חשוב במיוחד לשיטות בידינג לפי זמן עד ההמרה שמשתמשות בשיטת הבידינג persist_for. בדרך כלל, persist_for PDTs נוצרים כשמשתמש שולח שאילתה לגביהם, הם נשארים במסד הנתונים עד שpersist_for המרווח שלהם מסתיים, ואז הם לא נוצרים מחדש עד שהמשתמש שולח שאילתה לגביהם בפעם הבאה. עם זאת, אם persist_for PDT הוא חלק מקסקדה עם PDTs מבוססי-טריגר (PDTs שמשתמשים באסטרטגיית השמירה datagroup_trigger, interval_trigger או sql_trigger_value), מתבצעת שאילתה לגבי persist_for PDT בכל פעם שה-PDTs שתלויים בו נבנים מחדש. לכן, במקרה הזה, ה-PDT persist_for ייבנה מחדש לפי לוח הזמנים של ה-PDT שתלויים בו. המשמעות היא שpersist_for יכול להיות ש-PDT יושפעו מאסטרטגיית ההתמדה של התלויות שלהם.
בנייה מחדש ידנית של טבלאות לשימוש חוזר בשאילתה
משתמשים יכולים לבחור באפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה) בתפריט של Explore כדי לבטל את הגדרות ההתמדה ולבנות מחדש את כל הטבלאות הנגזרות המתמידות (PDT) וטבלאות הצבירה שנדרשות לשאילתה הנוכחית ב-Explore:
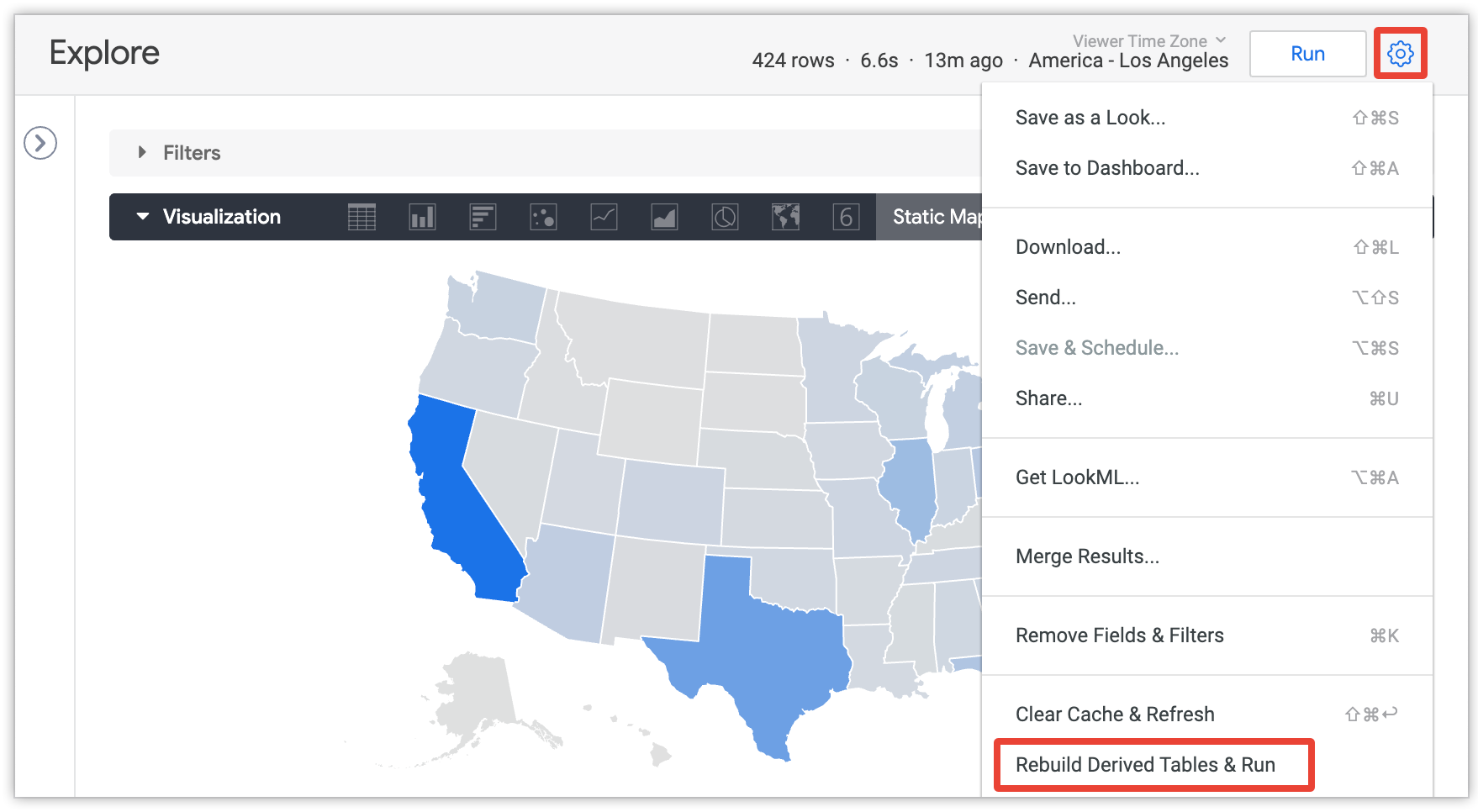
האפשרות הזו גלויה רק למשתמשים עם הרשאת develop, ורק אחרי שהשאילתה בכלי 'ניתוח נתונים' נטענת.
האפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה) בונה מחדש את כל הטבלאות הקבועות (כל ה-PDT וטבלאות הצבירה) שנדרשות כדי לענות על השאילתה, ללא קשר לאסטרטגיית ההתמדה שלהן. החיפוש כולל את כל הטבלאות המצטברות ואת ה-PDT בשאילתה הנוכחית, וגם את כל הטבלאות המצטברות ואת ה-PDT שמקושרים לטבלאות המצטברות ול-PDT בשאילתה הנוכחית.
במקרה של טבלאות PDT מצטברות, האפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה) מפעילה את הבנייה של תוספת חדשה. ב-PDT מצטבר, הגידול כולל את תקופת הזמן שצוינה בפרמטר increment_key, וגם את מספר תקופות הזמן הקודמות שצוין בפרמטר increment_offset, אם יש כזה. במאמר PDT מצטברות מופיעות דוגמאות לתרחישים שמראים איך נוצרות PDT מצטברות, בהתאם להגדרה שלהן.
במקרה של טבלאות PDT מדורגות, המשמעות היא בנייה מחדש של כל הטבלאות הנגזרות בהיררכיה, החל מהטבלה העליונה. זוהי התנהגות זהה לזו שמתרחשת כשמבצעים שאילתה בטבלה בסדרה של טבלאות זמניות נגזרות:
חשוב לשים לב לנקודות הבאות לגבי בנייה מחדש ידנית של טבלאות נגזרות:
- אם המשתמש מפעיל את הפעולה Rebuild Derived Tables & Run, השאילתה תמתין עד שהטבלאות ייבנו מחדש לפני שהתוצאות ייטענו. השאילתות של משתמשים אחרים עדיין ישתמשו בטבלאות הקיימות. אחרי שהטבלאות הקבועות ייבנו מחדש, כל המשתמשים ישתמשו בטבלאות שנבנו מחדש. התהליך הזה נועד למנוע הפרעות לשאילתות של משתמשים אחרים בזמן שהטבלאות נבנות מחדש, אבל יכול להיות שהמשתמשים האלה עדיין יושפעו מהעומס הנוסף על מסד הנתונים. אם אתם נמצאים במצב שבו הפעלה של בנייה מחדש בשעות הפעילות עלולה להעמיס עומס בלתי מתקבל על הדעת על מסד הנתונים שלכם, יכול להיות שתצטרכו להודיע למשתמשים שלכם שאסור להם לבנות מחדש טבלאות PDT או טבלאות צבירה מסוימות בשעות האלה.
אם משתמש נמצא במצב פיתוח והניתוח מבוסס על טבלת פיתוח, הפעולה בנייה מחדש של טבלאות נגזרות והרצה תבנה מחדש את טבלת הפיתוח ולא את טבלת הייצור של הניתוח. אבל אם התכונה 'ניתוח ב'מצב פיתוח' משתמשת בגרסת הייצור של טבלה נגזרת, טבלת הייצור תיבנה מחדש. מידע על טבלאות פיתוח וטבלאות ייצור זמין במאמר טבלאות קבועות במצב פיתוח.
במקרים שבהם מופעלות טבלאות נגזרות במופעים שמתארחים ב-Looker, אם בנייה מחדש של הטבלה נמשכת יותר משעה, הטבלה לא תיבנה מחדש בהצלחה והסשן בדפדפן יסתיים בגלל חוסר פעילות. מידע נוסף על פסק זמן שעשוי להשפיע על תהליכים ב-Looker מופיע בקטע פסק זמן של שאילתות והוספה לתור בדף התיעוד הגדרות אדמין – שאילתות.
טבלאות שנשמרות במצב פיתוח
ל-Looker יש התנהגויות מיוחדות לניהול טבלאות שנשמרות במצב פיתוח.
אם שולחים שאילתה לטבלה שנשמרה במצב פיתוח בלי לבצע שינויים בהגדרה שלה, Looker ישלח שאילתה לגרסת הייצור של הטבלה הזו. אם כן מבצעים שינוי בהגדרת הטבלה שמשפיע על הנתונים בטבלה או על האופן שבו מתבצעת שאילתה בטבלה, תיווצר גרסת פיתוח חדשה של הטבלה בפעם הבאה שתבצעו שאילתה בטבלה במצב פיתוח. טבלת פיתוח כזו מאפשרת לכם לבדוק שינויים בלי להפריע למשתמשים.
מה גורם ל-Looker ליצור טבלת פיתוח
כשזה אפשרי, Looker משתמש בטבלת הייצור הקיימת כדי לענות על שאילתות, בין אם אתם במצב פיתוח ובין אם לא. אבל יש מקרים מסוימים שבהם Looker לא יכול להשתמש בטבלת הייצור לשאילתות במצב פיתוח:
- אם בטבלה הקבועה יש פרמטר שמצמצם את מערך הנתונים שלה כדי לעבוד מהר יותר במצב פיתוח
- אם ביצעתם שינויים בהגדרה של הטבלה הקבועה שמשפיעים על הנתונים בטבלה
Looker ייצור טבלת פיתוח אם אתם במצב פיתוח ואתם שולחים שאילתה לטבלה נגזרת שמבוססת על SQL ומוגדרת באמצעות תנאי WHERE עם הצהרות if prod ו-if dev.
בטבלאות קבועות שלא כוללות פרמטר לצמצום מערך הנתונים במצב פיתוח, מערכת Looker משתמשת בגרסת הייצור של הטבלה כדי לענות על שאילתות במצב פיתוח, אלא אם משנים את ההגדרה של הטבלה ואז שולחים שאילתה לטבלה במצב פיתוח. ההערה הזו רלוונטית לכל שינוי בטבלה שמשפיע על הנתונים בטבלה או על האופן שבו מתבצעת שאילתה בטבלה.
אלה כמה דוגמאות לסוגי שינויים שיגרמו ל-Looker ליצור גרסת פיתוח של טבלה קבועה (Looker ייצור את הטבלה רק אם תבצעו שאילתה על הטבלה אחרי ביצוע השינויים האלה):
- שינוי השאילתה שעליה מבוססת הטבלה הקבועה, למשל שינוי הפרמטר
explore_source,sql,query,sql_createאוcreate_processבטבלה הקבועה עצמה, או בכל טבלה נדרשת (במקרה של טבלאות נגזרות מדורגות) - שינוי אסטרטגיית השמירה של הטבלה, למשל שינוי הפרמטרים
datagroup_trigger,sql_trigger_value,interval_triggerאוpersist_forשל הטבלה - שינוי השם של
viewבטבלה נגזרת - שינוי
increment_keyאוincrement_offsetשל PDT מצטבר - שינוי
connectionשמשמש את המודל המשויך
אם השינויים לא משנים את הנתונים בטבלה או לא משפיעים על האופן שבו Looker שולח שאילתות לטבלה, Looker לא ייצור טבלת פיתוח. הפרמטר publish_as_db_view הוא דוגמה טובה: במצב פיתוח, אם משנים רק את ההגדרה publish_as_db_view של טבלה נגזרת, Looker לא צריך לבנות מחדש את הטבלה הנגזרת, ולכן לא ייצור טבלת פיתוח.
כמה זמן Looker שומר טבלאות פיתוח
לא משנה מהי אסטרטגיית השמירה בפועל של הטבלה, Looker מתייחס לטבלאות ששמירה שלהן מוגדרת כ-persistence strategy של persist_for: "24 hours". מערכת Looker עושה את זה כדי לוודא שטבלאות פיתוח לא נשמרות יותר מיום אחד, כי מפתח Looker עשוי לבצע שאילתות על הרבה איטרציות של טבלה במהלך הפיתוח, ובכל פעם נבנית טבלת פיתוח חדשה. כדי למנוע עומס בבסיס הנתונים בגלל טבלאות הפיתוח, Looker משתמש באסטרטגיה persist_for: "24 hours" כדי לוודא שהטבלאות מנוקות מבסיס הנתונים בתדירות גבוהה.
אחרת, Looker בונה טבלאות נגזרות מתמידות (PDT) וטבלאות מצטברות במצב פיתוח באותו אופן שבו הוא בונה טבלאות מתמידות במצב ייצור.
אם טבלת פיתוח נשמרת במסד הנתונים כשפורסים שינויים ב-PDT או בטבלה מסכמת, Looker יכול לעיתים קרובות להשתמש בטבלת הפיתוח כטבלת הייצור, כך שהמשתמשים לא צריכים לחכות עד שהטבלה תיבנה כשהם שולחים שאילתה לטבלה.
שימו לב: כשפורסים את השינויים, יכול להיות שעדיין צריך לבנות מחדש את הטבלה כדי שאפשר יהיה לשלוח אליה שאילתות בסביבת הייצור, בהתאם למצב:
- אם עברו יותר מ-24 שעות מאז ששלחתם שאילתה לטבלה במצב פיתוח, גרסת הפיתוח של הטבלה מתויגת כגרסה שתוקפה פג ולא נעשה בה שימוש בשאילתות. אפשר לבדוק אם יש PDT שלא נוצרו באמצעות Looker IDE או באמצעות הכרטיסייה פיתוח בדף טבלאות נגזרות קבועות. אם יש לכם PDT שלא נבנה, אתם יכולים לשלוח לו שאילתה במצב פיתוח ממש לפני שאתם מבצעים את השינויים, כדי שהטבלה של הפיתוח תהיה זמינה לשימוש בסביבת הייצור.
- אם בטבלה קבועה מוגדר הפרמטר
dev_filters(במקרה של טבלאות נגזרות מקוריות) או פסקה מותנית conditionalWHEREשמשתמשת בהצהרותif prodו-if dev(במקרה של טבלאות נגזרות מבוססות-SQL), אי אפשר להשתמש בטבלת הפיתוח כגרסת הייצור, כי גרסת הפיתוח היא מערך נתונים מקוצר. במקרה כזה, אחרי שמסיימים לפתח את הטבלה ולפני שמפעילים את השינויים, אפשר להוסיף הערה לפרמטרdev_filtersאו לתנאיWHEREואז להריץ שאילתה על הטבלה במצב פיתוח. לאחר מכן, Looker ייצור גרסה מלאה של הטבלה שאפשר להשתמש בה בסביבת הייצור כשפורסים את השינויים.
אחרת, אם אתם פורסים את השינויים כשאין טבלת פיתוח תקינה שאפשר להשתמש בה כטבלת הייצור, Looker יבנה מחדש את הטבלה בפעם הבאה שתתבצע שאילתה בטבלה במצב ייצור (במקרה של טבלאות שנשמרו ומשתמשות באסטרטגיה persist_for), או בפעם הבאה שהכלי ליצירה מחדש יפעל (במקרה של טבלאות שנשמרו ומשתמשות באסטרטגיה datagroup_trigger, interval_trigger או sql_trigger_value).
בדיקה של PDTs שלא נבנו במצב פיתוח
אם טבלת פיתוח נשמרת במסד הנתונים כשפורסים שינויים בטבלה נגזרת מתמידה (PDT) או בטבלה מסכמת, Looker יכול לעיתים קרובות להשתמש בטבלת הפיתוח כטבלת הייצור, כך שהמשתמשים לא צריכים לחכות עד שהטבלה תיווצר כשהם שולחים שאילתה לטבלה. פרטים נוספים זמינים בקטעים כמה זמן Looker שומר על טבלאות פיתוח ומה גורם ל-Looker ליצור טבלת פיתוח בדף הזה.
לכן, מומלץ לבנות את כל הטבלאות של ה-PDT כשמבצעים פריסה בסביבת ייצור, כדי שאפשר יהיה להשתמש בטבלאות באופן מיידי כגרסאות הייצור.
אפשר לבדוק אם יש בפרויקט PDT שלא נבנו בחלונית Project Health (תקינות הפרויקט). לוחצים על הסמל Project Health (תקינות הפרויקט) ב-Looker IDE כדי לפתוח את החלונית Project Health. לאחר מכן לוחצים על הלחצן אימות סטטוס PDT.
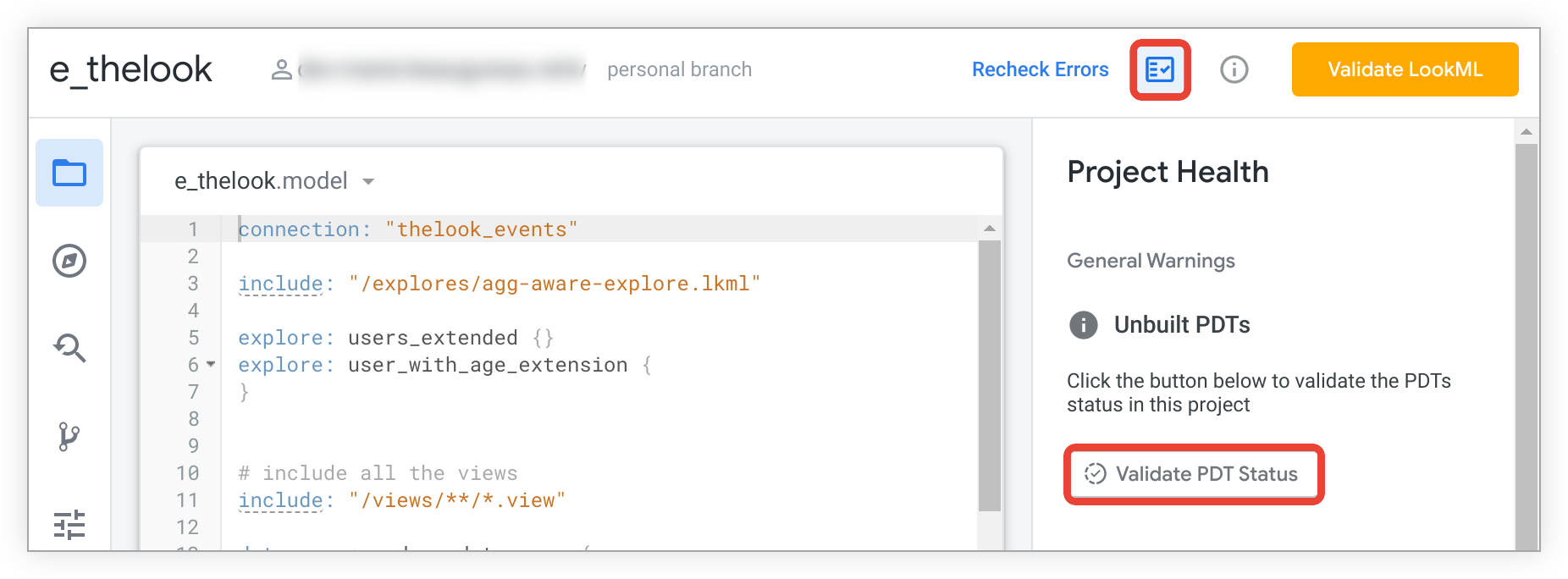
אם יש טבלאות PDT שלא נבנו, הן יופיעו בחלונית Project Health:
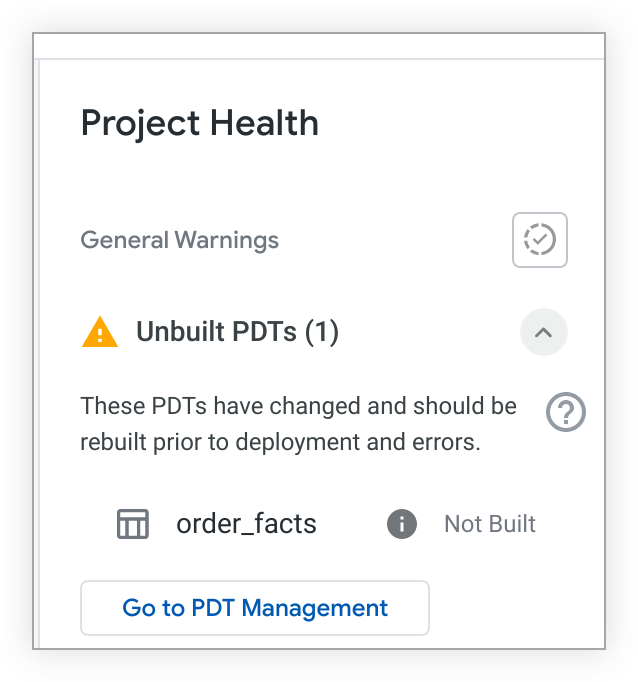
אם יש לכם הרשאה see_pdts, אתם יכולים ללחוץ על הלחצן מעבר לניהול PDT. מערכת Looker תפתח את הכרטיסייה Development בדף Persistent Derived Tables ותסנן את התוצאות לפי פרויקט LookML הספציפי שלכם. משם אפשר לראות אילו PDT פותחו ואילו לא, וגם לגשת למידע נוסף לפתרון בעיות. מידע נוסף זמין בדף התיעוד בנושא הגדרות אדמין – טבלאות נגזרות קבועות.
אחרי שמזהים PDT שלא נבנה בפרויקט, אפשר לבנות גרסת פיתוח שלו. לשם כך, פותחים ניתוח ששולח שאילתה לטבלה, ואז משתמשים באפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה) בתפריט הניתוח. אפשר לעיין בקטע בנייה מחדש ידנית של טבלאות קבועות לשאילתה בדף הזה.
שיתוף וניקוי של טבלאות
בכל מופע נתון של Looker, מערכת Looker תשתף טבלאות שנשמרו בין משתמשים אם לטבלאות יש את אותה הגדרה ואת אותה הגדרת שיטת שמירה. בנוסף, אם ההגדרה של טבלה מסוימת מפסיקה להתקיים, Looker מסמן את הטבלה כלא פעילה.
יש לזה כמה יתרונות:
- אם לא ביצעתם שינויים בטבלה במצב פיתוח, השאילתות ישתמשו בטבלאות הייצור הקיימות. זה המצב אלא אם הטבלה היא טבלה נגזרת שמבוססת על SQL ומוגדרת באמצעות פסקה conditional
WHEREעם הצהרותif prodו-if dev. אם הטבלה מוגדרת עם פסקה מותניתWHERE, Looker ייצור טבלת פיתוח אם תבצעו שאילתה בטבלה במצב פיתוח. (בטבלאות נגזרות מקוריות עם הפרמטרdev_filters, ל-Looker יש את הלוגיקה להשתמש בטבלת הייצור כדי לענות על שאילתות במצב פיתוח, אלא אם משנים את ההגדרה של הטבלה ואז שולחים שאילתה לטבלה במצב פיתוח). - אם שני מפתחים מבצעים את אותו שינוי בטבלה במקביל במצב פיתוח, הם ישתפו את אותה טבלת פיתוח.
- אחרי שמעבירים את השינויים ממצב פיתוח למצב ייצור, הגדרת הייצור הישנה כבר לא קיימת, ולכן טבלת הייצור הישנה מסומנת כטבלה שתוקפה פג והיא תוסר.
- אם מחליטים לבטל את השינויים במצב פיתוח, הגדרת הטבלה הזו כבר לא קיימת, ולכן טבלאות הפיתוח המיותרות מסומנות כלא רלוונטיות ויוסרו.
עבודה מהירה יותר במצב פיתוח
יש מצבים שבהם לוקח הרבה זמן ליצור את טבלת הנתונים הנגזרים הקבועה (PDT) שאתם יוצרים, וזה יכול להיות בזבוז זמן אם אתם בודקים הרבה שינויים במצב פיתוח. במקרים כאלה, אפשר להנחות את Looker ליצור גרסאות קטנות יותר של טבלת נתונים נגזרת כשנמצאים במצב פיתוח.
בטבלאות נגזרות מבוססות LookML (NDT), אפשר להשתמש בתת-פרמטר dev_filters של explore_source כדי לציין מסננים שמוחלים רק על גרסאות פיתוח של הטבלה הנגזרת:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
בדוגמה הזו יש פרמטר dev_filters שמסנן את הנתונים ל-90 הימים האחרונים, ופרמטר filters שמסנן את הנתונים לשנתיים האחרונות ולנמל התעופה בעמק יוקה.
הפרמטר dev_filters פועל בשילוב עם הפרמטר filters, כך שכל המסננים מוחלים על גרסת הפיתוח של הטבלה. אם גם dev_filters וגם filters מציינים מסננים לאותה עמודה, dev_filters מקבל עדיפות בגרסת הפיתוח של הטבלה. בדוגמה הזו, גרסת הפיתוח של הטבלה תסנן את הנתונים ל-90 הימים האחרונים עבור נמל התעופה של עמק יוקה.
בטבלאות נגזרות שמבוססות על SQL, Looker תומך בסעיף WHERE מותנה עם אפשרויות שונות לגרסאות הייצור (if prod) והפיתוח (if dev) של הטבלה:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
בדוגמה הזו, השאילתה תכלול את כל הנתונים משנת 2000 ואילך כשהיא במצב ייצור, אבל רק את הנתונים משנת 2020 ואילך כשהיא במצב פיתוח. שימוש אסטרטגי בתכונה הזו כדי להגביל את קבוצת התוצאות ולהגדיל את מהירות השאילתה יכול להקל מאוד על אימות השינויים במצב פיתוח.
איך Looker בונה PDT
אחרי שמגדירים טבלת נתונים נגזרת מתמשכת (PDT) ומריצים אותה בפעם הראשונה או מפעילים אותה באמצעות הגנרטור כדי לבנות אותה מחדש בהתאם לאסטרטגיית ההתמדה שלה, Looker יבצע את השלבים הבאים:
- משתמשים ב-SQL של הטבלה הנגזרת כדי ליצור פקודה CREATE TABLE AS SELECT (או CTAS) ומריצים אותה. לדוגמה, כדי לבנות מחדש PDT בשם
customer_orders_facts:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - מריצים את ההצהרות כדי ליצור את האינדקסים כשיוצרים את הטבלה
- משנים את שם הטבלה מ-LC$.. (Looker Create) ל-LR$.. (Looker Read), כדי לציין שהטבלה מוכנה לשימוש
- מחיקת גרסה ישנה יותר של הטבלה שכבר לא אמורה להיות בשימוש
יש לכך כמה השלכות חשובות:
- ה-SQL שיוצר את הטבלה הנגזרת חייב להיות תקין בתוך הצהרת CTAS.
- הכינויים של העמודות בקבוצת התוצאות של הצהרת SELECT חייבים להיות שמות עמודות תקינים.
- השמות שמשמשים לציון הפצה, מפתחות מיון ואינדקסים חייבים להיות שמות העמודות שמופיעים בהגדרת ה-SQL של הטבלה הנגזרת, ולא שמות השדות שמוגדרים ב-LookML.
הכלי ליצירה מחדש ב-Looker
הכלי Looker regenerator בודק את הסטטוס ומתחיל לבנות מחדש טבלאות שנשמרו באמצעות טריגר. טבלה הנגזרת מטריגר מתמיד היא טבלה נגזרת מתמידה (PDT) או טבלה מסכמת שמשתמשת בטריגר כאסטרטגיית התמדה:
- בטבלאות שמשתמשות ב-
sql_trigger_value, הטריגר הוא שאילתה שמוגדרת בפרמטרsql_trigger_valueשל הטבלה. הכלי ליצירה מחדש ב-Looker מפעיל בנייה מחדש של הטבלה כשהתוצאה של הבדיקה האחרונה של שאילתת הטריגר שונה מהתוצאה של הבדיקה הקודמת של שאילתת הטריגר. לדוגמה, אם הטבלה הנגזרת נשמרת באמצעות שאילתת ה-SQLSELECT CURDATE(), הכלי ליצירה מחדש של Looker יבנה מחדש את הטבלה בפעם הבאה שהכלי יבדוק את הטריגר אחרי שהתאריך ישתנה. - בטבלאות שמשתמשות ב-
interval_trigger, הטריגר הוא משך זמן שמוגדר בפרמטרinterval_triggerשל הטבלה. הכלי ליצירה מחדש ב-Looker מפעיל בנייה מחדש של הטבלה כשהזמן שצוין חולף. - בטבלאות שמשתמשות ב-
datagroup_trigger, הטריגר יכול להיות שאילתה שצוינה בפרמטרsql_triggerשל קבוצת הנתונים המשויכת, או משך זמן שצוין בפרמטרinterval_triggerשל קבוצת הנתונים.
הכלי ליצירה מחדש ב-Looker גם יוזם בנייה מחדש של טבלאות שנשמרו ומשתמשות בפרמטר persist_for, אבל רק אם טבלת persist_for היא קסקדה של יחסי תלות של טבלה הנגזרת מטריגר מתמיד. במקרה כזה, הכלי Looker regenerator יתחיל לבנות מחדש את הטבלה persist_for, כי צריך את הטבלה הזו כדי לבנות מחדש את שאר הטבלאות בשרשרת. אחרת, הגנרטור לא עוקב אחרי טבלאות קבועות שמשתמשות באסטרטגיית persist_for.
מחזור החידוש של Looker מתחיל במרווחי זמן קבועים שמוגדרים על ידי אדמין Looker בהגדרה Maintenance Schedule בחיבור למסד הנתונים (ברירת המחדל היא מרווח של חמש דקות). עם זאת, מחולל ה-Looker לא מתחיל מחזור חדש עד שהוא משלים את כל הבדיקות ואת הבנייה מחדש של ה-PDT מהמחזור האחרון. המשמעות היא שאם יש לכם בניית PDT שפועלת לאורך זמן, יכול להיות שמחזור הרגנרטור של Looker לא יפעל בתדירות שהוגדרה בהגדרה Maintenance Schedule (לוח זמנים לתחזוקה). יש גורמים נוספים שיכולים להשפיע על הזמן שנדרש לבנייה מחדש של הטבלאות, כמו שמתואר בקטע שיקולים חשובים להטמעה של טבלאות קבועות בדף הזה.
במקרים שבהם בניית PDT נכשלת, יכול להיות שהמחולל מחדש ינסה לבנות מחדש את הטבלה במחזור הבא של המחולל מחדש:
- אם ההגדרה Retry Failed PDT Builds (ניסיון חוזר לבניית טבלאות PDT שנכשלו) מופעלת בחיבור למסד הנתונים, מחולל ה-LookML ינסה לבנות מחדש את הטבלה במהלך המחזור הבא של המחולל, גם אם לא מתקיים התנאי להפעלת הטבלה.
- אם ההגדרה Retry Failed PDT Builds (ניסיון חוזר לבניית טבלאות PDT שנכשלו) מושבתת, כלי ה-regenerator של Looker לא ינסה לבנות מחדש את הטבלה עד שתנאי ההפעלה של ה-PDT יתקיימו.
אם משתמש מבקש נתונים מהטבלה המתמשכת בזמן שהיא נוצרת ותוצאות השאילתה לא נמצאות במטמון, Looker בודק אם הטבלה הקיימת עדיין תקפה. (יכול להיות שהטבלה הקודמת לא תהיה תקפה אם היא לא תהיה תואמת לגרסה החדשה של הטבלה. זה יכול לקרות אם לטבלה החדשה יש הגדרה שונה, אם היא משתמשת בחיבור שונה למסד הנתונים או אם היא נוצרה באמצעות גרסה אחרת של Looker). אם הטבלה הקיימת עדיין תקפה, Looker יחזיר נתונים מהטבלה הקיימת עד שהטבלה החדשה תיבנה. אחרת, אם הטבלה הקיימת לא תקינה, Looker יספק תוצאות של שאילתות אחרי שהטבלה החדשה תיבנה מחדש.
שיקולים חשובים בהטמעה של טבלאות קבועות
בהתחשב בשימושיות של טבלאות קבועות (PDT וטבלאות מצטברות), יכול להיות שתצברו הרבה טבלאות כאלה במופע Looker שלכם. יכול להיות שייווצר תרחיש שבו הכלי ליצירה מחדש של Looker יצטרך ליצור הרבה טבלאות בו-זמנית. במיוחד כשמדובר בטבלאות מדורגות או בטבלאות שפועלות לאורך זמן, יכול להיות שתיווצר סיטואציה שבה יש עיכוב ארוך לפני שהטבלאות נבנות מחדש, או שבה המשתמשים חווים עיכוב בקבלת תוצאות השאילתה מטבלה בזמן שמסד הנתונים פועל במאמץ רב כדי ליצור את הטבלה.
הכלי ליצירה מחדש ב-Looker בודק את הטריגרים של PDT כדי לראות אם צריך לבנות מחדש טבלאות שנוצרו על ידי טריגרים. מחזור החידוש מוגדר במרווח קבוע שמוגדר על ידי האדמין של Looker בהגדרה Maintenance Schedule (תזמון תחזוקה) בחיבור למסד הנתונים (ברירת המחדל היא מרווח של חמש דקות).
יש כמה גורמים שיכולים להשפיע על הזמן שנדרש לבנייה מחדש של הטבלאות:
- יכול להיות שהאדמין שלכם ב-Looker שינה את המרווח בין הבדיקות של טריגר הגנרטור באמצעות ההגדרה Maintenance Schedule בחיבור למסד הנתונים.
- המחולל מחדש של Looker לא מתחיל מחזור חדש עד שהוא משלים את כל הבדיקות והבנייה מחדש של PDT מהמחזור האחרון. לכן, אם יש לכם בניית PDT שפועלת לאורך זמן, יכול להיות שמחזור יצירת ה-PDT מחדש ב-Looker לא יהיה בתדירות שמוגדרת בלוח הזמנים לתחזוקה.
- כברירת מחדל, הגנרטור יכול להתחיל לבנות מחדש PDT אחד או טבלה מסכמת אחת בכל פעם דרך חיבור. אדמין ב-Looker יכול לשנות את מספר הבנייה מחדש המקסימלי המותר של מחולל ה-PDT באמצעות השדה מספר החיבורים המקסימלי של מחולל ה-PDT בהגדרות של חיבור.
- כל טבלאות ה-PDT והטבלאות המצטברות שהופעלו על ידי אותו
datagroupייבנו מחדש במהלך אותו תהליך יצירה מחדש. אם יש לכם הרבה טבלאות שמשתמשות בקבוצת הנתונים, ישירות או כתוצאה מתלות מדורגת, העומס על המערכת יכול להיות כבד.
בנוסף לשיקולים הקודמים, יש גם מצבים שבהם כדאי להימנע מהוספת התמדה לטבלה נגזרת:
- מתי טבלאות נגזרות מורחבות – כל הרחבה של PDT תיצור עותק חדש של הטבלה במסד הנתונים.
- כשמשתמשים בטבלאות נגזרות במסננים מבוססי-תבנית או בפרמטרים של Liquid — אין תמיכה בשימור של טבלאות נגזרות שמשתמשות במסננים מבוססי-תבנית או בפרמטרים של Liquid.
- כשיוצרים טבלאות נגזרות מקוריות מניתוחים שמשתמשים במאפייני משתמש עם
access_filtersאו עםsql_always_where, המערכת תיצור עותקים של הטבלה במסד הנתונים לכל ערך אפשרי של מאפיין משתמש שצוין. - כשהנתונים הבסיסיים משתנים לעיתים קרובות, ודיאלקט מסד הנתונים לא תומך בPDT מצטבר.
- כשהעלות והזמן שנדרשים ליצירת PDT גבוהים מדי.
בהתאם למספר ולמורכבות של הטבלאות הקבועות בחיבור Looker, יכול להיות שהתור יכיל הרבה טבלאות קבועות שצריך לבדוק ולבנות מחדש בכל מחזור. לכן חשוב לזכור את הגורמים האלה כשמטמיעים טבלאות נגזרות במופע Looker.
ניהול כללי PDT בקנה מידה נרחב באמצעות API
ככל שיוצרים יותר טבלאות נגזרות קבועות (PDT) במופע, המעקב והניהול שלהן הופכים למורכבים יותר, כי הן מתרעננות בלוחות זמנים שונים. כדאי להשתמש בשילוב של Looker עם Apache Airflow כדי לנהל את לוחות הזמנים של PDT לצד תהליכי ETL ו-ELT אחרים.
מעקב ופתרון בעיות ב-PDT
אם אתם משתמשים בטבלאות נגזרות מתמשכות (PDT), ובמיוחד בטבלאות PDT מדורגות, כדאי לכם לראות את הסטטוס של הטבלאות האלה. אפשר להשתמש בדף הניהול של טבלאות נגזרות קבועות ב-Looker כדי לראות את הסטטוס של הטבלאות הנגזרות הקבועות. אפשר גם לעיין בתרשים לפתרון בעיות ב-PDT כדי לקבל הוראות מפורטות לניפוי באגים.
כשמנסים לפתור בעיות ב-PDT:
- כשבודקים את יומן האירועים של PDT, חשוב לשים לב להבדל בין טבלאות פיתוח לבין טבלאות ייצור.
- מוודאים שההגדרה Temp Database בחיבור Looker תואמת לסכימה או למסד הנתונים בפועל. אם ההגדרה Temp Database בחיבור לא תואמת לסכימת ה-scratch במסד הנתונים, צריך לעדכן את ההגדרה Temp Database כדי ש-Looker יוכל לאחסן טבלאות נגזרות קבועות במסד הנתונים.
- בודקים אם יש בעיות בכל כללי התמחור או רק באחד מהם. אם יש בעיה באחד מהם, סביר להניח שהבעיה נגרמת בגלל שגיאת LookML או SQL.
- בודקים אם הבעיות ב-PDT תואמות למועדים שבהם הוא אמור להיבנות מחדש.
- מוודאים שכל השאילתות
sql_trigger_valueמוערכות בהצלחה ושהן מחזירות רק שורה ועמודה אחת. ב-PDT מבוססי-SQL, אפשר לעשות זאת על ידי הרצתם ב-SQL Runner. (החלתLIMITמגנה מפני שאילתות לא מבוקרות). מידע נוסף על שימוש ב-SQL Runner כדי לנפות באגים בטבלאות נגזרות זמין בפוסט לקהילה בנושא שימוש ב-SQL Runner כדי לבדוק טבלאות נגזרות . - ל-PDT שמבוססים על SQL, משתמשים ב-SQL Runner כדי לוודא שקוד ה-SQL של ה-PDT פועל ללא שגיאות. (חשוב להשתמש ב-
LIMITב-SQL Runner כדי שזמני השאילתות יהיו סבירים). - בטבלאות נגזרות שמבוססות על SQL, מומלץ להימנע משימוש בביטויי טבלה נפוצים (CTEs). שימוש ב-CTEs עם DTs יוצר הצהרות
WITHמקוננות שעלולות לגרום ל-PDTs להיכשל ללא אזהרה. במקום זאת, משתמשים ב-SQL עבור ה-CTE כדי ליצור DT משני, ומפנים ל-DT הזה מה-DT הראשון באמצעות התחביר${derived_table_or_view_name.SQL_TABLE_NAME}. - בודקים שכל הטבלאות שה-PDT הבעייתי תלוי בהן – בין אם אלה טבלאות רגילות או PDT בעצמן – קיימות ואפשר לשלוח להן שאילתות.
- מוודאים שלטבלאות ש-PDT הבעייתי תלוי בהן אין נעילות משותפות או בלעדיות. כדי ש-Looker יוכל ליצור PDT, הוא צריך לקבל נעילה בלעדית של הטבלה שצריך לעדכן. הנעילה הזו תתנגש עם נעילות משותפות או בלעדיות אחרות שמוגדרות בטבלה. המערכת לא תוכל לעדכן את ה-PDT עד שכל הנעילות האחרות יוסרו. הדבר נכון גם לגבי נעילות בלעדיות בטבלה שממנה Looker יוצר PDT. אם יש נעילה בלעדית בטבלה, Looker לא יוכל לקבל נעילה משותפת כדי להריץ שאילתות עד שהנעילה הבלעדית תוסר.
- משתמשים בלחצן הצגת תהליכים ב-SQL Runner. אם יש מספר גדול של תהליכים פעילים, יכול להיות שזמני השאילתות יהיו ארוכים יותר.
- מעקב אחרי תגובות בשאילתה. אפשר לעיין בקטע שאילתות של הערות ל-PDT בדף הזה.
כשמשתמשים בפונקציות תאריך ספציפיות למסד נתונים (כמו
current_date()) בשאילתת ה-SQL של טבלה נגזרת, יש סיכון לאי התאמה בין אזור הזמן של סשן Looker של המשתמש לבין מסד הנתונים הבסיסי. מכיוון שפונקציות של מסד נתונים מופעלות ישירות במסד הנתונים ולא עוברות המרה של אזור הזמן של השאילתה ב-Looker, הפער הזה יכול לגרום לתוצאות לא צפויות של מסנן תאריכים (לדוגמה, מסנן תאריכים של 'אתמול' יכול להחזיר תוצאות של לפני יומיים בסמוך לחצות).כדי לפתור את הבעיה, צריך לוודא שיש התאמה נכונה בין אזור הזמן במסד הנתונים לבין אזור הזמן במופע Looker. יכול להיות שתצטרכו לתאם עם צוות הנדסת הנתונים.
שאילתות לגבי הערות ב-PDT
אדמינים של מסדי נתונים יכולים להבדיל בין שאילתות רגילות לבין שאילתות שיוצרות טבלאות נגזרות קבועות (PDT). Looker מוסיף הערות להצהרת CREATE TABLE ... AS SELECT ... שכוללת את מודל LookML ואת התצוגה של PDT, בנוסף למזהה ייחודי (slug) של מופע Looker. אם ה-PDT נוצר בשם משתמש במצב פיתוח, בתגובות יצוין מזהה המשתמש. התגובות שנוצרות על ידי PDT פועלות לפי התבנית הבאה:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
הערה לגבי יצירת PDT תופיע בכרטיסיית ה-SQL של ניתוח ב-Explore אם Looker נאלץ ליצור PDT עבור השאילתה של הניתוח ב-Explore. ההערה תופיע בחלק העליון של הצהרת ה-SQL.
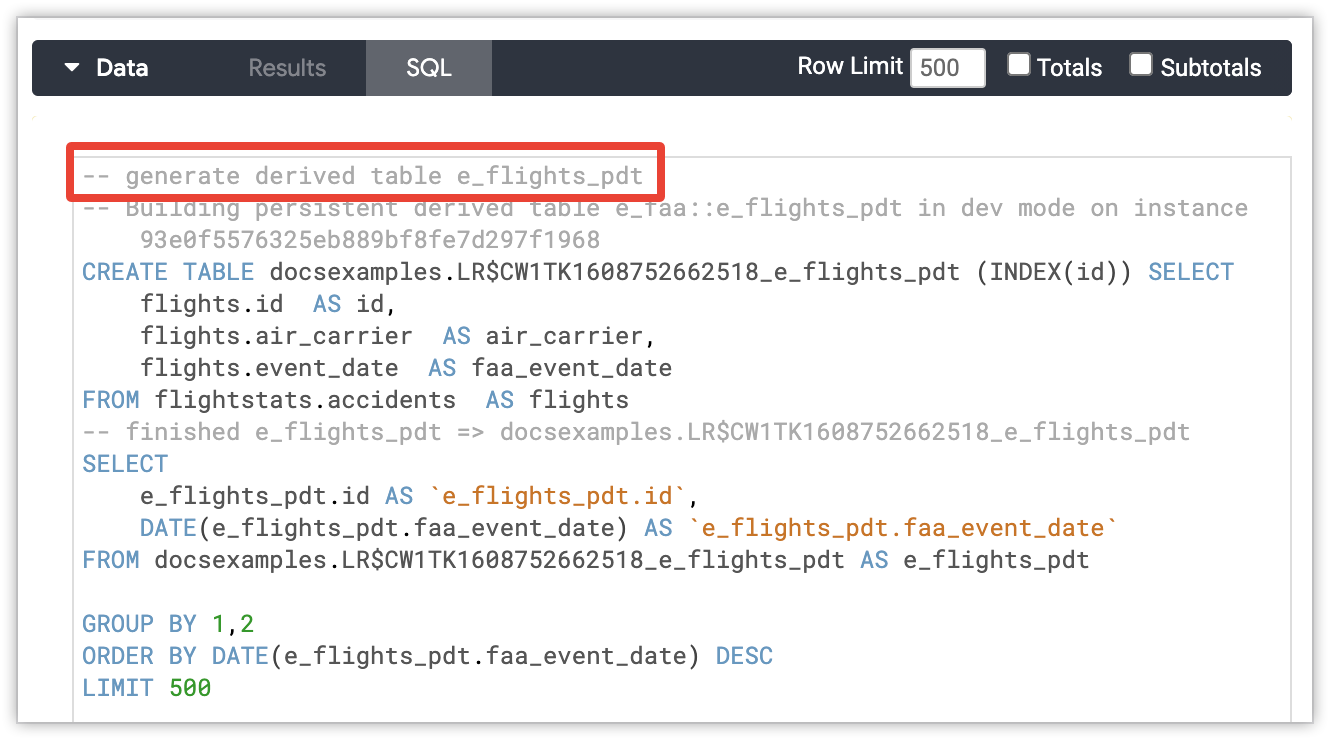
לבסוף, התגובה ליצירת PDT מופיעה בשדה Message בכרטיסייה Info בחלון הקופץ Query Details לכל שאילתה בדף האדמין Queries.
בנייה מחדש של PDT אחרי כשל
כשמתרחשת שגיאה בטבלה נגזרת מתמידה (PDT), זה מה שקורה כשמבצעים שאילתה ב-PDT:
- אם אותה שאילתה הופעלה בעבר, Looker ישתמש בתוצאות שבמטמון. (הסבר על אופן הפעולה מופיע בדף שמירת שאילתות במטמון).
- אם התוצאות לא נמצאות במטמון, Looker ישלוף תוצאות מ-PDT במסד הנתונים, אם קיימת גרסה תקפה של ה-PDT.
- אם אין PDT תקף במסד הנתונים, Looker ינסה לבנות מחדש את ה-PDT.
- אם אי אפשר לבנות מחדש את ה-PDT, Looker תחזיר שגיאה לגבי שאילתה. הכלי ליצירה מחדש של Looker ינסה לבנות מחדש את ה-PDT בפעם הבאה שתתבצע שאילתה לגבי ה-PDT או בפעם הבאה שאסטרטגיית השמירה של ה-PDT תפעיל בנייה מחדש.
ב-PDT מדורגות, אותה לוגיקה חלה, אבל יש הבדל אחד:
- אם ה-build של טבלה אחת נכשל, ה-build של ה-PDTs בהמשך שרשרת התלות ייכשל גם הוא.
- בעצם, PDT שתלוי ב-PDT אחר מבצע שאילתה לגבי ה-PDT שהוא מסתמך עליו, כך שאסטרטגיית ההתמדה של טבלה אחת יכולה להפעיל בנייה מחדש של ה-PDT שמעל בשרשרת.
נחזור לדוגמה הקודמת של טבלאות מדורגות, שבה TABLE_D תלויה ב-TABLE_C, שתלויה ב-TABLE_B, שתלויה ב-TABLE_A:
אם יש כשל ב-TABLE_B, כל ההתנהגות הרגילה (לא קסקדית) חלה על TABLE_B:
- אם מתבצעת שאילתה לגבי
TABLE_B, Looker מנסה קודם להשתמש במטמון כדי להחזיר תוצאות. - אם הניסיון הזה נכשל, Looker מנסה להשתמש בגרסה קודמת של הטבלה, אם אפשר.
- אם גם הניסיון הזה נכשל, Looker מנסה לבנות מחדש את הטבלה.
- לבסוף, אם אי אפשר לבנות מחדש את
TABLE_B, Looker יחזיר שגיאה.
Looker ינסה שוב לבנות מחדש את TABLE_B כשהטבלה תישלח לשאילתה בפעם הבאה או כשהאסטרטגיה של הטבלה להתמדה תפעיל בנייה מחדש בפעם הבאה.
אותו עיקרון חל גם על התלויים של TABLE_B. לכן, אם אי אפשר ליצור את TABLE_B ויש שאילתה לגבי TABLE_C, מתרחש הרצף הבא:
- Looker ינסה להשתמש במטמון בשביל השאילתה ב-
TABLE_C. - אם התוצאות לא נמצאות במטמון, Looker ינסה לשלוף תוצאות מ-
TABLE_Cבמסד הנתונים. - אם אין גרסה תקינה של
TABLE_C, Looker ינסה לבנות מחדש אתTABLE_C, וכך תיצור שאילתה ב-TABLE_B. - לאחר מכן, מערכת Looker תנסה לבנות מחדש את
TABLE_B(הפעולה תיכשל אםTABLE_Bלא תוקן). - אם אי אפשר לבנות מחדש את
TABLE_B, אי אפשר לבנות מחדש אתTABLE_C, ולכן Looker יחזיר שגיאה לגבי השאילתה ב-TABLE_C. - Looker ינסה לבנות מחדש את
TABLE_Cבהתאם לאסטרטגיית ההתמדה הרגילה שלו, או בפעם הבאה שתתבצע שאילתה ב-PDT (כולל בפעם הבאה ש-TABLE_Dינסה לבנות, כיTABLE_Dתלוי ב-TABLE_C).
אחרי שתפתרו את הבעיה ב-TABLE_B, המערכת תנסה לבנות מחדש את TABLE_B ואת כל הטבלאות התלויות בה בהתאם לאסטרטגיות השמירה שלהן, או בפעם הבאה שתתבצע שאילתה לגביהן (כולל בפעם הבאה שטבלת PDT תלויה תנסה להיבנות מחדש). לחלופין, אם גרסת פיתוח של ה-PDT בשרשרת נוצרה במצב פיתוח, יכול להיות שגרסאות הפיתוח ישמשו כ-PDT חדשים של סביבת הייצור. (בקטע טבלאות קבועות במצב פיתוח בדף הזה מוסבר איך זה עובד). אפשר גם להשתמש ב-Explore כדי להריץ שאילתה ב-TABLE_D ואז לבנות מחדש באופן ידני את ה-PDT בשביל השאילתה. פעולה כזו תגרום לבנייה מחדש של כל ה-PDT שמופיעים בשרשרת התלות.
שיפור הביצועים של PDT
כשיוצרים טבלאות נגזרות מתמידות (PDT), הביצועים יכולים להיות בעיה. במיוחד אם הטבלה גדולה מאוד, יכול להיות שהרצת שאילתה בטבלה תהיה איטית, בדיוק כמו בכל טבלה גדולה במסד הנתונים.
כדי לשפר את הביצועים, אפשר לסנן את הנתונים או לקבוע איך הנתונים ב-PDT ימוינו ויוגדרו באינדקס.
הוספת מסננים להגבלת מערך הנתונים
במערכי נתונים גדולים במיוחד, אם יש הרבה שורות, השאילתות שמופעלות על טבלה נגזרת מתמשכת (PDT) ירוצו לאט יותר. אם בדרך כלל אתם שולחים שאילתות רק לגבי נתונים מהזמן האחרון, כדאי להוסיף מסנן לסעיף WHERE של ה-PDT כדי להגביל את הטבלה לנתונים של 90 ימים או פחות. כך, בכל פעם שהטבלה תיבנה מחדש, יתווספו אליה רק נתונים רלוונטיים, והרצת השאילתות תהיה מהירה הרבה יותר. לאחר מכן, תוכלו ליצור PDT נפרד וגדול יותר לניתוח היסטורי, כדי לאפשר הרצת שאילתות מהירות על נתונים עדכניים וגם הרצת שאילתות על נתונים ישנים.
שימוש ב-indexes או ב-sortkeys וב-distribution
כשיוצרים טבלת PDT גדולה ומתמשכת, כדאי להוסיף אינדקס לטבלה (בניבים כמו MySQL או Postgres) או להוסיף מפתחות מיון והפצה (ב-Redshift) כדי לשפר את הביצועים.
בדרך כלל הכי טוב להוסיף את הפרמטר indexes לשדות של מזהים או תאריכים.
ב-Redshift, בדרך כלל הכי טוב להוסיף את הפרמטר sortkeys לשדות של מזהה או תאריך, ואת הפרמטר distribution לשדה שמשמש לצירוף.
הגדרות מומלצות לשיפור הביצועים
ההגדרות הבאות קובעות איך הנתונים בטבלת ה-PDT ממוינים ומאונדקסים. ההגדרות הבאות הן אופציונליות, אבל מומלצות מאוד:
- ב-Redshift וב-Aster, משתמשים בפרמטר
distributionכדי לציין את שם העמודה שהערך שלה משמש לפיזור הנתונים באשכול. כשמבצעים איחוד של שתי טבלאות לפי העמודה שצוינה בפרמטרdistribution, מסד הנתונים יכול למצוא את נתוני האיחוד באותו צומת, ולכן מצמצם את קלט/פלט בין הצמתים. - ב-Redshift, מגדירים את הפרמטר
distribution_styleלערךallכדי להנחות את מסד הנתונים לשמור עותק מלא של הנתונים בכל צומת. האפשרות הזו שימושית בדרך כלל כדי למזער את קלט/פלט בין הצמתים כשמצטרפים לטבלאות קטנות יחסית. מגדירים את הערך הזה ל-evenכדי להנחות את מסד הנתונים לפזר את הנתונים באופן שווה בין הצמתים בלי להשתמש בעמודת הפצה. אפשר לציין את הערך הזה רק אם לא צוין הערךdistribution. - ב-Redshift, משתמשים בפרמטר
sortkeys. הערכים מציינים באילו עמודות של PDT נעשה שימוש כדי למיין את הנתונים בדיסק, כדי להקל על החיפוש. ב-Redshift, אפשר להשתמש ב-sortkeysאו ב-indexes, אבל לא בשניהם. - ברוב מסדי הנתונים, משתמשים בפרמטר
indexes. הערכים מציינים אילו עמודות ב-PDT עוברות אינדוקס. (ב-Redshift, נעשה שימוש באינדקסים כדי ליצור מפתחות מיון משולבים).