

O Serviço de destilação do Gemini (destilação) permite que os usuários treinem um modelo "estudante" menor e mais eficiente que usa os resultados e padrões de raciocínio de um modelo "professor" maior e mais capaz. Embora os modelos de fronteira definam a vanguarda da IA, eles podem ser provisionados em excesso para casos de uso empresariais específicos. A destilação preenche essa lacuna, permitindo eficiência de nível de produção (menor latência e custo) e modelos menores para alcançar um nível mais profundo de raciocínio.
Ao contrário do ajuste supervisionado (SFT) padrão, que usa apenas a saída de texto final, a destilação aproveita:
- Respostas do professor: a saída textual final.
- Raciocínios brutos: os caminhos de raciocínio internos gerados pelo modelo professor.
Modelos compatíveis
Os seguintes modelos são compatíveis com a destilação durante o acesso antecipado:
- Modelo de professor:
gemini-3.1-pro - Modelo do estudante:
gemini-2.5-flash
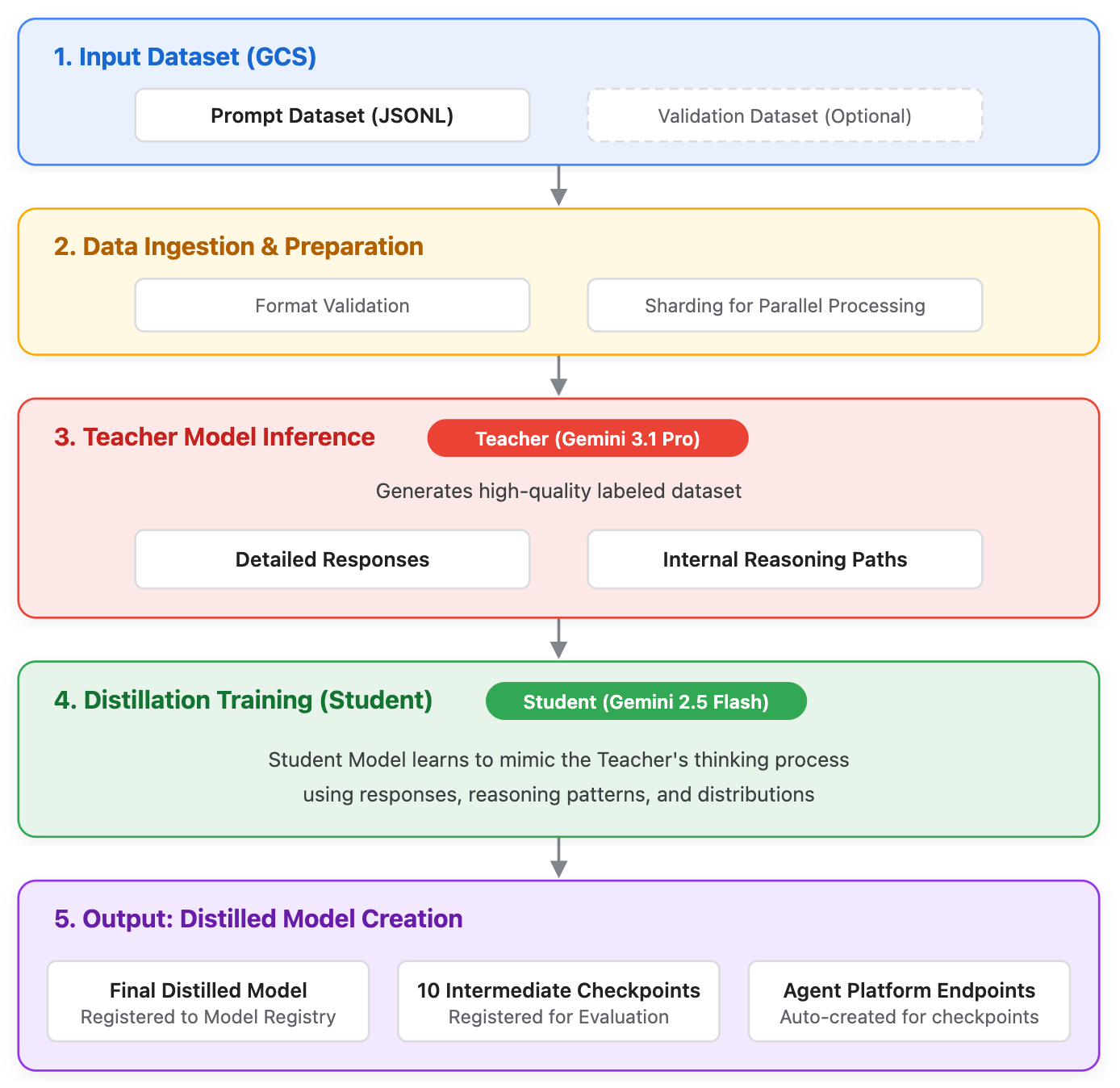
Fig. 1. Ilustração do sistema de como o Gemini Distillation Service funciona.
Casos de uso adequados
A destilação é recomendada em vez de comandos padrão ou ajuste refinado supervisionado (SFT, na sigla em inglês) nos seguintes cenários:
- Aplicativos de alto volume e sensíveis à latência: quando seu aplicativo exige os recursos de raciocínio de um modelo do nível Pro, mas precisa atender a SLAs de latência ou restrições de orçamento rigorosas que exigem um modelo do nível Flash.
- Falta de dados de informações empíricas (SFT inviável): quando você tem um grande conjunto de dados de comandos ou consultas do usuário, mas não tem recursos para rotular ou gerar manualmente respostas de informações empíricas de alta qualidade necessárias para a SFT padrão.
- Tarefas de raciocínio complexo: tarefas que envolvem lógica de várias etapas, resumo de documentos altamente técnicos ou tarefas de programação complexas em que o modelo Flash básico tem dificuldades, mas o modelo Pro é bem-sucedido.
- Lacunas significativas de desempenho: quando o modelo professor supera substancialmente o modelo estudante de base na sua tarefa específica, oferecendo uma margem clara de conhecimento para transferência durante a destilação.
Pré-requisitos e configuração do projeto
Antes de iniciar um job de destilação, verifique se o ambiente Google Cloud está configurado corretamente:
- Solicite acesso à lista de permissões: verifique se o ID do projeto Google Cloud foi adicionado à lista de permissões para o acesso antecipado ao serviço de destilação do Gemini. Entre em contato com seu representante de vendas do Google para adicionar o projeto à lista de permissões.
- Ative a API: ative a API Agent Platform no seu projeto Google Cloud .
- Definir permissões de função do IAM: você precisa ter a função de
administrador da plataforma de agentes (
roles/aiplatform.admin) do IAM. - Defina a região: os jobs de destilação precisam ser executados na região
us-central1.
Preparação do conjunto de dados
Um dos principais recursos desse serviço é o uso de conjuntos de dados somente de comandos. Como o modelo professor gera as saídas de destino durante o processo de destilação, não é necessário fornecer as respostas esperadas.
Requisitos do conjunto de dados
Os conjuntos de dados precisam estar no formato JSON Lines (JSONL) e armazenados em um bucket do Cloud Storage. Cada entrada precisa seguir o formato do conjunto de dados de ajuste do Gemini, além do seguinte:
- Instruções do sistema: é possível incluir um campo
systemInstructionopcional (com uma função "system") para definir comandos do sistema. - Entrada: o campo "conteúdo" (com a função "usuário") é obrigatório para a entrada principal.
Comandos de várias rodadas: você pode alternar entre as funções "usuário" e "modelo", desde que a entrada final na sequência seja "usuário".
Confira abaixo dois exemplos de arquivos dataset.jsonl:
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
}
]
},
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Choose several strands of embroidery thread in a variety of colors."
}
]
},
{
"role": "user",
"parts": [
{
"text": "You will need one egg (raw or hard boiled but hard boiled is best) and one spoon for each person participating in the race. You might even like to use dyed Easter eggs as something special for Easter. It's best to have this race on grass or some other soft surface, to give dropped eggs a chance!"
}
]
}
]
}
Práticas recomendadas
Siga estas diretrizes ao criar seu conjunto de dados:
- Tamanho: é recomendável ter pelo menos 1.000 exemplos para uma melhoria notável na qualidade.
- Diversidade: verifique se seus comandos abrangem os casos extremos e os comprimentos variados esperados no tráfego de produção.
Configurar a solicitação de destilação
Um job de destilação requer a configuração do comportamento de geração do professor e dos hiperparâmetros de treinamento do estudante.
Configurar o comportamento de geração do modelo de professor
Você precisa definir como o modelo de professor responde ao seu conjunto de dados. A qualidade do modelo estudante depende diretamente da qualidade da resposta do professor. Para
configurar o comportamento de geração do modelo de professor, defina o candidateCount:
candidateCount: o número de variações de resposta a serem geradas. Exemplo:4. Intervalo[1, 5]. Se não for especificado na solicitação, um valor padrão de4será usado.
Definir os hiperparâmetros de destilação
Os hiperparâmetros de destilação controlam o processo de treinamento do modelo de estudante. Para mais informações sobre hiperparâmetros na plataforma de agentes do Gemini Enterprise, consulte a seção "Criar um job de ajuste" do guia de ajuste supervisionado.
Os seguintes hiperparâmetros precisam ser definidos ao criar um job de destilação:
epochCount: o número de vezes que o modelo do estudante vai iterar no conjunto de dados. Exemplo:20. Intervalo[1, 100]. Se não for especificado, um valor padrão de4será usado.learningRateMultiplier: modifica a taxa de aprendizado básica do modelo do estudante. Exemplo:2.0. Intervalo[0.25, 4]. Se não for especificado, um valor padrão de1será usado.
Iniciar o job de destilação
Durante o período de acesso antecipado, é possível enviar e monitorar jobs de destilação usando a versão REST da API Agent Platform. É possível iniciar um novo trabalho de destilação ou fazer ajuste contínuo em um ponto de verificação de modelo já destilado.
Criar um job de destilação
Crie um arquivo JSON chamado request.json com a configuração do seu job. No exemplo a seguir, a configuração de geração do professor está aninhada no campo hyperParameters:
{
"description": "Distillation testing job.",
"baseModel": "gemini-2.5-flash",
"tunedModelDisplayName": "flash-distillation-run-1",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5
}
}
}
}
Envie o job usando curl:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Fazer ajustes contínuos
Se quiser retomar o ajuste de um checkpoint de modelo destilado anteriormente, inclua o bloco preTunedModel no arquivo request.json. O ajuste contínuo só é compatível com pontos de verificação de modelos destilados anteriormente, com o mesmo modelo de estudante de base. Não há suporte para checkpoints de modelos ajustados supervisionados anteriormente, mesmo com o mesmo modelo de estudante de base.
Confira um exemplo de como configurar o ajuste contínuo para um ponto de verificação de modelo destilado anteriormente:
{
"description": "Continuous distillation testing job.",
"preTunedModel": {
"tunedModelName": "projects/YOUR_PROJECT_ID/locations/us-central1/models/PRETUNED_MODEL_ID@1",
"checkpointId": "1",
"baseModel": "gemini-2.5-flash"
},
"tunedModelDisplayName": "flash-distillation-continuous",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5,
}
}
}
}
Envie o payload usando curl:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Monitorar o job de destilação
A resposta do envio vai retornar um nome de job que contém seu
JOB_ID. Para verificar o status do seu job (state, erros e hiperparâmetros finais), envie uma solicitação GET:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs/JOB_ID
Também é possível monitorar o progresso visualmente no console do Google Cloud . Para isso, acesse Plataforma do agente > Ajuste e escolha a região us-central1.
Nesta versão de acesso antecipado, a interface do console da plataforma do agente tem as seguintes limitações conhecidas:
- Progresso da amostragem de professores: não há um widget de progresso para o processo de amostragem do modelo de professor. Embora o status possa mostrar "Executando a preparação para ajuste", o job está sendo executado normalmente em segundo plano.
- Gráficos de ajuste do estudante: durante a etapa de ajuste do modelo estudante, a UI fornece gráficos para a curva de perda e o total de tokens de texto de treinamento.
- Tabela de checkpoints: a interface mostra uma tabela de checkpoints intermediários e links para o endpoint de previsão da Agent Platform gerado para avaliação. A coluna "Época" nesta tabela mostra "0" devido a um problema conhecido.
Cancele o job de destilação
Para cancelar um job de destilação em andamento, faça o seguinte:
Use o console Google Cloud , mudando o seguinte URL:
https://console.cloud.google.com/agent-platform/tuning/managed?project=YOUR_PROJECT_ID&vertex_ai_region=us-central1Substitua YOUR_PROJECT_ID pela ID do seu projeto.
Use
curlpara enviar uma solicitação POST e cancelar o job:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID:cancelSubstitua:
YOUR_PROJECT_IDpelo código do projeto;YOUR_JOB_IDpelo ID do job.
Como avaliar o resultado
Depois que o job de destilação é concluído, o novo modelo estudante é registrado automaticamente no Gemini Enterprise Agent Platform Model Registry, e um ou mais endpoints dedicados são criados para disponibilizar previsões. Para avaliar o resultado, localize o endpoint, envie uma solicitação de previsão e, por fim, avalie.
Para avaliar o resultado, faça o seguinte:
Envie a seguinte solicitação GET para conferir o status do job de ajuste.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_IDSubstitua:
YOUR_PROJECT_IDpelo código do projeto;YOUR_JOB_IDpelo ID do job.
Os jobs concluídos mostram um campo
endpointaninhado dentro do objetotunedModel. Extraia oENDPOINT_IDdo final da string de caminho retornada (por exemplo,projects/.../endpoints/YOUR_ENDPOINT_ID). Anote o ID do endpoint.Confira se o job de ajuste foi concluído com sucesso, porque o endpoint não fica disponível enquanto o job de ajuste ainda está em execução ou falhou. Se o campo
endpointestiver faltando, depure o job de ajuste visualizando as chavesstateouerrordele.Crie uma solicitação de payload JSON chamada
generate_content_request.jsonque contenha seu comando:{ "contents": { "role": "user", "parts": [ { "text": "hi, say something" } ] } }Use o exemplo de POST a seguir para enviar uma solicitação de previsão:
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/endpoints/YOUR_ENDPOINT_ID:generateContent \ -d @generate_content_request.jsonSubstitua:
YOUR_PROJECT_ID: o ID do projeto.YOUR_JOB_ID: o ID do job.ENDPOINT_ID: o ID do endpoint.
Para avaliar os resultados, faça o seguinte:
Execute um conjunto de teste de validação cruzada usando comandos não incluídos nos dados de treinamento com o modelo recém-destilado.
Compare as saídas com o modelo
gemini-2.5-flashde base para medir as melhorias na qualidade.Compare as respostas com o modelo
gemini-3.1-propara determinar o quanto o estudante se aproxima do raciocínio do professor.
Limitações
A tabela a seguir descreve as limitações da destilação:
A destilação está sujeita às seguintes limitações:
- Limitações do modelo:
- Consulte os modelos compatíveis.
- Restrições de conjuntos de dados:
- Limites de volume:
- A capacidade máxima do conjunto de treinamento é de 50.000 exemplos.
- O tamanho do arquivo JSONL de origem não pode exceder 1 GB.
- Especificações da janela de contexto:
- O serviço acomoda um máximo de 8.000 tokens de entrada por entrada. Os jobs de destilação são encerrados se mais de 10% das entradas fornecidas excederem esse limite estabelecido.
- A amostragem do modelo professor é limitada a uma saída máxima de 24.000 tokens. Quando o modelo do professor gera mais de 24.000 tokens, o conteúdo é truncado nesse limite, o que pode afetar o desempenho do modelo do estudante.
- Modalidade: limitada a dados baseados em texto. Não há suporte para entradas multimodais, incluindo vídeo, imagens ou chamadas de função.
- Limites de volume:
- Limitações de configuração e hiperparâmetros
- Siga estas restrições ao definir o distillationSpec e os hiperparâmetros associados:
- Criptografia: a CMEK não está disponível para tarefas de destilação que envolvem modelos próprios do Google.
epochCount: restrito a um valor inteiro entre 1 e 100.learningRateMultiplier: os valores precisam estar no intervalo de usar pontos flutuantes de0.25a4.0.
- Siga estas restrições ao definir o distillationSpec e os hiperparâmetros associados:
- Destilação em uma etapa: a amostragem do modelo professor e o ajuste do modelo estudante são executados em uma única chamada de API. Se você tiver uma grande quantidade de dados para amostragem, os mesmos dados precisarão ser amostrados novamente no ajuste a seguir.
Acesso
Se quiser testar o serviço de destilação do Gemini, entre em contato com nossa equipe do serviço de ajuste em cloud-ai-tuning-service-support@google.com para solicitar acesso e inclusão de projetos na lista de permissões.
Para garantir o desempenho ideal e o gerenciamento de recursos, recomendamos criar um projeto Google Cloud dedicado para suas tarefas de destilação. Ao entrar em contato com nossa equipe, forneça o ID do projeto ou o número do projeto para acelerar o processo de inclusão na lista de permissões.
Políticas de cota e acesso
As seguintes políticas de cota e acesso estão em vigor:
Capacidade: os projetos adicionados recentemente à nossa lista de permissões são provisionados com uma cota simultânea padrão de 4. Para evitar disputas de recursos, recomendamos usar um projeto separado em vez de um que já esteja executando outros jobs de ajuste do Gemini.
Período de acesso: o acesso é concedido por um período inicial de 30 dias.