

Layanan Distilasi Gemini (Distilasi) memungkinkan pengguna melatih model "siswa" yang lebih kecil dan efisien yang menggunakan output dan pola penalaran model "pengajar" yang lebih besar dan mumpuni. Meskipun model canggih mendefinisikan teknologi AI tercanggih, model ini dapat dialokasikan secara berlebihan untuk kasus penggunaan perusahaan tertentu. Distilasi menjembatani kesenjangan ini, sehingga memungkinkan efisiensi tingkat produksi (latensi dan biaya yang lebih rendah) sekaligus memungkinkan model yang lebih kecil mencapai tingkat penalaran yang lebih dalam.
Tidak seperti supervised fine-tuning (SFT) standar yang hanya menggunakan output teks akhir, distilasi memanfaatkan:
- Respons pengajar: Output tekstual akhir.
- Pemikiran mentah: Jalur penalaran internal yang dihasilkan oleh model pengajar.
Model yang didukung
Model berikut didukung untuk Distilasi selama akses awal:
- Model pengajar:
gemini-3.1-pro - Model siswa:
gemini-2.5-flash
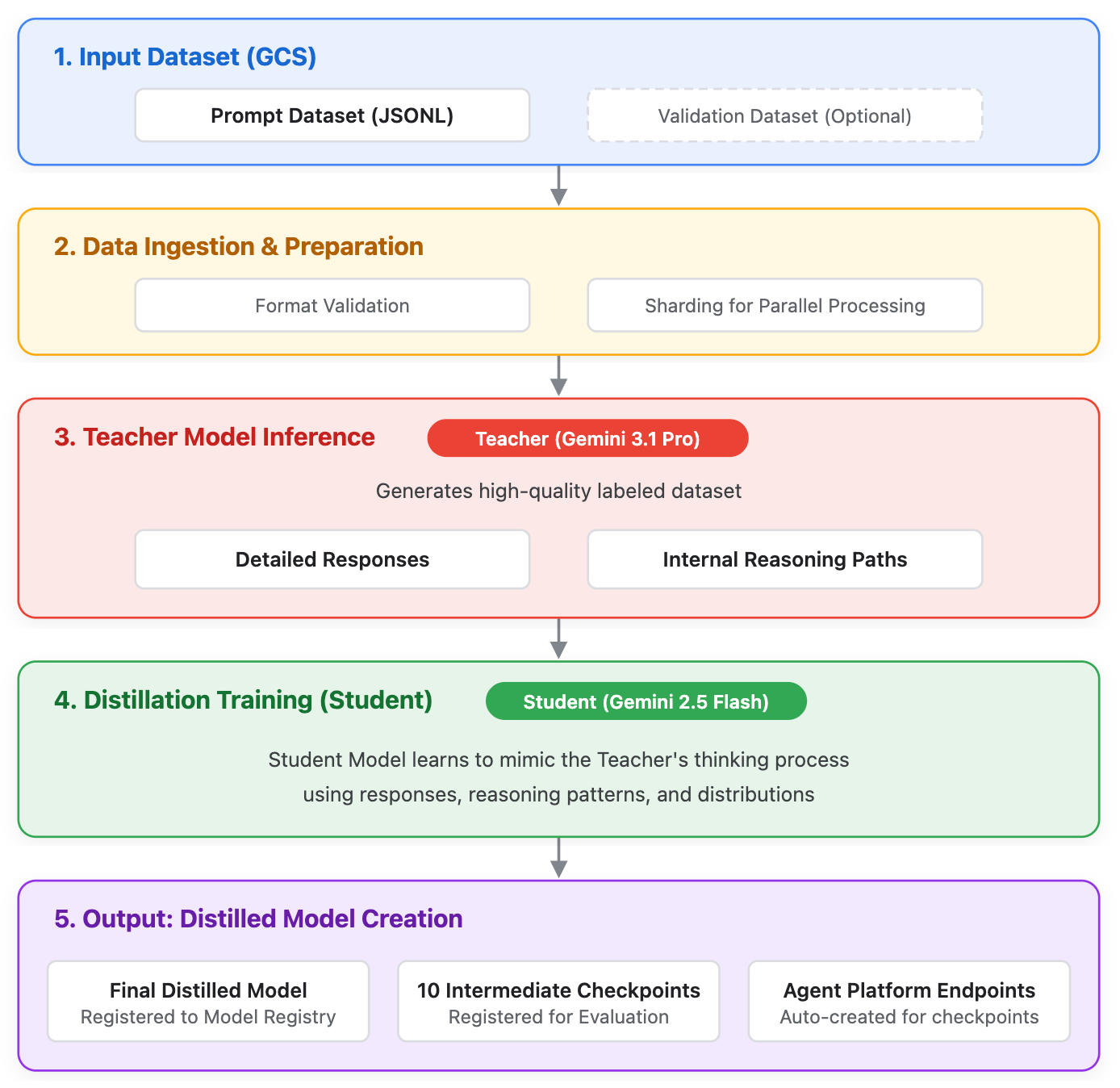
Gambar 1. Ilustrasi sistem tentang cara kerja Layanan Distilasi Gemini.
Kasus penggunaan yang cocok
Distilasi direkomendasikan daripada perintah standar atau penyesuaian terawasi (SFT) dalam skenario berikut:
- Aplikasi bervolume tinggi dan sensitif terhadap latensi: Jika aplikasi Anda memerlukan kemampuan penalaran model tingkat Pro, tetapi harus memenuhi SLA latensi yang ketat atau batasan anggaran yang memerlukan model tingkat Flash.
- Kurangnya data kebenaran dasar (SFT tidak dapat dilakukan): Jika Anda memiliki set data besar yang berisi perintah atau kueri pengguna, tetapi tidak memiliki resource untuk memberi label secara manual atau membuat jawaban kebenaran dasar berkualitas tinggi yang diperlukan untuk SFT standar.
- Tugas penalaran yang kompleks: Tugas yang melibatkan logika multi-langkah, meringkas dokumen yang sangat teknis, atau tugas coding yang kompleks yang membuat model Flash dasar kesulitan, tetapi model Pro berhasil.
- Perbedaan performa yang signifikan: Jika model pengajar secara substansial mengungguli model siswa dasar dalam tugas spesifik Anda, hal ini memberikan margin pengetahuan yang jelas untuk ditransfer selama distilasi.
Prasyarat dan penyiapan project
Sebelum memulai tugas distilasi, pastikan lingkungan Google Cloud Anda dikonfigurasi dengan benar:
- Minta akses ke daftar yang diizinkan: Pastikan project ID Anda telah ditambahkan ke daftar yang diizinkan untuk akses awal Layanan Distilasi Gemini. Hubungi sales representative Google Anda untuk menambahkan project Anda ke daftar yang diizinkan. Google Cloud
- Aktifkan API: Aktifkan Agent Platform API di Google Cloud project Anda.
- Tetapkan izin peran IAM: Anda harus memiliki peran IAM
Agent Platform Administrator (
roles/aiplatform.admin). - Tetapkan region: Tugas distilasi harus dijalankan di region
us-central1.
Persiapan set data
Fitur utama layanan ini adalah penggunaan set data khusus perintah. Karena model pengajar menghasilkan output target selama proses distilasi, Anda tidak perlu memberikan jawaban yang diharapkan.
Persyaratan set data
Set data harus dalam format JSON Lines (JSONL) dan disimpan di bucket Cloud Storage. Setiap entri harus mematuhi format set data penyesuaian Gemini selain yang berikut:
- Petunjuk sistem: Anda dapat menyertakan kolom
systemInstructionopsional (dengan peran 'sistem') untuk menentukan perintah sistem. - Input: Kolom konten (dengan peran 'pengguna') diperlukan untuk input utama.
Perintah multi-giliran: Anda dapat bergantian antara peran 'pengguna' dan 'model', asalkan entri terakhir dalam urutan adalah 'pengguna'.
Berikut adalah dua contoh file dataset.jsonl:
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
}
]
},
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Choose several strands of embroidery thread in a variety of colors."
}
]
},
{
"role": "user",
"parts": [
{
"text": "You will need one egg (raw or hard boiled but hard boiled is best) and one spoon for each person participating in the race. You might even like to use dyed Easter eggs as something special for Easter. It's best to have this race on grass or some other soft surface, to give dropped eggs a chance!"
}
]
}
]
}
Praktik terbaik
Gunakan panduan berikut saat membuat set data:
- Ukuran: Sebaiknya gunakan minimal 1.000 contoh untuk peningkatan kualitas yang terlihat jelas.
- Keragaman: Pastikan perintah Anda mencakup kasus ekstrem dan berbagai panjang yang diharapkan dalam traffic produksi Anda.
Mengonfigurasi permintaan distilasi
Tugas distilasi memerlukan konfigurasi perilaku pembuatan teacher dan hyperparameter pelatihan student.
Mengonfigurasi perilaku pembuatan model pengajar
Anda harus menentukan cara model pengajar merespons set data Anda. Kualitas model siswa secara langsung dibatasi oleh kualitas output model pengajar. Untuk
mengonfigurasi perilaku pembuatan model pengajar, tetapkan candidateCount:
candidateCount: Jumlah variasi respons yang akan dibuat. (Contoh:4. Rentang[1, 5]). Jika tidak ditentukan dalam permintaan, nilai default4akan digunakan.
Menetapkan hyperparameter distilasi
Hyperparameter distilasi mengontrol proses pelatihan model siswa. Untuk mengetahui informasi selengkapnya tentang hyperparameter di Gemini Enterprise Agent Platform, lihat bagian"Buat tugas tuning" dalam panduan supervised fine-tuning.
Hyperparameter berikut harus ditetapkan saat membuat tugas penyulingan:
epochCount: Jumlah iterasi model siswa pada set data. (Contoh:20. Rentang[1, 100]). Jika tidak ditentukan, nilai default4akan digunakan.learningRateMultiplier: Mengubah kecepatan pembelajaran dasar model siswa. (Contoh:2.0. Rentang[0.25, 4]). Jika tidak ditentukan, nilai default1akan digunakan.
Mulai tugas distilasi
Selama periode akses awal, Anda dapat mengirimkan dan memantau tugas distilasi menggunakan Agent Platform API versi REST. Anda dapat memulai tugas distilasi baru atau melakukan penyetelan berkelanjutan pada checkpoint model yang sudah didistilasi.
Membuat tugas distilasi baru
Buat file JSON bernama request.json yang berisi konfigurasi tugas Anda. Dalam
contoh berikut, konfigurasi pembuatan guru disarangkan dalam
kolom hyperParameters:
{
"description": "Distillation testing job.",
"baseModel": "gemini-2.5-flash",
"tunedModelDisplayName": "flash-distillation-run-1",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5
}
}
}
}
Kirim tugas menggunakan curl:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Melakukan penyetelan berkelanjutan
Jika Anda ingin melanjutkan penyetelan dari titik pemeriksaan model yang sebelumnya di-distilasi,
sertakan blok preTunedModel dalam file request.json Anda. Penyesuaian berkelanjutan
hanya didukung untuk checkpoint model yang sebelumnya di-distilasi, dengan model siswa
dasar yang sama. Pos pemeriksaan model yang disesuaikan dan diawasi sebelumnya (bahkan dengan
model siswa dasar yang sama) tidak didukung.
Berikut adalah contoh penyiapan penyetelan berkelanjutan untuk checkpoint model yang sebelumnya di-distilasi:
{
"description": "Continuous distillation testing job.",
"preTunedModel": {
"tunedModelName": "projects/YOUR_PROJECT_ID/locations/us-central1/models/PRETUNED_MODEL_ID@1",
"checkpointId": "1",
"baseModel": "gemini-2.5-flash"
},
"tunedModelDisplayName": "flash-distillation-continuous",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5,
}
}
}
}
Kirimkan payload menggunakan curl:
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Memantau tugas distilasi
Respons pengiriman akan menampilkan nama tugas yang berisi
JOB_ID. Anda dapat memeriksa status tugas
(state, error, dan hyperparameter akhir) dengan mengirim permintaan GET:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs/JOB_ID
Anda juga dapat memantau progres secara visual di konsol Google Cloud dengan
membuka Agent Platform > Tuning dan memilih region
us-central1.
Untuk rilis akses awal ini, UI Konsol Agent Platform memiliki batasan umum berikut:
- Progres pengambilan sampel pengajar: Tidak ada widget progres untuk proses pengambilan sampel model pengajar. Meskipun statusnya mungkin menampilkan "Menjalankan Persiapan untuk penyesuaian", tugas berjalan normal di latar belakang.
- Diagram penyesuaian siswa: Selama tahap penyesuaian model siswa, UI menyediakan diagram untuk kurva penyimpangan dan total token teks pelatihan.
- Tabel titik pemeriksaan: UI menampilkan tabel titik pemeriksaan perantara dan link ke endpoint prediksi Agent Platform yang dihasilkan untuk evaluasi. Kolom "Epoch" dalam tabel ini menampilkan '0' karena masalah yang diketahui.
Membatalkan tugas distilasi
Untuk membatalkan tugas distilasi yang sedang berlangsung, lakukan salah satu hal berikut:
Gunakan konsol Google Cloud , dengan mengubah URL berikut:
https://console.cloud.google.com/agent-platform/tuning/managed?project=YOUR_PROJECT_ID&vertex_ai_region=us-central1Ganti YOUR_PROJECT_ID dengan project ID Anda.
Gunakan
curluntuk mengirim permintaan POST guna membatalkan tugas:curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID:cancelGanti kode berikut:
YOUR_PROJECT_IDdengan ID project Anda.YOUR_JOB_IDdengan ID tugas Anda.
Mengevaluasi Hasil
Setelah tugas distilasi berhasil diselesaikan, model turunan baru akan otomatis didaftarkan di Registry Model Platform Agen Gemini Enterprise, dan satu atau beberapa endpoint khusus akan dibuat untuk menyajikan prediksi. Untuk mengevaluasi hasilnya, Anda akan menemukan endpoint, mengirim permintaan prediksi, dan akhirnya mengevaluasi.
Untuk mengevaluasi hasilnya, lakukan tindakan berikut:
Kirim permintaan GET berikut untuk melihat status tugas penyesuaian.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_IDGanti kode berikut:
YOUR_PROJECT_IDdengan ID project Anda.YOUR_JOB_IDdengan ID tugas Anda.
Tugas yang selesai menampilkan kolom
endpointyang bertingkat di dalam objektunedModel. EkstrakENDPOINT_IDdari akhir string jalur yang ditampilkan (misalnya,projects/.../endpoints/YOUR_ENDPOINT_ID). Perhatikan ID endpoint.Pastikan tugas penyesuaian berhasil diselesaikan, karena endpoint tidak tersedia saat tugas penyesuaian masih berjalan atau gagal. Jika kolom
endpointtidak ada, debug tugas penyetelan dengan melihat kuncistateatauerrortugas.Buat permintaan payload JSON bernama
generate_content_request.jsonyang berisi perintah Anda:{ "contents": { "role": "user", "parts": [ { "text": "hi, say something" } ] } }Gunakan contoh POST berikut untuk mengirim permintaan prediksi:
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/endpoints/YOUR_ENDPOINT_ID:generateContent \ -d @generate_content_request.jsonGanti kode berikut:
YOUR_PROJECT_ID: project ID Anda.YOUR_JOB_ID: ID tugas Anda.ENDPOINT_ID: ID endpoint Anda.
Lakukan hal berikut untuk mengevaluasi hasilnya:
Jalankan set pengujian pisahan, menggunakan perintah yang tidak disertakan dalam data pelatihan, terhadap model yang baru di-distilasi.
Bandingkan output dengan model dasar
gemini-2.5-flashuntuk mengukur peningkatan kualitas.Bandingkan output dengan model
gemini-3.1-prountuk menentukan seberapa dekat perkiraan penalaran siswa dengan penalaran pengajar.
Batasan
Tabel berikut menjelaskan batasan untuk Distilasi:
Distilasi tunduk pada batasan berikut:
- Batasan model:
- Lihat model yang didukung
- Batasan set data:
- Batas volume:
- Kapasitas set pelatihan maksimum adalah 50.000 contoh.
- Ukuran file JSONL sumber tidak boleh melebihi 1 GB.
- Spesifikasi jendela konteks:
- Layanan ini mengakomodasi maksimum 8.000 token input per entri. Tugas distilasi akan dihentikan jika lebih dari 10% entri yang diberikan melebihi nilai minimum yang ditetapkan ini.
- Sampling model pengajar dibatasi hingga output maksimum 24.000 token. Jika model pengajar menghasilkan lebih dari 24.000 token, konten akan dipangkas pada batas ini, yang dapat memengaruhi performa model siswa.
- Modalitas: Terbatas pada data berbasis teks. Tidak ada dukungan untuk input multimodal termasuk video, gambar, atau panggilan fungsi.
- Batas volume:
- Batasan konfigurasi dan hyperparameter
- Patuhi batas berikut saat menentukan distillationSpec dan hyperParameters terkait:
- Enkripsi: CMEK tidak tersedia untuk tugas distilasi yang melibatkan model pihak pertama Google.
epochCount: Dibatasi untuk nilai bilangan bulat antara 1 dan 100.learningRateMultiplier: Nilai harus berada dalam rentang floating point0.25-4.0.
- Patuhi batas berikut saat menentukan distillationSpec dan hyperParameters terkait:
- Distilasi satu langkah: Pengambilan sampel model pengajar dan penyesuaian model siswa berjalan dalam satu panggilan API. Jika Anda memiliki banyak data untuk diambil sampelnya, data yang sama harus diambil sampelnya lagi dalam penyesuaian berikutnya.
Mendapatkan akses
Jika Anda tertarik untuk bereksperimen dengan Gemini Distillation Service, hubungi tim Tuning Service kami di cloud-ai-tuning-service-support@google.com untuk meminta akses dan memasukkan project ke dalam daftar yang diizinkan.
Untuk memastikan performa dan pengelolaan resource yang optimal, sebaiknya buat project Google Cloud khusus untuk tugas penyulingan Anda. Saat menghubungi tim kami, berikan Project ID atau nomor project Anda untuk mempercepat proses pemberian izin.
Kebijakan Kuota dan Akses
Kuota dan kebijakan akses berikut berlaku:
Kapasitas: Project yang baru ditambahkan ke daftar yang diizinkan akan disediakan dengan kuota serentak default sebesar 4. Untuk mencegah perebutan resource, sebaiknya gunakan project terpisah, bukan project yang sudah menjalankan tugas penyesuaian Gemini lainnya.
Periode akses: Akses diberikan untuk periode awal 30 hari.