

O modelo e a ferramenta de uso do computador do Gemini permitem que seus aplicativos interajam e automatizem tarefas no navegador. Usando capturas de tela, o modelo e a ferramenta de uso do computador podem inferir informações sobre uma tela de computador e realizar ações gerando ações específicas da UI, como cliques do mouse e entradas do teclado. Assim como na chamada de função, você precisa escrever o código do aplicativo do lado do cliente para receber o modelo de uso de computador e a chamada de função da ferramenta e executar as ações correspondentes.
Com o modelo e a ferramenta de uso do computador, é possível criar agentes que podem:
- Automatizar a entrada de dados repetitivos ou o preenchimento de formulários em sites.
- Navegar em sites para coletar informações.
- Ajude os usuários realizando sequências de ações em aplicativos da Web.
Este guia aborda:
- Como o modelo e a ferramenta de uso de computadores funcionam
- Como ativar o modelo e a ferramenta de uso do computador
- Como enviar solicitações, receber respostas e criar loops de agente
- Quais ações de computador são compatíveis?
- Suporte de segurança e proteção
- Preços de pré-lançamento
Neste guia, pressupomos que você está usando o SDK de IA generativa para Python e conhece a API Playwright.
O modelo e a ferramenta de uso do computador estão indisponíveis nas outras linguagens do SDK ou no console Google Cloud durante este pré-lançamento.
Além disso, você pode conferir a implementação de referência do modelo e da ferramenta de uso do computador no GitHub.
Modelos compatíveis
O modelo e a ferramenta de uso do computador são compatíveis com os seguintes modelos:
Clique para abrir os modelos compatíveis
Como o modelo e a ferramenta de uso de computadores funcionam
Em vez de gerar respostas de texto, o modelo e a ferramenta de uso do computador determinam quando
realizar ações específicas da UI, como cliques do mouse, e retornam os parâmetros necessários
para executar essas ações. Você precisa escrever o código do aplicativo do lado do cliente para
receber o modelo e a ferramenta de uso do computador function_call e executar as ações correspondentes.
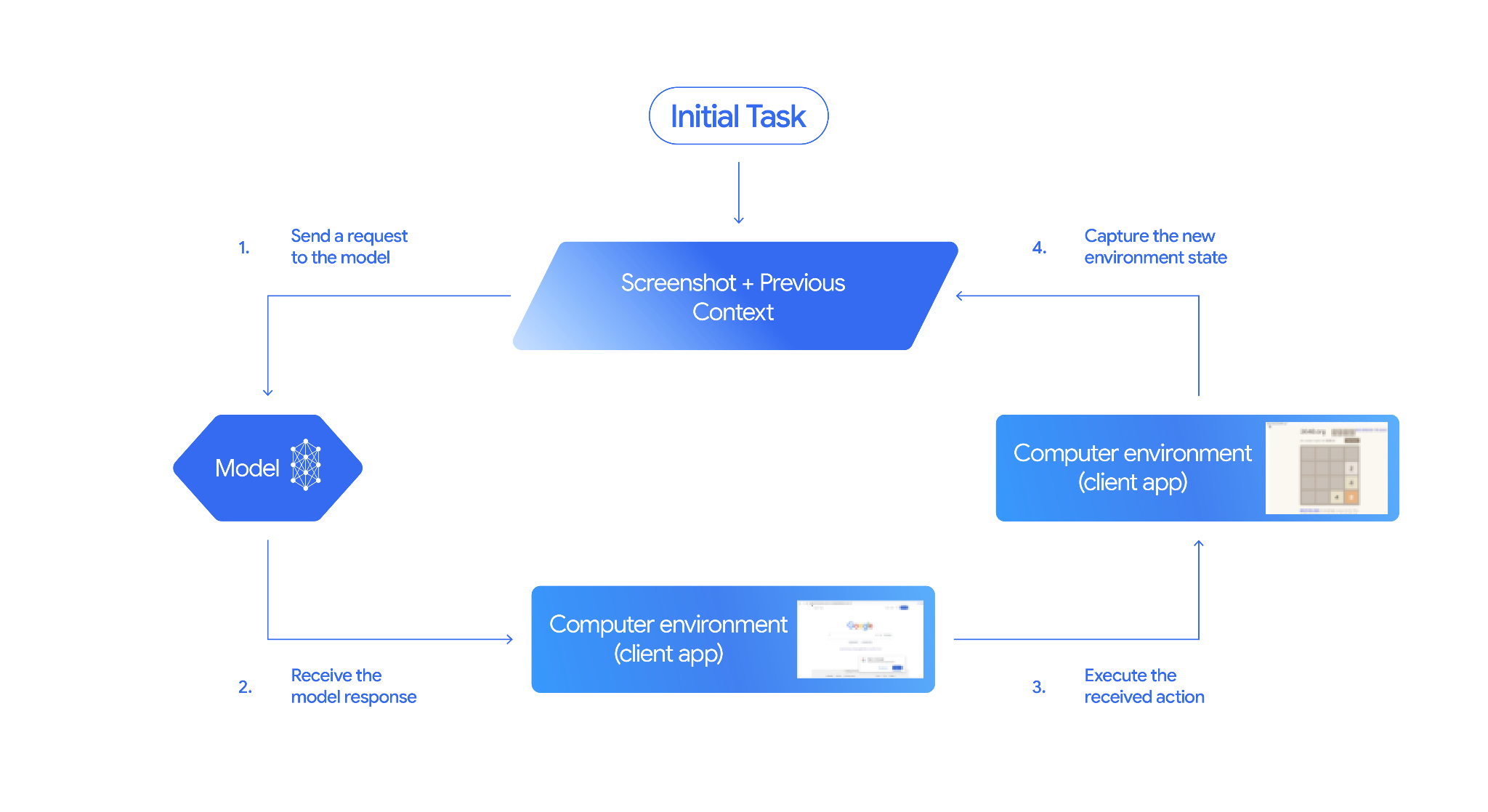
O modelo de uso do computador e as interações com ferramentas seguem um processo de loop de agente:
Enviar uma solicitação para o modelo
- Adicione o modelo e a ferramenta de uso do computador e, opcionalmente, outras ferramentas à sua solicitação de API.
- Comande o modelo e a ferramenta de uso do computador com o pedido do usuário e uma captura de tela que represente o estado atual da GUI.
Receber a resposta do modelo
- O modelo analisa a solicitação e a captura de tela do usuário e gera uma resposta que inclui um
function_callsugerido representando uma ação da UI (por exemplo, "clique na coordenada (x,y)" ou "digite 'texto'"). Consulte Ações compatíveis para ver a lista de todas as ações que você pode usar com o modelo. - A resposta da API também pode incluir um
safety_responsede um sistema de segurança interno que verificou a ação proposta pelo modelo. Estesafety_responseclassifica a ação como:- Regular ou permitida:a ação é considerada segura. Isso também pode ser representado pela ausência de
safety_response. - Requer confirmação:o modelo está prestes a realizar uma ação que pode ser arriscada (por exemplo, clicar em um banner "Aceitar cookies").
- Regular ou permitida:a ação é considerada segura. Isso também pode ser representado pela ausência de
- O modelo analisa a solicitação e a captura de tela do usuário e gera uma resposta que inclui um
Executar a ação recebida
- Seu código do lado do cliente recebe o
function_calle qualquersafety_responseacompanhante. - Se o
safety_responseindicar "regular" ou "permitido" (ou se nenhumsafety_responseestiver presente), seu código do lado do cliente poderá executar ofunction_callespecificado no ambiente de destino (como um navegador da Web). - Se o
safety_responseindicar que é necessária uma confirmação, seu aplicativo vai precisar pedir a confirmação do usuário final antes de executar ofunction_call. Se o usuário confirmar, execute a ação. Se o usuário negar, não execute a ação.
- Seu código do lado do cliente recebe o
Capturar o novo estado do ambiente
- Se a ação tiver sido executada, o cliente vai capturar uma nova captura de tela da GUI e o URL atual para enviar de volta ao modelo e à ferramenta de uso do computador como parte de um
function_response. - Se uma ação foi bloqueada pelo sistema de segurança ou teve a confirmação negada pelo usuário, seu aplicativo poderá enviar uma forma diferente de feedback ao modelo ou encerrar a interação.
- Se a ação tiver sido executada, o cliente vai capturar uma nova captura de tela da GUI e o URL atual para enviar de volta ao modelo e à ferramenta de uso do computador como parte de um
Uma nova solicitação é enviada ao modelo com o estado atualizado. O processo se repete desde a etapa 2, com o modelo e a ferramenta de uso do computador usando a nova captura de tela (se fornecida) e a meta em andamento para sugerir a próxima ação. O loop continua até que a tarefa seja concluída, ocorra um erro ou o processo seja encerrado (por exemplo, se uma resposta for bloqueada por filtros de segurança ou decisão do usuário).
O diagrama a seguir ilustra como o modelo e a ferramenta de uso de computador funcionam:
Ativar o modelo e a ferramenta de uso do computador
Para ativar o modelo e a ferramenta de uso do computador, use gemini-3-flash-preview
ou gemini-3.5-flash como modelo e adicione o modelo e a ferramenta de uso do computador à sua lista de ferramentas ativadas:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part, FunctionResponse client = genai.Client() # Add Computer Use model and tool to the list of tools generate_content_config = genai.types.GenerateContentConfig( tools=[ types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, ) ), ] ) # Example request using the Computer Use model and tool contents = [ Content( role="user", parts=[ Part(text="Go to google.com and search for 'weather in New York'"), ], ) ] response = client.models.generate_content( model="gemini-3-flash-preview", contents=contents, config=generate_content_config, )
Enviar uma solicitação
Depois de configurar o modelo e a ferramenta de uso do computador, envie um comando para o modelo que inclua a meta do usuário e uma captura de tela inicial da GUI.
Você também pode adicionar o seguinte:
- Ações excluídas:se houver ações da lista de ações da UI compatíveis que você não quer que o modelo execute, especifique-as em
excluded_predefined_functions. - Funções definidas pelo usuário:além do modelo e da ferramenta de uso de computadores, talvez você queira incluir funções personalizadas definidas pelo usuário.
O exemplo de código a seguir ativa o modelo e a ferramenta de uso de computador e envia a solicitação ao modelo:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part client = genai.Client() # Specify predefined functions to exclude (optional) excluded_functions = ["drag_and_drop"] # Configuration for the Computer Use model and tool with browser environment generate_content_config = genai.types.GenerateContentConfig( tools=[ # 1. Computer Use tool with browser environment types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, # Optional: Exclude specific predefined functions excluded_predefined_functions=excluded_functions ) ), # 2. Optional: Custom user-defined functions (need to defined above) # types.Tool( # function_declarations=custom_functions # ) ], ) # Create the content with user message contents: list[Content] = [ Content( role="user", parts=[ Part(text="Search for highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping. Create a bulleted list of the 3 cheapest options in the format of name, description, price in an easy-to-read layout."), # Optional: include a screenshot of the initial state # Part.from_bytes( # data=screenshot_image_bytes, # mime_type='image/png', # ), ], ) ] # Generate content with the configured settings response = client.models.generate_content( model='gemini-3-flash-preview', contents=contents, config=generate_content_config, ) # Print the response output print(response.text)
Você também pode incluir funções personalizadas definidas pelo usuário para estender a funcionalidade do modelo. Consulte Usar o modelo e a ferramenta de uso do computador para casos de uso móvel para saber como configurar o uso do computador para casos de uso móvel adicionando ações como open_app, long_press_at e go_home e excluindo ações específicas do navegador.
Receber respostas
O modelo responde com um ou mais FunctionCalls se determinar que são necessárias ações UI ou funções definidas pelo usuário para concluir a tarefa. O código do aplicativo precisa analisar e executar essas ações, além de coletar os resultados. O modelo e a ferramenta de uso de computador são compatíveis com a chamada de função paralela, ou seja, o modelo pode retornar várias ações independentes em uma única vez.
{
"content": {
"parts": [
{
"text": "I will type the search query into the search bar. The search bar is in the center of the page."
},
{
"function_call": {
"name": "type_text_at",
"args": {
"x": 371,
"y": 470,
"text": "highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping",
"press_enter": true
}
}
}
]
}
}
Dependendo da ação, a resposta da API também pode retornar um safety_response:
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
Executar ações recebidas
Depois de receber uma resposta, o modelo precisa executar as ações recebidas.
O código a seguir extrai chamadas de função de uma resposta do Gemini, converte coordenadas do intervalo de 0 a 1000 para pixels reais, executa ações do navegador usando o Playwright e retorna o status de sucesso ou falha de cada ação:
import time
from typing import Any, List, Tuple
def normalize_x(x: int, screen_width: int) -> int:
"""Convert normalized x coordinate (0-1000) to actual pixel coordinate."""
return int(x / 1000 * screen_width)
def normalize_y(y: int, screen_height: int) -> int:
"""Convert normalized y coordinate (0-1000) to actual pixel coordinate."""
return int(y / 1000 * screen_height)
def execute_function_calls(response, page, screen_width: int, screen_height: int) -> List[Tuple[str, Any]]:
"""
Extract and execute function calls from Gemini response.
Args:
response: Gemini API response object
page: Playwright page object
screen_width: Screen width in pixels
screen_height: Screen height in pixels
Returns:
List of tuples: [(function_name, result), ...]
"""
# Extract function calls and thoughts from the model's response
candidate = response.candidates[0]
function_calls = []
thoughts = []
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_calls.append(part.function_call)
elif hasattr(part, 'text') and part.text:
thoughts.append(part.text)
if thoughts:
print(f"Model Reasoning: {' '.join(thoughts)}")
# Execute each function call
results = []
for function_call in function_calls:
result = None
try:
if function_call.name == "open_web_browser":
print("Executing open_web_browser")
# Browser is already open via Playwright, so this is a no-op
result = "success"
elif function_call.name == "click_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
print(f"Executing click_at: ({actual_x}, {actual_y})")
page.mouse.click(actual_x, actual_y)
result = "success"
elif function_call.name == "type_text_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
text = function_call.args["text"]
press_enter = function_call.args.get("press_enter", False)
clear_before_typing = function_call.args.get("clear_before_typing", True)
print(f"Executing type_text_at: ({actual_x}, {actual_y}) text='{text}'")
# Click at the specified location
page.mouse.click(actual_x, actual_y)
time.sleep(0.1)
# Clear existing text if requested
if clear_before_typing:
page.keyboard.press("Control+A")
page.keyboard.press("Backspace")
# Type the text
page.keyboard.type(text)
# Press enter if requested
if press_enter:
page.keyboard.press("Enter")
result = "success"
else:
# For any functions not parsed above
print(f"Unrecognized function: {function_call.name}")
result = "unknown_function"
except Exception as e:
print(f"Error executing {function_call.name}: {e}")
result = f"error: {str(e)}"
results.append((function_call.name, result))
return results
Se o safety_decision retornado for require_confirmation, peça ao
usuário para confirmar antes de executar a ação. De acordo com os termos de serviço, não é permitido ignorar solicitações de confirmação humana.
O código a seguir adiciona lógica de segurança ao código anterior:
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true"
# ... Execute function call and append to results ...
Capturar o novo estado
Depois de executar as ações, envie o resultado da execução da função de volta ao modelo para que ele possa usar essas informações e gerar a próxima ação. Se várias ações (chamadas paralelas) foram executadas, envie um FunctionResponse para cada uma delas na próxima vez que o usuário falar. Para funções definidas pelo usuário, o FunctionResponse precisa conter o valor de retorno da função executada.
function_response_parts = []
for name, result in results:
# Take screenshot after each action
screenshot = page.screenshot()
current_url = page.url
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
# Create the user feedback content with all responses
user_feedback_content = Content(
role="user",
parts=function_response_parts
)
# Append this feedback to the 'contents' history list for the next API call
contents.append(user_feedback_content)
Criar um loop de agente
Combine as etapas anteriores em um loop para ativar interações de várias etapas. O loop precisa processar chamadas de função paralelas. Não se esqueça de gerenciar o histórico da conversa (matriz de conteúdo) corretamente, anexando as respostas do modelo e da função.
Python
from google import genai from google.genai.types import Content, Part from playwright.sync_api import sync_playwright def has_function_calls(response): """Check if response contains any function calls.""" candidate = response.candidates[0] return any(hasattr(part, 'function_call') and part.function_call for part in candidate.content.parts) def main(): client = genai.Client() # ... (config setup from "Send a request to model" section) ... with sync_playwright() as p: browser = p.chromium.launch(headless=False) page = browser.new_page() page.goto("https://www.google.com") screen_width, screen_height = 1920, 1080 # ... (initial contents setup from "Send a request to model" section) ... # Agent loop: iterate until model provides final answer for iteration in range(10): print(f"\nIteration {iteration + 1}\n") # 1. Send request to model (see "Send a request to model" section) response = client.models.generate_content( model='gemini-3-flash-preview', contents=contents, config=generate_content_config, ) contents.append(response.candidates[0].content) # 2. Check if done - no function calls means final answer if not has_function_calls(response): print(f"FINAL RESPONSE:\n{response.text}") break # 3. Execute actions (see "Execute the received actions" section) results = execute_function_calls(response, page, screen_width, screen_height) time.sleep(1) # 4. Capture state and create feedback (see "Capture the New State" section) contents.append(create_feedback(results, page)) input("\nPress Enter to close browser...") browser.close() if __name__ == "__main__": main()
Casos de uso do Gemini 3.5 Flash ou versões mais recentes em dispositivos móveis ou computadores
O modelo e a ferramenta de uso de computadores oferecem suporte à configuração de ambientes para dispositivos móveis (ENVIRONMENT_MOBILE),
computadores (ENVIRONMENT_DESKTOP) ou navegadores (ENVIRONMENT_BROWSER). O padrão é ENVIRONMENT_BROWSER.
Os exemplos a seguir demonstram como configurar o ambiente de execução para o modelo e a ferramenta de uso de computador com o Gemini 3.5 Flash ou versões mais recentes.
API REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: o ID do projeto.
Método HTTP e URL:
POST https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/global/publishers/google/models/gemini-3.5-flash:generateContent
Corpo JSON da solicitação:
{
"contents": [
{
"role": "user",
"parts": {
"text": "find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. start by navigating directly to flights.google.com"
}
}
],
"generation_config": {
"candidateCount": 1
},
"tools": [
{
"computer_use": {
"environment": "ENVIRONMENT_BROWSER"
}
}
]
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá um código de status bem-sucedido (2xx) e uma resposta vazia.
Python
O exemplo a seguir requer a versão 2.7.0 ou mais recente da biblioteca python-genai.
from google import genai
from google.genai.types import (
Part,
GenerateContentConfig,
Content,
Tool,
ComputerUse,
Environment,
ThinkingConfig,
)
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
Content(
role="user",
parts=[
Part(text="find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th"),
],
)
],
config=GenerateContentConfig(
temperature=1,
top_p=0.95,
top_k=40,
max_output_tokens=8192,
tools=[
Tool(
computer_use=ComputerUse(
environment=Environment.ENVIRONMENT_MOBILE
),
),
],
thinking_config=ThinkingConfig(
include_thoughts=True
),
)
)
Uso do Gemini 3 Flash em dispositivos móveis
O exemplo a seguir do Gemini 3 Flash demonstra como definir funções personalizadas (como open_app, long_press_at e go_home), combiná-las com a ferramenta integrada de uso do computador do Gemini e excluir funções desnecessárias específicas do navegador. Ao registrar essas funções personalizadas, o modelo pode
chamá-las de maneira inteligente junto com ações padrão da UI para concluir tarefas em
ambientes que não são navegadores.
from typing import Optional, Dict, Any
from google import genai
from google.genai import types
from google.genai.types import Content, Part
client = genai.Client()
def open_app(app_name: str, intent: Optional[str] = None) -> Dict[str, Any]:
"""Opens an app by name.
Args:
app_name: Name of the app to open (any string).
intent: Optional deep-link or action to pass when launching, if the app supports it.
Returns:
JSON payload acknowledging the request (app name and optional intent).
"""
return {"status": "requested_open", "app_name": app_name, "intent": intent}
def long_press_at(x: int, y: int, duration_ms: int = 500) -> Dict[str, int]:
"""Long-press at a specific screen coordinate.
Args:
x: X coordinate (absolute), scaled to the device screen width (pixels).
y: Y coordinate (absolute), scaled to the device screen height (pixels).
duration_ms: Press duration in milliseconds. Defaults to 500.
Returns:
Object with the coordinates pressed and the duration used.
"""
return {"x": x, "y": y, "duration_ms": duration_ms}
def go_home() -> Dict[str, str]:
"""Navigates to the device home screen.
Returns:
A small acknowledgment payload.
"""
return {"status": "home_requested"}
# Build function declarations
CUSTOM_FUNCTION_DECLARATIONS = [
types.FunctionDeclaration.from_callable(client=client, callable=open_app),
types.FunctionDeclaration.from_callable(client=client, callable=long_press_at),
types.FunctionDeclaration.from_callable(client=client, callable=go_home),
]
# Exclude browser functions
EXCLUDED_PREDEFINED_FUNCTIONS = [
"open_web_browser",
"search",
"navigate",
"hover_at",
"scroll_document",
"go_forward",
"key_combination",
"drag_and_drop",
]
# Utility function to construct a GenerateContentConfig
def make_generate_content_config() -> genai.types.GenerateContentConfig:
"""Return a fixed GenerateContentConfig with Computer Use + custom functions."""
return genai.types.GenerateContentConfig(
tools=[
types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER,
excluded_predefined_functions=EXCLUDED_PREDEFINED_FUNCTIONS,
)
),
types.Tool(function_declarations=CUSTOM_FUNCTION_DECLARATIONS),
]
)
# Create the content with user message
contents: list[Content] = [
Content(
role="user",
parts=[
# text instruction
Part(text="Open Chrome, then long-press at 200,400."),
# optional screenshot attachment
Part.from_bytes(
data=screenshot_image_bytes,
mime_type="image/png",
),
],
)
]
# Build your fixed config (from helper)
config = make_generate_content_config()
# Generate content with the configured settings
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=contents,
config=generate_content_config,
)
print(response)
Ações permitidas
O modelo e a ferramenta de uso de computador permitem que o modelo solicite as seguintes
ações usando um FunctionCall. O código do lado do cliente precisa implementar a lógica de execução dessas ações. Confira exemplos na implementação de referência. A tabela a seguir mostra as ações compatíveis com o ambiente do navegador.
O Gemini 3 Flash e o Gemini 3.5 Flash têm conjuntos de nomes FunctionCall diferentes.
Gemini 3.5 Flash
| Nome do comando | Descrição | Argumentos (na chamada de função) |
|---|---|---|
| click | Clique com o botão esquerdo na coordenada. |
y: int (0-999)x: int
(0-999)intent: str
|
| double_click | Clique duas vezes na coordenada. |
y: int (0-999)x: int
(0-999)intent: str
|
| triple_click | Clica três vezes na coordenada. |
y: int (0-999)x: int
(0-999)intent: str
|
| middle_click | Clique com o botão do meio na coordenada. |
y: int (0-999)x: int
(0-999)intent: str
|
| right_click | Clica com o botão direito do mouse na coordenada. |
y: int (0-999)x: int
(0-999)intent: str
|
| mouse_down | Toca e mantém pressionado o botão do mouse na coordenada. |
y: int (0-999)x: int
(0-999)intent: str
|
| mouse_up | Solta o botão do mouse na coordenada. |
y: int (0-999)x: int
(0-999)intent: str
|
| move | Mova o cursor para a posição especificada. |
y: int (0-999)x: int
(0-999)intent: str
|
| type | Digita texto. |
text: strintent:
strpress_enter: bool (opcional, o padrão é "false")
|
| drag_and_drop | Arrasta o item de start_y e start_x para end_y e end_x |
start_y: int (0-999)start_x: int
(0-999)end_y: int (0-999)end_x:
int (0-999)intent: str
|
| wait | Aguarde o número de segundos especificado. |
intent: strseconds: int (opcional, padrão 1)
|
| press_key | Pressiona e solta a tecla especificada. | key: strintent: str |
| key_down | Pressiona e mantém pressionada a tecla especificada. | key: strintent: str |
| key_up | Libera a chave especificada. | key: strintent: str |
| tecla de atalho | Pressiona a combinação de teclas especificada. | keys: List[str]intent: str |
| take_screenshot | Retorna uma captura de tela da tela atual. | intent: str |
| scroll | Rola para cima, para baixo, para a esquerda ou para a direita em uma coordenada por uma distância de pixel. |
y: int (0-999)x: int
(0-999)direction: str ("up", "down", "left",
"right")intent:
strmagnitude_in_pixels: int (0-999, opcional,
padrão 300)
|
| go_back | Volta para a página da Web anterior no histórico do navegador. | intent: str |
| navigate | Navega diretamente para um URL especificado. | url: strintent: str |
| go_forward | Navega para a próxima página da Web no histórico do navegador. | intent: str |
Gemini 3 Flash
| Nome do comando | Descrição | Argumentos (na chamada de função) | Exemplo de chamada de função |
|---|---|---|---|
| open_web_browser | Abre o navegador da Web. | Nenhum | {"name": "open_web_browser", "args": {}} |
| wait_5_seconds | Pausa a execução por 5 segundos para permitir que o conteúdo dinâmico seja carregado ou que as animações sejam concluídas. | Nenhum | {"name": "wait_5_seconds", "args": {}} |
| go_back | Navega para a página anterior no histórico do navegador. | Nenhum | {"name": "go_back", "args": {}} |
| go_forward | Navega para a próxima página no histórico do navegador. | Nenhum | {"name": "go_forward", "args": {}} |
| search | Navega até a página inicial do mecanismo de pesquisa padrão (por exemplo, o Google). Útil para iniciar uma nova tarefa de pesquisa. | Nenhum | {"name": "search", "args": {}} |
| navigate | Navega o navegador diretamente para o URL especificado. | url: str |
{"name": "navigate", "args": {"url": "https://www.wikipedia.org"}}
|
| click_at | Clica em uma coordenada específica na página da Web. Os valores x e y são baseados em uma grade de 1000 x 1000 e são dimensionados para as dimensões da tela. | y: int (0-999), x: int (0-999) |
{"name": "click_at", "args": {"y": 300, "x": 500}}
|
| hover_at | 521963309 Passa o cursor do mouse em uma coordenada específica na página da Web. Útil para revelar submenus. x e y são baseados em uma grade de 1000x1000. | y: int (0-999) x: int (0-999) |
{"name": "hover_at", "args": {"y": 150, "x": 250}}
|
| type_text_at | Digita texto em uma coordenada específica. Por padrão, limpa o campo primeiro e pressiona ENTER depois de digitar, mas isso pode ser desativado. x e y são baseados em uma grade de 1000 x 1000. |
y: int (0 a 999), x: int (0 a 999),
text: str, press_enter: bool (opcional,
padrão True), clear_before_typing: bool (opcional,
padrão True)
|
{"name": "type_text_at", "args": {"y": 250, "x": 400,
"text": "search query", "press_enter": false}}
|
| key_combination | Pressiona teclas ou combinações de teclas do teclado, como "Control+C" ou "Enter". Útil para acionar ações (como enviar um formulário com "Enter") ou operações da área de transferência. |
keys: str (por exemplo, "enter", "control+c". Consulte a referência da API para ver a lista completa de chaves permitidas.
|
{"name": "key_combination", "args": {"keys":
"Control+A"}}
|
| scroll_document | Rola toda a página da Web para "cima", "baixo", "esquerda" ou "direita". | direction: str ("up", "down", "left" ou "right") |
{"name": "scroll_document", "args": {"direction": "down"}}
|
| scroll_at | Rola um elemento ou área específica na coordenada (x, y) na direção especificada por uma determinada magnitude. As coordenadas e a magnitude (padrão 800) são baseadas em uma grade de 1.000 x 1.000. |
y: int (0-999), x: int (0-999),
direction: str ("up", "down", "left", "right"),
magnitude: int (0-999, opcional, padrão 800)
|
{"name": "scroll_at", "args": {"y": 500, "x": 500,
"direction": "down", "magnitude": 400}}
|
| drag_and_drop | Arrasta um elemento de uma coordenada inicial (x, y) e o solta em uma coordenada de destino (destination_x, destination_y). Todas as coordenadas são baseadas em uma grade de 1000 x 1000. |
y: int (0-999), x: int (0-999),
destination_y: int (0-999),
destination_x: int (0-999)
|
{"name": "drag_and_drop", "args": {"y": 100, "x": 100,
"destination_y": 500, "destination_x": 500}}
|
Gemini 3.5 Flash: você tem acesso a diferentes conjuntos de chamadas de função dependendo do ambiente selecionado:
Ambiente para dispositivos móveis
| Nome do comando | Descrição | Argumentos (na chamada de função) |
|---|---|---|
| open_app | Abre um aplicativo pelo nome. | intent: str |
| clique | Clique com o botão esquerdo na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| list_apps | Lista os aplicativos disponíveis no dispositivo, retornando os nomes e nomes de pacotes. | intent: str |
| wait | Aguarde o número especificado de segundos. |
intent: str seconds: int(Optional, default 1) |
| go_back | Volta para a página da Web anterior no histórico do navegador. | intent: str |
| tipo | Digita texto. |
text: str intent: str press_enter: bool(Optional, default false) |
| drag_and_drop | Arrasta o item de start_y e start_x para end_y e end_x |
start_y: int (0-999) start_x: int (0-999) end_y: int (0-999) end_x: int (0-999) intent: str |
| long_press | Realiza um toque longo em uma coordenada y (0 a 999) e x (0 a 999) específica na tela. |
y: int (0-999) x: int (0-999) intent: str seconds: int (opcional, padrão é 2) |
| press_key | Pressiona e solta a tecla especificada. |
key: str intent: str |
| take_screenshot | Retorna uma captura de tela da tela atual. | intent: str |
Ambiente de desktop
| Nome do comando | Descrição | Argumentos (na chamada de função) |
|---|---|---|
| clique | Clique com o botão esquerdo na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| double_click | Clique duas vezes na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| triple_click | Clica três vezes na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| middle_click | Clique com o botão do meio na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| right_click | Clica com o botão direito do mouse na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| mouse_down | Toca e mantém pressionado o botão do mouse na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| mouse_up | Solta o botão do mouse na coordenada. |
y: int (0-999) x: int (0-999) intent: str |
| move | Mova o cursor para a posição especificada. |
y: int (0-999) x: int (0-999) intent: str |
| tipo | Digita texto. |
text: str intent: str press_enter: bool(Optional, default false) |
| drag_and_drop | Arrasta o item de start_y e start_x para end_y e end_x. |
start_y: int (0-999) start_x: int (0-999) end_y: int (0-999) end_x: int (0-999) intent: str |
| wait | Aguarde o número de segundos especificado. |
intent: str seconds: int(Optional, default 1) |
| press_key | Pressiona e solta a tecla especificada. |
key: str intent: str |
| key_down | Pressiona e mantém pressionada a tecla especificada. |
key: str intent: str |
| key_up | Libera a chave especificada. |
key: str intent: str |
| tecla de atalho | Pressiona a combinação de teclas especificada. |
keys: List[str] intent: str |
| take_screenshot | Retorna uma captura de tela da tela atual. | intent: str |
| rolar | Rola para cima, para baixo, para a esquerda ou para a direita em uma coordenada por uma distância de pixel. |
y: int (0-999) x: int (0-999) direction: str ("up", "down", "left", "right") intent: str magnitude_in_pixels: int (0-999, Optional, default 300) |
Segurança e proteção
Esta seção descreve as proteções que o modelo e a ferramenta de uso de computadores têm para melhorar o controle do usuário e a segurança. Também descreve as práticas recomendadas para reduzir possíveis novos riscos que a ferramenta possa apresentar.
Confirmar decisão de segurança
Dependendo da ação, a resposta do modelo e da ferramenta de uso do computador pode incluir uma
safety_decision de um sistema de segurança interno. Essa decisão verifica a ação proposta pela ferramenta para segurança.
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
Se o safety_decision for require_confirmation, peça ao usuário final para confirmar antes de executar a ação.
O exemplo de código a seguir pede confirmação ao usuário antes de executar a
ação. Se o usuário não confirmar a ação, o loop será encerrado. Se o usuário
confirmar a ação, ela será executada e o campo safety_acknowledgement
será marcado como True.
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true" # Safety acknowledgement
# ... Execute function call and append to results ...
Se o usuário confirmar, inclua a declaração de segurança no seu FunctionResponse.
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url,
**extra_fr_fields}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
Detecção de injeção de comandos
O modelo e a ferramenta Computer Use para o Gemini 3.5 Flash ou versões mais recentes oferecem um mecanismo de segurança avançado para detectar ataques de injeção de comandos. Quando ativado, esse recurso verifica se uma captura de tela incluída pode causar um ataque de injeção de comandos. É possível definir esse recurso na configuração do modelo e da ferramenta de uso de computadores. O padrão é false.
Os exemplos a seguir demonstram como ativar o modelo de uso de computadores e a configuração de ferramentas para ativar a detecção de injeção de comandos:
API REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- PROJECT_ID: o ID do projeto.
Método HTTP e URL:
POST https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/global/publishers/google/models/gemini-3.5-flash:generateContent
Corpo JSON da solicitação:
{
"contents": [
{
"role": "user",
"parts": {
"text": "find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. start by navigating directly to flights.google.com"
}
}
],
"generation_config": {
"candidateCount": 1
},
"tools": [
{
"computer_use": {
"environment": "ENVIRONMENT_BROWSER",
"enable_prompt_injection_detection": true
}
}
]
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá um código de status bem-sucedido (2xx) e uma resposta vazia.
Python
O exemplo a seguir requer a versão 2.7.0 ou mais recente da biblioteca python-genai.
from google import genai
from google.genai.types import (
Part,
GenerateContentConfig,
Content,
Tool,
ComputerUse,
Environment,
ThinkingConfig,
)
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
Content(
role="user",
parts=[
Part(text="find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th"),
],
)
],
config=GenerateContentConfig(
temperature=1,
top_p=0.95,
top_k=40,
max_output_tokens=8192,
tools=[
Tool(
computer_use=ComputerUse(
environment=Environment.ENVIRONMENT_MOBILE,
enable_prompt_injection_detection=True
),
),
],
thinking_config=ThinkingConfig(
include_thoughts=True
),
)
)
Práticas recomendadas de segurança
O modelo e a ferramenta de uso de computadores são novidades e apresentam novos riscos que os desenvolvedores precisam conhecer:
- Conteúdo e golpes não confiáveis:ao tentar alcançar a meta do usuário, o modelo pode usar fontes de informações e instruções não confiáveis da tela. Por exemplo, se a meta do usuário for comprar um smartphone Pixel e o modelo encontrar um golpe de "Pixel sem custo financeiro se você responder a uma pesquisa", há alguma chance de que o modelo responda à pesquisa.
- Ações ocasionais não intencionais:o modelo pode interpretar mal a meta de um usuário ou o conteúdo da página da Web, fazendo com que ele realize ações incorretas, como clicar no botão errado ou preencher o formulário errado. Isso pode levar a falhas nas tarefas ou exfiltração de dados.
- Violações da política:os recursos da API podem ser direcionados, intencionalmente ou não, a atividades que violam os termos e as políticas do Google. Isso inclui ações que podem interferir na integridade de um sistema, comprometer a segurança, burlar medidas de segurança, como CAPTCHAs, controlar dispositivos médicos etc.
Para reduzir esses riscos, implemente as seguintes medidas de segurança e práticas recomendadas:
- Human-in-the-loop (HITL):
- Implemente a confirmação do usuário:quando a resposta de segurança indicar require_confirmation, implemente a confirmação do usuário antes da execução.
- Fornecer instruções de segurança personalizadas:além das verificações de confirmação do usuário integradas, os desenvolvedores podem adicionar uma instrução de sistema personalizada que aplique as próprias políticas de segurança, seja para bloquear determinadas ações do modelo ou exigir confirmação do usuário antes que o modelo execute determinadas ações irreversíveis de alto risco. Confira um exemplo de instrução personalizada do sistema de segurança que você pode incluir ao interagir com o modelo.
Clique para conferir um exemplo de como criar uma conexão
## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask th e user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in these cases: - User confirmation - When the task is complete or you have enough information to respond to the user
- Ambiente de execução seguro:execute o agente em um ambiente seguro e em sandbox para limitar o impacto potencial dele. Por exemplo, uma máquina virtual (VM) em sandbox, um contêiner (como o Docker) ou um perfil de navegador dedicado com permissões limitadas.
- Sanitização de entrada:sanitizar todo o texto gerado pelo usuário em comandos para reduzir o risco de instruções não intencionais ou injeção de comando. Essa é uma camada útil de segurança, mas não substitui um ambiente de execução seguro.
- Listas de permissões e de bloqueio:implemente mecanismos de filtragem para controlar onde o modelo pode navegar e o que ele pode fazer. Uma lista de bloqueio de sites proibidos é um bom ponto de partida, mas uma lista de permissões mais restritiva é ainda mais segura.
- Observabilidade e geração de registros:mantenha registros detalhados para depuração, auditoria e resposta a incidentes. O cliente precisa registrar solicitações,
capturas de tela, ações sugeridas pelo modelo (
function_call), respostas de segurança e todas as ações executadas pelo cliente.
Preços
O modelo e a ferramenta de uso de computadores têm os mesmos preços do Gemini e usam as mesmas SKUs. Para dividir os custos do modelo e da ferramenta de uso do computador, use rótulos de metadados personalizados. Para mais informações sobre como usar rótulos de metadados personalizados para monitoramento de custos, consulte Rótulos de metadados personalizados.