

Dieser Leitfaden für Einsteiger ist eine Einführung in das Abrufen von Inferenzen aus benutzerdefinierten Modellen auf der Gemini Enterprise Agent Platform.
Lernziele
Gemini Enterprise Agent Platform-Erfahrungsstufe: Einsteiger
Geschätzte Lesezeit: 15 Minuten
Lerninhalte:
- Vorteile der Verwendung eines verwalteten Inferenzdienstes
- So funktionieren Batchinferenzen in der Gemini Enterprise Agent Platform.
- Funktionsweise von Onlineinferenzen in der Agent Platform
Warum sollte ich einen verwalteten Inferenzdienst verwenden?
Stellen Sie sich vor, Sie sollen mit einem Modell arbeiten, in das das Bild einer Pflanze eingegeben wird, und das dann deren Art prognostiziert. Sie können besipielsweise zuerst ein Modell in einem Notebook trainieren und verschiedene Hyperparameter und Architekturen ausprobieren. Wenn Sie ein trainiertes Modell haben, können Sie die predict-Methode in Ihrem ML-Framework Ihrer Wahl aufrufen und die Modellqualität testen.
Dieser Workflow eignet sich hervorragend zum Experimentieren. Wenn Sie aber das Modell verwenden möchten, um Inferenzen für große Datenmengen oder im laufenden Betrieb Inferenzen mit niedriger Latenz zu erhalten, benötigen Sie etwas mehr als ein Notebook. Beispiel: Sie versuchen, die biologische Vielfalt eines bestimmten Ökosystems zu messen und wollen nicht, dass Menschen Pflanzenarten vor Ort bestimmen und zählen müssen, sondern wollen das ML-Modell nutzen, um große Mengen Bilder zu klassifizieren. Wenn Sie ein Notebook verwenden, können Sie in Sachen Speicher Probleme erhalten. Darüber hinaus ist das Abrufen von Inferenzen für alle diese Daten wahrscheinlich ein Job, der lange Zeit benötigt, was möglicherweise in Ihrem Notebook zu einer Zeitüberschreitung führt.
Oder Sie wollen dieses Modell in einer Anwendung verwenden, in die Nutzer Bilder von Pflanzen hochladen können, die dann sofort bestimmt werden. Sie benötigen einen Ort, an dem das Modell außerhalb eines Notebooks gehostet werden kann, und auf den Ihre Anwendung für Inferenzen zugreifen kann. Außerdem ist ein konsistenter Traffic zu Ihrem Modell unwahrscheinlich. Daher benötigen Sie einen Dienst, der bei Bedarf automatisch skaliert werden kann.
In all diesen Fällen reduziert ein verwalteter Inferenzdienst die Probleme, die beim Hosting und der Verwendung Ihrer ML-Modelle anfallen. Diese Anleitung bietet eine Einführung in das Abrufen von Inferenzen aus ML-Modellen auf der Gemini Enterprise Agent Platform. Beachten Sie, dass es zusätzliche Anpassungen, Funktionen und Möglichkeiten zur Nutzung des Dienstes gibt, die hier nicht behandelt werden. Dieser Leitfaden bietet einen Überblick. Weitere Informationen finden Sie in der Dokumentation zu Inferenzierungen der Gemini Enterprise Agent Platform.
Verwalteter Inferenzdienst – Übersicht
Die Agent Platform unterstützt Batch- und Onlineinferenzen.
Batchinferenz ist eine asynchrone Anfrage. Sie eignet sich gut, wenn Sie nicht sofort eine Antwort benötigen und akkumulierte Daten in einer einzigen Anfrage verarbeiten möchten. In dem in der Einführung beschriebenen Beispiel ist dies der Anwendungsfall, in dem die biologische Vielfalt charakterisiert wird.
Wenn Sie Inferenz mit niedriger Latenz auf Basis von Daten erhalten möchten, die direkt an Ihr Modell übergeben werden, können Sie die Online-Inferenz nutzen. Im in der Einführung beschriebenen Beispiel wäre dies der Anwendungsfall, in dem Sie Ihr Modell in eine App einbetten möchten, mit der Nutzer Pflanzenarten in Echtzeit identifizieren können.
Modell in die Gemini Enterprise Agent Platform Model Registry hochladen
Um den Inferenzdienst verwenden zu können, müssen Sie zuerst Ihr trainiertes ML-Modell in die Modell-Registry hochladen. Dies ist eine Registry, in der Sie den Lebenszyklus Ihrer Modelle verwalten können.
Eine Modellressource erstellen
Wenn Sie Modelle mit dem benutzerdefinierten Trainingsdienst der Gemini Enterprise Agent Platform trainieren, kann Ihr Modell nach Abschluss des Trainingsjobs automatisch in die Registry importiert werden. Wenn Sie diesen Schritt übersprungen oder Ihr Modell außerhalb der Gemini Enterprise Agent Platform trainiert haben, können Sie es manuell über die Google Cloud Console oder das Agent Platform SDK für Python hochladen. Verweisen Sie dazu auf einen Cloud Storage-Speicherort mit Ihren gespeicherten Modellartefakten. Das Format dieser Modellartefakte kann je nach verwendetem ML-Framework savedmodel.pb oder model.joblib sein.
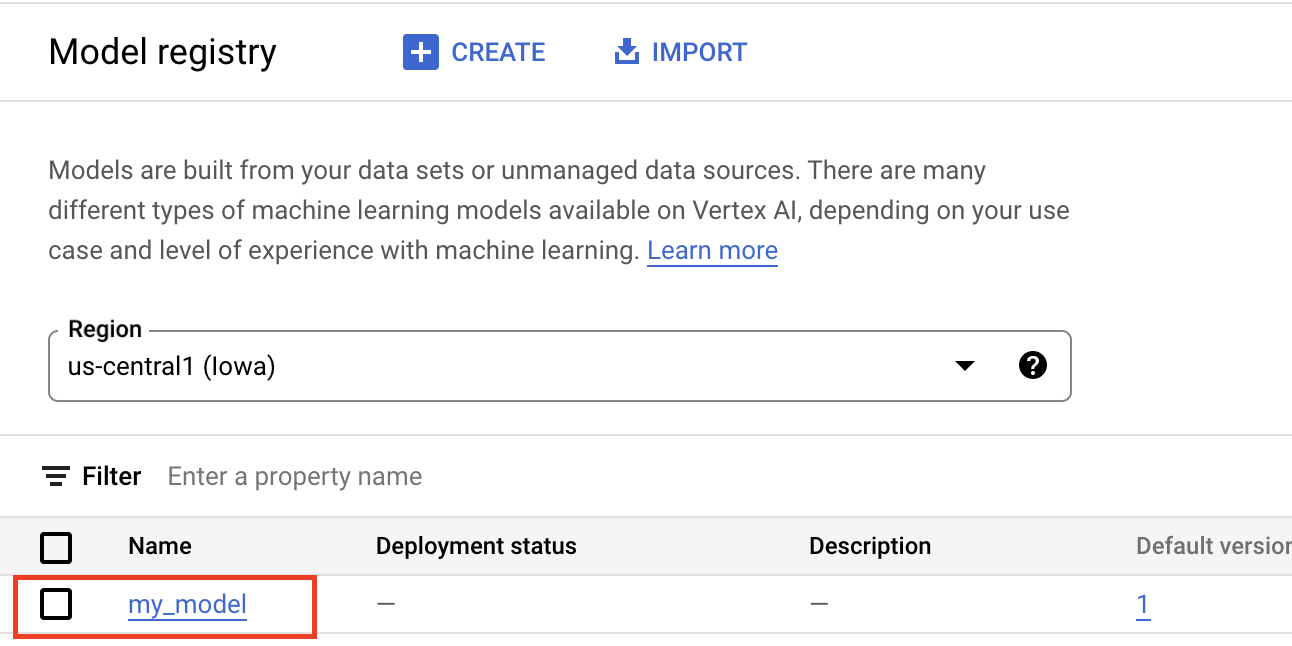
Beim Hochladen von Artefakten in die Gemini Enterprise Agent Platform Model Registry wird eine Model-Ressource erstellt, die in der Google Cloud Console sichtbar ist:
Einen Container wählen
Wenn Sie ein Modell in die Gemini Enterprise Agent Platform Model Registry importieren, müssen Sie es mit einem Container verknüpfen, damit die Gemini Enterprise Agent Platform Inferenzanfragen verarbeiten kann.
Vordefinierte Container
Die Gemini Enterprise Agent Platform bietet vorgefertigte Container, die Sie für Inferenzen verwenden können. Die vordefinierten Container sind nach ML-Framework und Framework-Version organisiert und stellen HTTP-Inferenzserver bereit, mit denen Sie Inferenzanfragen mit minimaler Konfiguration bereitstellen können. Sie führen nur den Inferenzvorgang des Frameworks für maschinelles Lernen aus. Wenn Sie Ihre Daten vorverarbeiten müssen, muss dies vor dem Inferenzanfrage erfolgen. Ebenso muss jede Nachbearbeitung nach Ausführen der Inferenzanfrage erfolgen. Ein Beispiel für die Verwendung eines vordefinierten Containers finden Sie im Notebook PyTorch-Bildmodelle mit vordefinierten Containern auf der Agent Platform bereitstellen.
Benutzerdefinierte Container
Wenn für Ihren Anwendungsfall Bibliotheken erforderlich sind, die nicht in den vordefinierten Containern enthalten sind, oder wenn benutzerdefinierte Datentransformationen vorliegen, die Sie als Teil der Inferenzanfrage ausführen möchten, können Sie einen benutzerdefinierten Container verwenden, den Sie erstellen und per Push in Artifact Registry übertragen. Benutzerdefinierte Container ermöglichen eine größere Anpassung, aber der Container muss einen HTTP-Server ausführen. Insbesondere muss der Container Aktivitätsprüfungen, Systemdiagnosen und Inferenzanfragen überwachen und darauf reagieren. In den meisten Fällen wird empfohlen, nach Möglichkeit einen vordefinierten Container zu verwenden. Ein Beispiel für die Verwendung eines benutzerdefinierten Containers finden Sie im Notebook PyTorch-Image-Klassifizierung: Einzelne GPU mit Vertex-Training und einem benutzerdefinierten Container.
Benutzerdefinierte Inferenzroutinen
Wenn Ihr Anwendungsfall benutzerdefinierte Vor- und Nachverarbeitungstransformationen erfordert und Sie den Aufwand für das Erstellen und Verwalten eines benutzerdefinierten Containers vermeiden möchten, können Sie benutzerdefinierte Inferenzroutinen verwenden. Mit benutzerdefinierten Inferenzroutinen können Sie Datentransformationen als Python-Code bereitstellen. Hinter den Kulissen erstellt das Agent Platform SDK für Python einen benutzerdefinierten Container, den Sie lokal testen und auf der Gemini Enterprise Agent Platform bereitstellen können. Ein Beispiel für die Verwendung benutzerdefinierter Inferenzroutinen finden Sie im Notebook Benutzerdefinierte Inferenzroutinen mit Sklearn.
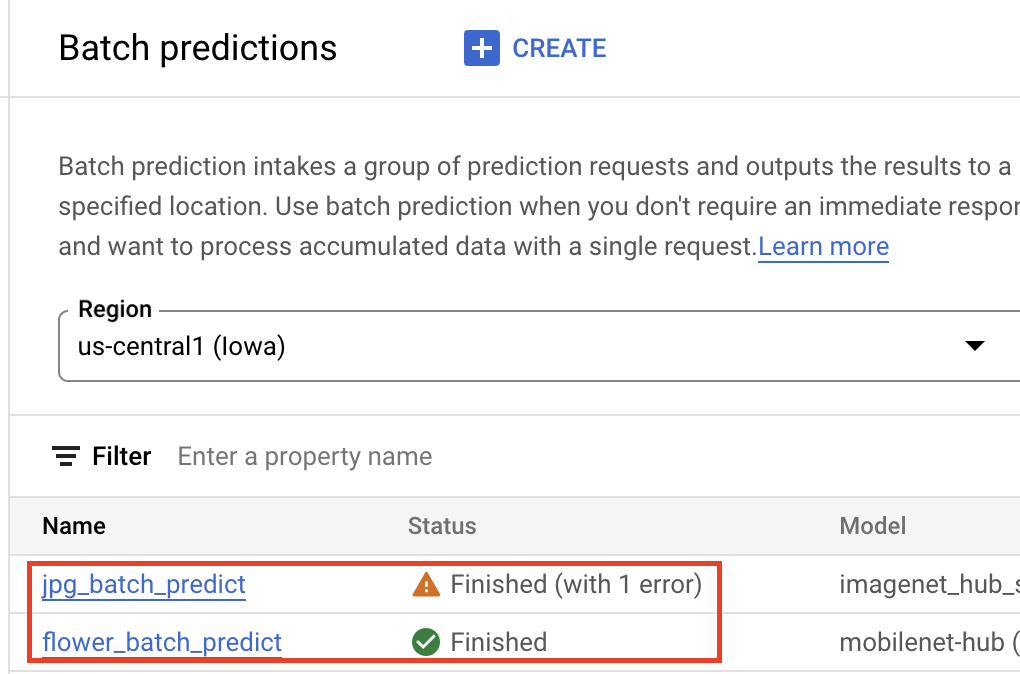
Batchinferenzen abrufen
Sobald sich Ihr Modell in der Gemini Enterprise Agent Platform Model Registry befindet, können Sie einen Batch-Inferenzjob über die Google Cloud Console oder das Agent Platform SDK für Python senden. Sie geben den Speicherort der Quelldaten und den Speicherort in Cloud Storage oder BigQuery an, an dem die Ergebnisse gespeichert werden sollen. Sie können auch den Maschinentyp, auf dem dieser Job ausgeführt werden soll, sowie optionale Beschleuniger angeben. Da der Inferenzdienst vollständig verwaltet ist, stellt die Gemini Enterprise Agent Platform automatisch Rechenressourcen bereit, führt die Inferenzaufgabe aus und sorgt für das Löschen von Rechenressourcen, sobald der Inferenzjob abgeschlossen ist. Der Status Ihrer Batchinferenzjobs kann in der Google Cloud -Konsole verfolgt werden.
Onlineinferenzen abrufen
Wenn Sie Onlineinferenzen erhalten möchten, müssen Sie Ihr Modell zusätzlich auf einem Gemini Enterprise Agent Platform-Endpunkt bereitstellen.
Dadurch werden die Modellartefakte mit physischen Ressourcen für eine Bereitstellung mit niedriger Latenz verknüpft. Weiter wird eine DeployedModel-Ressource erstellt.
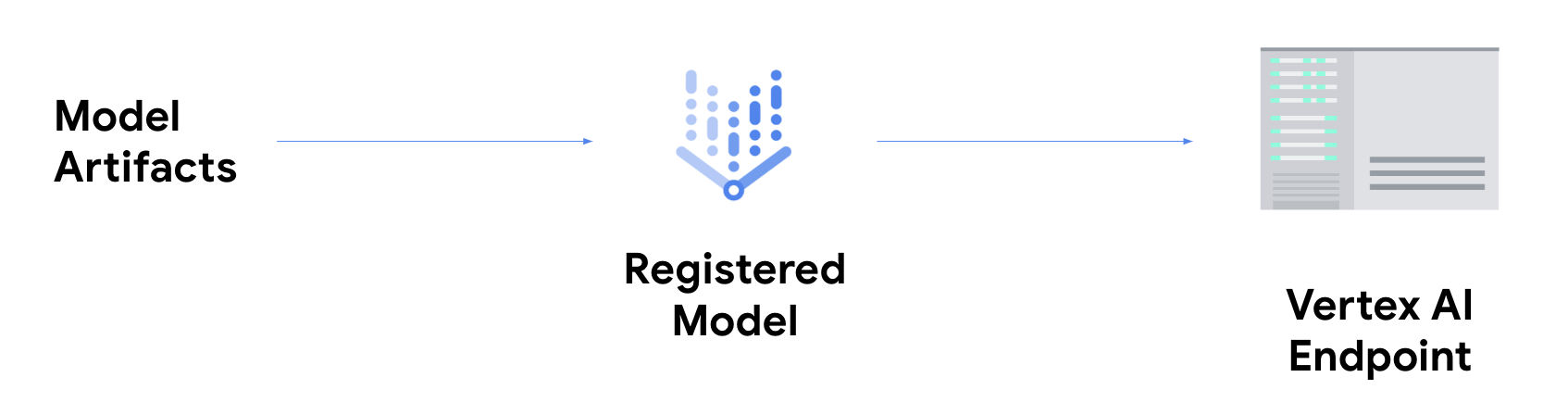
Sobald das Modell auf einem Endpunkt bereitgestellt wurde, akzeptiert es Anfragen wie jeder beliebige andere REST-Endpunkt. Das bedeutet, dass Sie es von einer Cloud Run-Funktion, einem Chatbot, einer Web-App usw. aufrufen können. Beachten Sie, dass Sie mehrere Modelle auf einem einzelnen Endpunkt bereitstellen und den Traffic unter diesen aufteilen können. Diese Funktion ist beispielsweise nützlich, wenn Sie eine neue Modellversion bereitstellen, aber nicht sofort den gesamten Traffic an das neue Modell weiterleiten möchten. Sie können auch dasselbe Modell auf mehreren Endpunkten bereitstellen.
Ressourcen zum Abrufen von Inferenzen aus benutzerdefinierten Modellen auf der Agent Platform
Weitere Informationen zum Hosten und Bereitstellen von Modellen auf der Agent Platform finden Sie in den folgenden Ressourcen oder im GitHub-Repository für Agent Platform-Beispiele.
- Video: Vorhersagen
- TensorFlow-Modell mit einem vordefinierten Container trainieren und bereitstellen
- PyTorch-Bildmodelle mit vordefinierten Containern auf der Agent Platform bereitstellen
- Stable Diffusion-Modell mit einem vordefinierten Container bereitstellen
- Benutzerdefinierte Inferenzroutinen mit Sklearn