

Ray-Cluster auf der Gemini Enterprise Agent Platform bieten zwei Skalierungsoptionen: Autoscaling und manuelle Skalierung. Beim Autoscaling kann der Cluster die Anzahl der Worker-Knoten automatisch an die Ressourcen anpassen, die von den Ray-Aufgaben und ‑Actors benötigt werden. Wenn Sie eine hohe Arbeitslast ausführen und sich nicht sicher sind, welche Ressourcen erforderlich sind, wird Autoscaling empfohlen. Die manuelle Skalierung bietet Nutzern eine detailliertere Kontrolle über die Knoten.
Das Autoscaling kann die Kosten für Arbeitslasten senken, führt aber zu einem zusätzlichen Aufwand beim Starten von Knoten und kann schwierig zu konfigurieren sein. Wenn Sie Ray zum ersten Mal verwenden, sollten Sie mit Clustern ohne Autoscaling beginnen und die manuelle Skalierungsfunktion verwenden.
Autoscaling
Sie können die Autoscaling-Funktion eines Ray-Clusters aktivieren, indem Sie die minimale (min_replica_count) und maximale (max_replica_count) Anzahl von Replicas für einen Worker-Pool angeben.
Wichtige Hinweise:
- Konfigurieren Sie die Autoscaling-Spezifikation aller Worker-Pools.
- Benutzerdefinierte Geschwindigkeit für Upscaling und Downscaling wird nicht unterstützt. Standardwerte finden Sie in der Ray-Dokumentation unter Upscaling- und Downscaling-Geschwindigkeit.
Autoscaling-Spezifikation für Worker-Pool festlegen
Verwenden Sie die Google Cloud -Konsole oder das Agent Platform SDK für Python, um die Funktion zur automatischen Skalierung eines Ray-Clusters zu aktivieren.
Ray on Agent Platform SDK
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Gemini Enterprise Agent Platform CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
Console
Gemäß der Best Practice für OSS Ray wird die Festlegung der logischen CPU-Anzahl auf 0 auf dem Ray-Hauptknoten erzwungen, um zu vermeiden, dass Arbeitslasten auf dem Hauptknoten ausgeführt werden.
Rufen Sie in der Google Cloud Console die Seite „Ray on Agent Platform“ auf.
Klicken Sie auf Cluster erstellen, um den Bereich Cluster erstellen zu öffnen.
Prüfen oder ersetzen Sie für jeden Schritt im Bereich Cluster erstellen die Standardclusterinformationen. Klicken Sie auf Weiter, um die einzelnen Schritte abzuschließen:
- Geben Sie unter Name und Region einen Namen an und wählen Sie einen Standort für den Cluster aus.
Geben Sie für Compute-Einstellungen die Konfiguration des Hauptknotens des Ray-Clusters, einschließlich Maschinentyp, Beschleunigertyp und Anzahl, Laufwerkstyp und -größe und Replikatanzahl an. Optional können Sie einen benutzerdefinierten Image-URI hinzufügen, um ein benutzerdefiniertes Container-Image anzugeben, um Python-Abhängigkeiten hinzuzufügen, die nicht vom Standard-Container-Image bereitgestellt werden. Weitere Informationen finden Sie unter Benutzerdefiniertes Bild.
Unter Erweiterte Optionen haben Sie folgende Möglichkeiten:
- Geben Sie einen eigenen Verschlüsselungsschlüssel an.
- Geben Sie ein benutzerdefiniertes Dienstkonto an.
- Wenn Sie die Ressourcenstatistiken Ihrer Arbeitslast während des Trainings nicht beobachten müssen, deaktivieren Sie die Erfassung von Messwerten.
Wenn Sie einen Cluster mit einem Worker-Pool mit automatischer Skalierung erstellen möchten, geben Sie einen Wert für die maximale Replikatanzahl des Worker-Pools an.
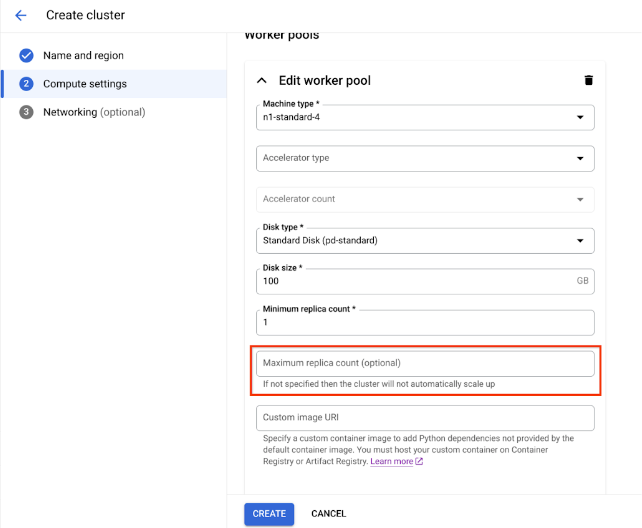
Klicken Sie auf Erstellen.
Manuelle Skalierung
Wenn Ihre Arbeitslasten in Ihren Ray-Clustern in der Gemini Enterprise Agent Platform zu- oder abnehmen, können Sie die Anzahl der Replikate manuell an den Bedarf anpassen. Wenn Sie beispielsweise überschüssige Kapazität haben, können Sie Ihre Worker-Pools verkleinern, um Kosten zu sparen.
Einschränkungen beim VPC-Peering
Beim Skalieren von Clustern können Sie nur die Anzahl der Replikate in vorhandenen Worker-Pools ändern. Sie können beispielsweise weder Worker-Pools zu Ihrem Cluster hinzufügen, noch aus ihm entfernen, noch den Maschinentyp Ihrer Worker-Pools ändern. Außerdem darf die Anzahl der Replikate für Ihre Worker-Pools nicht unter 1 sein.
Wenn Sie eine VPC-Peering-Verbindung für die Verbindung zu Ihren Clustern verwenden, ist die maximale Knotenanzahl begrenzt. Die maximale Anzahl von Knoten hängt von der Anzahl der Knoten ab, die der Cluster hatte, als Sie ihn erstellt haben. Weitere Informationen finden Sie unter Berechnung der maximalen Anzahl an Knoten. Diese maximale Anzahl umfasst nicht nur Ihre Worker-Pools, sondern auch Ihren Head-Knoten. Wenn Sie die Standard-Netzwerkkonfiguration verwenden, darf die Anzahl der Knoten die in der Dokumentation Cluster erstellen vermerkten oberen Grenzwerte nicht überschreiten.
Best Practices für die Zuweisung von Subnetzen
Wenn Sie Ray auf der Gemini Enterprise Agent Platform mit Zugriff auf private Dienste (PSA) bereitstellen, ist es wichtig, dass der zugewiesene IP-Adressbereich ausreichend groß und zusammenhängend ist, um die maximale Anzahl von Knoten aufzunehmen, auf die Ihr Cluster skaliert werden kann. Die IP-Adressen können ausgehen, wenn der für Ihre PSA-Verbindung reservierte IP-Bereich zu klein oder fragmentiert ist. Dies kann zu Bereitstellungsfehlern führen.
Alternativ empfehlen wir, Ray auf der Agent Platform mit einer Private Service Connect-Schnittstelle bereitzustellen, wodurch der IP-Verbrauch auf ein /28-Subnetz reduziert wird.
Monitoring des privaten Dienstzugriffs
Als Best Practice sollten Sie Network Analyzer verwenden. Dieses Diagnosetool im Network Intelligence Center von Google Cloud überwacht automatisch die Konfigurationen Ihres VPC-Netzwerks (Virtual Private Cloud), um Fehlkonfigurationen und suboptimale Einstellungen zu erkennen. Der Network Analyzer wird kontinuierlich ausgeführt. Er führt proaktiv Tests durch und generiert Statistiken, mit denen Sie Netzwerkprobleme identifizieren, diagnostizieren und beheben können, bevor sie sich auf die Dienstverfügbarkeit auswirken.
Network Analyzer kann Subnetze überwachen, die für den Zugriff auf private Dienste (Private Service Access, PSA) verwendet werden, und bietet spezifische Statistiken dazu. Dies ist eine wichtige Funktion für die Verwaltung von Diensten wie Cloud SQL, Memorystore und Agent Platform, die PSA verwenden.
Der Network Analyzer überwacht PSA-Subnetze hauptsächlich, indem er Informationen zur IP-Adressauslastung für die zugewiesenen Bereiche bereitstellt.
PSA-Bereichsauslastung: Network Analyzer verfolgt aktiv den Zuweisungsprozentsatz von IP-Adressen innerhalb der dedizierten CIDR-Blöcke, die Sie für PSA zugewiesen haben. Das ist wichtig, weil Google beim Erstellen eines verwalteten Dienstes (z. B. Agent Platform) eine Dienstersteller-VPC und ein Subnetz darin erstellt und einen IP-Bereich aus Ihrem zugewiesenen Block bezieht.
Proaktive Benachrichtigungen: Wenn die IP-Adressennutzung für einen PSA-zugewiesenen Bereich einen bestimmten Schwellenwert überschreitet (z. B. 75%), generiert Network Analyzer eine Warnung. So werden Sie proaktiv auf potenzielle Kapazitätsprobleme aufmerksam gemacht und haben Zeit, den zugewiesenen IP-Adressbereich zu erweitern, bevor Ihnen die verfügbaren Adressen für neue Dienstressourcen ausgehen.
Subnetz-Updates für den privaten Dienstzugriff
Für die Bereitstellung von Ray auf der Agent Platform empfiehlt Google, einen CIDR-Block vom Typ „/16“ oder „/17“ für Ihre PSA-Verbindung zuzuweisen. Dadurch wird ein ausreichend großer zusammenhängender Block von IP-Adressen für eine erhebliche Skalierung bereitgestellt, der bis zu 65.536 bzw. 32.768 eindeutige IP-Adressen umfasst. So wird eine IP-Erschöpfung auch bei großen Ray-Clustern verhindert.
Wenn Sie den zugewiesenen IP-Adressbereich aufgebraucht haben,gibt Google Cloud diesen Fehler zurück:
Subnetzwerk konnte nicht erstellt werden. Couldn't find free blocks in allocated IP ranges.
Wir empfehlen, den aktuellen Subnetzbereich zu erweitern oder einen Bereich zuzuweisen, der zukünftiges Wachstum ermöglicht.
Berechnung der maximalen Anzahl von Knoten
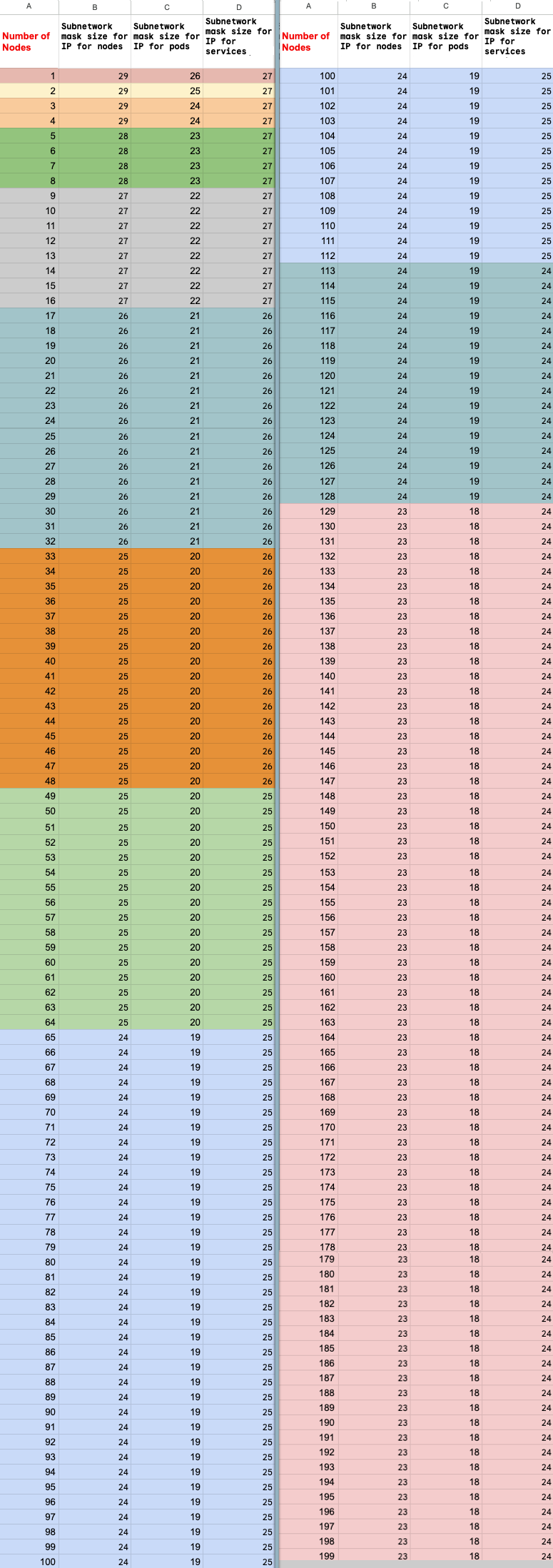
Wenn Sie den Zugriff auf private Dienste (VPC-Peering) nutzen, um eine Verbindung zu Ihren Knoten herzustellen, verwenden Sie folgende Formeln, um zu prüfen, ob Sie die maximale Knotenanzahl (M) nicht überschreiten, wobei f(x) = min(29, (32 -
ceiling(log2(x))) vorausgesetzt wird:
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
Die maximale Gesamtzahl der Knoten im Ray on Agent Platform-Cluster, auf die Sie hochskalieren können (M), hängt von der anfänglichen Gesamtzahl der Knoten ab, die Sie eingerichtet haben (N). Nachdem Sie den Ray on Agent Platform-Cluster erstellt haben, können Sie die Gesamtzahl der Knoten auf einen beliebigen Wert zwischen P und M einschließlich skalieren. Dabei ist P die Anzahl der Pools in Ihrem Cluster.
Die anfängliche Gesamtzahl der Knoten im Cluster und die Zielanzahl für die Skalierung müssen sich im selben Farbblock befinden.
Anzahl der Replikate aktualisieren
Verwenden Sie die Google Cloud Console oder das Agent Platform SDK für Python, um die Anzahl der Replikate des Worker-Pools zu aktualisieren. Wenn Ihr Cluster mehrere Worker-Pools enthält, können Sie die jeweilige Anzahl der Replikate in einer einzigen Anfrage ändern.
Ray on Agent Platform SDK
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
Console
Rufen Sie in der Google Cloud Console die Seite „Ray on Agent Platform“ auf.
Klicken Sie in der Liste der Cluster auf den Cluster, den Sie ändern möchten.
Klicken Sie auf der Seite Clusterdetails auf Cluster bearbeiten.
Wählen Sie im Bereich Cluster bearbeiten den zu aktualisierenden Worker-Pool aus und ändern Sie dann die Anzahl der Replikate.
Klicken Sie auf Aktualisieren.
Warten Sie einige Minuten, bis Ihr Cluster aktualisiert wurde. Nach Abschluss des Updates sehen Sie die aktualisierte Anzahl der Replikate auf der Seite Clusterdetails.
Klicken Sie auf Erstellen.