

בקטע 'יעד' שבהמשך מפורטים דרישות הנתונים, קובץ סכימת הקלט/הפלט והפורמט של קובצי ייבוא הנתונים (JSON Lines ו-CSV) שמוגדרים על ידי הסכימה.
הרשאות
כדי להשתמש בתמונות מקטגוריה של Cloud Storage, צריך להעניק לסוכן של Agent Platform Service את התפקיד Storage Object Viewer בקטגוריה. סוכן השירות הוא חשבון שירות בניהול Google ש-Agent Platform משתמשת בו כדי לגשת לנתונים שלכם בשמכם. הסבר מפורט יותר זמין במאמר סוכני שירות.
זיהוי אובייקטים
הדרישות לגבי הנתונים
| דרישות כלליות לגבי תמונות | |
|---|---|
| סוגי קבצים נתמכים |
|
| סוגי תמונות | מודלים של AutoML מותאמים לתמונות של אובייקטים בעולם האמיתי. |
| גודל הקובץ של תמונת האימון (MB) | גודל מקסימלי: 30MB. |
| גודל הקובץ של תמונת החיזוי* (MB) | גודל מקסימלי של 1.5MB. |
| גודל התמונה (בפיקסלים) | מומלץ להשתמש בתמונות בגודל של עד 1,024 פיקסלים על 1,024 פיקסלים. אם התמונות גדולות בהרבה מ-1,024 פיקסלים על 1,024 פיקסלים, יכול להיות שתחול ירידה באיכות התמונה במהלך תהליך הנרמול של התמונה ב-Gemini Enterprise Agent Platform. |
| דרישות לגבי תוויות ותיבות תוחמות | |
|---|---|
| הדרישות הבאות חלות על מערכי נתונים שמשמשים לאימון מודלים של AutoML. | |
| תיוג מקרים לאימון | מינימום 10 הערות (מופעים). |
| דרישות לגבי הערות | לכל תווית צריכות להיות לפחות 10 תמונות, ולכל תמונה צריכה להיות לפחות הערה אחת (תיבת תוחמת והתווית). עם זאת, לצורך אימון המודל, מומלץ להשתמש בכ-1,000 הערות לכל תוית. באופן כללי, ככל שיש יותר תמונות לכל תוית, כך המודל יפעל טוב יותר. |
| יחס התוויות (התווית הנפוצה ביותר לעומת התווית הכי פחות נפוצה): | המודל פועל בצורה הכי טובה כשיש לכל היותר פי 100 יותר תמונות לתווית הנפוצה ביותר מאשר לתווית הכי פחות נפוצה. כדי לשפר את הביצועים של המודל, מומלץ להסיר תוויות עם תדירות נמוכה מאוד. |
| אורך הקצה של התיבה התוחמת (bounding box) | לפחות 0.01 * אורך הצלע של התמונה. לדוגמה, בתמונה בגודל 1000 * 900 פיקסלים, תיבות התוחמות צריכות להיות בגודל 10 * 9 פיקסלים לפחות. גודל מינימלי של תיבה תוחמת: 8 פיקסלים על 8 פיקסלים. |
| הדרישות הבאות חלות על מערכי נתונים שמשמשים לאימון מודלים ב-AutoML או מודלים שעברו אימון בהתאמה אישית. | |
| תיבות תוחמות לכל תמונה נפרדת | עד 500 תווים. |
| תיבות תוחמות שמוחזרות מבקשת חיזוי | 100 (ברירת מחדל), 500 מקסימום. |
| הדרישות לגבי נתוני אימון וערכות נתונים | |
|---|---|
| הדרישות הבאות חלות על מערכי נתונים שמשמשים לאימון מודלים של AutoML. | |
| מאפיינים של תמונות לאימון | נתוני האימון צריכים להיות כמה שיותר קרובים לנתונים שעליהם יתבססו התחזיות. לדוגמה, אם תרחיש השימוש שלכם כולל תמונות מטושטשות ברזולוציה נמוכה (למשל ממצלמת אבטחה), נתוני האימון צריכים לכלול תמונות מטושטשות ברזולוציה נמוכה. באופן כללי, כדאי גם לספק כמה זוויות, רזולוציות ורקעים לתמונות האימון. מודלים של Gemini Enterprise Agent Platform בדרך כלל לא יכולים לחזות תוויות שאנשים לא יכולים להקצות. לכן, אם אי אפשר לאמן אדם להקצות תוויות על ידי התבוננות בתמונה למשך שנייה או שתיים, סביר להניח שגם את המודל אי אפשר לאמן לעשות זאת. |
| עיבוד מקדים פנימי של תמונות | אחרי ייבוא התמונות, פלטפורמת הסוכנים של Gemini Enterprise מבצעת עיבוד מקדים של הנתונים. התמונות שעברו עיבוד מקדים הן הנתונים בפועל שמשמשים לאימון המודל. עיבוד מקדים של התמונה (שינוי גודל) מתבצע כשהקצה הקצר ביותר של התמונה גדול מ-1,024 פיקסלים. אם הצד הקצר יותר של התמונה גדול מ-1,024 פיקסלים, הצד הקצר יותר יוקטן ל-1,024 פיקסלים. הצד הגדול יותר וגם תיבות התוחמות שצוינו מוקטנות באותו שיעור כמו הצד הקטן יותר. לכן, כל ההערות (תיבות תוחמות ותוויות) שצומצמו יוסרו אם הן קטנות מ-8 פיקסלים על 8 פיקסלים. תמונות שהצד הקצר שלהן קטן מ-1,024 פיקסלים או שווה לו לא עוברות שינוי גודל לפני העיבוד. |
| הדרישות הבאות חלות על מערכי נתונים שמשמשים לאימון מודלים ב-AutoML או מודלים שעברו אימון בהתאמה אישית. | |
| תמונות בכל מערך נתונים | מקסימום 150,000 |
| מספר תיבות התוחמות הכולל עם הערות בכל קבוצת נתונים | מקסימום 1,000,000 |
| מספר התוויות בכל מערך נתונים | מינימום 1, מקסימום 1,000 |
קובץ סכימת YAML
כדי לייבא הערות (תיבות תוחמות ותוויות) של זיהוי אובייקטים בתמונות, צריך להשתמש בקובץ הסכימה הבא שזמין לציבור. קובץ הסכימה הזה קובע את הפורמט של קובצי קלט הנתונים. המבנה של הקובץ הזה מבוסס על סכימת OpenAPI.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
קובץ סכימה מלא
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
קבצי קלט
JSON Lines
JSON בכל שורה:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}הערות בשדה:
-
imageGcsUri– שדה החובה היחיד. -
annotationResourceLabels– יכול להכיל כל מספר של צמדי מפתח/ערך של מחרוזות. צמד המפתח/ערך היחיד ששמור למערכת הוא:- "aiplatform.googleapis.com/annotation_set_name" : "value"
כאשר value הוא אחד מהשמות המוצגים של קבוצות ההערות הקיימות במערך הנתונים.
-
dataItemResourceLabels– יכול להכיל כל מספר של צמדי מפתח/ערך של מחרוזות. צמד המפתח/ערך היחיד ששמור למערכת הוא הבא, שמציין את קבוצת השימוש של למידת מכונה בפריט הנתונים:- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
דוגמה ל-JSON Lines – object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
פורמט CSV:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
-
ML_USE(אופציונלי). למטרות פיצול נתונים במהלך אימון של מודל. אפשר להשתמש בערכים TRAINING, TEST או VALIDATION. מידע נוסף על פיצול נתונים ידני זמין במאמר מידע על פיצול נתונים למודלים של AutoML. -
GCS_FILE_PATH. השדה הזה מכיל את ה-URI של Cloud Storage לתמונה. כתובות URI של Cloud Storage הן תלויות רישיות. LABEL. תוויות חייבות להתחיל באות ויכולות להכיל רק אותיות, מספרים וקווים תחתונים.BOUNDING_BOX. תיבה תוחמת לאובייקט בתמונה. הגדרת תיבת תוחמת כוללת יותר מעמודה אחת.
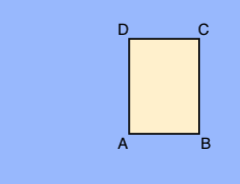
א.X_MIN,Y_MIN
ב.X_MAX,Y_MIN
ג.X_MAX,Y_MAX
D.X_MIN,Y_MAX
כל קודקוד מוגדר על ידי ערכי קואורדינטות x ו-y. הקואורדינטות הן ערכי float מנורמלים [0,1]; 0.0 הוא X_MIN או Y_MIN, 1.0 הוא X_MAX או Y_MAX.
לדוגמה, תיבת תוחמת של התמונה כולה מוצגת כ- (0.0,0.0,,,1.0,1.0,,) או כ- (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0).
אפשר לציין את תיבת התוחמת של אובייקט באחת משתי דרכים:
- שני קודקודים (שתי קבוצות של קואורדינטות x,y) שהם נקודות מנוגדות באלכסון של
המלבן:
א.X_MIN,Y_MIN
C.X_MAX,Y_MAX
כמו בדוגמה הזו:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - כל ארבעת הקודקודים שצוינו, כמו שמוצג כאן:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
אם ארבעת הקודקודים שצוינו לא יוצרים מלבן שמקביל לקצוות התמונה,
Agent Platform מציינת קודקודים שכן יוצרים מלבן כזה.
- שני קודקודים (שתי קבוצות של קואורדינטות x,y) שהם נקודות מנוגדות באלכסון של
המלבן:
דוגמה לקובץ CSV – object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...