
代管災難復原
為保護資料並在區域性中斷期間維持業務連續性,您可以為 BigQuery 資料和工作負載設定及使用 BigQuery 管理的災難復原功能。
總覽
BigQuery 支援災難復原,即使整個區域的服務全面中斷,也能正常營運。BigQuery 災難復原機制會透過跨區域資料集複製功能,管理儲存空間容錯移轉。在次要區域建立資料集副本後,您可以控管運算和儲存空間的容錯移轉行為,在服務中斷期間維持業務持續性。容錯移轉後,您可以在升級的區域存取運算容量 (配額) 和複製的資料集。災難復原功能僅支援 Enterprise Plus 版。
代管災難復原功能提供兩種容錯移轉選項:硬體容錯移轉和軟體容錯移轉。硬性容錯移轉會立即將次要區域的預訂和資料集副本升級為主要區域。即使目前的主要區域處於離線狀態,這項操作仍會繼續進行,且不會等待任何未複製的資料完成複製。因此,硬體容錯移轉期間可能會發生資料遺失情形。如果副本的 replication_time 值在來源區域中提交資料,則在硬體容錯移轉後,可能需要在目的地區域中重新執行任何工作。與硬體容錯移轉不同,軟體容錯移轉會等待主要區域中所有已提交的預訂和資料集變更複製到次要區域,再完成容錯移轉程序。軟性容錯移轉需要主要和次要區域皆可使用。啟動軟性容錯移轉會為預留項目設定 softFailoverStartTime。虛擬 IP 位址會在虛擬容錯移轉完成時清除。softFailoverStartTime
如要啟用災難復原功能,您必須在主要區域建立 Enterprise Plus 版本預留項目,也就是資料集在容錯移轉前的所在區域。配對區域的待命運算容量包含在 Enterprise Plus 預留容量中。然後將資料集附加至這個預留項目,為該資料集啟用容錯移轉功能。只有在資料集已回填,且與預留項目配對的主要和次要位置相同時,才能將資料集附加至預留項目。資料集附加至容錯移轉預留位置後,只有 Enterprise Plus 預留位置可以寫入這些資料集,且您無法對資料集執行跨區域複製升級作業。您可以透過任何容量模式,從附加至容錯移轉預留項目的資料集讀取資料。如要進一步瞭解預留項目,請參閱工作負載管理簡介。
容錯移轉後,次要區域會立即提供主要區域的運算容量。無論是否使用,這項可用性都適用於預留項目的基準。
您必須主動選擇容錯移轉,才能進行測試或因應實際災難。在 10 分鐘內,您不應容錯移轉超過一次。在資料複寫情境中,回填是指在建立或啟用副本之前,以現有歷來資料填入資料集副本的程序。資料集必須先完成回填,才能容錯移轉至該資料集。
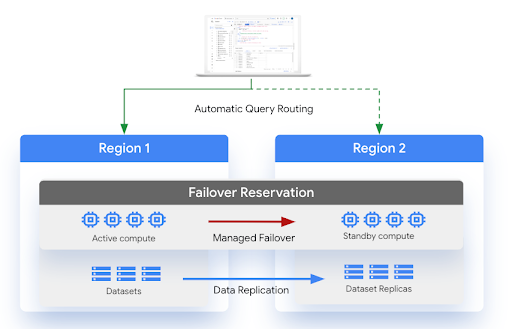
下圖顯示受管理災難復原的架構:
限制
BigQuery 災難復原功能有下列限制:
資料集附加至容錯移轉預留項目後,只有 Enterprise Plus 預留項目可以寫入該資料集。不過,您可以使用任何容量模型,從附加至容錯移轉預留位置的資料集讀取資料。
BigQuery 災難復原功能與跨區域資料集複製功能有相同的限制。
容錯移轉後的自動調度取決於次要區域的運算容量。次要區域僅提供預訂基準。
INFORMATION_SCHEMA.RESERVATIONS檢視區塊沒有容錯移轉詳細資料。INFORMATION_SCHEMA.JOBS檢視畫面中的主要區域資料不會複製到次要區域。這個檢視畫面只會顯示工作執行所在特定區域的工作記錄。如果發生容錯移轉,使用INFORMATION_SCHEMA.JOBS檢視畫面時,次要區域不會顯示主要區域的工作記錄。如果您有多個容錯移轉預留項目,且這些項目屬於同一個管理專案,但附加的資料集使用不同的次要位置,請勿使用一個容錯移轉預留項目,並將資料集附加至不同的容錯移轉預留項目。
如要將現有預留項目轉換為容錯移轉預留項目,現有預留項目不得有超過 1,000 個預留項目指派。
容錯移轉預留項目最多只能附加 1,000 個資料集。
只有在來源和目的地區域都可用時,才能觸發軟性容錯移轉。
如果在資源的初始建立期間複製失敗,系統就不會在次要位置建立預留項目,也就是說,硬體和軟體容錯移轉都無法使用。
如果預留設定變更尚未成功複製到次要區域,就無法觸發軟體容錯移轉。如果預留項目複製期間發生任何錯誤,例如次要區域的配額不足,或發生其他暫時性問題,系統就無法啟動軟性容錯移轉。
在作用中的軟體容錯移轉期間,無法更新預訂和附加的資料集,但仍可從中讀取資料。
在有效虛擬容錯移轉期間,於容錯移轉預留項目執行的工作可能無法在預留項目上執行,因為容錯移轉作業期間,資料集和預留項目路徑會暫時變更。不過,在啟動任何軟體容錯移轉之前和完成之後,這些工作都會使用預留的時段。
如果資料集使用 BigQuery 災害復原功能,載入和擷取工作就無法使用免費共用時段集區。您必須建立
PIPELINE類型的預訂指派,因為只有 Enterprise Plus 版支援寫入已設定的 MDR 資料集。這項規定可確保所有資料擷取作業,都由支援 MDR 跨區域複製和復原點目標 (RPO) 的專用基礎架構處理。排定查詢不會在容錯移轉後自動重新導向至新的主要位置,因為這類查詢會繫結至建立時指定的位置。如要在新的主要位置繼續執行預定查詢,請在該位置手動重新建立查詢。
位置
建立容錯移轉預留項目時,可使用下列區域:
| 位置代碼 | 地區名稱 | 地區說明 |
|---|---|---|
AU |
||
AUSTRALIA-SOUTHEAST1 |
雪梨 | |
AUSTRALIA-SOUTHEAST2 |
墨爾本 | |
CA |
||
NORTHAMERICA-NORTHEAST1 |
蒙特婁 | |
NORTHAMERICA-NORTHEAST2 |
多倫多 | |
DE |
||
EUROPE-WEST3 |
法蘭克福 | |
EUROPE-WEST10 |
柏林 | |
EU |
||
EU |
歐洲 (多區域) | |
EUROPE-CENTRAL2 |
華沙 | |
EUROPE-NORTH1 |
芬蘭 | |
EUROPE-SOUTHWEST1 |
馬德里 | |
EUROPE-WEST1 |
比利時 | |
EUROPE-WEST3 |
法蘭克福 | |
EUROPE-WEST4 |
荷蘭 | |
EUROPE-WEST8 |
米蘭 | |
EUROPE-WEST9 |
巴黎 | |
IN |
||
ASIA-SOUTH1 |
孟買 | |
ASIA-SOUTH2 |
德里 | |
US |
||
US |
美國 (多區域) | |
US-CENTRAL1 |
愛荷華州 | |
US-EAST1 |
南卡羅來納州 | |
US-EAST4 |
北維吉尼亞州 | |
US-EAST5 |
哥倫布 | |
US-SOUTH1 |
達拉斯 | |
US-WEST1 |
俄勒岡州 | |
US-WEST2 |
洛杉磯 | |
US-WEST3 |
鹽湖城 | |
US-WEST4 |
拉斯維加斯 |
您必須在 AU、CA、DE、EU、IN 或 US 中選取區域配對。舉例來說,US 內的區域無法與 EU 內的區域配對。
如果 BigQuery 資料集位於多區域位置,則無法使用下列區域配對。這項限制是為了確保容錯移轉預留空間和資料在複製後位於不同地理位置。如要進一步瞭解多區域內含的區域,請參閱「多區域」。
us-central1-us多區域us-west1-us多區域eu-west1-eu多區域eu-west4-eu多區域
事前準備
- 確認您具備更新預訂的身分與存取權管理 (IAM) 權限。
bigquery.reservations.update - 確認您已設定要複製的現有資料集。詳情請參閱「複製資料集」。
強化型複製
災難復原功能會使用強化型複製功能,加快跨區域的資料複製速度,降低資料遺失風險、縮短服務停機時間,並協助支援區域中斷後的服務不中斷。
強化型複製功能不適用於初始回填作業。完成初始回填作業後,只要未超過頻寬配額且沒有使用者錯誤,強化型複製功能就會在 15 分鐘內,將資料集複製到具有次要副本的單一容錯移轉區域配對。
復原時間目標
復原時間目標 (RTO) 是指發生災難時,BigQuery 允許復原的目標時間。如要進一步瞭解 RTO,請參閱「災難復原規劃基礎知識」。啟動容錯移轉後,受管理的災難復原程序會在五分鐘內完成 RTO。由於 RTO 的關係,啟動容錯移轉程序後五分鐘內,次要區域就會提供容量。
復原點目標
復原點目標 (RPO) 是指資料必須能夠還原到的最近時間點。如要進一步瞭解 RPO,請參閱災害復原規劃基本概念。代管的災難復原服務 會為每個資料集定義 RPO。RPO 的目標是讓次要副本與主要副本的差距在 15 分鐘內。為達到這個 RPO,您不得超過頻寬配額,且不得發生任何使用者錯誤。
配額
設定容錯移轉預留項目前,次要區域必須有您選擇的運算容量。如果次要區域沒有可用配額,您就無法設定或更新預留空間。詳情請參閱「配額與限制」。
強化型複製功能的頻寬有配額限制。詳情請參閱「配額與限制」。
定價
如要設定受管理災難復原功能,必須採用下列定價方案:
運算容量:您必須購買 Enterprise Plus 版本。
強化型複製:災難復原功能在複製期間會依賴強化型複製功能。系統會根據實體位元組數,以及每個複製的實體 GiB 向您收費。詳情請參閱「強化型複製功能的資料複製資料移轉價格」。
儲存空間:次要區域的儲存空間位元組計費方式,與主要區域的儲存空間位元組相同。詳情請參閱「儲存空間價格」一文。
客戶只需支付主要區域的運算容量費用。次要運算容量 (以預訂基準為準) 可在次要區域使用,不需額外付費。閒置運算單元無法使用次要運算容量,除非預留項目已容錯移轉。
如要在次要區域執行過時讀取作業,您必須購買額外的運算容量。
代管災難復原支援 BigQuery 彈性擴縮。如要確保容錯移轉後以秒計費,且沒有最短時間限制,您必須在主要和次要區域啟用 BigQuery 彈性擴縮功能。
建立或變更 Enterprise Plus 預留項目
將資料集附加至預訂項目之前,您必須建立 Enterprise Plus 預訂項目,或變更現有預訂項目並設定為災難復原。
建立預留項目
請選取下列其中一個選項:
控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「工作負載管理」。
按一下「建立預留項目」。
在「Reservation name」(預留項目名稱) 欄位中,輸入預留項目的名稱。
在「位置」清單中選取位置。
在「版本」清單中,選取 Enterprise Plus 版本。
在「預留項目大小選取器」清單中,選取預留項目大小上限。
選用:在「Baseline slots」(基準運算單元) 欄位中,輸入保留項目的基準運算單元數量。
可用的自動調度資源運算單元數量,取決於「基準運算單元」值減去「預留項目大小上限」值。舉例來說,如果您建立的預留項目有 100 個基準運算單元,且預留項目大小上限為 400,則預留項目會有 300 個自動調度運算單元。如要進一步瞭解基準運算單元,請參閱「使用預留項目搭配基準和自動調度運算單元」一文。
在「次要位置」清單中,選取次要位置。
如要停用閒置的運算單元共用功能,並只使用指定的運算單元容量,請按一下「忽略閒置的運算單元」切換鈕。
如要展開「進階設定」部分,請按一下展開箭頭。
選用:如要設定目標工作並行數,請按一下「覆寫自動目標工作並行設定」切換鈕,然後輸入「目標工作並行數」的值。 費用預估表格會顯示時段明細。預留項目摘要會顯示在「容量摘要」表格中。
按一下 [儲存]。
新預訂項目會顯示在「預訂時段」分頁中。
SQL
如要建立預留項目,請使用CREATE RESERVATION資料定義語言 (DDL) 陳述式。
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
CREATE RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` OPTIONS ( slot_capacity = NUMBER_OF_BASELINE_SLOTS, edition = ENTERPRISE_PLUS, secondary_location = SECONDARY_LOCATION);
請替換下列項目:
ADMIN_PROJECT_ID:管理專案的專案 ID,該專案擁有預留資源。LOCATION:預訂的位置。如果選取 BigQuery Omni 位置,版本選項會限制為 Enterprise 版。RESERVATION_NAME:預訂名稱。名稱開頭和結尾須為小寫英文字母或數字,中間只能使用小寫英文字母、數字和破折號。
NUMBER_OF_BASELINE_SLOTS:要分配給預訂的基準時段數量。您無法在同一個預訂中設定slot_capacity選項和edition選項。SECONDARY_LOCATION:預留項目的次要位置。如果發生中斷情形,附加至這個預留項目的任何資料集都會容錯移轉至這個位置。
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
變更現有預訂
請選取下列其中一個選項:
控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「工作負載管理」。
按一下「運算單元預留項目」分頁標籤。
找出要更新的預訂。
依序點按 「預訂動作」和「編輯」。
在「Secondary location」(次要位置) 欄位中,輸入次要位置。
按一下 [儲存]。
SQL
如要為預訂項目新增或變更次要位置,請使用 ALTER RESERVATION SET OPTIONS DDL 陳述式。
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( secondary_location = SECONDARY_LOCATION);
請替換下列項目:
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
將資料集附加至預留項目
如要為先前建立的預留項目啟用災害復原功能,請完成下列步驟。資料集必須已在與預訂相同的主要和次要區域中設定複製作業。詳情請參閱「跨區域資料集複製」。
控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下導覽選單中的「工作負載管理」。
按一下「運算單元預留項目」分頁標籤。
按一下要附加資料集的預留項目。
按一下「災難復原」分頁標籤。
按一下「新增容錯移轉資料集」。
輸入要與預訂項目建立關聯的資料集名稱。
按一下「新增」。
SQL
如要將資料集附加至預留項目,請使用 ALTER SCHEMA SET OPTIONS DDL 陳述式。
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = ADMIN_PROJECT_ID.RESERVATION_NAME);
請替換下列項目:
DATASET_NAME:資料集名稱。ADMIN_PROJECT_ID.RESERVATION_NAME:要與資料集建立關聯的預訂名稱。
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
從預留項目卸離資料集
如要停止透過預留項目管理資料集的容錯移轉行為,請將資料集從預留項目中分離。這不會變更資料集的目前主要副本,也不會移除任何現有資料集副本。如要進一步瞭解如何在卸離資料集後移除資料集副本,請參閱「移除資料集副本」。
控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
在導覽選單中,依序點選「工作負載管理」和「運算單元預留項目」分頁標籤。
按一下要從中卸離資料集的預留項目。
按一下「災難復原」分頁標籤。
展開資料集主要副本的「動作」選項。
按一下 [移除]。
SQL
如要將資料集從預留位置分離,請使用 ALTER SCHEMA SET OPTIONS DDL 陳述式。
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
ALTER SCHEMA `DATASET_NAME` SET OPTIONS ( failover_reservation = NULL);
請替換下列項目:
DATASET_NAME:資料集名稱。
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
啟動容錯移轉
如果發生區域性服務中斷,您必須手動將預訂項目容錯移轉至備用資源使用的位置。預留項目容錯移轉時,也會一併容錯移轉任何相關聯的資料集。如要手動容錯移轉預留項目,請執行下列步驟:
控制台
前往 Google Cloud 控制台的「BigQuery」頁面。
在導覽選單中,按一下「Disaster recovery」(災害復原)。
按一下要容錯移轉的預訂名稱。
選取「硬式容錯移轉模式 (預設)」或「軟式容錯移轉模式」。
按一下「Failover」。
SQL
如要為預留項目新增或變更次要位置,請使用 ALTER RESERVATION SET OPTIONS DDL 陳述式,並將 is_primary 設為 TRUE。
前往 Google Cloud 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
ALTER RESERVATION `ADMIN_PROJECT_ID.region-LOCATION.RESERVATION_NAME` SET OPTIONS ( is_primary = TRUE, failover_mode=FAILOVER_MODE);
請替換下列項目:
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
監控複製作業
您可以透過 BigQuery、Cloud Monitoring 或 INFORMATION_SCHEMA 檢視畫面,監控資料集副本的狀態。
如要瞭解如何針對這些指標建立快訊,請參閱「建立資訊主頁、圖表和快訊」。
使用 BigQuery 查看複製狀態
如要在Google Cloud 控制台中查看資料集的複製狀態和延遲時間,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
在「Explorer」窗格中展開專案。
按一下要監控的資料集。
在資料集詳細資料窗格中,按一下「詳細資料」分頁標籤。
在「副本」部分中,查看「複寫延遲」和「狀態」。如要查看更多詳細資料,包括複寫延遲圖表,請按一下「查看詳細資料」。
使用 Cloud Monitoring 查看複製狀態
BigQuery 會在 Monitoring 中提供下列指標,協助您監控複製狀態:
- 複製延遲時間:次要區域內資料的過時程度,這些資料是透過跨區域複製或代管災難復原作業複製。這項指標可做為復原點目標 (RPO) 的替代指標。
- 網路輸出位元組:從主要區域複製到次要區域的資料量 (以位元組為單位),會據此計費。這項指標可協助您監控頻寬配額用量。
如要在 Monitoring 中查看這些指標,請按照下列步驟操作:
前往 Google Cloud 控制台的「Monitoring」頁面。
按一下「指標探索工具」。
在「選取指標」欄位中,搜尋並選取「BigQuery 資料集」。
選取「複寫延遲時間」 (
bigquery.googleapis.com/storage/replication/dataset_staleness) 或「網路輸出位元組」 (bigquery.googleapis.com/storage/replication/network_egress_bytes_count)。按一下「套用」。
在「匯總」部分中,選取匯總方法。對於複寫延遲指標,建議選取「第 99 個百分位數」。相較於平均值或其他匯總資料,這項匯總資料更能顯示最差的成效。
選用:如要查看特定資料集或次要區域的指標,請按一下「新增篩選條件」,選取「dataset_id」或「location」選項,然後輸入值。如果將資料複製到多個次要區域,可以依位置分組,查看每個區域的指標。
使用 INFORMATION_SCHEMA 查看複製狀態
如要判斷副本的狀態,請查詢 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 檢視區塊。例如:
SELECT schema_name, replica_name, creation_complete, replica_primary_assigned, replica_primary_assignment_complete FROM `region-LOCATION`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name="my_dataset"
下列查詢會傳回過去七天內的工作,如果這些工作使用容錯移轉資料集,就會失敗:
WITH non_epe_reservations AS ( SELECT project_id, reservation_name FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.RESERVATIONS WHERE edition != 'ENTERPRISE_PLUS' ) SELECT * FROM ( SELECT job_id FROM ( SELECT job_id, reservation_id, ARRAY_CONCAT(referenced_tables, [destination_table]) AS all_referenced_tables, query FROM `PROJECT_ID.region-LOCATION`.INFORMATION_SCHEMA.JOBS WHERE creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP() ) A, UNNEST(all_referenced_tables) AS referenced_table ) jobs LEFT OUTER JOIN non_epe_reservations ON ( jobs.reservation_id = CONCAT( non_epe_reservations.project_id, ':', 'LOCATION', '.', non_epe_reservations.reservation_name)) WHERE CONCAT(jobs.project_id, ':', jobs.dataset_id) IN UNNEST( [ 'PROJECT_ID:DATASET_ID', 'PROJECT_ID:DATASET_ID']);
更改下列內容:
PROJECT_ID:專案 ID。DATASET_ID:資料集 ID。LOCATION:位置。