
הרצת שאילתה
במאמר הזה מוסבר איך להריץ שאילתה ב-BigQuery ולהבין כמה נתונים השאילתה תעבד לפני ההרצה, באמצעות הרצה יבשה.
סוגי שאילתות
אתם יכולים להריץ שאילתות על נתוני BigQuery באמצעות אחד מסוגי משימות השאילתות הבאים:
משימות של שאילתות אינטראקטיביות. כברירת מחדל, BigQuery מריץ שאילתות כמשימות של שאילתות אינטראקטיביות, שמיועדות להתחיל לפעול כמה שיותר מהר.
משימות של שאילתות באצווה. לשאילתות אצווה יש עדיפות נמוכה יותר מאשר לשאילתות אינטראקטיביות. כשפרויקט או הזמנה משתמשים בכל משאבי ה-Compute הזמינים, סביר יותר ששאילתות באצ' יתווספו לתור וישארו בו. אחרי שמתחילים להריץ שאילתה באצווה, היא פועלת כמו שאילתה אינטראקטיבית. מידע נוסף זמין במאמר בנושא תורים של שאילתות.
עבודות של שאילתות מתמשכות. בעזרת המשימות האלה, השאילתה פועלת באופן רציף, ומאפשרת לכם לנתח נתונים נכנסים ב-BigQuery בזמן אמת, ואז לכתוב את התוצאות בטבלה ב-BigQuery או לייצא את התוצאות ל-Bigtable או ל-Pub/Sub. אתם יכולים להשתמש ביכולת הזו כדי לבצע משימות רגישות לזמן, כמו יצירת תובנות ופעולה מיידית על בסיסן, הפעלת הסקה של למידת מכונה (ML) בזמן אמת ויצירת צינורות נתונים מבוססי-אירועים.
אפשר להריץ משימות של שאילתות בדרכים הבאות:
- לכתוב ולהריץ שאילתה במסוףGoogle Cloud .
- מריצים את הפקודה
bq queryבכלי שורת הפקודה של BigQuery. - קוראים באופן פרוגרמטי ל-method
jobs.queryאו ל-methodjobs.insertב-API בארכיטקטורת REST של BigQuery. - שימוש בספריות הלקוח של BigQuery.
המערכת של BigQuery שומרת את התוצאות של השאילתה בטבלה זמנית (ברירת מחדל) או בטבלה קבועה. כשמציינים טבלה קבועה כטבלת היעד של התוצאות, אפשר לבחור אם להוסיף או להחליף טבלה קיימת, או ליצור טבלה חדשה עם שם ייחודי.
התפקידים הנדרשים
כדי לקבל את ההרשאות שדרושות להרצת שאילתה, אתם צריכים לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים:
- BigQuery Job User (
roles/bigquery.jobUser) בפרויקט. - BigQuery Data Viewer (
roles/bigquery.dataViewer) בכל הטבלאות והתצוגות שהשאילתה מתייחסת אליהן. כדי לשלוח שאילתות לתצוגות, צריך גם את התפקיד הזה בכל הטבלאות והתצוגות הבסיסיות. אם אתם משתמשים בתצוגות מורשות או בקבוצות נתונים מורשות, אתם לא צריכים גישה לנתוני המקור הבסיסיים.
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
התפקידים המוגדרים מראש האלה כוללים את ההרשאות שנדרשות להרצת משימת שאילתה. כדי לראות בדיוק אילו הרשאות נדרשות, אפשר להרחיב את הקטע ההרשאות הנדרשות:
ההרשאות הנדרשות
כדי להריץ עבודת שאילתה, צריך את ההרשאות הבאות:
-
bigquery.jobs.createבפרויקט שממנו מריצים את השאילתה, ללא קשר למקום שבו הנתונים מאוחסנים. -
bigquery.tables.getDataבכל הטבלאות והתצוגות שהשאילתה מתייחסת אליהן. כדי לשלוח שאילתות לתצוגות, צריך גם את ההרשאה הזו לכל הטבלאות והתצוגות הבסיסיות. אם אתם משתמשים בתצוגות מורשות או בקבוצות נתונים מורשות, אתם לא צריכים גישה לנתוני המקור הבסיסיים.
יכול להיות שתקבלו את ההרשאות האלה באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
פתרון בעיות
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
השגיאה הזו מתרחשת כשאין לחשבון משתמש הרשאה ליצור עבודות של שאילתות בפרויקט.
פתרון: אדמין צריך להעניק לכם את ההרשאה bigquery.jobs.create בפרויקט שאתם שולחים אליו שאילתה. ההרשאה הזו נדרשת בנוסף לכל הרשאה שנדרשת לגישה לנתונים שאליהם נשלחת השאילתה.
מידע נוסף על הרשאות ב-BigQuery זמין במאמר בקרת גישה באמצעות IAM.
הרצת שאילתה אינטראקטיבית
כדי להריץ שאילתה אינטראקטיבית, בוחרים באחת מהאפשרויות הבאות:
המסוף
עוברים לדף BigQuery.
לוחצים על שאילתת SQL.
מזינים שאילתת GoogleSQL תקינה בעורך השאילתות.
לדוגמה, אפשר להריץ שאילתה במערך הנתונים הציבורי של BigQuery
usa_namesכדי לזהות את השמות הנפוצים ביותר בארצות הברית בין השנים 1910 ל-2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;לחלופין, אפשר להשתמש בחלונית הפניה כדי ליצור שאילתות חדשות.
אופציונלי: כדי להציג באופן אוטומטי הצעות לקוד כשמקלידים שאילתה, לוחצים על Tools (כלים) > Parser-based auto-completion (השלמה אוטומטית מבוססת-מנתח). אם לא רוצים הצעות להשלמה אוטומטית, מבטלים את הסימון של האפשרות השלמה אוטומטית מבוססת-ניתוח. הפעולה הזו משביתה גם את ההצעות למילוי אוטומטי של שם הפרויקט.
אופציונלי: כדי לבחור הגדרות נוספות של שאילתות, לוחצים על עריכה > הגדרות שאילתה.
לוחצים על הפעלה.
אם לא מציינים טבלת יעד, עבודת השאילתה כותבת את הפלט לטבלה זמנית (מטמון).
עכשיו אפשר לעיין בתוצאות השאילתה בכרטיסייה Results בחלונית Query results.
אופציונלי: כדי למיין את תוצאות השאילתה לפי עמודה, לוחצים על תפריט המיון לצד שם העמודה ובוחרים סדר מיון. אם מספר הבייטים המשוערים שנדרשים למיון גדול מאפס, מספר הבייטים מוצג בחלק העליון של התפריט.
אופציונלי: כדי לראות תצוגה חזותית של תוצאות השאילתה, עוברים לכרטיסייה תצוגה חזותית. אפשר להגדיל או להקטין את התרשים, להוריד אותו כקובץ PNG או להפעיל או להשבית את התצוגה של מקרא התרשים.
בחלונית Visualization configuration (הגדרת התצוגה החזותית), אפשר לשנות את סוג התצוגה החזותית ולהגדיר את המדדים והמאפיינים של התצוגה החזותית. השדות בחלונית הזו מאוכלסים מראש בהגדרה הראשונית שמוסקת מסכימת טבלת היעד של השאילתה. ההגדרה נשמרת בין הרצות של שאילתות בעורך השאילתות.
במקרה של תרשימי קו, עמודות או פיזור, המימדים הנתמכים הם סוגי הנתונים
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIMEו-STRING, והמדדים הנתמכים הם סוגי הנתוניםINT64,FLOAT64,NUMERICו-BIGNUMERIC.אם תוצאות השאילתה כוללות את הסוג
GEOGRAPHY, סוג ההדמיה שמוגדר כברירת מחדל הוא מפה, שמאפשר לכם לראות את התוצאות במפה אינטראקטיבית.אופציונלי: בכרטיסייה JSON אפשר לעיין בתוצאות השאילתה בפורמט JSON, שבו המפתח הוא שם העמודה והערך הוא התוצאה של העמודה הזו.
BQ
-
במסוף Google Cloud , מפעילים את Cloud Shell.
בחלק התחתון של Google Cloud המסוף יתחיל סשן של Cloud Shell ותופיע הודעה של שורת הפקודה. Cloud Shell היא סביבת מעטפת שבה ה-CLI של Google Cloud מותקן ומוגדרים ערכים לפרויקט הקיים. הסשן יופעל תוך כמה שניות.
משתמשים בפקודה
bq query. בדוגמה הבאה, הדגל--use_legacy_sql=falseמאפשר להשתמש בתחביר של GoogleSQL.bq query \ --use_legacy_sql=false \ 'QUERY'
מחליפים את QUERY בשאילתת GoogleSQL תקינה. לדוגמה, אפשר להריץ שאילתה במערך הנתונים הציבורי של BigQuery
usa_namesכדי לקבוע מהם השמות הנפוצים ביותר בארצות הברית בין השנים 1910 ל-2013:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'משימת השאילתה כותבת את הפלט לטבלה זמנית (מטמון).
אפשר גם לציין את טבלת היעד ואת המיקום של תוצאות השאילתה. כדי לכתוב את התוצאות לטבלה קיימת, צריך לכלול את הדגל המתאים כדי לצרף (
--append_table=true) או להחליף (--replace=true) את הטבלה.bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
מחליפים את מה שכתוב בשדות הבאים:
LOCATION: האזור או האזור המרובה של טבלת היעד, לדוגמה
USבדוגמה הזו, מערך הנתונים
usa_namesמאוחסן במיקום של מספר אזורים בארה"ב. אם מציינים טבלת יעד לשאילתה הזו, מערך הנתונים שמכיל את טבלת היעד צריך להיות גם הוא באזור מרובה בארה"ב. אי אפשר להריץ שאילתה על מערך נתונים במיקום אחד ולכתוב את התוצאות בטבלה במיקום אחר.אפשר להגדיר ערך ברירת מחדל למיקום באמצעות הקובץ .bigqueryrc.
TABLE: שם טבלת היעד, למשל
myDataset.myTableאם טבלת היעד היא טבלה חדשה, BigQuery יוצר את הטבלה כשמריצים את השאילתה. עם זאת, צריך לציין מערך נתונים קיים.
אם הטבלה לא נמצאת בפרויקט הנוכחי, צריך להוסיף אתGoogle Cloud מזהה הפרויקט בפורמט
PROJECT_ID:DATASET.TABLE– לדוגמה,myProject:myDataset.myTable. אם לא מציינים את--destination_table, נוצרת משימת שאילתה שכותבת את הפלט לטבלה זמנית.
Terraform
משתמשים במשאב google_bigquery_job.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
בדוגמה הבאה מריצים שאילתה. אפשר לאחזר את תוצאות השאילתה על ידי צפייה בפרטי המשרה:
כדי להחיל את הגדרות Terraform בפרויקט ב- Google Cloud , מבצעים את השלבים בקטעים הבאים.
הכנת Cloud Shell
- מפעילים את Cloud Shell.
-
מגדירים את פרויקט ברירת המחדל שבו רוצים להחיל את ההגדרות של Terraform. Google Cloud
תצטרכו להריץ את הפקודה הזו רק פעם אחת לכל פרויקט, ותוכלו לעשות זאת בכל ספרייה.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
אם תגדירו ערכים ספציפיים בקובץ התצורה של Terraform, הם יבטלו את ערכי ברירת המחדל של משתני הסביבה.
הכנת הספרייה
לכל קובץ תצורה של Terraform צריכה להיות ספרייה משלו (שנקראת גם מודול ברמה הבסיסית).
-
יוצרים ספרייה חדשה ב-Cloud Shell ובה יוצרים קובץ חדש. שם הקובץ חייב לכלול את הסיומת
.tf, למשלmain.tf. במדריך הזה, הקובץ נקראmain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
אם אתם עוקבים אחרי המדריך, תוכלו להעתיק את הקוד לדוגמה בכל קטע או שלב.
מעתיקים את הקוד לדוגמה בקובץ
main.tfהחדש שיצרתם.לחלופין, אפשר גם להעתיק את הקוד מ-GitHub. כדאי לעשות את זה כשקטע הקוד של Terraform הוא חלק מפתרון מקצה לקצה.
- בודקים את הפרמטרים לדוגמה ומשנים אותם בהתאם לסביבה שלכם.
- שומרים את השינויים.
-
מפעילים את Terraform. צריך לעשות זאת רק פעם אחת לכל ספרייה.
terraform init
אופציונלי: תוכלו לכלול את האפשרות
-upgrade, כדי להשתמש בגרסה העדכנית ביותר של הספק של Google:terraform init -upgrade
החלה של השינויים
-
בודקים את ההגדרות ומוודאים שהמשאבים שמערכת Terraform תיצור או תעדכן תואמים לציפיות שלכם:
terraform plan
מתקנים את ההגדרות לפי הצורך.
-
מריצים את הפקודה הבאה ומזינים
yesבהודעה שמופיעה, כדי להחיל את הגדרות Terraform:terraform apply
ממתינים עד שב-Terraform תוצג ההודעה "Apply complete!".
- פותחים את Google Cloud הפרויקט כדי לראות את התוצאות. במסוף Google Cloud , נכנסים למשאבים בממשק המשתמש כדי לוודא שהם נוצרו או עודכנו ב-Terraform.
API
כדי להריץ שאילתה באמצעות ה-API, מוסיפים משימה חדשה ומאכלסים את מאפיין ההגדרה של המשימה query. אפשר גם לציין את המיקום במאפיין location בקטע jobReference של משאב המשרה.
שולחים בקשת בדיקה לתוצאות באמצעות קריאה ל-getQueryResults. שולחים בקשת בדיקה עד ש-jobComplete שווה ל-true. בודקים אם יש שגיאות ואזהרות ברשימה errors.
C#
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי C#הוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery C# API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
המשך
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Goהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Go API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
כדי להריץ שאילתה עם שרת proxy, אפשר לעיין במאמר בנושא הגדרת שרת proxy.
Node.js
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
PHP
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי PHPהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery PHP API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Python
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Ruby
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Rubyהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Ruby API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
הרצת שאילתה באצווה
כדי להריץ שאילתת אצווה, בוחרים באחת מהאפשרויות הבאות:
המסוף
עוברים לדף BigQuery.
לוחצים על שאילתת SQL.
מזינים שאילתת GoogleSQL תקינה בעורך השאילתות.
לדוגמה, אפשר להריץ שאילתה במערך הנתונים הציבורי של BigQuery
usa_namesכדי לזהות את השמות הנפוצים ביותר בארצות הברית בין השנים 1910 ל-2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;לוחצים על עריכה > הגדרות שאילתה.
בקטע ניהול משאבים, בוחרים באפשרות Batch.
אופציונלי: משנים את הגדרות השאילתה.
לוחצים על Save.
לוחצים על הפעלה.
אם לא מציינים טבלת יעד, עבודת השאילתה כותבת את הפלט לטבלה זמנית (מטמון).
BQ
-
במסוף Google Cloud , מפעילים את Cloud Shell.
בחלק התחתון של Google Cloud המסוף יתחיל סשן של Cloud Shell ותופיע הודעה של שורת הפקודה. Cloud Shell היא סביבת מעטפת שבה ה-CLI של Google Cloud מותקן ומוגדרים ערכים לפרויקט הקיים. הסשן יופעל תוך כמה שניות.
משתמשים בפקודה
bq queryומציינים את הדגל--batch. בדוגמה הבאה, הדגל--use_legacy_sql=falseמאפשר להשתמש בתחביר של GoogleSQL.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
מחליפים את QUERY בשאילתת GoogleSQL תקינה. לדוגמה, אפשר להריץ שאילתה במערך הנתונים הציבורי של BigQuery
usa_namesכדי לקבוע מהם השמות הנפוצים ביותר בארצות הברית בין השנים 1910 ל-2013:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'משימת השאילתה כותבת את הפלט לטבלה זמנית (מטמון).
אפשר גם לציין את טבלת היעד ואת המיקום של תוצאות השאילתה. כדי לכתוב את התוצאות לטבלה קיימת, צריך לכלול את הדגל המתאים כדי לצרף (
--append_table=true) או להחליף (--replace=true) את הטבלה.bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
מחליפים את מה שכתוב בשדות הבאים:
LOCATION: האזור או האזור המרובה של טבלת היעד, לדוגמה
USבדוגמה הזו, מערך הנתונים
usa_namesמאוחסן במיקום של מספר אזורים בארה"ב. אם מציינים טבלת יעד לשאילתה הזו, מערך הנתונים שמכיל את טבלת היעד צריך להיות גם הוא באזור מרובה בארה"ב. אי אפשר להריץ שאילתה על מערך נתונים במיקום אחד ולכתוב את התוצאות בטבלה במיקום אחר.אפשר להגדיר ערך ברירת מחדל למיקום באמצעות הקובץ .bigqueryrc.
TABLE: שם טבלת היעד, למשל
myDataset.myTableאם טבלת היעד היא טבלה חדשה, BigQuery יוצר את הטבלה כשמריצים את השאילתה. עם זאת, צריך לציין מערך נתונים קיים.
אם הטבלה לא נמצאת בפרויקט הנוכחי, צריך להוסיף אתGoogle Cloud מזהה הפרויקט בפורמט
PROJECT_ID:DATASET.TABLE– לדוגמה,myProject:myDataset.myTable. אם לא מציינים את--destination_table, נוצרת משימת שאילתה שכותבת את הפלט לטבלה זמנית.
API
כדי להריץ שאילתה באמצעות ה-API, מוסיפים משימה חדשה ומאכלסים את מאפיין ההגדרה של המשימה query. אפשר גם לציין את המיקום במאפיין location בקטע jobReference של משאב המשרה.
כשמאכלסים את מאפייני עבודת השאילתה, צריך לכלול את המאפיין configuration.query.priority ולהגדיר את הערך שלו ל-BATCH.
שולחים בקשת בדיקה לתוצאות באמצעות קריאה ל-getQueryResults. שולחים בקשת בדיקה עד ש-jobComplete שווה ל-true. בודקים אם יש שגיאות ואזהרות ברשימה errors.
המשך
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Goהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Go API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Java
כדי להריץ שאילתת אצווה, מגדירים את העדיפות של השאילתה לערך QueryJobConfiguration.Priority.BATCH כשיוצרים QueryJobConfiguration.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Node.js
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Python
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
הרצת שאילתה מתמשכת
כדי להריץ משימת שאילתה מתמשכת, צריך לבצע הגדרה נוספת. מידע נוסף זמין במאמר בנושא יצירת שאילתות מתמשכות.
שימוש בחלונית הפניה
בחלונית הפניה בכלי לעריכת שאילתות מוצג באופן דינמי מידע רלוונטי על טבלאות, תמונות מצב, תצוגות ותצוגות חומריות. בחלונית אפשר לראות תצוגה מקדימה של פרטי הסכימה של המשאבים האלה, או לפתוח אותם בכרטיסייה חדשה. אפשר גם להשתמש בחלונית הפניה כדי ליצור שאילתות חדשות או לערוך שאילתות קיימות על ידי הוספה של קטעי שאילתות או שמות שדות.
כדי ליצור שאילתה חדשה באמצעות החלונית Reference, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
לוחצים על שאילתת SQL.
לוחצים על quick_reference_all הפניה.
לוחצים על טבלה או תצוגה שסימנתם בכוכב או שהשתמשתם בהן לאחרונה. אפשר גם להשתמש בסרגל החיפוש כדי למצוא טבלאות ותצוגות.
לוחצים על View actions (הצגת פעולות) ואז על Insert query snippet (הוספת קטע קוד של שאילתה).
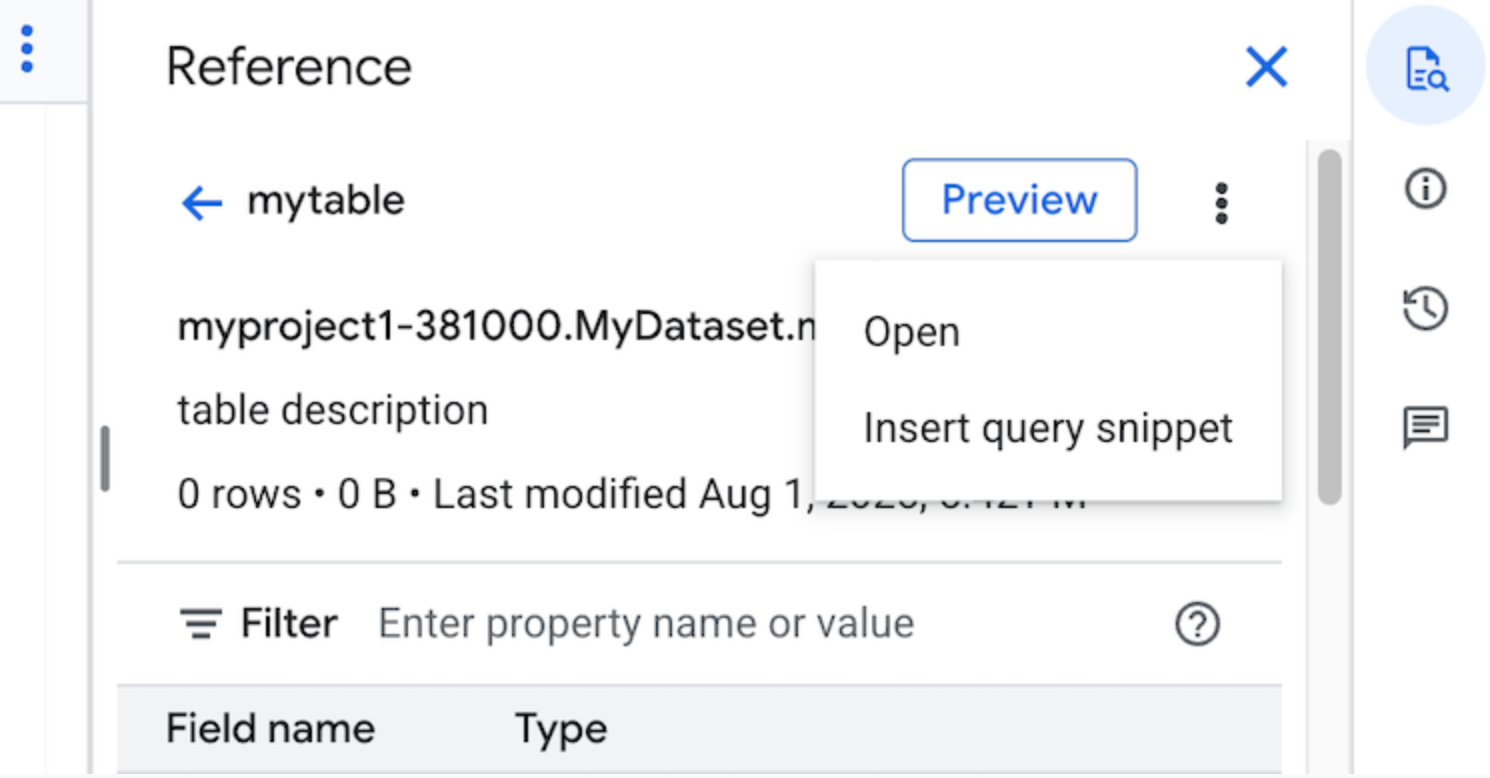
אופציונלי: אפשר לראות תצוגה מקדימה של פרטי הסכימה של הטבלה או התצוגה, או לפתוח אותם בכרטיסייה חדשה.
עכשיו אפשר לערוך את השאילתה באופן ידני או להוסיף שמות של שדות ישירות לשאילתה. כדי להוסיף שם של שדה, מצביעים על המקום בכלי לעריכת שאילתות שבו רוצים להוסיף את שם השדה ולוחצים עליו בחלונית הפניה.
הגדרות השאילתה
כשמריצים שאילתה, אפשר לציין את ההגדרות הבאות:
טבלת יעד לתוצאות השאילתה.
העדיפות של העבודה.
האם להשתמש בתוצאות של שאילתות שנשמרו במטמון.
הזמן הקצוב לתפוגה של העבודה באלפיות השנייה.
האם להשתמש במצב סשן.
סוג ההצפנה שבה יש להשתמש.
מספר הבייטים המקסימלי שהחיוב על השאילתה יתבסס עליו.
ניב ה-SQL שבו רוצים להשתמש.
המיקום שבו תופעל השאילתה. השאילתה חייבת לפעול באותו מיקום כמו הטבלאות שאליהן מתייחסים בשאילתה.
ההזמנה להרצת השאילתה.
מצב יצירה אופציונלית של משימות
מצב יצירה אופציונלית של משימות יכול לשפר את זמן הטעינה הכולל של שאילתות שמופעלות למשך זמן קצר, כמו שאילתות מלוחות בקרה או מעומסי עבודה של חיפוש נתונים. במצב הזה, השאילתה מופעלת והתוצאות מוחזרות בתוך שורה עבור הצהרות SELECT בלי שנדרש שימוש ב-jobs.getQueryResults כדי לאחזר את התוצאות. שאילתות שמשתמשות במצב יצירה אופציונלית של משימות לא יוצרות משימה כשהן מופעלות, אלא אם BigQuery קובע שיצירת משימה נדרשת כדי להשלים את השאילתה.
כדי להפעיל את מצב יצירה אופציונלית של משימות, מגדירים את השדה jobCreationMode של המופע QueryRequest לערך JOB_CREATION_OPTIONAL בגוף הבקשה jobs.query.
כשהערך של השדה הזה מוגדר ל-JOB_CREATION_OPTIONAL, מערכת BigQuery קובעת אם השאילתה יכולה להשתמש במצב האופציונלי של יצירת משימה. אם כן, BigQuery מריץ את השאילתה ומחזיר את כל התוצאות בשדה rows של התגובה. מכיוון שלא נוצרה משימה עבור השאילתה הזו, BigQuery לא מחזיר jobReference בגוף התגובה. במקום זאת, היא מחזירה שדה queryId, שבו אפשר להשתמש כדי לקבל תובנות לגבי השאילתה באמצעות INFORMATION_SCHEMA.JOBS. מכיוון שלא נוצרת משימה, אין jobReference שאפשר להעביר אל ממשקי ה-API jobs.get ו-jobs.getQueryResults כדי לחפש את השאילתות האלה.
אם BigQuery קובע שנדרשת משימה כדי להשלים את השאילתה, מוחזרת jobReference. כדי לגלות למה נוצרה עבודה עבור השאילתה, אפשר לבדוק את השדה job_creation_reason בתצוגה INFORMATION_SCHEMA.JOBS. במקרה כזה, צריך להשתמש ב-jobs.getQueryResults כדי לאחזר את התוצאות כשהשאילתה מסתיימת.
כשמשתמשים בערך JOB_CREATION_OPTIONAL, יכול להיות שהשדה jobReference לא יופיע בתשובה. כדאי לבדוק אם השדה קיים לפני שניגשים אליו.
כשמציינים JOB_CREATION_OPTIONAL בשאילתות מרובות הצהרות (סקריפטים), יכול להיות ש-BigQuery יבצע אופטימיזציה של תהליך הביצוע. במסגרת האופטימיזציה הזו, יכול להיות ש-BigQuery יקבע שאפשר להשלים את הסקריפט על ידי יצירת פחות משאבי עבודה ממספר ההצהרות הנפרדות, ואולי אפילו לבצע את כל הסקריפט בלי ליצור עבודה בכלל. האופטימיזציה הזו תלויה בהערכה של BigQuery לגבי הסקריפט, ויכול להיות שהיא לא תתבצע בכל מקרה. האופטימיזציה מתבצעת באופן אוטומטי לחלוטין על ידי המערכת, ולא נדרשים פעולות או אמצעי בקרה מצד המשתמש.
כדי להריץ שאילתה באמצעות מצב יצירה אופציונלית של משימות, בוחרים באחת מהאפשרויות הבאות:
המסוף
עוברים לדף BigQuery.
לוחצים על שאילתת SQL.
מזינים שאילתת GoogleSQL תקינה בעורך השאילתות.
לדוגמה, אפשר להריץ שאילתה במערך הנתונים הציבורי של BigQuery
usa_namesכדי לזהות את השמות הנפוצים ביותר בארצות הברית בין השנים 1910 ל-2013:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;לוחצים על עריכה > מצב שאילתה > יצירת משימה אופציונלית. כדי לאשר את הבחירה, לוחצים על אישור.
לוחצים על הפעלה.
BQ
-
במסוף Google Cloud , מפעילים את Cloud Shell.
בחלק התחתון של Google Cloud המסוף יתחיל סשן של Cloud Shell ותופיע הודעה של שורת הפקודה. Cloud Shell היא סביבת מעטפת שבה ה-CLI של Google Cloud מותקן ומוגדרים ערכים לפרויקט הקיים. הסשן יופעל תוך כמה שניות.
משתמשים בפקודה
bq queryומציינים את הדגל--job_creation_mode=JOB_CREATION_OPTIONAL. בדוגמה הבאה, הדגל--use_legacy_sql=falseמאפשר להשתמש בתחביר של GoogleSQL.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
מחליפים את QUERY בשאילתת GoogleSQL תקינה, ואת LOCATION באזור תקין שבו נמצא מערך הנתונים. לדוגמה, אפשר להריץ שאילתה במערך הנתונים הציבורי של BigQuery
usa_namesכדי לקבוע מהם השמות הנפוצים ביותר בארצות הברית בין השנים 1910 ל-2013:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'עבודת השאילתה מחזירה את הפלט בשורה בתגובה.
API
כדי להריץ שאילתה במצב יצירה אופציונלית של משימות באמצעות ה-API, מריצים שאילתה באופן סינכרוני ומאכלסים את המאפיין QueryRequest. כוללים את המאפיין jobCreationMode ומגדירים את הערך שלו ל-JOB_CREATION_OPTIONAL.
בודקים את התשובה. אם jobComplete שווה ל-true ו-jobReference ריק, קוראים את התוצאות מהשדה rows. אפשר גם לקבל את queryId מהתשובה.
אם jobReference מופיע, אפשר לבדוק את jobCreationReason כדי להבין למה נוצרה משימה על ידי BigQuery. כדי לקבל את תוצאות הסקר, צריך להתקשר למספר getQueryResults.
סקר עד ש-jobComplete שווה ל-true. בודקים אם יש שגיאות ואזהרות ברשימה errors.
Java
גרסה זמינה: 2.51.0 ואילך
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
כדי להריץ שאילתה עם שרת proxy, אפשר לעיין במאמר בנושא הגדרת שרת proxy.
Python
גרסה זמינה: 3.34.0 ומעלה
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
צומת
הגרסה הזמינה: 8.1.0 ואילך
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
המשך
גרסה זמינה: 1.69.0 ומעלה
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Goהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Go API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
מנהל התקן של JDBC
גרסה זמינה: JDBC v1.6.1 ומעלה
צריך להגדיר את JobCreationMode=2 במחרוזת החיבור.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
מנהל התקן של ODBC
גרסה זמינה: ODBC v3.0.7.1016 ואילך
צריך להגדיר את הערך JobCreationMode=2 בקובץ .ini.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
שאילתות גלובליות
השאילתות מורצות במיקום של הנתונים שהן מפנות אליהם. עם זאת, אם שאילתה מפנה לנתונים שמאוחסנים ביותר ממיקום אחד, מתבצעת שאילתה גלובלית. כשמריצים שאילתה עם אחזור נתונים גלובלי, מערכת BigQuery יכולה לאסוף את כל הנתונים הנדרשים ממיקומים שונים במקום אחד, להריץ שאילתה ולהחזיר את התוצאות. שאילתות גלובליות מחייבות העברת נתונים בין מיקומים, ולכן הן דורשות הרשאות נוספות ועשויות להיות כרוכות בעלויות נוספות.
מידע נוסף על שאילתות גלובליות זמין במאמר שאילתות גלובליות.
מכסות
מידע על מכסות שקשורות לשאילתות אינטראקטיביות ולשאילתות אצווה זמין במאמר בנושא עבודות של שאילתות.
כדי לפתור בעיות שקשורות לשגיאות במכסות של שאילתות, אפשר לעיין בדף פתרון הבעיות ב-BigQuery. שגיאות המכסות הבאות ומידע לפתרון בעיות שקשורות אליהן רלוונטיים ישירות לשאילתות:
- שגיאות שקשורות למגבלות על תור השאילתות
- שגיאות שקשורות למכסת הייבוא של טבלאות או להוספה של שאילתות לאפליקציה
מעקב אחרי שאילתות
אפשר לקבל מידע על שאילתות בזמן שהן מופעלות באמצעות כלי הבדיקה של העבודות או באמצעות שאילתה של התצוגה INFORMATION_SCHEMA.JOBS_BY_PROJECT.
הרצה יבשה
הרצת סימולציה ב-BigQuery מספקת את המידע הבא:
- הערכה של החיובים במצב על פי דרישה
- אימות השאילתה
- מספר הבייטים המשוער שעובדו על ידי השאילתה במצב קיבולת
הפעלות הרצה יבשה לא משתמשות במשבצות זמן לשאילתות, ולא תחויבו על הפעלת הרצה יבשה. תוכלו להשתמש בהערכה שמתקבלת מהרצה יבשה כדי לחשב את עלויות השאילתות במחשבון התמחור.
הרצת בדיקה
כדי לבצע הרצה יבשה:
המסוף
נכנסים לדף BigQuery.
מזינים את השאילתה בעורך השאילתות.
אם השאילתה תקינה, יופיע אוטומטית סימן וי לצד כמות הנתונים שהשאילתה תעבד. אם השאילתה לא תקינה, יופיע סימן קריאה לצד הודעת שגיאה.
BQ
מזינים שאילתה כמו זו שבהמשך באמצעות הדגל --dry_run.
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
אם השאילתה תקינה, הפקודה תחזיר את התגובה הבאה:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
כדי לבצע הרצה יבשה באמצעות ה-API, שולחים עבודת שאילתה עם dryRun שמוגדר ל-true בסוג JobConfiguration.
המשך
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Goהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Go API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Node.js
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
PHP
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי PHPהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery PHP API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Python
מגדירים את המאפיין QueryJobConfig.dry_run לערך True. הפונקציה Client.query() תמיד מחזירה QueryJob שהושלם כשמספקים לה הגדרת שאילתה של הרצה יבשה.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
המאמרים הבאים
- איך מנהלים עבודות של שאילתות
- איך מציגים את היסטוריית השאילתות
- איך שומרים ומשתפים שאילתות
- מידע על תורים של שאילתות
- איך כותבים תוצאות של שאילתות