
本教學課程說明如何使用 Colab Enterprise 資料科學代理,透過自然語言提示建構機器學習 (ML) 模型。
在本教學課程中,您將使用愛荷華州酒類零售銷售公開資料集,建立機器學習模型來預測酒類銷售量。這項 AI 輔助代理程式可讓您直接在筆記本中使用自然語言提示詞,編寫、說明及排解程式碼問題,加快資料科學工作流程。
本教學課程適用於資料從業人員。
目標
在本教學課程中,您將瞭解如何使用資料科學代理執行下列工作:
- 對愛荷華州酒類零售銷售公開資料集執行探索性資料分析 (EDA),瞭解資料分布情形、檢查是否有遺漏值,並驗證整體資料品質。
- 找出所有產品中酒精銷量最高的商店。
- 使用 BigQuery ML 建構、訓練及評估模型,預測酒類銷售量。
- 生成並總結重要洞察和模型成效。
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
如要根據預測用量估算費用,請使用 Pricing Calculator。
完成本文所述工作後,您可以刪除建立的資源,避免繼續計費,詳情請參閱「清除所用資源」。
事前準備
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
啟用 BigQuery、Gemini for Google Cloud、Dataform 和 Compute Engine API。
啟用 API 時所需的角色
如要啟用 API,您需要服務使用情形管理員 IAM 角色 (
roles/serviceusage.serviceUsageAdmin),其中包含serviceusage.services.enable權限。瞭解如何授予角色。新專案會自動啟用 BigQuery API。
必要的角色
如果您建立新專案,則已具備完成本教學課程的所有必要權限。如果您使用現有專案,請要求管理員授予下列角色。
建立及執行筆記本的權限
如要取得建立及執行筆記本所需的權限,請要求管理員授予您專案的「BigQuery Studio 使用者」 (roles/bigquery.studioUser) IAM 角色。如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和組織的存取權」。
如要查看建立及執行筆記本所需的權限,請參閱「建立筆記本」頁面的設定步驟。
如要進一步瞭解 BigQuery Identity and Access Management (IAM),請參閱「使用存取控管功能搭配 IAM」。
建立 Colab Enterprise 筆記本並連線至執行階段
Colab Enterprise 筆記本是 BigQuery Studio 程式碼資產,由 Dataform 提供支援。您可以使用筆記本,透過 SQL、Python 和其他常見的套件和 API,完成分析和機器學習工作流程。
如要建立新筆記本並連線至預設執行階段,請按照下列步驟操作:
前往「BigQuery」頁面
在左側窗格中展開專案,然後按一下「Notebooks」。
依序點選「新增筆記本」>「空白筆記本」。
按一下 [儲存]。
如要查看新筆記本,請按一下「筆記本」分頁標籤。你可能需要按一下「重新整理」。
如要為未命名的筆記本重新命名,請按一下 more_vert「開啟動作」,然後選擇「重新命名」。
在「Notebook name」(筆記本名稱) 中輸入
predict_liquor_sales,然後按一下「Rename」(重新命名)。按一下「
predict_liquor_sales」分頁標籤。在筆記本工具列中,按一下「連線」,將筆記本連線至預設執行階段環境。
使用資料科學代理分析資料
資料科學代理是 Gemini 輔助助理,可直接在筆記本中編寫、說明及排解程式碼問題。從探索性資料分析到生成機器學習預測和預報,這項工具都能協助您完成各種工作,包括:
- 生成計畫。建立逐步計畫,解決資料科學問題。
- 探索及清理資料。找出遺漏值、離群值,並以視覺化方式呈現分布情形。
- 特徵工程:轉換類別特徵並建立新特徵。
- 模型訓練與評估。訓練線性迴歸或隨機森林等模型,並比較效能。
在本教學課程中,您將使用資料科學代理分析愛荷華州酒類零售銷售公開資料集中的資料,並建立預測酒類銷售量的模型。
如要使用 資料科學代理 分析資料,請按照下列步驟操作:
在
predict_liquor_sales筆記本中,如果 Gemini 對話視窗未開啟,請點選「spark」切換 Colab 中的 Gemini,開啟對話方塊。在對話介面中輸入下列提示詞:
Analyze the liquor sales data from bigquery-public-data.iowa_liquor_sales.sales by performing exploratory data analysis. Find the stores that sold the most gallons of alcohol across all products. Then, create a model that predicts liquor sales by store by using BigQuery ML. Visualize the results, evaluate the model, summarize the model's performance, and provide any key insights.確認模型已設為「Gemini 3.0 Flash」。
按一下 [傳送]。
查看代理生成的計畫。方案類似如下所示。
「我已分析愛荷華州酒類銷售資料的要求,並制定策略計畫。由於資料儲存在 BigQuery 中,且您已指定使用 BigQuery ML,因此我們將從資料探索開始,找出績效最佳的商店,然後建立迴歸模型來預測銷售量。以下是逐步操作計畫:
- 資料探索與剖析:初步探索「bigquery-public-data.iowa_liquor_sales.sales」資料表,瞭解資料分布情形、檢查是否有遺漏值,並驗證商店資訊、銷售量和銷售金額等重要資料欄的資料品質。
- 找出銷售量最高的商店:彙整各商店所有產品的酒精總銷售量,找出成效最佳的商店。
- 準備資料:彙整各商店的酒類銷售資料,並選取預測模型適用的特徵,準備訓練資料。
- 模型開發:使用 BigQuery ML 訓練迴歸模型,預測每間商店的酒類銷售量。
- 模型評估:使用標準迴歸指標評估訓練後模型的效能。
- 模型預測:使用訓練完成的模型產生酒類銷售預測。
- 視覺化:建立散布圖,比較預測的酒類銷售額與實際值,以視覺化方式評估模型的準確率。
- 完成工作:總結模型成效、提供商店銷售量的主要洞察資料,並完成分析。」
查看企劃書後,按一下「接受並執行」。代理程式會生成第一個子工作:探索及剖析資料。代理程式會暫停,直到您查看並接受代碼為止。如果代理程式正在等待使用者輸入內容,系統會以綠色背景顯示生成的儲存格。
查看生成的程式碼儲存格和代理提供的推論。
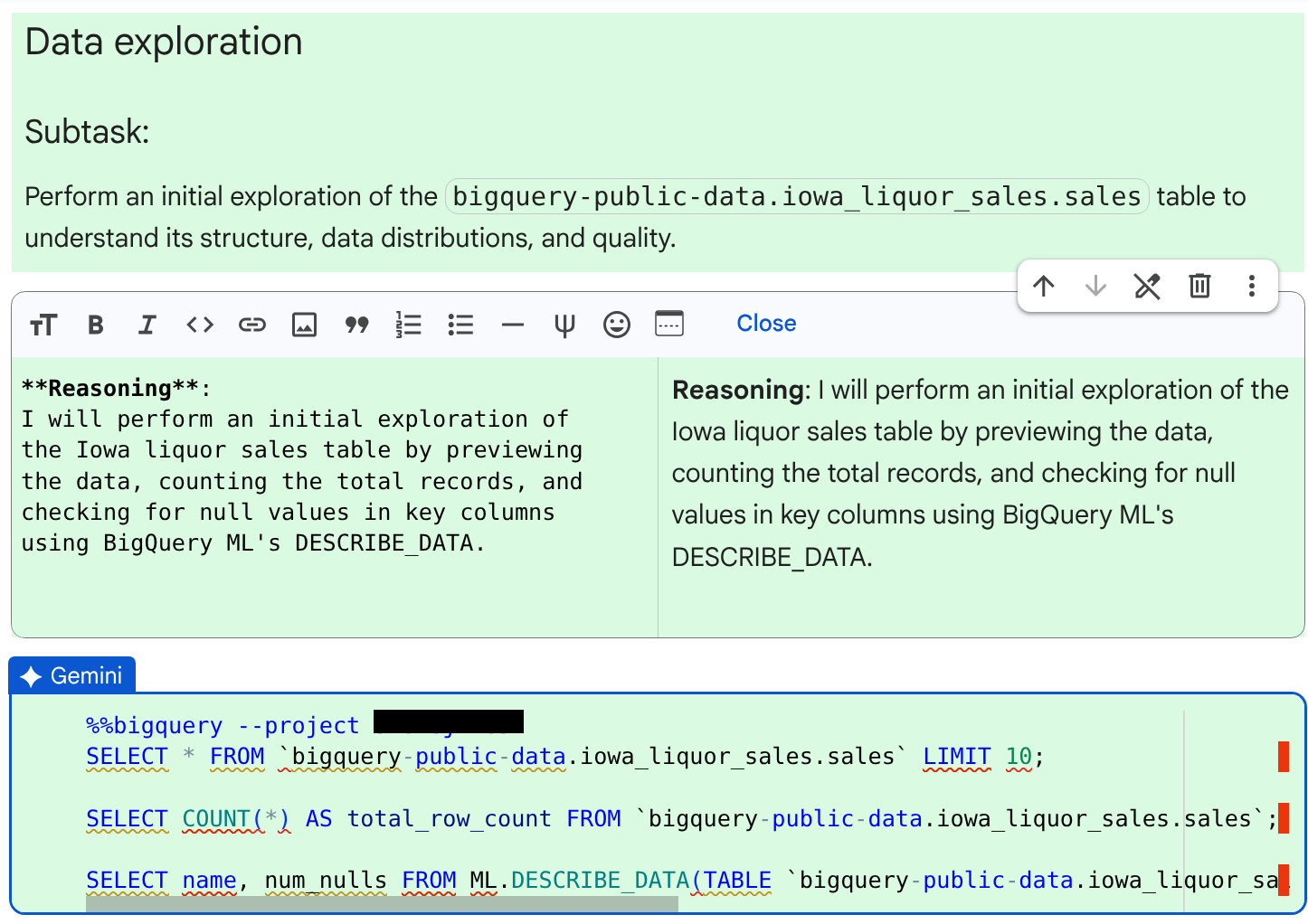
按一下「接受並執行」。如果代理程式在處理時遇到問題,會說明如何修正問題,並提示您接受修改後的程式碼。
查看程式碼儲存格中的輸出內容。
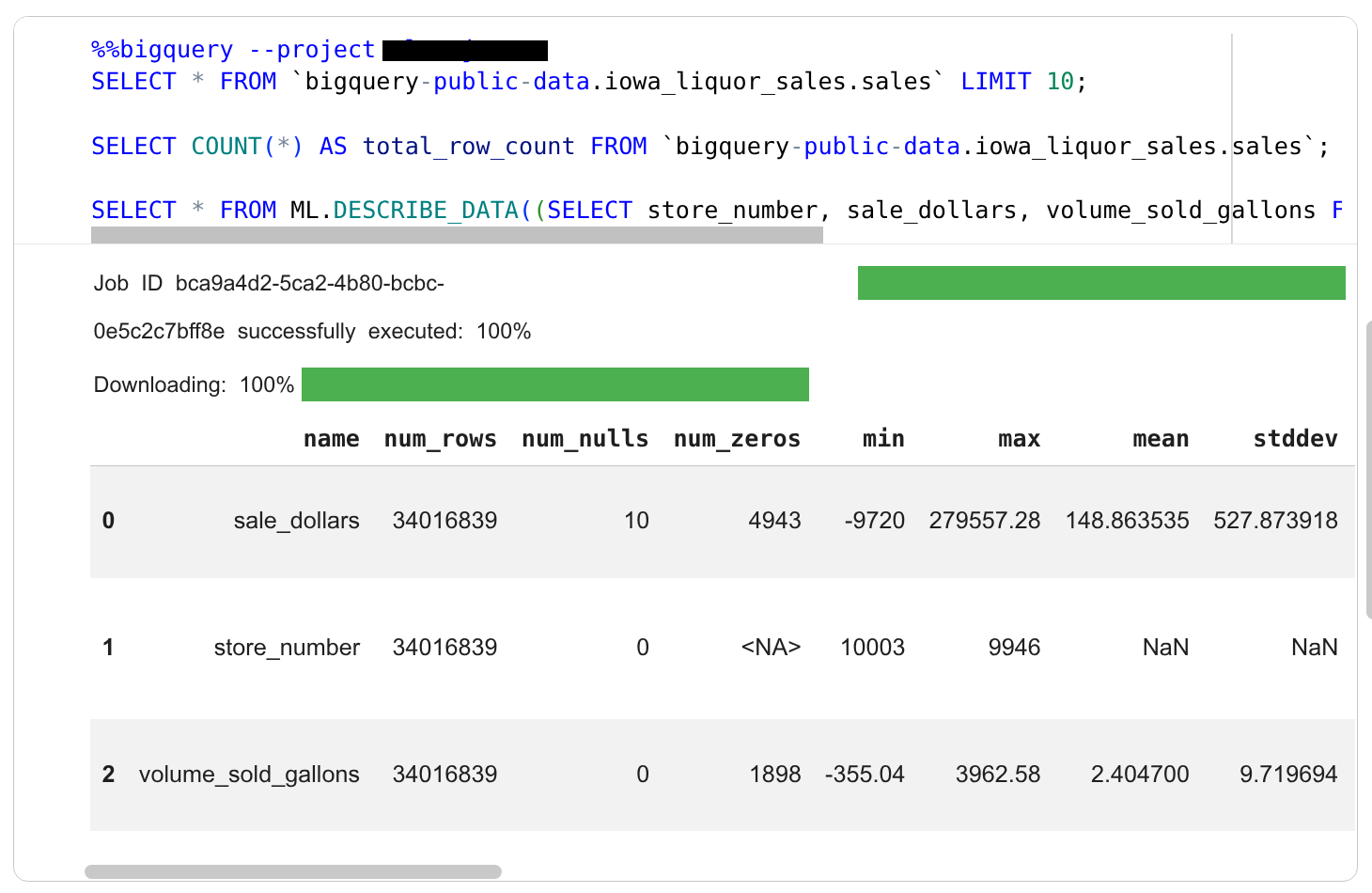
在結果下方,代理程式會建立新儲存格,完成下一個子工作:找出酒類銷售額最高的商店。
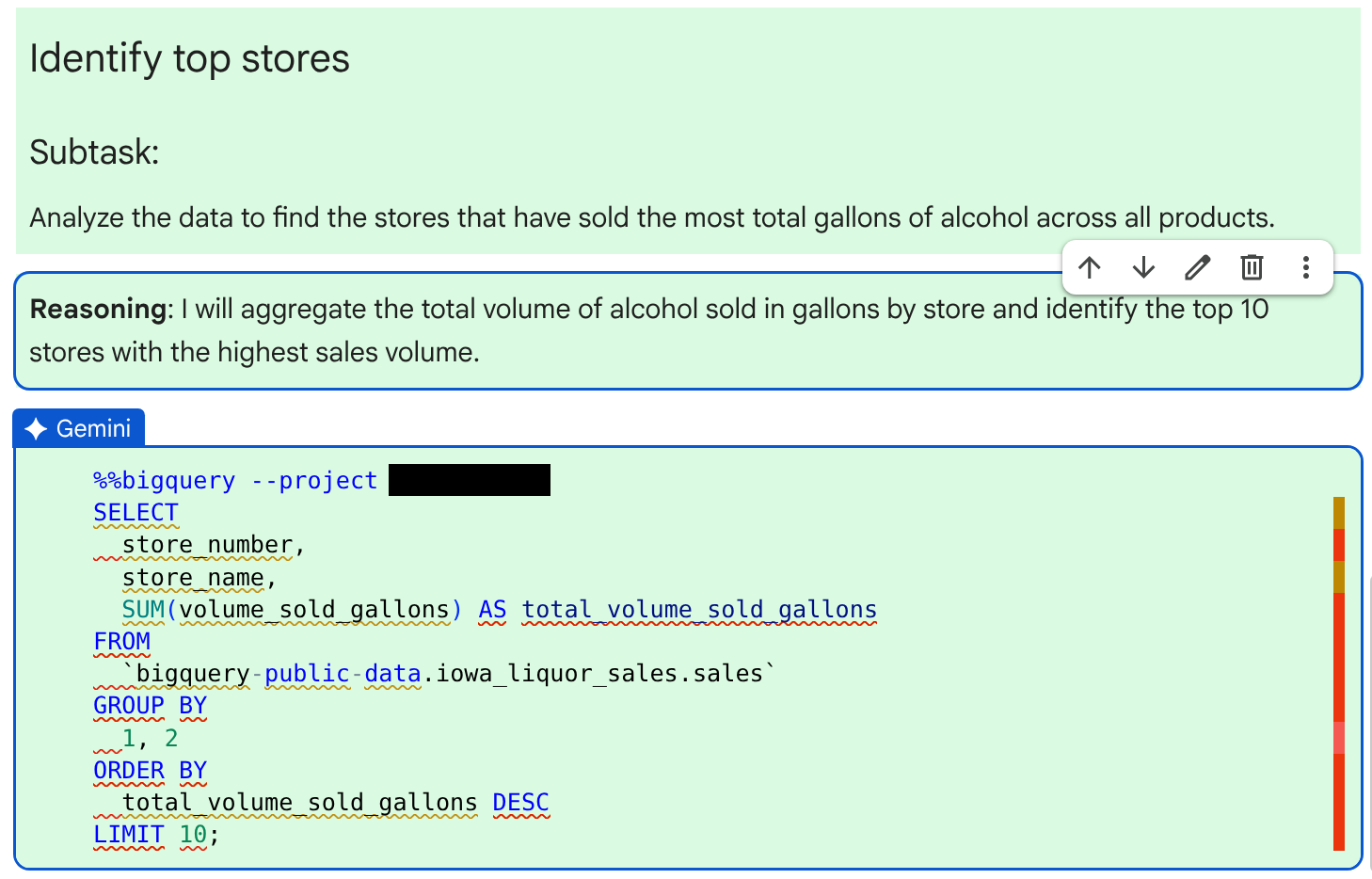
查看生成的 SQL 程式碼,查詢酒精銷售量最高的商店資料。如要查看代理程式的推論過程,請查看程式碼上方的「推論」文字儲存格。確認程式碼正確無誤後,按一下「接受並執行」。
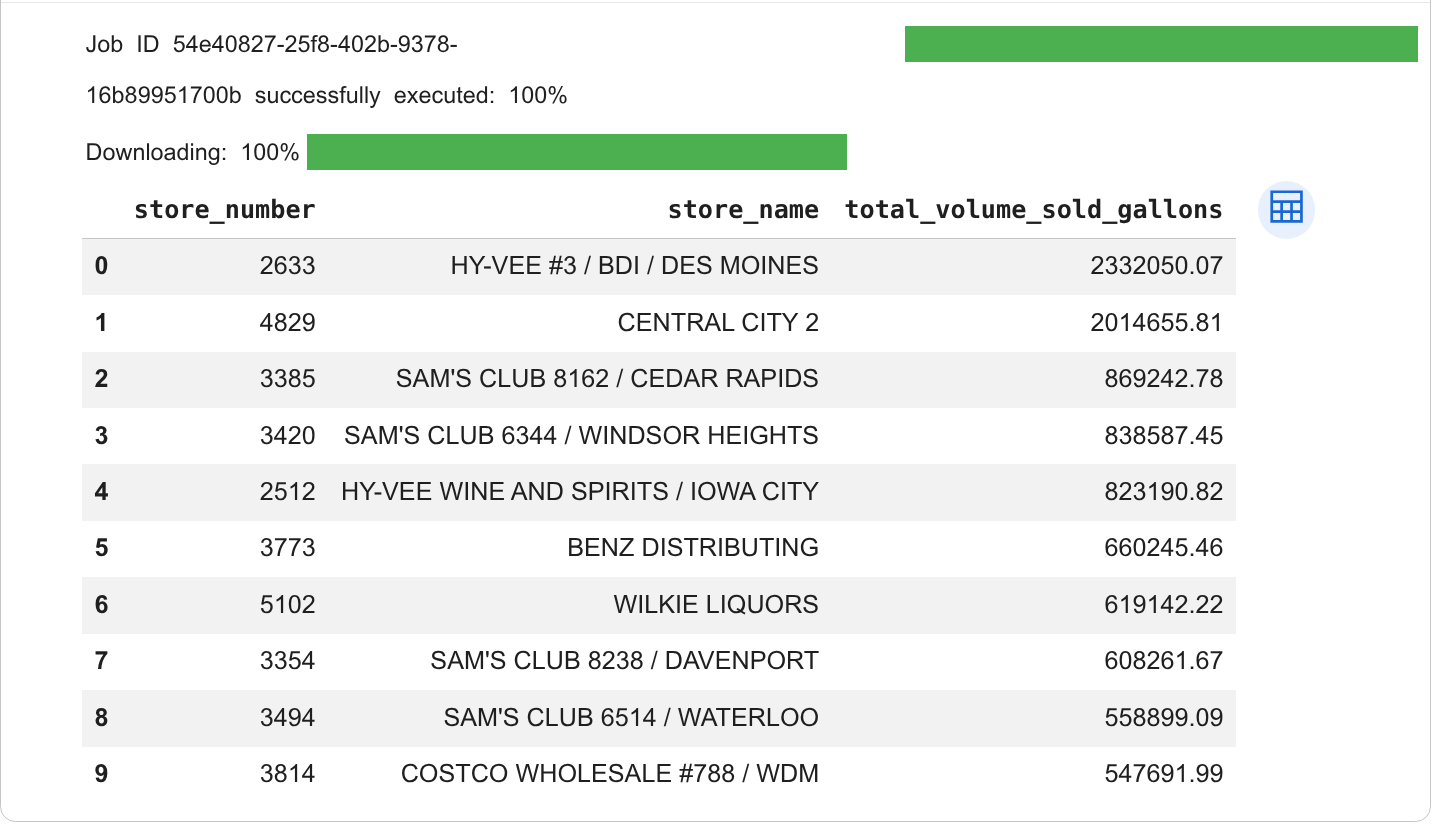
查看儲存格輸出內容中的查詢結果。結果類似下方:
查看代理程式為下一個子工作生成的程式碼和推論:準備模型訓練資料。
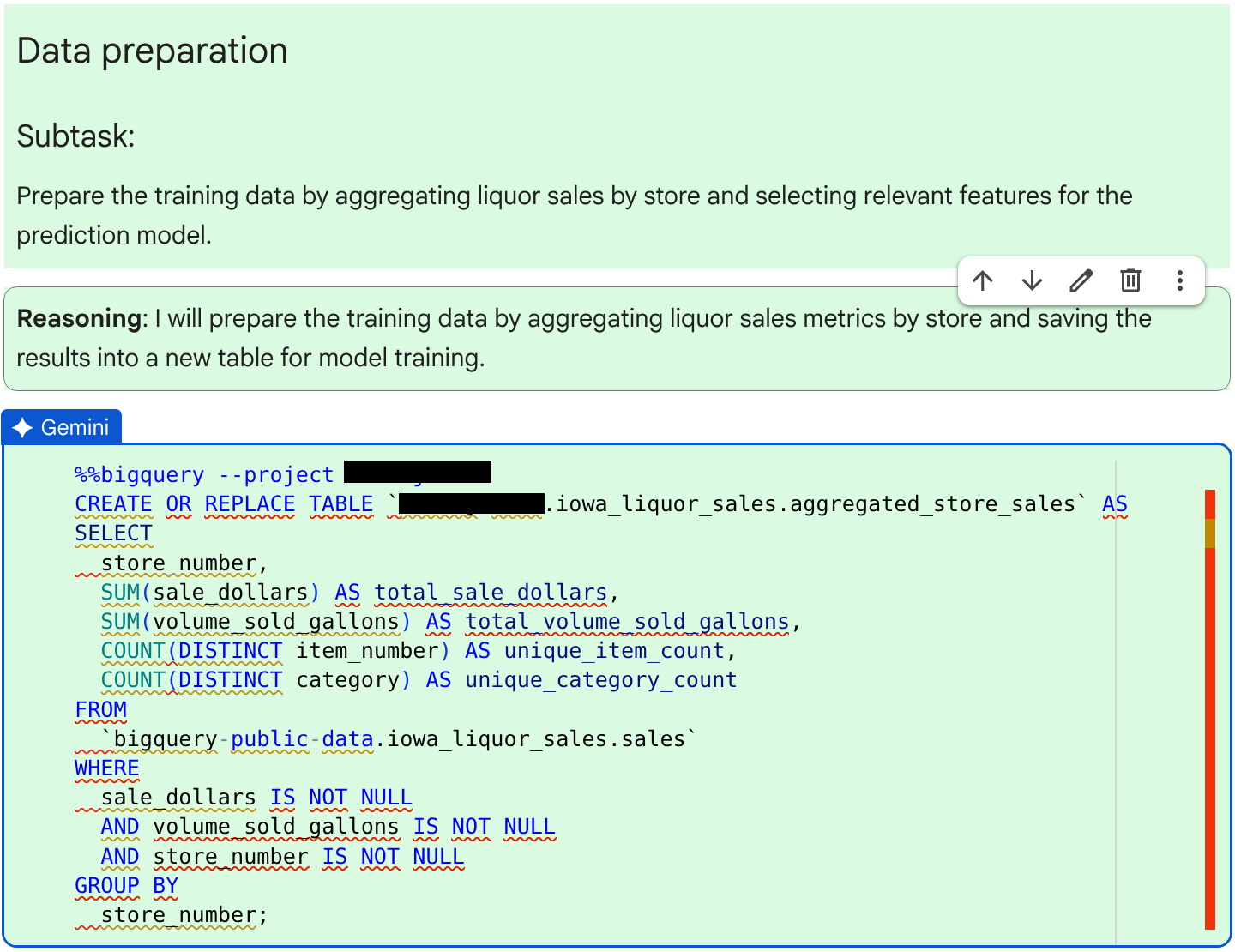
確認 SQL 程式碼正確無誤後,請按一下「接受並執行」。
查看程式碼儲存格中的輸出內容。畫面會顯示類似以下的訊息:
JOB ID 123456 successfully executed.查看代理程式為下一個子工作生成的程式碼和推論:訓練迴歸模型。
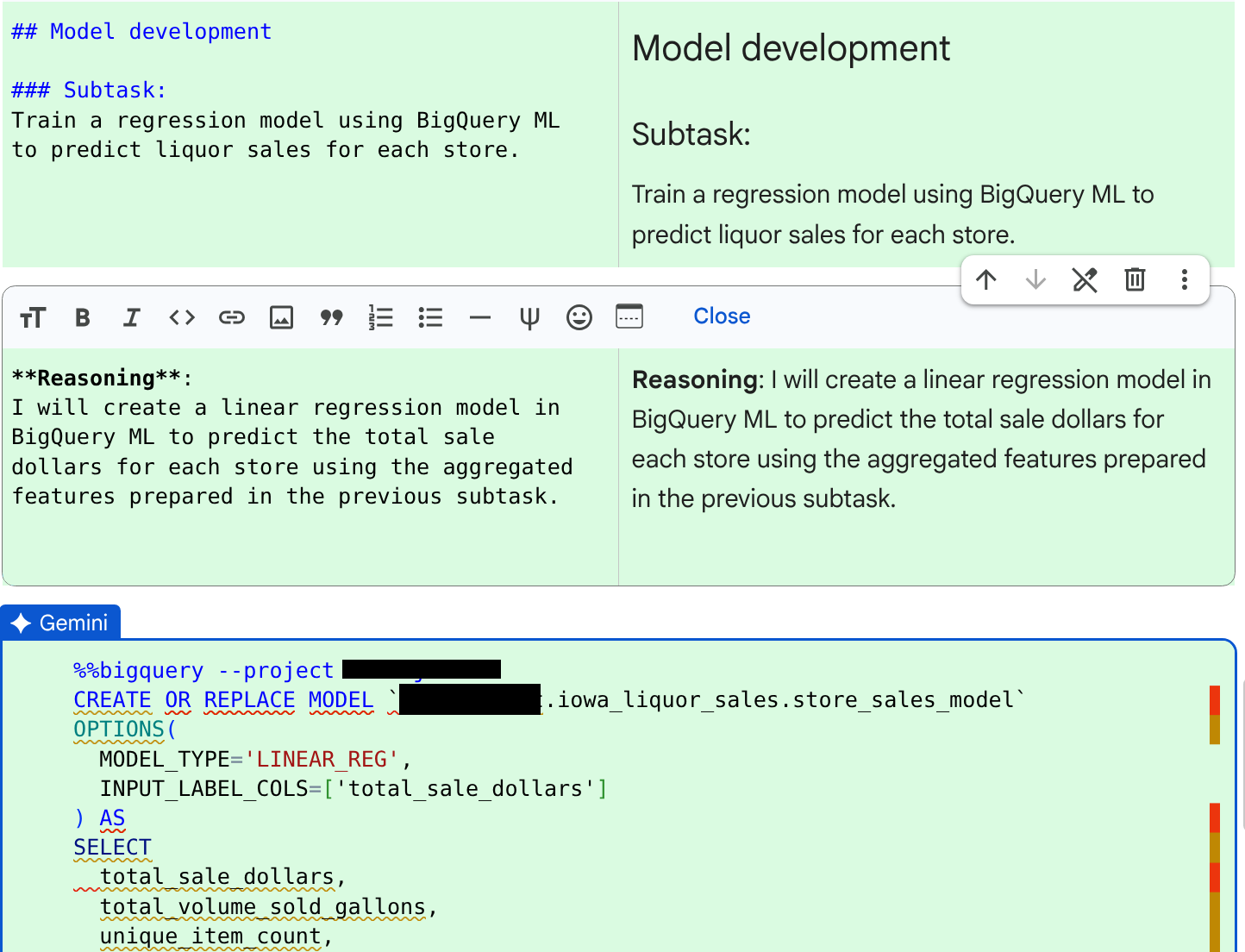
查看程式碼和原因後,按一下「接受並執行」。
查看程式碼儲存格中的輸出內容。畫面會顯示類似以下的訊息:
JOB ID 123456 successfully executed.查看代理程式為下一個子工作生成的程式碼和推論: 模型評估。
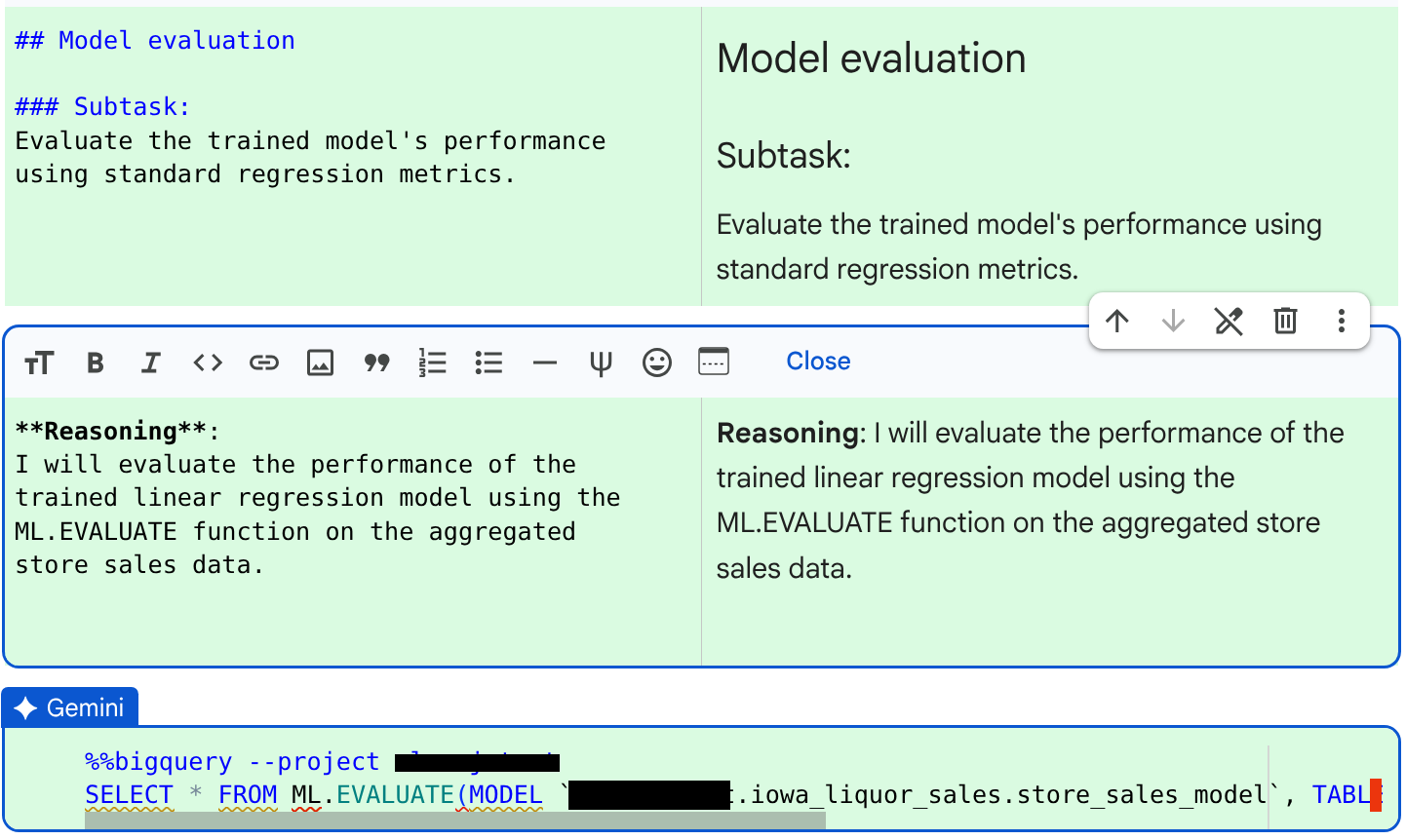
查看程式碼和原因後,按一下「接受並執行」。
查看程式碼儲存格中的輸出內容。
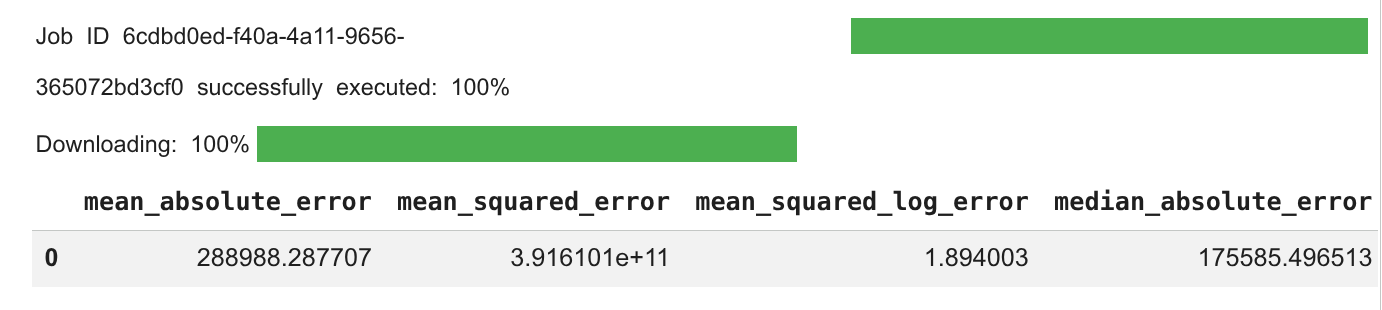
查看代理程式為下一個子工作 (產生預測) 生成的程式碼和推論。
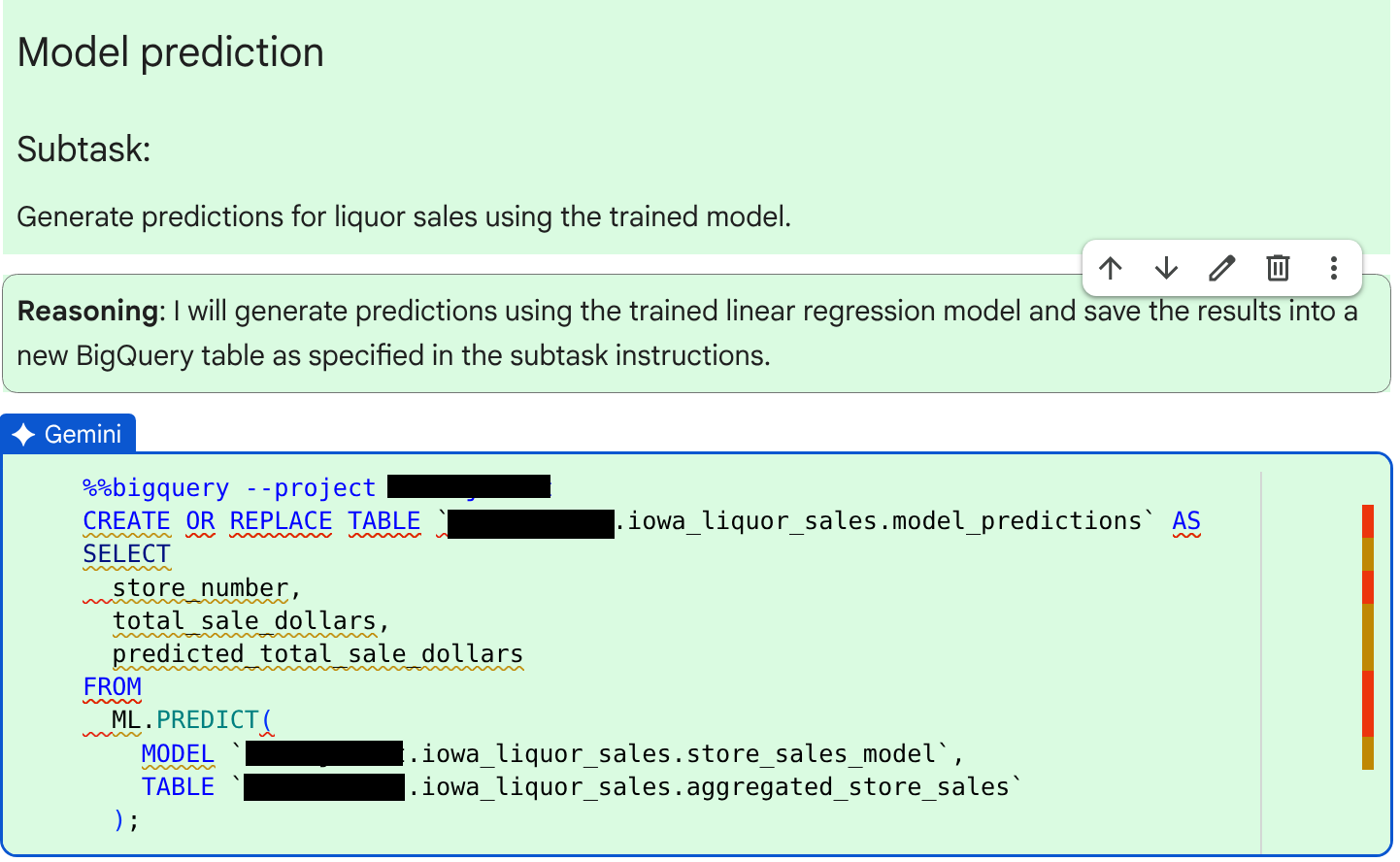
查看程式碼和原因後,按一下「接受並執行」。
查看程式碼儲存格中的輸出內容。畫面會顯示類似以下的訊息:
JOB ID 123456 successfully executed.查詢執行完畢後,代理程式會為下一個子工作建立程式碼儲存格:將資料視覺化。
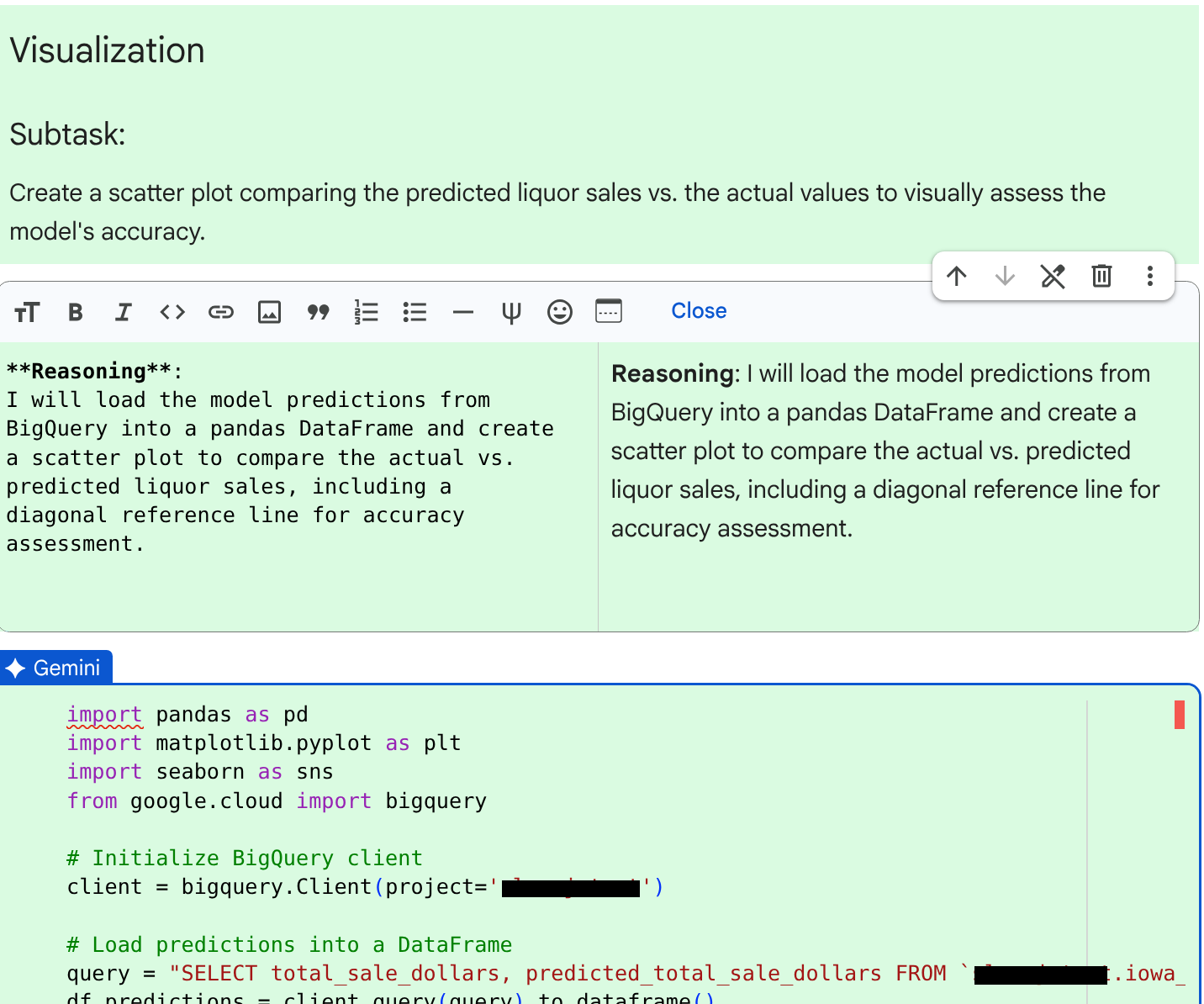
查看程式碼和原因後,按一下「接受並執行」。
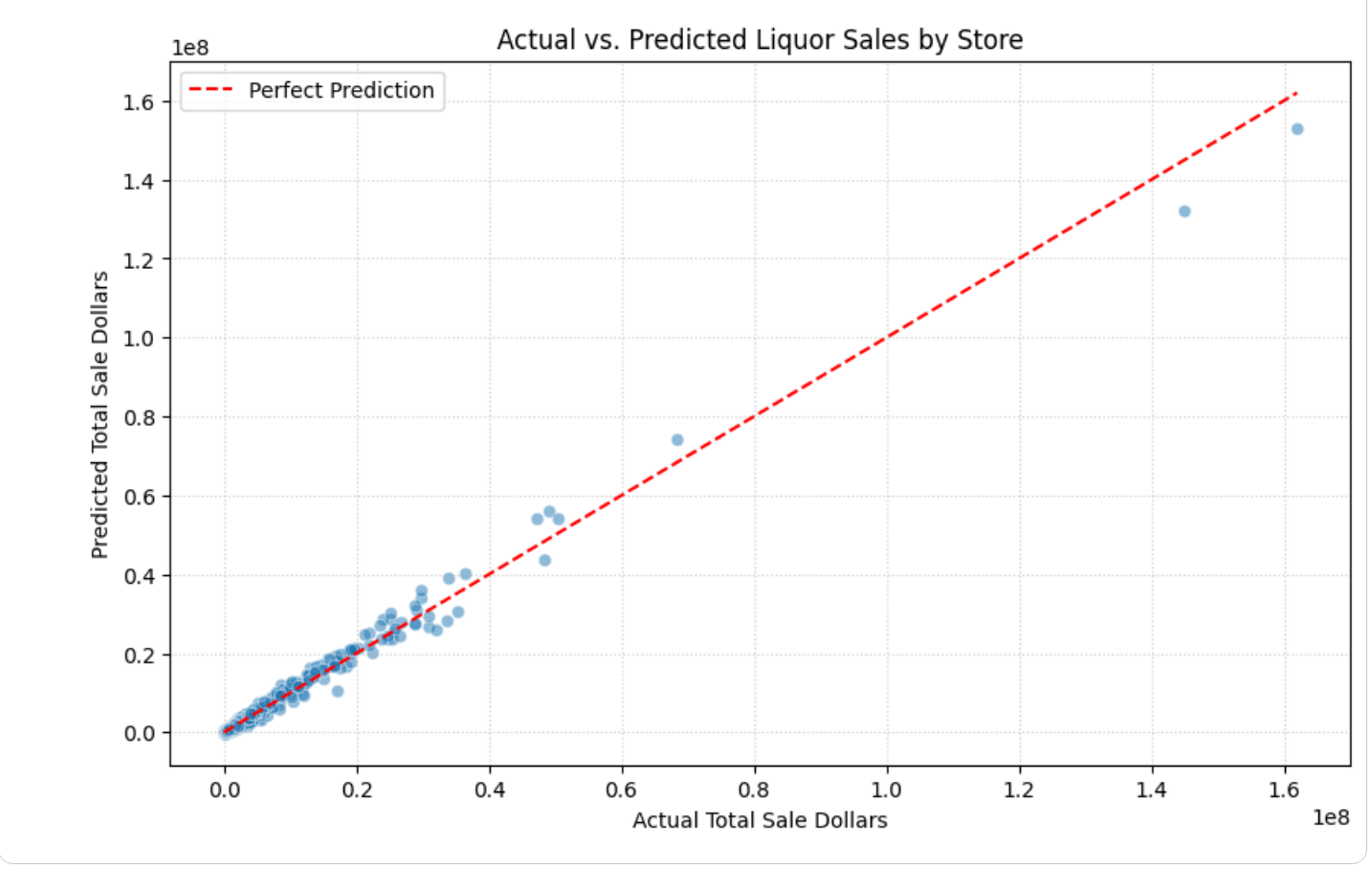
查看程式碼儲存格中的輸出內容。您會看到圖表,其中繪製了實際與預測的酒類銷售量。圖表看起來類似如下:
圖表生成後,AI 助理會根據結果生成摘要,並提供重要發現和洞察。
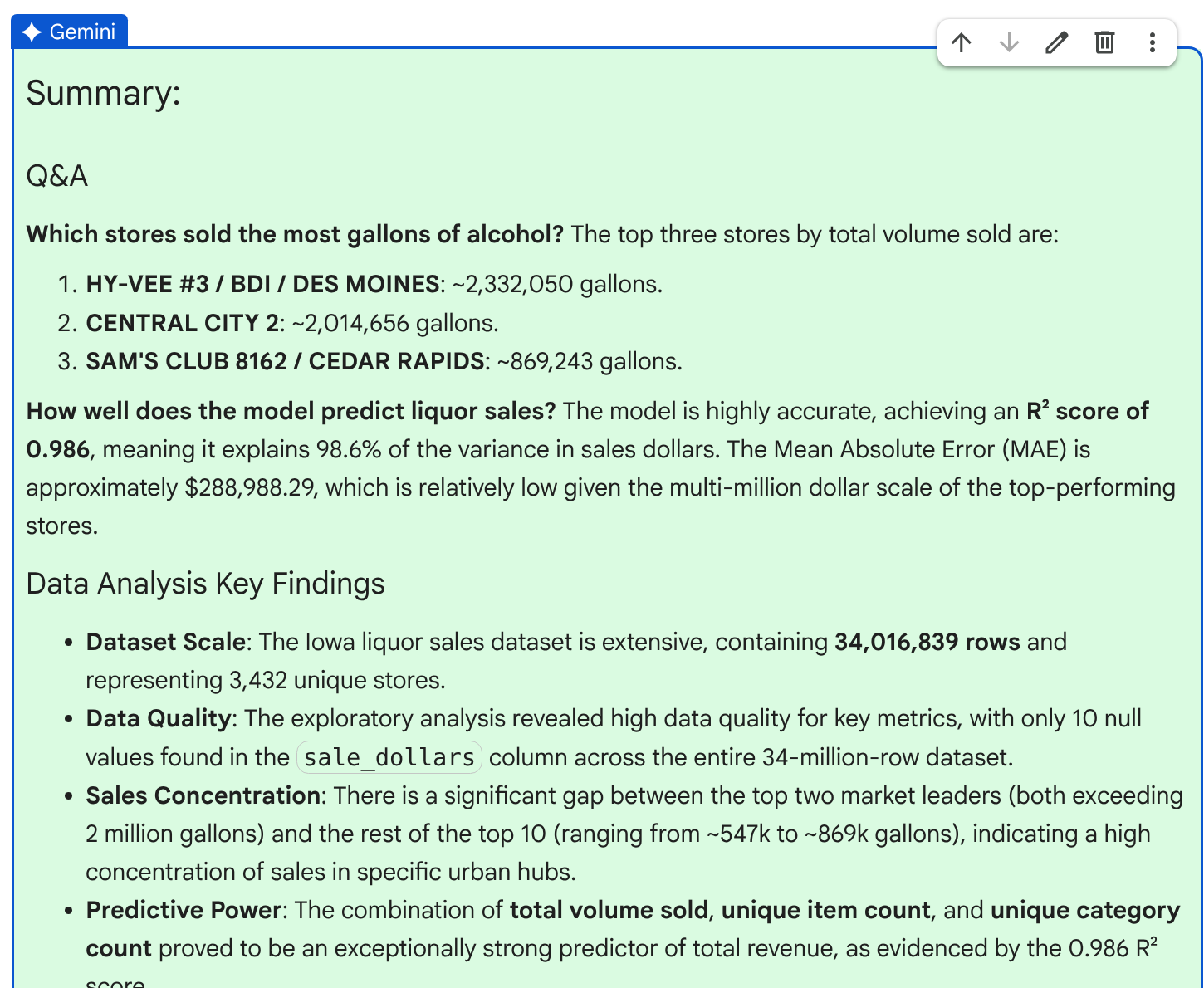
查看摘要後,按一下「接受」即可完成計畫。
清除所用資源
為避免因為本教學課程所用資源,導致系統向 Google Cloud 帳戶收取費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
如要避免系統向您的 Google Cloud 帳戶收取本教學課程所用資源的費用,請刪除您建立的筆記本。如要刪除筆記本,請按照下列步驟操作:前往「BigQuery」頁面
在左側窗格中展開專案,然後按一下「Notebooks」。
按一下
predict_liquor_sales筆記本的 more_vert「Open actions」(開啟動作),然後選擇「Delete」(刪除)。按一下「刪除」即可移除筆記本。
後續步驟
- 瞭解資料科學代理的功能。
- 進一步瞭解 BigQuery 中的 Colab Enterprise 筆記本。
- 參閱 Gemini in BigQuery 說明文件。