

Tabular Workflows è un insieme di pipeline integrate, completamente gestite e scalabili per il machine learning end-to-end con dati tabellari. Sfrutta la tecnologia di Google per lo sviluppo di modelli e ti offre opzioni di personalizzazione per soddisfare le tue esigenze.
Vantaggi
- Completamente gestito: non devi preoccuparti di aggiornamenti, dipendenze e conflitti.
- Facile da scalare: non è necessario riprogettare l'infrastruttura man mano che i workload o i set di dati aumentano.
- Ottimizzato per le prestazioni: l'hardware giusto viene configurato automaticamente in base ai requisiti del flusso di lavoro.
- Integrazione profonda: la compatibilità con i prodotti della suite MLOps di Gemini Enterprise Agent Platform, come Gemini Enterprise Agent Platform Pipelines e Vertex AI Experiments, ti consente di eseguire molti esperimenti in un breve periodo di tempo.
Panoramica tecnica
Ogni workflow è un'istanza gestita di Gemini Enterprise Agent Platform Pipelines.
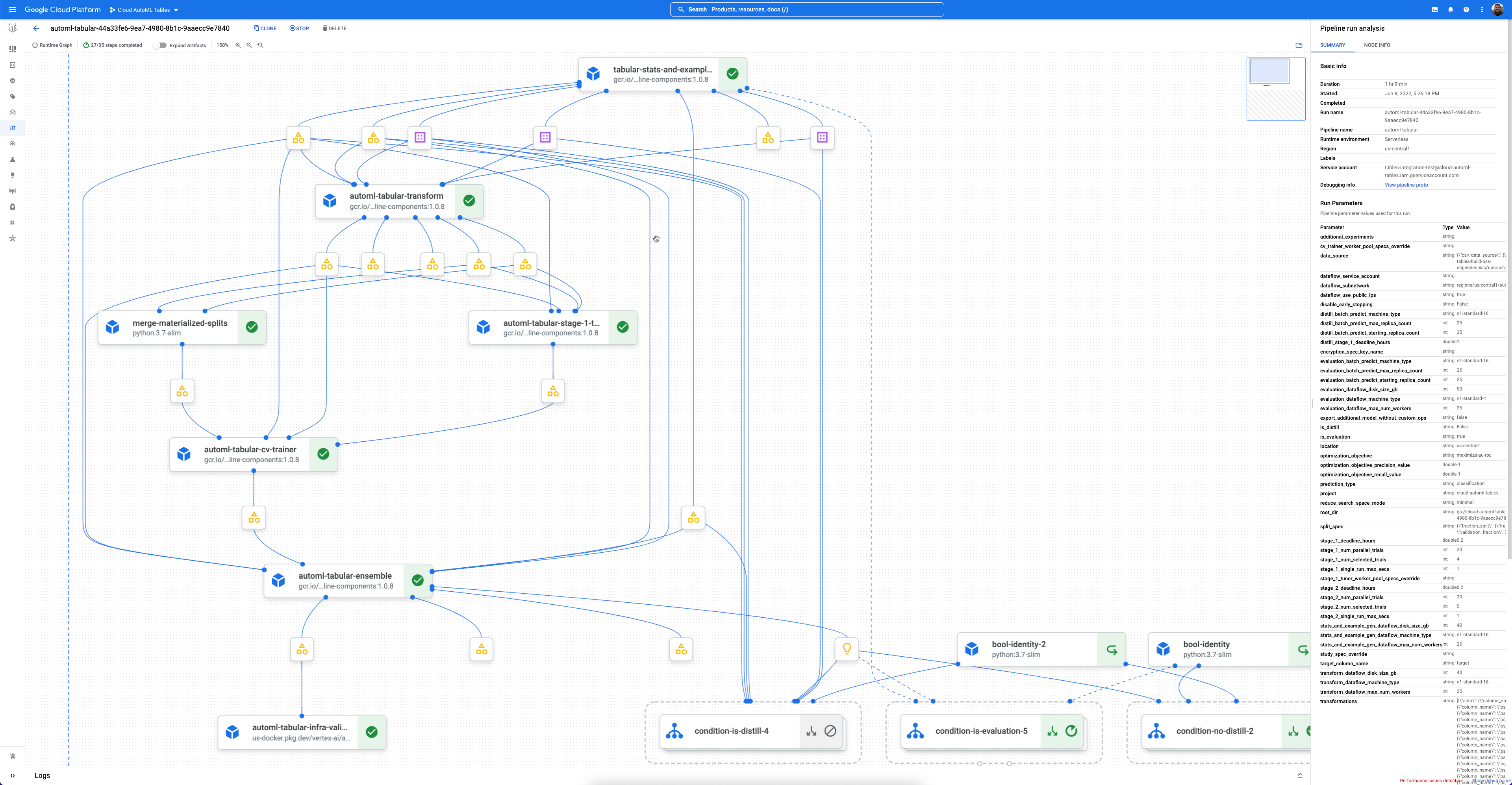
Gemini Enterprise Agent Platform Pipelines è un servizio serverless che esegue pipeline Kubeflow. Puoi utilizzare le pipeline per automatizzare e monitorare le attività di machine learning e preparazione dei dati. Ogni passaggio di una pipeline esegue una parte del workflow della pipeline. Ad esempio, una pipeline può includere passaggi per dividere i dati, trasformare i tipi di dati e addestrare un modello. Poiché i passaggi sono istanze dei componenti della pipeline, hanno input, output e un'immagine container. Gli input dei passaggi possono essere impostati dagli input della pipeline o possono dipendere dall'output di altri passaggi all'interno di questa pipeline. Queste dipendenze definiscono il workflow della pipeline come un grafo diretto aciclico.
Inizia
Nella maggior parte dei casi, definisci ed esegui la pipeline utilizzando l'Google Cloud SDK Pipeline Components. Il seguente codice campione illustra questo processo. Tieni presente che l'implementazione effettiva del codice potrebbe essere diversa.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
Per esempi di colab e notebook, contatta il tuo rappresentante di vendita o compila un modulo di richiesta.
Controllo delle versioni e manutenzione
I workflow tabellari dispongono di un sistema di controllo delle versioni efficace che consente aggiornamenti e miglioramenti continui senza modifiche sostanziali alle applicazioni.
Ogni flusso di lavoro viene rilasciato e aggiornato nell'ambito dell'Google Cloud SDK Pipeline Components. Gli aggiornamenti e le modifiche a qualsiasi flusso di lavoro vengono rilasciati come nuove versioni del flusso di lavoro. Le versioni precedenti di ogni flusso di lavoro sono sempre disponibili tramite le versioni precedenti dell'SDK. Se la versione dell'SDK è bloccata, anche la versione del flusso di lavoro è bloccata.
Workflow disponibili
Agent Platform fornisce i seguenti flussi di lavoro tabulari:
| Nome | Tipo | Disponibilità |
|---|---|---|
| Feature Transform Engine | Feature Engineering | Anteprima pubblica |
| AutoML end-to-end | Classificazione e regressione | In disponibilità generale |
| Previsione | Previsione | Anteprima pubblica |
Per ulteriori informazioni e notebook di esempio, contatta il tuo rappresentante di vendita o compila un modulo di richiesta.
Motore di trasformazione delle caratteristiche
Feature Transform Engine esegue la selezione e le trasformazioni delle caratteristiche. Se la selezione delle funzionalità è attivata, Feature Transform Engine crea un insieme classificato di funzionalità importanti. Se le trasformazioni delle caratteristiche sono attivate, Feature Transform Engine elabora le caratteristiche per garantire che l'input per l'addestramento e la pubblicazione del modello sia coerente. Feature Transform Engine può essere utilizzato da solo o insieme a uno qualsiasi dei flussi di lavoro di addestramento tabellare. Supporta sia TensorFlow che framework non TensorFlow.
Per saperne di più, consulta Ingegneria delle funzionalità.
Workflow tabulari per la classificazione e la regressione
Workflow tabulare per AutoML end-to-end
Il flusso di lavoro tabulare per AutoML end-to-end è una pipeline AutoML completa per le attività di classificazione e regressione. È simile all'API AutoML, ma ti consente di scegliere cosa controllare e cosa automatizzare. Anziché avere controlli per l'intera pipeline, hai controlli per ogni passaggio della pipeline. Questi controlli della pipeline includono:
- Suddivisione dei dati
- Feature engineering
- Ricerca dell'architettura
- Addestramento del modello
- Combinazione di modelli
- Distillazione del modello
Vantaggi
- Supporta set di dati di grandi dimensioni di più TB e fino a 1000 colonne.
- Consente di migliorare la stabilità e ridurre i tempi di addestramento limitando lo spazio di ricerca dei tipi di architettura o saltando la ricerca dell'architettura.
- Consente di migliorare la velocità di addestramento selezionando manualmente l'hardware utilizzato per l'addestramento e la ricerca dell'architettura.
- Consente di ridurre le dimensioni del modello e migliorare la latenza con la distillazione o modificando le dimensioni dell'ensemble.
- Ogni componente AutoML può essere esaminato in una potente interfaccia grafica delle pipeline che consente di visualizzare le tabelle di dati trasformate, le architetture dei modelli valutate e molti altri dettagli.
- Ogni componente AutoML offre maggiore flessibilità e trasparenza, ad esempio la possibilità di personalizzare parametri, hardware, visualizzare lo stato del processo, i log e altro ancora.
Input-Output
- Prende come input una tabella BigQuery o un file CSV da Cloud Storage.
- Produce un modello Agent Platform come output.
- Gli output intermedi includono statistiche e suddivisioni del set di dati.
Per saperne di più, consulta Flusso di lavoro tabulare per AutoML end-to-end.
Workflow tabulari per la previsione
Flusso di lavoro tabulare per la previsione
Il flusso di lavoro tabulare per la previsione è la pipeline completa per le attività di previsione. È simile all'API AutoML, ma ti consente di scegliere cosa controllare e cosa automatizzare. Invece di avere controlli per l'intera pipeline, hai controlli per ogni passaggio della pipeline. Questi controlli della pipeline includono:
- Suddivisione dei dati
- Feature engineering
- Ricerca dell'architettura
- Addestramento del modello
- Combinazione di modelli
Vantaggi
- Supporta set di dati di grandi dimensioni fino a 1 TB e con un massimo di 200 colonne.
- Consente di migliorare la stabilità e ridurre i tempi di addestramento limitando lo spazio di ricerca dei tipi di architettura o saltando la ricerca dell'architettura.
- Consente di migliorare la velocità di addestramento selezionando manualmente l'hardware utilizzato per l'addestramento e la ricerca dell'architettura.
- Consente di ridurre le dimensioni del modello e migliorare la latenza modificando le dimensioni dell'ensemble.
- Ogni componente può essere esaminato in una potente interfaccia grafica delle pipeline che consente di visualizzare le tabelle di dati trasformate, le architetture dei modelli valutate e molti altri dettagli.
- Ogni componente offre maggiore flessibilità e trasparenza, ad esempio la possibilità di personalizzare parametri e hardware, visualizzare lo stato del processo, i log e altro ancora.
Input-Output
- Prende come input una tabella BigQuery o un file CSV da Cloud Storage.
- Produce un modello Agent Platform come output.
- Gli output intermedi includono statistiche e suddivisioni del set di dati.
Per ulteriori informazioni, consulta Workflow tabellare per la previsione.
Passaggi successivi
- Scopri di più sul flusso di lavoro tabulare per AutoML end-to-end.
- Scopri di più sul flusso di lavoro tabulare per la previsione.
- Scopri di più sui prezzi dei workflow tabulari.