

I cluster Ray su Gemini Enterprise Agent Platform offrono due opzioni di scalabilità: scalabilità automatica e scalabilità manuale. La scalabilità automatica consente al cluster di regolare automaticamente il numero di nodi worker in base alle risorse richieste dalle attività e dagli attori Ray. Se esegui un carico di lavoro elevato e non sei sicuro delle risorse necessarie, ti consigliamo di utilizzare la scalabilità automatica. La scalabilità manuale offre agli utenti un controllo più granulare dei nodi.
La scalabilità automatica può ridurre i costi dei carichi di lavoro, ma aggiunge l'overhead di avvio dei nodi e può essere difficile da configurare. Se non hai familiarità con Ray, inizia con i cluster non sottoposti a scalabilità automatica e utilizza la funzionalità di scalabilità manuale.
Scalabilità automatica
Abilita la funzionalità di scalabilità automatica di un cluster Ray specificando il conteggio minimo delle repliche (min_replica_count) e il conteggio massimo delle repliche (max_replica_count) di un pool di worker.
Tieni presente quanto segue:
- Configura la specifica di scalabilità automatica di tutti i pool di worker.
- La velocità di scalabilità orizzontale e verticale personalizzata non è supportata. Per i valori predefiniti, consulta Velocità di scalabilità orizzontale e verticale nella documentazione di Ray.
Imposta la specifica di scalabilità automatica del pool di worker
Utilizza la Google Cloud console o l'SDK Agent Platform per Python per abilitare la funzionalità di scalabilità automatica di un cluster Ray.
SDK Ray on Agent Platform
from google.cloud import aiplatform import vertex_ray from vertex_ray import AutoscalingSpec autoscaling_spec = AutoscalingSpec( min_replica_count=1, max_replica_count=3, ) head_node_type = Resources( machine_type="n1-standard-16", node_count=1, ) worker_node_types = [Resources( machine_type="n1-standard-16", accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, autoscaling_spec=autoscaling_spec, )] # Create the Ray cluster on Gemini Enterprise Agent Platform CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, worker_node_types=worker_node_types, ... )
Console
In conformità con la best practice di Ray OSS, l'impostazione del conteggio delle CPU logiche su 0 sul nodo head di Ray viene applicata per evitare di eseguire qualsiasi carico di lavoro sul nodo head.
Nella Google Cloud console, vai alla pagina Ray on Agent Platform.
Fai clic su Crea cluster per aprire il riquadro Crea cluster.
Per ogni passaggio del riquadro Crea cluster, esamina o sostituisci le informazioni predefinite del cluster. Fai clic su Continua per completare ogni passaggio:
- In Nome e regione, specifica un Nome e scegli una località per il cluster.
In Impostazioni di calcolo, specifica la configurazione del cluster Ray sul nodo head, inclusi il tipo di macchina, il tipo e il conteggio degli acceleratori, il tipo e le dimensioni del disco e il conteggio delle repliche. Facoltativamente, aggiungi un URI immagine personalizzata per specificare un'immagine container personalizzata per aggiungere dipendenze Python non fornite dall'immagine container predefinita. Consulta Immagine personalizzata.
In Opzioni avanzate, puoi:
- Specifica la tua chiave di crittografia.
- Specifica un account di servizio personalizzato.
- Se non devi monitorare le statistiche delle risorse del carico di lavoro durante l'addestramento, disattiva la raccolta delle metriche.
Per creare un cluster con un pool di worker con scalabilità automatica, fornisci un valore per il conteggio massimo delle repliche del pool di worker.
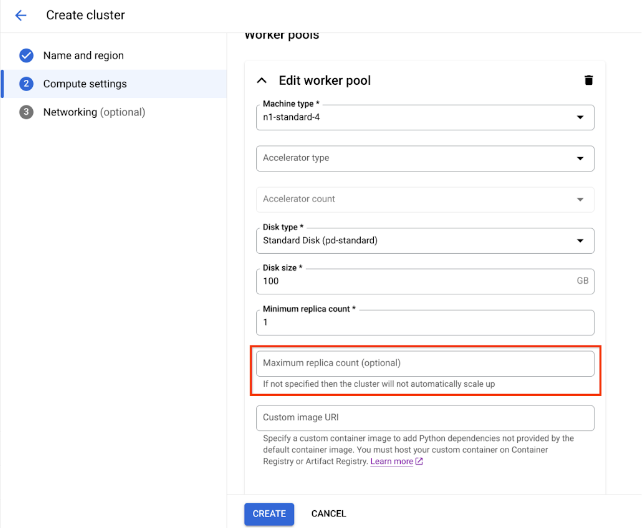
Fai clic su Crea.
Scalabilità manuale
Man mano che i carichi di lavoro aumentano o diminuiscono sui cluster Ray su Gemini Enterprise Agent Platform, ridimensiona manualmente il numero di repliche in base alla domanda. Ad esempio, se hai una capacità in eccesso, fare lo scale down dei pool di worker per risparmiare sui costi.
Limitazioni con il peering VPC
Quando ridimensioni i cluster, puoi modificare solo il numero di repliche nei pool di worker esistenti. Ad esempio, non puoi aggiungere o rimuovere pool di worker dal cluster o modificare il tipo di macchina dei pool di worker. Inoltre, il numero di repliche per i pool di worker non può essere inferiore a uno.
Se utilizzi una connessione di peering VPC per connetterti ai cluster, esiste una limitazione al numero massimo di nodi. Il numero massimo di nodi dipende dal numero di nodi del cluster al momento della creazione. Per ulteriori informazioni, consulta Calcolo del numero massimo di nodi. Questo numero massimo include non solo i pool di worker, ma anche il nodo head. Se utilizzi la configurazione di rete predefinita, il numero di nodi non può superare i limiti superiori descritti nella documentazionerelativa alla creazione dei cluster.
Best practice per l'allocazione delle subnet
Quando esegui il deployment di Ray su Gemini Enterprise Agent Platform utilizzando l'accesso privato ai servizi (PSA), è fondamentale assicurarsi che l'intervallo di indirizzi IP allocato sia sufficientemente grande e contiguo da ospitare il numero massimo di nodi a cui il cluster potrebbe essere scalato. L'esaurimento degli IP può verificarsi se l'intervallo IP riservato per la connessione PSA è troppo piccolo o frammentato, causando errori di deployment.
In alternativa, ti consigliamo di eseguire il deployment di Ray on Agent Platform con un' interfaccia Private Service Connect, che riduce il consumo di IP a una subnet /28.
Monitoraggio dell'accesso privato ai servizi
Come best practice, utilizza Network Analyzer uno strumento di diagnostica all'interno di Network Intelligence Center di Google Cloud che monitora automaticamente le configurazioni di rete Virtual Private Cloud (VPC) per rilevare configurazioni errate e impostazioni non ottimali. Network Analyzer funziona continuamente, eseguendo test in modo proattivo e generando insight per aiutarti a identificare, diagnosticare e risolvere i problemi di rete prima che influiscano sulla disponibilità del servizio.
Network Analyzer è in grado di monitorare le subnet utilizzate per l'accesso privato ai servizi (PSA) e fornisce insight specifici correlati. Questa è una funzione fondamentale per la gestione di servizi come Cloud SQL, Memorystore e Agent Platform, che utilizzano PSA.
Il modo principale in cui Network Analyzer monitora le subnet PSA è fornendo insight sull'utilizzo degli indirizzi IP per gli intervalli allocati.
Utilizzo dell'intervallo PSA: Network Analyzer monitora attivamente la percentuale di allocazione degli indirizzi IP all'interno dei blocchi CIDR dedicati che hai allocato per PSA. Questo è importante perché quando crei un servizio gestito (come Agent Platform), Google crea un VPC del producer di servizi e una subnet al suo interno, estraendo un intervallo IP dal blocco allocato.
Avvisi proattivi: se l'utilizzo degli indirizzi IP per un intervallo allocato PSA supera una determinata soglia (ad esempio, il 75%), Network Analyzer genera un insight di avviso. In questo modo, riceverai un avviso proattivo in caso di potenziali problemi di capacità, dandoti il tempo di espandere l'intervallo IP allocato prima di esaurire gli indirizzi disponibili per le nuove risorse di servizio.
Aggiornamenti delle subnet di accesso privato ai servizi
Per i deployment di Ray on Agent Platform, Google consiglia di allocare un blocco CIDR /16 o /17 per la connessione PSA. In questo modo, viene fornito un blocco contiguo di indirizzi IP sufficientemente grande da supportare una scalabilità significativa, ospitando rispettivamente fino a 65.536 o 32.768 indirizzi IP univoci. In questo modo, si evita l'esaurimento degli IP anche con cluster Ray di grandi dimensioni.
Se esaurisci lo spazio di indirizzi IP allocato, Google Cloud viene restituito questo errore:
Impossibile creare la subnet. Impossibile trovare blocchi liberi negli intervalli IP allocati.
Ti consigliamo di espandere l'intervallo di subnet corrente o di allocare un intervallo che possa ospitare la crescita futura.
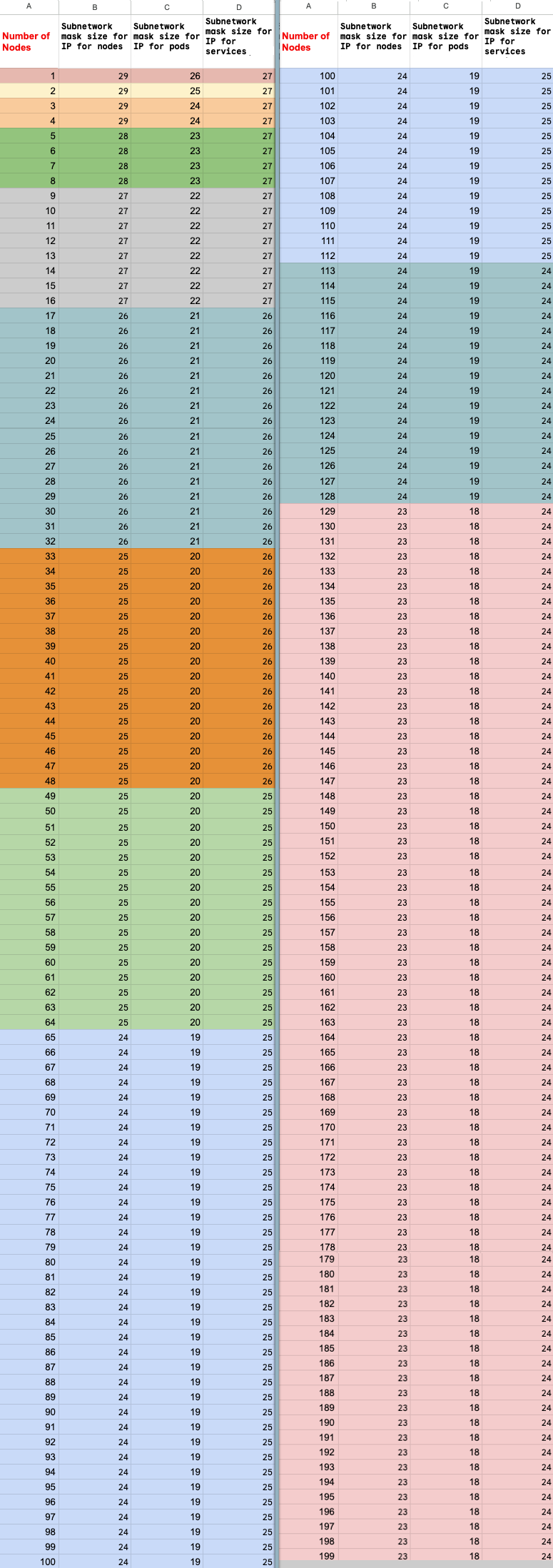
Calcolo del numero massimo di nodi
Se utilizzi l'accesso privato ai servizi (peering VPC) per connetterti ai
tuoi nodi, utilizza le seguenti formule per verificare di non superare il
numero massimo di nodi (M), presupponendo che f(x) = min(29, (32 -
ceiling(log2(x))):
f(2 * M) = f(2 * N)f(64 * M) = f(64 * N)f(max(32, 16 + M)) = f(max(32, 16 + N))
Il numero totale massimo di nodi nel cluster Ray on Agent Platform a cui puoi eseguire lo scale up (M) dipende dal numero totale iniziale di nodi che hai configurato (N). Dopo aver creato il cluster Ray on Agent Platform, puoi scalare il numero totale di nodi a qualsiasi valore compreso tra P e M, inclusi, dove P è il numero di pool nel cluster.
Il numero totale iniziale di nodi nel cluster e il numero target di scale up devono trovarsi nello stesso blocco di colore.
Aggiorna il conteggio delle repliche
Utilizza la Google Cloud consoleo l'SDK Agent Platform per Python per aggiornare il conteggio delle repliche del pool di worker. Se il cluster include più pool di worker, puoi modificare singolarmente il conteggio delle repliche di ciascuno in un'unica richiesta.
SDK Ray on Agent Platform
import vertexai import vertex_ray vertexai.init() cluster = vertex_ray.get_ray_cluster("CLUSTER_NAME") # Get the resource name. cluster_resource_name = cluster.cluster_resource_name # Create the new worker pools new_worker_node_types = [] for worker_node_type in cluster.worker_node_types: worker_node_type.node_count = REPLICA_COUNT # new worker pool size new_worker_node_types.append(worker_node_type) # Make update call updated_cluster_resource_name = vertex_ray.update_ray_cluster( cluster_resource_name=cluster_resource_name, worker_node_types=new_worker_node_types, )
Console
Nella Google Cloud console, vai alla pagina Ray on Agent Platform.
Nell'elenco dei cluster, fai clic sul cluster da modificare.
Nella pagina Dettagli cluster, fai clic su Modifica cluster.
Nel riquadro Modifica cluster, seleziona il pool di worker da aggiornare e poi modifica il conteggio delle repliche.
Fai clic su Aggiorna.
Attendi alcuni minuti che il cluster venga aggiornato. Al termine dell'aggiornamento, puoi visualizzare il conteggio delle repliche aggiornato nella pagina Dettagli cluster.
Fai clic su Crea.