

Gemini 정제 서비스 (정제)를 사용하면 사용자가 더 크고 성능이 우수한 '티처' 모델의 출력 및 추론 패턴을 사용하는 더 작고 효율적인 '스튜던트' 모델을 학습시킬 수 있습니다. 프런티어 모델은 AI의 최첨단을 정의하지만 특정 엔터프라이즈 사용 사례에 과도하게 프로비저닝될 수 있습니다. 정제는 이러한 격차를 해소하여 프로덕션 등급 효율성 (지연 시간 및 비용 절감)을 지원하는 동시에 더 작은 모델이 더 심층적인 수준의 추론을 달성할 수 있도록 합니다.
최종 텍스트 출력만 사용하는 표준 감독 기반 미세 조정 (SFT)과 달리 정제는 다음을 활용합니다.
- 티처 응답: 최종 텍스트 출력입니다.
- 원시 생각: 티처 모델에서 생성된 내부 추론 경로입니다.
지원되는 모델
사전 체험판 기간 동안 정제에 지원되는 모델은 다음과 같습니다.
- 티처 모델:
gemini-3.1-pro - 스튜던트 모델:
gemini-2.5-flash
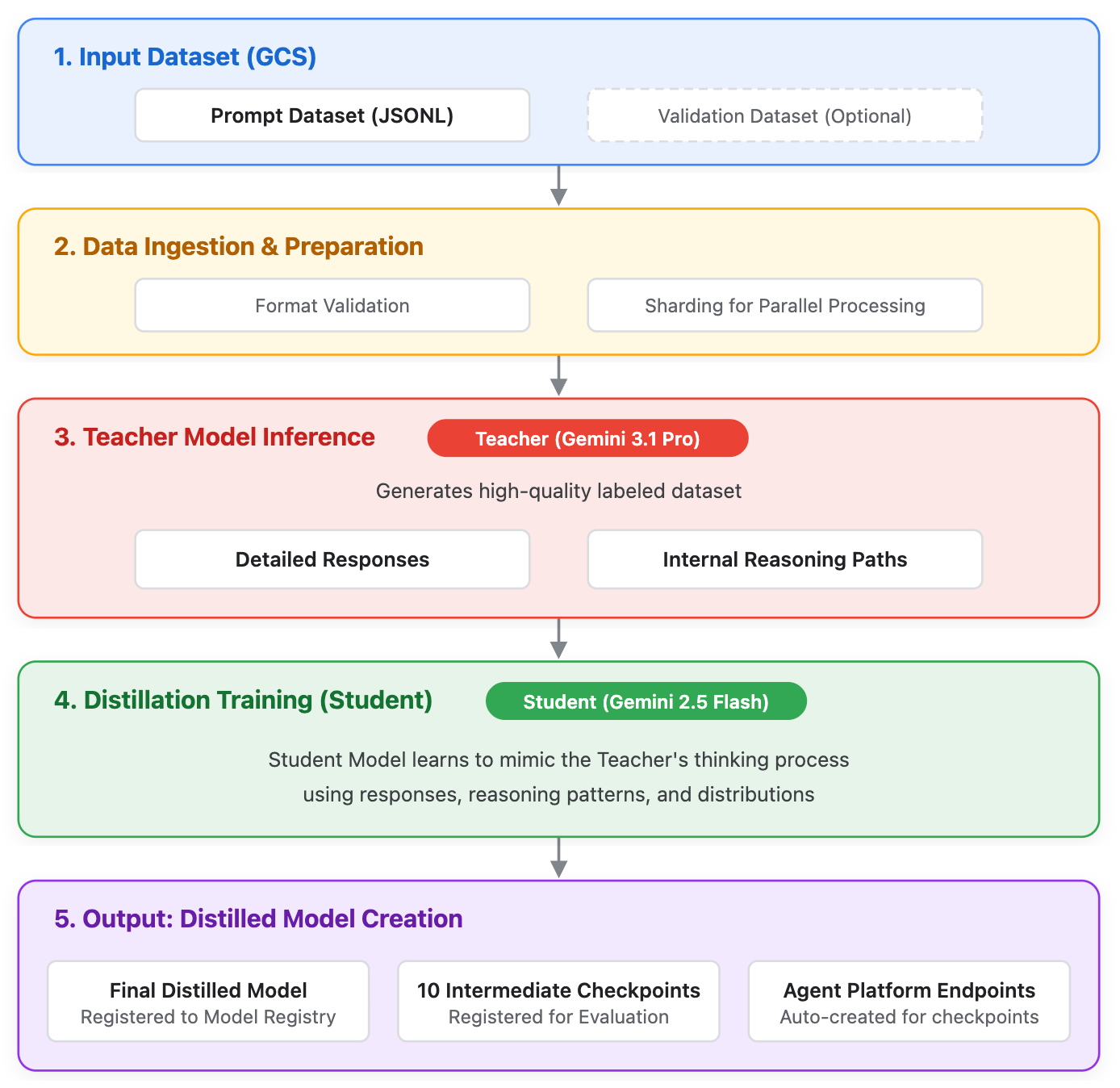
그림 1. Gemini 정제 서비스의 작동 방식을 보여주는 시스템 그림입니다.
적합한 사용 사례
다음 시나리오에서는 표준 프롬프트 또는 감독 기반 미세 조정 (SFT)보다 정제를 사용하는 것이 좋습니다.
- 대용량, 지연 시간에 민감한 애플리케이션: 애플리케이션에 Pro 등급 모델의 추론 기능이 필요하지만 엄격한 지연 시간 SLA 또는 Flash 등급 모델이 필요한 예산 제약조건을 충족해야 하는 경우.
- 그라운드 트루스 데이터 부족 (SFT가 불가능함): 사용자 프롬프트 또는 쿼리의 대규모 데이터 세트가 있지만 표준 SFT에 필요한 고품질 그라운드 트루스 답변을 수동으로 라벨링 하거나 생성할 리소스가 없는 경우.
- 복잡한 추론 작업: 기본 Flash 모델은 어려워하지만 Pro 모델은 성공하는 다단계 로직, 고도로 기술적인 문서 요약 또는 복잡한 코딩 작업과 관련된 작업.
- 성능 격차: 티처 모델이 특정 작업에서 기본 스튜던트 모델보다 훨씬 우수하여 정제 중에 전이할 수 있는 명확한 지식 마진을 제공하는 경우.
기본 요건 및 프로젝트 설정
정제 작업을 시작하기 전에 환경이 올바르게 구성되어 있는지 확인하세요. Google Cloud
- 허용 목록에 대한 액세스 요청: Gemini 정제 서비스 사전 체험판의 허용 목록에 프로젝트 ID가 추가되었는지 확인합니다. Google Cloud Google 영업 담당자에게 문의하여 프로젝트를 허용 목록에 추가하세요.
- API 사용 설정: 프로젝트에서 Agent Platform API를 사용 설정합니다. Google Cloud
- IAM 역할 권한 설정: Agent Platform 관리자 (
roles/aiplatform.admin) IAM 역할이 있어야 합니다. - 리전 설정: 정제 작업은
us-central1리전에서 실행해야 합니다.
데이터 세트 준비
이 서비스의 주요 기능은 프롬프트 전용 데이터 세트 를 사용하는 것입니다. 티처 모델은 정제 프로세스 중에 타겟 출력을 생성하므로 예상 답변을 제공할 필요가 없습니다.
데이터 세트 요구사항
데이터 세트는 JSON Lines (JSONL) 형식이어야 하며 Cloud Storage 버킷에 저장되어야 합니다. 각 항목은 다음 외에도 Gemini 조정 데이터 세트 형식을 준수해야 합니다.
- 시스템 요청 사항: 선택적
systemInstruction필드('system' 역할 포함)를 포함하여 시스템 프롬프트를 정의할 수 있습니다. - 입력: 콘텐츠 필드('user' 역할 포함)는 기본 입력에 필요합니다.
멀티턴 프롬프트: 시퀀스의 최종 항목이 'user'인 경우 'user' 역할과 'model' 역할을 번갈아 사용할 수 있습니다.
다음은 두 가지 dataset.jsonl 파일 예시입니다.
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
}
]
},
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Choose several strands of embroidery thread in a variety of colors."
}
]
},
{
"role": "user",
"parts": [
{
"text": "You will need one egg (raw or hard boiled but hard boiled is best) and one spoon for each person participating in the race. You might even like to use dyed Easter eggs as something special for Easter. It's best to have this race on grass or some other soft surface, to give dropped eggs a chance!"
}
]
}
]
}
권장사항
데이터 세트를 만들 때 다음 가이드라인을 따르세요.
- 크기: 눈에 띄는 품질 개선을 위해서는 최소 1,000개의 예시를 사용하는 것이 좋습니다.
- 다양성: 프롬프트가 프로덕션 트래픽에서 예상되는 엣지 케이스와 다양한 길이를 포함하는지 확인합니다.
정제 요청 구성
정제 작업을 수행하려면 티처의 생성 동작과 스튜던트의 학습 초매개변수를 모두 구성해야 합니다.
티처 모델의 생성 동작 구성
티처 모델이 데이터 세트에 응답하는 방식을 정의해야 합니다. 스튜던트 모델의 품질은 티처의 출력 품질에 직접적으로 영향을 받습니다. 티처 모델의 생성 동작을 구성하려면 candidateCount를 설정합니다.
candidateCount: 생성할 응답 변형의 수입니다. (예:4. 범위[1, 5]). 요청에 지정되지 않은 경우 기본값인4가 사용됩니다.
정제 초매개변수 설정
정제 초매개변수는 스튜던트 모델의 학습 프로세스를 제어합니다. Gemini Enterprise Agent Platform의 하이퍼파라미터에 대한 자세한 내용은 지도 미세 조정 가이드의 "튜닝 작업 만들기" 섹션을 참고하세요.
정제 작업을 만들 때 다음 초매개변수를 설정해야 합니다.
epochCount: 스튜던트 모델이 데이터 세트를 반복하는 횟수입니다. (예:20. 범위[1, 100]). 지정하지 않으면 기본값인4가 사용됩니다.learningRateMultiplier: 스튜던트 모델의 기본 학습률을 수정합니다. (예:2.0. 범위[0.25, 4]). 지정하지 않으면 기본값인1이 사용됩니다.
정제 작업 시작
사전 체험판 기간 동안 Agent Platform API의 REST 버전을 사용하여 정제 작업을 제출하고 모니터링할 수 있습니다. 새 정제 작업을 시작하거나 이미 정제된 모델 체크포인트에서 지속적 조정을 실행할 수 있습니다.
새 정제 작업 만들기
작업 구성이 포함된 request.json이라는 JSON 파일을 만듭니다. 다음 예시에서 티처의 생성 구성은 hyperParameters 필드 내에 중첩되어 있습니다.
{
"description": "Distillation testing job.",
"baseModel": "gemini-2.5-flash",
"tunedModelDisplayName": "flash-distillation-run-1",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5
}
}
}
}
curl을 사용하여 작업을 제출합니다.
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
지속적 조정 실행
이전에 정제된 모델 체크포인트에서 조정을 재개하려면 request.json 파일에 preTunedModel 블록을 포함하세요. 지속적 조정은 이전에 정제된 모델 체크포인트에만 지원되며 기본 스튜던트 모델은 동일합니다. 이전에 감독 기반으로 미세 조정된 모델 체크포인트는 기본 스튜던트 모델이 동일하더라도 지원되지 않습니다.
다음은 이전에 정제된 모델 체크포인트에 대한 지속적 조정을 설정하는 예시입니다.
{
"description": "Continuous distillation testing job.",
"preTunedModel": {
"tunedModelName": "projects/YOUR_PROJECT_ID/locations/us-central1/models/PRETUNED_MODEL_ID@1",
"checkpointId": "1",
"baseModel": "gemini-2.5-flash"
},
"tunedModelDisplayName": "flash-distillation-continuous",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5,
}
}
}
}
curl을 사용하여 페이로드를 제출합니다.
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
정제 작업 모니터링
제출 응답은 JOB_ID가 포함된 작업 이름을 반환합니다
JOB_ID. GET 요청을 전송하여 작업 상태(state, 오류, 최종 초매개변수)를 확인할 수 있습니다.
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs/JOB_ID
**Agent Platform> 조정** 으로 이동하고 리전을 선택하여 콘솔에서 진행 상황을 시각적으로 모니터링할 수도 있습니다. Google Cloud us-central1
이 사전 체험판 출시 버전의 경우 Agent Platform 콘솔 UI에는 다음과 같은 알려진 제한사항이 있습니다.
- 티처 샘플링 진행 상황: 티처 모델 샘플링 프로세스를 위한 진행 상황 위젯이 없습니다. 상태가 '조정을 위한 준비 실행 중'으로 표시되더라도 작업은 백그라운드에서 정상적으로 진행됩니다.
- 스튜던트 조정 차트: 스튜던트 모델 조정 단계에서 UI 는 손실 곡선 및 총 학습 텍스트 토큰에 대한 차트를 제공합니다.
- 체크포인트 표: UI는 중간 체크포인트 표와 평가를 위해 생성된 Agent Platform 예측 엔드포인트 링크를 표시합니다. 알려진 문제로 인해 이 표의 '에포크' 열에 '0'이 표시됩니다.
정제 작업 취소
진행 중인 정제 작업을 취소하려면 다음 중 하나를 수행합니다.
콘솔을 사용하여 다음 URL을 변경합니다. Google Cloud
https://console.cloud.google.com/agent-platform/tuning/managed?project=YOUR_PROJECT_ID&vertex_ai_region=us-central1YOUR_PROJECT_ID를 프로젝트 ID로 바꿉니다.
curl을 사용하여 작업을 취소하는 POST 요청을 전송합니다.curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID:cancel다음을 바꿉니다.
YOUR_PROJECT_ID를 프로젝트 ID로 바꿉니다.YOUR_JOB_ID를 작업 ID로 바꿉니다.
결과 평가
정제 작업이 완료되면 새 스튜던트 모델이 Gemini Enterprise Agent Platform Model Registry에 자동으로 등록되고 예측을 제공하기 위해 하나 이상의 전용 엔드포인트가 생성됩니다. 결과를 평가하려면 엔드포인트를 찾고 예측 요청을 전송한 후 평가합니다.
결과를 평가하려면 다음을 수행합니다.
다음 GET 요청을 전송하여 조정 작업의 상태를 확인합니다.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID다음을 바꿉니다.
YOUR_PROJECT_ID를 프로젝트 ID로 바꿉니다.YOUR_JOB_ID를 작업 ID로 바꿉니다.
완료된 작업은
tunedModel객체 내에 중첩된endpoint필드를 표시합니다. 반환된 경로 문자열의 끝에서ENDPOINT_ID를 추출합니다 (예:projects/.../endpoints/YOUR_ENDPOINT_ID). 엔드포인트 ID를 기록해 둡니다.조정 작업이 아직 실행 중이거나 실패한 동안에는 엔드포인트를 사용할 수 없으므로 조정 작업이 완료되었는지 확인합니다.
endpoint필드가 누락된 경우 작업의state또는error키를 확인하여 조정 작업을 디버그합니다.프롬프트가 포함된
generate_content_request.json이라는 JSON 페이로드 요청을 만듭니다.{ "contents": { "role": "user", "parts": [ { "text": "hi, say something" } ] } }다음 POST 예시를 사용하여 예측 요청을 전송합니다.
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/endpoints/YOUR_ENDPOINT_ID:generateContent \ -d @generate_content_request.json다음을 바꿉니다.
YOUR_PROJECT_ID: 프로젝트 ID입니다.YOUR_JOB_ID: 작업 ID입니다.ENDPOINT_ID: 엔드포인트 ID입니다.
결과를 평가하려면 다음을 수행합니다.
학습 데이터에 포함되지 않은 프롬프트를 사용하여 새로 정제된 모델에 대해 홀드아웃 테스트 세트를 실행합니다.
출력을 기본
gemini-2.5-flash모델과 비교하여 품질 개선을 측정합니다.출력을
gemini-3.1-pro모델과 비교하여 스튜던트가 티처의 추론에 얼마나 근접하는지 확인합니다.
제한사항
다음 표에서는 정제의 제한사항을 설명합니다.
정제에는 다음과 같은 제한사항이 적용됩니다.
- 모델 제한사항:
- 지원되는 모델을 참고하세요.
- 데이터 세트 제한사항:
- 볼륨 제한:
- 최대 학습 세트 용량은 50,000개의 예시입니다.
- 소스 JSONL 파일 크기는 1GB를 초과할 수 없습니다.
- 컨텍스트 윈도우 사양:
- 이 서비스는 항목당 최대 8,000개의 입력 토큰을 수용합니다. 제공된 항목의 10% 를 초과하는 경우 정제 작업이 종료됩니다.
- 티처 모델 샘플링은 최대 24,000 개의 토큰 출력으로 제한됩니다. 티처 모델이 24,000개 이상의 토큰을 생성하는 경우 콘텐츠는 이 한도에서 잘리므로 스튜던트 모델의 성능에 영향을 미칠 수 있습니다.
- 모달리티: 텍스트 기반 데이터로 제한됩니다. 동영상, 이미지 또는 함수 호출을 비롯한 멀티모달 입력은 지원되지 않습니다.
- 볼륨 제한:
- 구성 및 하이퍼파라미터 제한사항
- distillationSpec 및 관련 hyperParameters를 정의할 때는 다음 경계를 준수하세요.
- 암호화: Google의 퍼스트 파티 모델과 관련된 정제 작업에는 CMEK를 사용할 수 없습니다.
epochCount: 1~100 사이의 정수 값으로 제한됩니다.learningRateMultiplier: 값은 부동 소수점 범위0.25-4.0내에 있어야 합니다.
- distillationSpec 및 관련 hyperParameters를 정의할 때는 다음 경계를 준수하세요.
- 원스텝 정제: 티처 모델 샘플링 및 스튜던트 모델 조정이 단일 API 호출로 실행됩니다. 샘플링할 데이터가 많은 경우 다음 조정에서 동일한 데이터를 다시 샘플링해야 합니다.
액세스 권한 받기
Gemini 정제 서비스를 실험해 보려면 cloud-ai-tuning-service-support@google.com 으로 조정 서비스팀에 문의하여 액세스 및 프로젝트 허용 목록 추가를 요청하세요.
최적의 성능과 리소스 관리를 위해서는 정제 작업을 위한 전용 프로젝트 Google Cloud 를 만드는 것이 좋습니다. Google팀에 문의할 때는 허용 목록 추가 프로세스를 신속하게 처리할 수 있도록 프로젝트 ID 또는 프로젝트 번호를 제공하세요.
할당량 및 액세스 정책
다음 할당량 및 액세스 정책이 적용됩니다.
용량: 최근에 허용 목록에 추가된 프로젝트에는 기본 동시 할당량 4가 프로비저닝됩니다. 리소스 경합을 방지하려면 다른 Gemini 조정 작업이 이미 실행 중인 프로젝트가 아닌 별도의 프로젝트를 사용하는 것이 좋습니다.
액세스 기간: 액세스 권한은 최초 30일 동안 부여됩니다.