

Gemini Distillation Service(蒸留)を使用すると、より大規模で高性能な「教師」モデルの出力と推論パターンを使用する、より小規模で効率的な「生徒」モデルをトレーニングできます。フロンティア モデルは AI の最先端を定義しますが、特定のエンタープライズ ユースケースでは過剰にプロビジョニングされる可能性があります。蒸留はこのギャップを埋め、より小規模なモデルがより深いレベルの推論を実現できるようにしながら、本番環境レベルの効率(レイテンシとコストの削減)を実現します。
最終的なテキスト出力のみを使用する標準の教師ありファインチューニング(SFT)とは異なり、蒸留では次のものが活用されます。
- 教師の回答: 最終的なテキスト出力。
- 未加工の思考: 教師モデルによって生成された内部推論パス。
サポートされているモデル
早期アクセス期間中の抽出では、次のモデルがサポートされています。
- 教師モデル:
gemini-3.1-pro - 生徒モデル:
gemini-2.5-flash
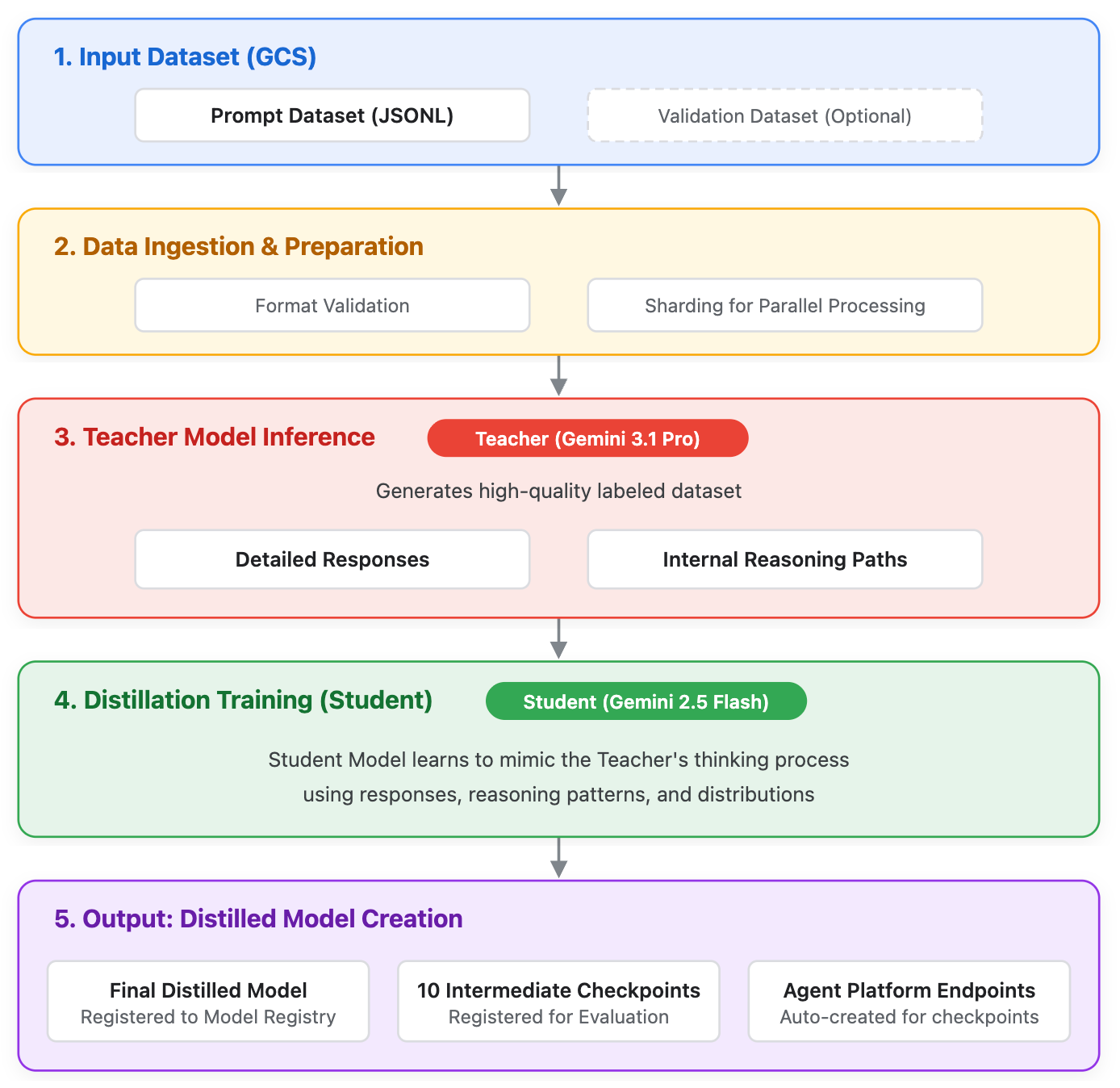
図 1. Gemini Distillation Service の仕組みを示すシステム図。
適切なユースケース
次のシナリオでは、標準のプロンプトや教師ありファインチューニング(SFT)よりも蒸留が推奨されます。
- 大容量でレイテンシの影響を受けやすいアプリケーション: アプリケーションに Pro ティアモデルの推論機能が必要だが、Flash ティアモデルが必要となる厳格なレイテンシ SLA または予算の制約を満たす必要がある場合。
- グラウンド トゥルース データがない(SFT が実行不可能): ユーザー プロンプトまたはクエリの大きなデータセットがあるが、標準の SFT に必要な高品質のグラウンド トゥルース回答を手動でラベル付けまたは生成するためのリソースがない場合。
- 複雑な推論タスク: ベースの Flash モデルでは苦戦するが、Pro モデルでは成功する、マルチステップ ロジック、高度な技術文書の要約、複雑なコーディング タスクを伴うタスク。
- パフォーマンスの大きな差: 特定のタスクで教師モデルがベースの生徒モデルを大幅に上回る場合、蒸留中に転送する知識の明確なマージンが提供されます。
前提条件とプロジェクトの設定
蒸留ジョブを開始する前に、 Google Cloud 環境が正しく構成されていることを確認してください。
- 許可リストへのアクセスをリクエストする: Gemini Distillation Service の早期アクセス用の許可リストに Google Cloud プロジェクト ID が追加されていることを確認します。プロジェクトを許可リストに追加するには、Google の営業担当者にお問い合わせください。
- API を有効にする: Google Cloud プロジェクトで Agent Platform API を有効にします。
- IAM ロールの権限を設定する: Agent Platform 管理者(
roles/aiplatform.admin)IAM ロールが必要です。 - リージョンを設定する: 蒸留ジョブは
us-central1リージョンで実行する必要があります。
データセットの準備
このサービスの重要な機能は、プロンプトのみのデータセットを使用することです。教師モデルは蒸留プロセスでターゲット出力を生成するため、期待される回答を提供する必要はありません。
データセットの要件
データセットは JSON Lines(JSONL)形式で、Cloud Storage バケットに保存する必要があります。各エントリは、次の条件に加えて、Gemini チューニング データセット形式に準拠する必要があります。
- システム指示: オプションの
systemInstructionフィールド(「system」ロール)を含めて、システム プロンプトを定義できます。 - 入力: メインの入力には、コンテンツ フィールド(「user」ロール)が必要です。
マルチターンのプロンプト: シーケンスの最後のエントリが「user」であれば、「user」ロールと「model」ロールを交互に使用できます。
次に、2 つの dataset.jsonl ファイルの例を示します。
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
}
]
},
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Choose several strands of embroidery thread in a variety of colors."
}
]
},
{
"role": "user",
"parts": [
{
"text": "You will need one egg (raw or hard boiled but hard boiled is best) and one spoon for each person participating in the race. You might even like to use dyed Easter eggs as something special for Easter. It's best to have this race on grass or some other soft surface, to give dropped eggs a chance!"
}
]
}
]
}
ベスト プラクティス
データセットを作成する際は、次のガイドラインを使用してください。
- サイズ: 品質を大幅に改善するには、少なくとも 1,000 個の例を用意することをおすすめします。
- 多様性: プロンプトが、本番環境のトラフィックで想定されるエッジケースとさまざまな長さを網羅していることを確認します。
蒸留リクエストを構成する
蒸留ジョブでは、教師の生成動作と生徒のトレーニング ハイパーパラメータの両方を構成する必要があります。
教師モデルの生成動作を構成する
教師モデルがデータセットにどのように応答するかを定義する必要があります。生徒モデルの品質は、教師の出力の品質に直接依存します。教師モデルの生成動作を構成するには、candidateCount を設定します。
candidateCount: 生成するレスポンスのバリエーションの数(例:4。範囲[1, 5])。リクエストで指定されていない場合は、デフォルト値の4が使用されます。
蒸留ハイパーパラメータを設定する
蒸留ハイパーパラメータは、生徒モデルのトレーニング プロセスを制御します。Gemini Enterprise Agent Platform のハイパーパラメータの詳細については、教師ありファインチューニング ガイドの「チューニング ジョブを作成する」セクションをご覧ください。
蒸留ジョブを作成するときは、次のハイパーパラメータを設定する必要があります。
epochCount: 生徒モデルがデータセットを反復処理する回数(例:20。範囲[1, 100])。指定しない場合は、デフォルト値の4が使用されます。learningRateMultiplier: 生徒モデルの基本学習率を変更します。(例:2.0。範囲[0.25, 4])。指定しない場合は、デフォルト値の1が使用されます。
抽出ジョブを開始する
早期アクセス期間中は、Agent Platform API の REST バージョンを使用して、蒸留ジョブを送信してモニタリングできます。新しい蒸留ジョブを開始するか、すでに蒸留されたモデルのチェックポイントで継続的チューニングを実行できます。
新しい蒸留ジョブを作成する
ジョブ構成を含む request.json という名前の JSON ファイルを作成します。次の例では、教師の生成構成が hyperParameters フィールド内にネストされています。
{
"description": "Distillation testing job.",
"baseModel": "gemini-2.5-flash",
"tunedModelDisplayName": "flash-distillation-run-1",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5
}
}
}
}
curl を使用してジョブを送信します。
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
継続的チューニングを実施する
以前に抽出したモデルのチェックポイントからチューニングを再開する場合は、request.json ファイルに preTunedModel ブロックを含めます。継続的チューニングは、以前に抽出したモデルのチェックポイントでのみサポートされており、ベースの生徒モデルは同じです。以前に教師ありファインチューニングされたモデルのチェックポイント(ベースの生徒モデルが同じ場合でも)はサポートされていません。
以前に抽出したモデル チェックポイントの継続的チューニングを設定する例を次に示します。
{
"description": "Continuous distillation testing job.",
"preTunedModel": {
"tunedModelName": "projects/YOUR_PROJECT_ID/locations/us-central1/models/PRETUNED_MODEL_ID@1",
"checkpointId": "1",
"baseModel": "gemini-2.5-flash"
},
"tunedModelDisplayName": "flash-distillation-continuous",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5,
}
}
}
}
curl を使用してペイロードを送信します。
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
蒸留ジョブをモニタリングする
送信レスポンスは、JOB_ID を含むジョブ名を返します。GET リクエストを送信して、ジョブのステータス(state、エラー、最終的なハイパーパラメータ)を確認できます。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs/JOB_ID
Google Cloud コンソールで、[Agent Platform> チューニング] に移動して us-central1 リージョンを選択すると、進行状況を視覚的にモニタリングすることもできます。
この早期アクセス リリースでは、Agent Platform コンソール UI に次の既知の制限事項があります。
- 教師サンプリングの進行状況: 教師モデルのサンプリング プロセスには進行状況ウィジェットはありません。ステータスに「チューニングの準備を実行中」と表示されることがありますが、ジョブはバックグラウンドで正常に進行しています。
- 生徒モデルのチューニング チャート: 生徒モデルのチューニング段階で、UI に損失曲線とトレーニング テキスト トークンの合計のグラフが表示されます。
- チェックポイント テーブル: UI には、中間チェックポイントの表と、評価用に生成された Agent Platform 予測エンドポイントへのリンクが表示されます。この表の [Epoch] 列には、既知の問題により「0」が表示されます。
蒸留ジョブをキャンセルする
進行中の蒸留ジョブをキャンセルするには、次のいずれかを行います。
Google Cloud コンソールを使用して、次の URL を変更します。
https://console.cloud.google.com/agent-platform/tuning/managed?project=YOUR_PROJECT_ID&vertex_ai_region=us-central1YOUR_PROJECT_ID は、実際のプロジェクト ID に置き換えます。
curlを使用して POST リクエストを送信し、ジョブをキャンセルします。curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID:cancel次のように置き換えます。
YOUR_PROJECT_ID: プロジェクト ID。YOUR_JOB_ID: ジョブ ID。
結果の評価
抽出ジョブが正常に完了すると、新しい生徒モデルが Gemini Enterprise Agent Platform Model Registry に自動的に登録され、予測を処理する 1 つ以上の専用エンドポイントが作成されます。結果を評価するには、エンドポイントを見つけて予測リクエストを送信し、最後に評価します。
結果を評価するには、次の操作を行います。
次の GET リクエストを送信して、チューニング ジョブのステータスを確認します。
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID次のように置き換えます。
YOUR_PROJECT_ID: プロジェクト ID。YOUR_JOB_ID: ジョブ ID。
完了したジョブには、
tunedModelオブジェクト内にネストされたendpointフィールドが表示されます。返されたパス文字列の末尾からENDPOINT_IDを抽出します(例:projects/.../endpoints/YOUR_ENDPOINT_ID)。エンドポイント ID をメモします。チューニング ジョブが正常に完了していることを確認します。チューニング ジョブが実行中または失敗している間は、エンドポイントを使用できません。
endpointフィールドがない場合は、ジョブのstateキーまたはerrorキーを表示して、チューニング ジョブをデバッグします。プロンプトを含む
generate_content_request.jsonという名前の JSON ペイロード リクエストを作成します。{ "contents": { "role": "user", "parts": [ { "text": "hi, say something" } ] } }次の POST の例を使用して、予測リクエストを送信します。
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/endpoints/YOUR_ENDPOINT_ID:generateContent \ -d @generate_content_request.json次のように置き換えます。
YOUR_PROJECT_ID: プロジェクト ID。YOUR_JOB_ID: ジョブ ID。ENDPOINT_ID: エンドポイント ID。
結果を評価するには、次の操作を行います。
トレーニング データに含まれていないプロンプトを使用して、新たに蒸留したモデルに対してホールドアウト テストセットを実行します。
出力をベースの
gemini-2.5-flashモデルと比較して、品質の改善を測定します。出力を
gemini-3.1-proモデルと比較して、生徒が教師の推論をどの程度近似しているかを判断します。
制限事項
次の表に、蒸留の制限事項を示します。
蒸留には次の制限があります。
- モデルの制限事項:
- サポートされているモデルをご覧ください。
- データセットの制限事項:
- ボリュームの上限:
- トレーニング セットの最大容量は 50,000 個のサンプルです。
- ソース JSONL ファイルのサイズは 1 GB を超えないようにしてください。
- コンテキスト ウィンドウの仕様:
- このサービスでは、エントリあたり最大 8,000 個の入力トークンを使用できます。指定されたエントリの 10% 以上がこのしきい値を超えると、蒸留ジョブは終了します。
- 教師モデルのサンプリングは、最大出力 24,000 トークンに制限されます。教師モデルが 24,000 トークンを超えるトークンを生成した場合、コンテンツはこの上限で切り捨てられます。これにより、生徒モデルのパフォーマンスに影響する可能性があります。
- モダリティ: テキストベースのデータに限定されます。動画、画像、関数呼び出しなどのマルチモーダル入力はサポートされていません。
- ボリュームの上限:
- 構成とハイパーパラメータの制限事項
- distillationSpec とそれに関連付けられた hyperParameters を定義するときは、次の境界を遵守してください。
- 暗号化: Google のファーストパーティ モデルを含む抽出タスクでは CMEK を使用できません。
epochCount: 1 ~ 100 の整数値に制限されます。learningRateMultiplier: 値は0.25~4.0の浮動小数点範囲内である必要があります。
- distillationSpec とそれに関連付けられた hyperParameters を定義するときは、次の境界を遵守してください。
- ワンステップ抽出: 教師モデルのサンプリングと生徒モデルのチューニングが 1 回の API 呼び出しで実行されます。サンプリングするデータ量が大きい場合は、次のチューニングで同じデータを再度サンプリングする必要があります。
利用方法
Gemini Distillation Service のテストに関心をお持ちの場合は、cloud-ai-tuning-service-support@google.com のチューニング サービス チームにお問い合わせいただき、アクセスとプロジェクトの許可リスト登録をリクエストしてください。
最適なパフォーマンスとリソース管理を確保するため、蒸留タスク専用の Google Cloud プロジェクトを作成することをおすすめします。チームにお問い合わせの際は、許可リスト登録プロセスを迅速に進めるため、プロジェクト ID またはプロジェクト番号をお知らせください。
割り当てとアクセス ポリシー
次の割り当てとアクセス ポリシーが有効になります。
容量: 最近許可リストに追加されたプロジェクトには、デフォルトの同時実行割り当てとして 4 がプロビジョニングされます。リソースの競合を回避するには、他の Gemini チューニング ジョブがすでに実行されているプロジェクトではなく、別のプロジェクトを使用することをおすすめします。
アクセス期間: 最初の 30 日間アクセス権が付与されます。