

Le service de distillation Gemini (distillation) permet aux utilisateurs d'entraîner un modèle "élève" plus petit et plus efficace qui utilise les sorties et les schémas de raisonnement d'un modèle "enseignant" plus grand et plus performant. Bien que les modèles de pointe définissent le summum de l'IA, ils peuvent être surdimensionnés pour des cas d'utilisation spécifiques aux entreprises. La distillation comble cette lacune, en permettant une efficacité de niveau production (latence et coût réduits) tout en permettant à des modèles plus petits d'atteindre un niveau de raisonnement plus profond.
Contrairement au réglage supervisé standard (SFT) qui n'utilise que le résultat textuel final, la distillation exploite :
- Réponses de l'enseignant : résultat textuel final.
- Pensées brutes : chemins de raisonnement internes générés par le modèle enseignant.
Modèles compatibles
Les modèles suivants sont compatibles avec la distillation pendant l'accès anticipé :
- Modèle enseignant :
gemini-3.1-pro - Modèle de l'élève :
gemini-2.5-flash
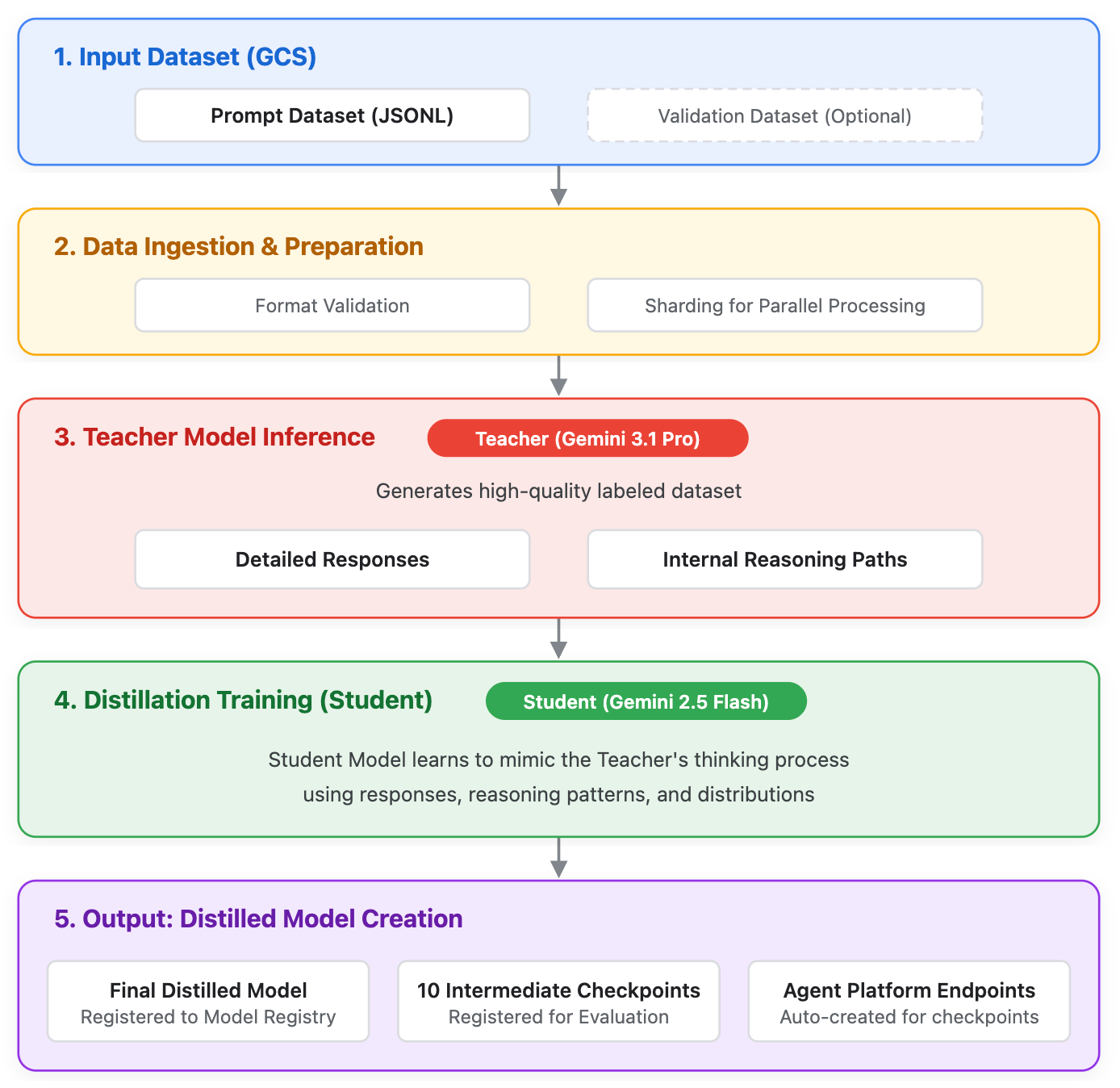
Fig. 1 Illustration du fonctionnement du service de distillation Gemini.
Cas d'utilisation adaptés
La distillation est recommandée plutôt que l'incitation standard ou le fine-tuning supervisé (SFT) dans les scénarios suivants :
- Applications à volume élevé et sensibles à la latence : lorsque votre application nécessite les capacités de raisonnement d'un modèle de niveau Pro, mais doit respecter des SLA de latence stricts ou des contraintes budgétaires qui nécessitent un modèle de niveau Flash.
- Manque de données de vérité terrain (SFT impossible) : lorsque vous disposez d'un grand ensemble de données de requêtes ou de questions utilisateur, mais que vous ne disposez pas des ressources nécessaires pour étiqueter ou générer manuellement des réponses de vérité terrain de haute qualité requises pour la SFT standard.
- Tâches de raisonnement complexes : tâches impliquant une logique en plusieurs étapes, la synthèse de documents très techniques ou des tâches de codage complexes pour lesquelles le modèle Flash de base a du mal, mais le modèle Pro réussit.
- Écarts de performances importants : lorsque le modèle enseignant surpasse considérablement le modèle élève de base pour votre tâche spécifique, ce qui fournit une marge de connaissances claire à transférer lors de la distillation.
Prérequis et configuration du projet
Avant de lancer un job de distillation, assurez-vous que votre environnement Google Cloud est correctement configuré :
- Demandez l'accès à la liste d'autorisation : assurez-vous que l'ID de votre projet Google Cloud a été ajouté à la liste d'autorisation pour l'accès anticipé au service de distillation Gemini. Contactez votre conseiller commercial Google pour ajouter votre projet à la liste d'autorisation.
- Activez l'API : activez l'API Agent Platform dans votre projet Google Cloud .
- Définir les autorisations de rôle IAM : vous devez disposer du rôle IAM Administrateur de la plate-forme d'agent (
roles/aiplatform.admin). - Définissez la région : les jobs de distillation doivent être exécutés dans la région
us-central1.
Préparation d'un ensemble de données
Une fonctionnalité clé de ce service est l'utilisation d'ensembles de données de requêtes uniquement. Étant donné que le modèle enseignant génère les sorties cibles pendant le processus de distillation, vous n'avez pas besoin de fournir les réponses attendues.
Exigences concernant les ensembles de données
Les ensembles de données doivent être au format JSON Lines (JSONL) et stockés dans un bucket Cloud Storage. Chaque entrée doit respecter le format de l'ensemble de données de réglage Gemini, en plus des éléments suivants :
- Instructions système : vous pouvez inclure un champ
systemInstructionfacultatif (avec un rôle "system") pour définir les invites système. - Entrée : le champ "Contenu" (avec le rôle "Utilisateur") est obligatoire pour l'entrée principale.
Requêtes multitours : vous pouvez alterner les rôles "user" et "model", à condition que la dernière entrée de la séquence soit "user".
Voici deux exemples de fichiers dataset.jsonl :
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
}
]
},
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "You're the artist here. Choose as many strands of thread as you like, as long as you're using three or more. Go for color combinations that you think would make a pretty pattern. Get creative! If you only use one color of thread, you won't be able to create a pattern.\n\nProvide a summary of the article in two or three sentences:\n\n"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Choose several strands of embroidery thread in a variety of colors."
}
]
},
{
"role": "user",
"parts": [
{
"text": "You will need one egg (raw or hard boiled but hard boiled is best) and one spoon for each person participating in the race. You might even like to use dyed Easter eggs as something special for Easter. It's best to have this race on grass or some other soft surface, to give dropped eggs a chance!"
}
]
}
]
}
Bonnes pratiques
Suivez les consignes ci-dessous lorsque vous créez votre ensemble de données :
- Taille : nous vous recommandons de fournir au moins 1 000 exemples pour obtenir une amélioration notable de la qualité.
- Diversité : assurez-vous que vos requêtes couvrent les cas extrêmes et les différentes longueurs attendues dans votre trafic de production.
Configurer la demande de distillation
Un job de distillation nécessite de configurer à la fois le comportement de génération du modèle enseignant et les hyperparamètres d'entraînement du modèle élève.
Configurer le comportement de génération du modèle enseignant
Vous devez définir la façon dont le modèle enseignant répond à votre ensemble de données. La qualité du modèle élève est directement liée à la qualité de la sortie du modèle enseignant. Pour configurer le comportement de génération du modèle enseignant, définissez candidateCount :
candidateCount: nombre de variantes de réponse à générer. (Exemple :4. Plage[1, 5]). Si elle n'est pas spécifiée dans la requête, la valeur par défaut4sera utilisée.
Définir les hyperparamètres de distillation
Les hyperparamètres de distillation contrôlent le processus d'entraînement du modèle étudiant. Pour en savoir plus sur les hyperparamètres dans Gemini Enterprise Agent Platform, consultez la section Créer un job de réglage du guide sur l'affinage supervisé.
Les hyperparamètres suivants doivent être définis lors de la création d'un job de distillation :
epochCount: nombre de fois où le modèle étudiant itérera sur l'ensemble de données. (Exemple :20. Plage[1, 100]). Si aucune valeur n'est spécifiée, la valeur par défaut4est utilisée.learningRateMultiplier: modifie le taux d'apprentissage de base du modèle étudiant. (Exemple :2.0. Plage :[0.25, 4]). Si aucune valeur n'est spécifiée, la valeur par défaut1est utilisée.
Démarrer le job de distillation
Pendant la période d'accès anticipé, vous pouvez envoyer et surveiller des tâches de distillation à l'aide de la version REST de l'API Agent Platform. Vous pouvez lancer un nouveau job de distillation ou effectuer un réglage continu sur un point de contrôle de modèle déjà distillé.
Créer un job de distillation
Créez un fichier JSON nommé request.json contenant la configuration de votre job. Dans l'exemple suivant, la configuration de la génération de l'enseignant est imbriquée dans le champ hyperParameters :
{
"description": "Distillation testing job.",
"baseModel": "gemini-2.5-flash",
"tunedModelDisplayName": "flash-distillation-run-1",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5
}
}
}
}
Envoyez le job à l'aide de curl :
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Effectuer un réglage continu
Si vous souhaitez reprendre le réglage à partir d'un point de contrôle de modèle distillé précédemment, incluez le bloc preTunedModel dans votre fichier request.json. Le réglage continu n'est compatible qu'avec les points de contrôle de modèle distillé précédemment, avec le même modèle élève de base. Les points de contrôle de modèle affiné supervisé précédemment (même avec le même modèle élève de base) ne sont pas compatibles.
Voici un exemple de configuration de l'ajustement continu pour un point de contrôle de modèle distillé précédemment :
{
"description": "Continuous distillation testing job.",
"preTunedModel": {
"tunedModelName": "projects/YOUR_PROJECT_ID/locations/us-central1/models/PRETUNED_MODEL_ID@1",
"checkpointId": "1",
"baseModel": "gemini-2.5-flash"
},
"tunedModelDisplayName": "flash-distillation-continuous",
"distillationSpec": {
"promptDatasetUri": "gs://your-bucket/path/to/prompt_dataset.jsonl",
"validationDatasetUri": "",
"base_teacher_model": "gemini-3.1-pro-preview",
"hyperParameters": {
"epochCount": "20",
"learningRateMultiplier": 2.0,
"generation_config": {
"candidateCount": 5,
}
}
}
}
Envoyez la charge utile à l'aide de curl :
curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs \
-d @request.json
Surveiller le job de distillation
La réponse à l'envoi renvoie un nom de tâche contenant votre JOB_ID. Vous pouvez vérifier l'état de votre tâche (state, erreurs et hyperparamètres finaux) en envoyant une requête GET :
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://us-central1-aiplatform.googleapis.com/v1beta1/projects/PROJECT_ID/locations/us-central1/tuningJobs/JOB_ID
Vous pouvez également surveiller visuellement la progression dans la console Google Cloud en accédant à Plate-forme d'agent > Optimisation et en choisissant la région us-central1.
Pour cette version en accès anticipé, l'UI de la console Agent Platform présente les limites connues suivantes :
- Progression de l'échantillonnage du modèle enseignant : il n'existe pas de widget de progression pour le processus d'échantillonnage du modèle enseignant. Même si l'état indique "Préparation de l'ajustement en cours", le job se déroule normalement en arrière-plan.
- Graphiques d'ajustement du modèle élève : pendant la phase d'ajustement du modèle élève, l'UI fournit des graphiques pour la courbe de fonction de perte et le nombre total de jetons de texte d'entraînement.
- Tableau des points de contrôle : l'UI affiche un tableau des points de contrôle intermédiaires et des liens vers le point de terminaison de prédiction de l'Agent Platform généré pour l'évaluation. En raison d'un problème connu, la colonne "Époque" de ce tableau affiche "0".
Annuler le job de distillation
Pour annuler une tâche de distillation en cours, procédez comme suit :
Utilisez la console Google Cloud en modifiant l'URL suivante :
https://console.cloud.google.com/agent-platform/tuning/managed?project=YOUR_PROJECT_ID&vertex_ai_region=us-central1Remplacez YOUR_PROJECT_ID par l'ID du projet.
Utilisez
curlpour envoyer une requête POST afin d'annuler le job :curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_ID:cancelRemplacez les éléments suivants :
YOUR_PROJECT_IDpar l'ID de votre projet.- Remplacez
YOUR_JOB_IDpar l'ID de votre job.
Évaluer le résultat
Une fois la tâche de distillation terminée, le nouveau modèle élève est automatiquement enregistré dans le registre de modèles de la plate-forme d'agents Gemini Enterprise. Un ou plusieurs points de terminaison dédiés sont créés pour diffuser les prédictions. Pour évaluer le résultat, vous devez localiser le point de terminaison, envoyer une demande de prédiction, puis évaluer le résultat.
Pour évaluer le résultat, procédez comme suit :
Envoyez la requête GET suivante pour afficher l'état du job de réglage.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/tuningJobs/YOUR_JOB_IDRemplacez les éléments suivants :
YOUR_PROJECT_IDpar l'ID de votre projet.- Remplacez
YOUR_JOB_IDpar l'ID de votre job.
Les tâches terminées affichent un champ
endpointimbriqué dans l'objettunedModel. ExtrayezENDPOINT_IDà la fin de la chaîne de chemin d'accès renvoyée (par exemple,projects/.../endpoints/YOUR_ENDPOINT_ID). Notez l'ID du point de terminaison.Assurez-vous que le job de réglage s'est terminé correctement, car le point de terminaison n'est pas disponible tant que le job de réglage est en cours d'exécution ou a échoué. Si le champ
endpointest manquant, déboguez le job de réglage en affichant les clésstateouerrordu job.Créez une requête de charge utile JSON nommée
generate_content_request.jsoncontenant votre requête :{ "contents": { "role": "user", "parts": [ { "text": "hi, say something" } ] } }Utilisez l'exemple POST suivant pour envoyer une requête de prédiction :
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ https://us-central1-aiplatform.googleapis.com/v1beta1/projects/YOUR_PROJECT_ID/locations/us-central1/endpoints/YOUR_ENDPOINT_ID:generateContent \ -d @generate_content_request.jsonRemplacez les éléments suivants :
YOUR_PROJECT_ID: ID de votre projet.YOUR_JOB_ID: ID de votre tâche.ENDPOINT_ID: ID de votre point de terminaison.
Pour évaluer les résultats, procédez comme suit :
Exécutez un ensemble de données de test de validation à l'aide de requêtes non incluses dans les données d'entraînement par rapport à votre nouveau modèle distillé.
Comparez les résultats avec ceux du modèle
gemini-2.5-flashde base pour mesurer les améliorations de la qualité.Comparez les sorties au modèle
gemini-3.1-propour déterminer dans quelle mesure l'élève se rapproche du raisonnement de l'enseignant.
Limites
Le tableau suivant décrit les limites de la distillation :
La distillation est soumise aux limites suivantes :
- Limites du modèle :
- Consultez les modèles compatibles.
- Restrictions concernant les ensembles de données :
- Limites de volume :
- La capacité maximale de l'ensemble d'entraînement est de 50 000 exemples.
- La taille du fichier JSONL source ne doit pas dépasser 1 Go.
- Spécifications de la fenêtre de contexte :
- Le service accepte un maximum de 8 000 jetons d'entrée par entrée. Les jobs de distillation sont arrêtés si plus de 10% des entrées fournies dépassent ce seuil établi.
- L'échantillonnage du modèle enseignant est limité à une sortie maximale de 24 000 jetons. Dans les cas où le modèle enseignant génère plus de 24 000 jetons, le contenu est tronqué à cette limite, ce qui peut affecter les performances du modèle élève.
- Modalité : limitée aux données textuelles. Les entrées multimodales, y compris les vidéos, les images ou les appels de fonction, ne sont pas prises en charge.
- Limites de volume :
- Limites de configuration et d'hyperparamètres
- Respectez les limites suivantes lorsque vous définissez distillationSpec et ses hyperparamètres associés :
- Chiffrement : CMEK n'est pas disponible pour les tâches de distillation impliquant des modèles propriétaires de Google.
epochCount: valeur entière comprise entre 1 et 100.learningRateMultiplier: les valeurs doivent être comprises dans la plage à virgule flottante0.25-4.0.
- Respectez les limites suivantes lorsque vous définissez distillationSpec et ses hyperparamètres associés :
- Distillation en une étape : l'échantillonnage du modèle enseignant et l'ajustement du modèle élève s'exécutent en un seul appel d'API. Si vous avez une grande quantité de données à échantillonner, les mêmes données doivent être échantillonnées à nouveau lors de l'ajustement suivant.
Obtenir l'accès
Si vous souhaitez tester le service de distillation Gemini, contactez notre équipe du service de réglage à l'adresse cloud-ai-tuning-service-support@google.com pour demander l'accès et l'ajout de votre projet à la liste d'autorisation.
Pour garantir des performances et une gestion des ressources optimales, nous vous recommandons de créer un projet Google Cloud dédié à vos tâches de distillation. Lorsque vous contactez notre équipe, indiquez l'ID du projet ou le numéro de projet pour accélérer le processus d'ajout à la liste d'autorisation.
Quotas et règles d'accès
Les quotas et règles d'accès suivants sont en vigueur :
Capacité : les projets récemment ajoutés à notre liste d'autorisation sont provisionnés avec un quota simultané par défaut de 4. Pour éviter toute contention des ressources, nous vous recommandons d'utiliser un projet distinct plutôt qu'un projet exécutant déjà d'autres jobs d'ajustement Gemini.
Période d'accès : l'accès est accordé pour une période initiale de 30 jours.