

La funzionalità di esecuzione del codice dell'API Gemini consente al modello di generare ed eseguire codice Python e di apprendere in modo iterativo dai risultati fino a ottenere un output finale. Puoi utilizzare questa funzionalità di esecuzione del codice per creare applicazioni che sfruttano il ragionamento basato sul codice e che producono output di testo. Ad esempio, potresti utilizzare l'esecuzione del codice in un'applicazione che risolve equazioni o elabora testo.
L'API Gemini fornisce l'esecuzione del codice come strumento, in modo simile alla chiamata di funzione. Dopo aver aggiunto l'esecuzione del codice come strumento, il modello decide quando utilizzarlo.
L'ambiente di esecuzione del codice include le seguenti librerie. Non puoi installare le tue librerie.
- Altair
- Chess
- Cv2
- Matplotlib
- Mpmath
- NumPy
- Panda
- Pdfminer
- Reportlab
- Seaborn
- Sklearn
- Statsmodels
- Striprtf
- SymPy
- Tabulate
Modelli supportati
I seguenti modelli supportano l'esecuzione del codice:
Fai clic per espandere i modelli supportati
Iniziare a utilizzare l'esecuzione del codice
Questa sezione presuppone che tu abbia completato i passaggi di configurazione mostrati in Inizia a utilizzare Gemini Enterprise Agent Platform.
Attiva l'esecuzione del codice
Puoi consentire al modello di utilizzare l'esecuzione di codice aggiungendolo all'elenco tools
durante la configurazione del modello:
Python
Installa
pip install --upgrade google-genai
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_ENTERPRISE=True
Go
Scopri come installare o aggiornare Go.
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_ENTERPRISE=True
Node.js
Installa
npm install @google/genai
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_ENTERPRISE=True
Java
Scopri come installare o aggiornare Java.
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_ENTERPRISE=True
REST
Prima di utilizzare i dati della richiesta, apporta le sostituzioni seguenti:
GENERATE_RESPONSE_METHOD: il tipo di risposta che vuoi che il modello generi. Scegli un metodo che generi la modalità di restituzione della risposta del modello:streamGenerateContent: la risposta viene trasmessa in streaming durante la generazione per ridurre la percezione della latenza per il pubblico umano.generateContent: la risposta viene restituita dopo essere stata generata completamente.
LOCATION: la regione in cui elaborare la richiesta. Le opzioni disponibili includono le seguenti:Fai clic per espandere un elenco parziale delle regioni disponibili
us-central1us-west4northamerica-northeast1us-east4us-west1asia-northeast3asia-southeast1asia-northeast1
PROJECT_ID: Il tuo [ID progetto](/resource-manager/docs/creating-managing-projects#identifiers). .MODEL_ID: l'ID modello del modello che vuoi utilizzare.ROLE: Il ruolo in una conversazione associata ai contenuti. La specifica di un ruolo è obbligatoria anche nei casi d'uso a singolo turno. I valori accettabili includono:USER: specifica i contenuti inviati da te.MODEL: specifica la risposta del modello.
TEXT
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json.
Esegui questo comando nel terminale per creare o sovrascrivere
questo file nella directory corrente:
cat > request.json << 'EOF'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
EOFQuindi esegui questo comando per inviare la richiesta REST:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD"
PowerShell
Salva il corpo della richiesta in un file denominato request.json.
Esegui questo comando nel terminale per creare o sovrascrivere
questo file nella directory corrente:
@'
{
"tools": [{'codeExecution': {}}],
"contents": {
"role": "ROLE",
"parts": { "text": "TEXT" }
},
}
'@ | Out-File -FilePath request.json -Encoding utf8Quindi esegui questo comando per inviare la richiesta REST:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:GENERATE_RESPONSE_METHOD" | Select-Object -Expand Content
Dovresti ricevere una risposta JSON simile alla seguente.
Utilizzare l'esecuzione del codice in chat
Puoi anche utilizzare l'esecuzione di codice nell'ambito di una chat.
REST
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-3.5-flash:generateContent -d \
$'{
"tools": [{'code_execution': {}}],
"contents": [
{
"role": "user",
"parts": {
"text": "Can you print \"Hello world!\"?"
}
},
{
"role": "model",
"parts": [
{
"text": ""
},
{
"executable_code": {
"language": "PYTHON",
"code": "\nprint(\"hello world!\")\n"
}
},
{
"code_execution_result": {
"outcome": "OUTCOME_OK",
"output": "hello world!\n"
}
},
{
"text": "I have printed \"hello world!\" using the provided python code block. \n"
}
],
},
{
"role": "user",
"parts": {
"text": "What is the sum of the first 50 prime numbers? Generate and run code for the calculation, and make sure you get all 50."
}
}
]
}'
(Solo Gemini 3 Flash) Utilizzare l'esecuzione del codice con le immagini
Gemini 3 Flash può scrivere ed eseguire codice Python per manipolare e ispezionare attivamente le immagini. Puoi utilizzare l'esecuzione del codice con le immagini per:
Ingrandisci e ispeziona le immagini: rileva quando i dettagli sono troppo piccoli (ad esempio, la lettura di un indicatore lontano dalla videocamera) e scrivi codice per ritagliare e riesaminare l'area a una risoluzione più elevata.
Matematica visiva: esegui calcoli in più passaggi utilizzando il codice (ad esempio, somma le voci di una ricevuta).
Annotazione delle immagini: annota le immagini per rispondere a domande, ad esempio disegnando frecce tra gli oggetti per mostrare le relazioni.
Per utilizzare l'esecuzione del codice con le immagini, attiva l'esecuzione del codice durante la configurazione del modello e invia un prompt con un'immagine da ispezionare per il modello:
Python
# Example input image image_path = "https://storage.googleapis.com/cloud-samples-data/generative-ai/image/chips.jpeg" image_bytes = requests.get(image_path).content image = types.Part.from_bytes( data=image_bytes, mime_type="image/jpeg" ) response = client.models.generate_content( model=MODEL_ID, contents=[image, "Locate the ESMT chip. What are the numbers on the chip?"], config=types.GenerateContentConfig( tools=[types.Tool(code_execution=types.ToolCodeExecution)] ), )
Esecuzione del codice e chiamata di funzione
L'esecuzione di codice e la chiamata di funzione sono funzionalità simili:
- L'esecuzione del codice consente al modello di eseguire il codice nel backend dell'API in un ambiente fisso e isolato.
- La chiamata di funzione ti consente di eseguire le funzioni richieste dal modello nell'ambiente che preferisci.
In generale, dovresti preferire l'utilizzo dell'esecuzione del codice se può gestire il tuo caso d'uso. L'esecuzione del codice è più semplice da usare (basta attivarla) e si risolve con una
singola richiesta GenerateContent. La chiamata di funzioni richiede un'ulteriore
richiesta GenerateContent per restituire l'output di ogni chiamata di funzione.
Nella maggior parte dei casi, devi utilizzare la chiamata di funzione se hai funzioni personalizzate che vuoi eseguire localmente e l'esecuzione di codice se vuoi che l'API scriva ed esegua codice Python per te e restituisca il risultato.
Fatturazione
Non sono previsti costi aggiuntivi per l'attivazione dell'esecuzione di codice dall'API Gemini. Ti verrà addebitato l'importo in base alla tariffa attuale dei token di input e output, a seconda del modello Gemini che utilizzi.
Ecco alcune altre informazioni da sapere sulla fatturazione per l'esecuzione del codice:
- Ti viene addebitato un costo una sola volta per i token di input che trasmetti al modello e per i token di input intermedi generati dall'utilizzo dello strumento di esecuzione del codice.
- Ti vengono addebitati i token di output finali restituiti nella risposta dell'API.
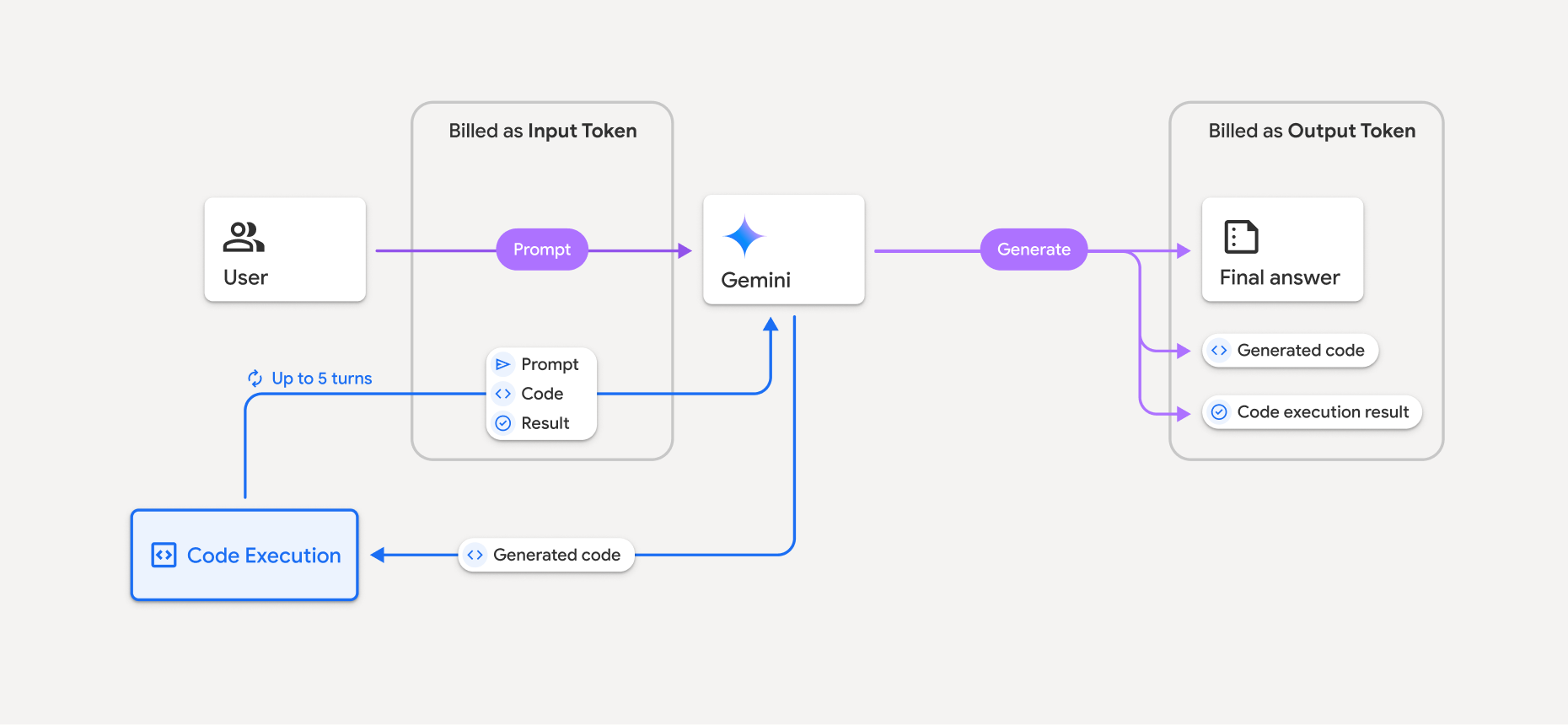
- Ti viene addebitata la tariffa attuale dei token di input e output in base al modello Gemini che utilizzi.
- Se Gemini utilizza l'esecuzione del codice durante la generazione della risposta, il prompt originale, il codice generato e il risultato del codice eseguito vengono etichettati come token intermedi e vengono fatturati come token di input.
- Gemini genera quindi un riepilogo e restituisce il codice generato, il risultato del codice eseguito e il riepilogo finale. Questi vengono fatturati come token di output.
- L'API Gemini include un conteggio dei token intermedi nella risposta dell'API, in modo da poter tenere traccia di eventuali token di input aggiuntivi oltre a quelli passati nel prompt iniziale.
Il codice generato può includere sia testo che output multimodali, come immagini.
Limitazioni
- Il modello può solo generare ed eseguire codice. Non può restituire altri artefatti come i file multimediali.
- Lo strumento di esecuzione del codice non supporta gli URI di file come input/output. Tuttavia,
lo strumento di esecuzione del codice supporta l'input di file e l'output di grafici come
byte incorporati. Utilizzando queste funzionalità di input e output, puoi caricare
file CSV e di testo, porre domande sui file e generare
grafici Matplotlib come parte del risultato dell'esecuzione del codice.
I tipi MIME supportati per i byte incorporati sono
.cpp,.csv,.java,.jpeg,.js,.png,.py,.tse.xml. - L'esecuzione del codice può durare al massimo 30 secondi prima del timeout.
- In alcuni casi, l'attivazione dell'esecuzione del codice può comportare regressioni in altre aree dell'output del modello (ad esempio, la scrittura di una storia).