

Gen AI evaluation service fornisce strumenti di livello aziendale per la valutazione oggettiva e basata sui dati dei modelli di AI generativa. Supporta e fornisce informazioni su una serie di attività di sviluppo, come le migrazioni dei modelli, la modifica dei prompt e l'ottimizzazione.
Funzionalità di Gen AI evaluation service
La funzionalità distintiva di Gen AI evaluation service è la possibilità di utilizzare le griglie di valutazione adattive, un insieme di test personalizzati superati/non superati per ogni singolo prompt. Le griglie di valutazione sono simili ai test delle unità nello sviluppo software e mirano a migliorare le prestazioni del modello in una varietà di attività.
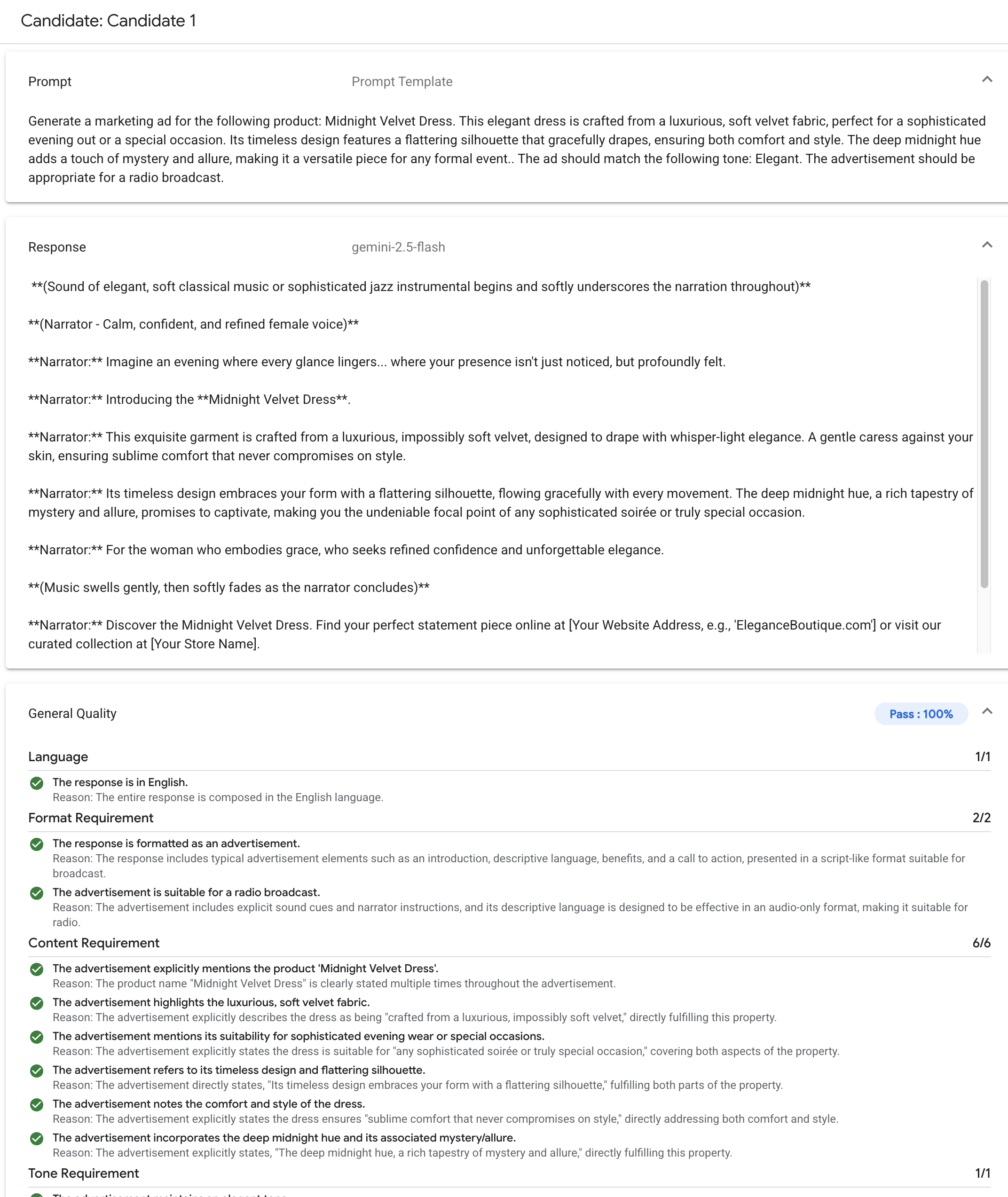
Gen AI evaluation service supporta i seguenti metodi di valutazione comuni:
Griglie di valutazione adattive (consigliate): genera un insieme unico di griglie di valutazione superate/non superate per ogni singolo prompt nel set di dati.
Griglie di valutazione statiche: applica un insieme fisso di criteri di punteggio a tutti i prompt.
Metriche basate sul calcolo: utilizza algoritmi deterministici come
ROUGEoBLEUquando sono disponibili dati empirici reali.Funzioni personalizzate: definisci la tua logica di valutazione in Python per requisiti specializzati.
Generazione del set di dati di valutazione
Puoi creare un set di dati di valutazione nei seguenti modi:
Carica un file contenente istanze di prompt complete oppure fornisci un modello di prompt insieme a un file corrispondente di valori delle variabili per popolare i prompt completati.
Esegui il campionamento direttamente dai log di produzione per valutare l'utilizzo del modello nel mondo reale.
Utilizza la generazione di dati sintetici per generare un numero elevato di esempi coerenti per qualsiasi modello di prompt.
Interfacce supportate
Puoi definire ed eseguire le valutazioni utilizzando le seguenti interfacce:
Google Cloud Console: un'interfaccia utente web che fornisce un flusso di lavoro guidato end-to-end. Gestisci i set di dati, esegui le valutazioni e approfondisci i report e le visualizzazioni interattive. Consulta Eseguire la valutazione utilizzando la console.
SDK Python: esegui le valutazioni a livello di programmazione e visualizza i confronti dei modelli affiancati direttamente nel tuo ambiente Colab o Jupyter. Consulta Eseguire la valutazione utilizzando il client GenAI nell'SDK Agent Platform
Casi d'uso
Gen AI evaluation service ti consente di vedere il rendimento di un modello per le tue attività specifiche e in base ai tuoi criteri univoci, fornendo informazioni preziose che non possono essere derivate dalle classifiche pubbliche e dai benchmark generali. Supporta le attività di sviluppo critiche, tra cui:
Migrazioni dei modelli: confronta le versioni dei modelli per comprendere le differenze comportamentali e ottimizzare di conseguenza i prompt e le impostazioni.
Trovare il modello migliore: esegui confronti diretti dei modelli Google e di terze parti sui tuoi dati per stabilire una baseline di rendimento e identificare la soluzione migliore per il tuo caso d'uso.
Miglioramento dei prompt: utilizza i risultati della valutazione per guidare i tuoi sforzi di personalizzazione. La riesecuzione di una valutazione crea un ciclo di feedback stretto, fornendo feedback immediati e quantificabili sulle modifiche.
Ottimizzazione del modello: valuta la qualità di un modello ottimizzato applicando criteri di valutazione coerenti a ogni esecuzione.
Valutazione degli agenti: valuta il rendimento di un agente utilizzando metriche specifiche per gli agenti, come le tracce degli agenti e la qualità delle risposte.
Workflow di valutazione
In genere, il completamento di una valutazione richiede i seguenti passaggi:
Crea un set di dati di valutazione: assembla un set di dati di istanze di prompt che riflettano il tuo caso d'uso specifico. Puoi includere risposte di riferimento (dati empirici reali) se prevedi di utilizzare metriche basate sul calcolo.
Definisci le metriche di valutazione: scegli le metriche che vuoi utilizzare per misurare il rendimento del modello.
Genera risposte del modello: seleziona uno o più modelli per generare risposte per il set di dati. L'SDK Agent Platform supporta qualsiasi modello chiamabile tramite
LiteLLM, mentre la console supporta i modelli Google Gemini.Esegui la valutazione: esegui il job di valutazione, che valuta le risposte di ogni modello in base alle metriche selezionate.
Interpreta i risultati: esamina i punteggi aggregati e le singole risposte per analizzare il rendimento del modello.
Metriche di valutazione
Di seguito sono riportati i concetti fondamentali relativi alle metriche di valutazione:
Griglie di valutazione: i criteri per valutare la risposta di un modello o di un'applicazione LLM.
Metriche: un punteggio che misura l'output del modello in base alle griglie di valutazione.
Gen AI evaluation service offre le seguenti categorie di metriche:
Metriche basate su griglie di valutazione: incorpora gli LLM nei workflow di valutazione per valutare la qualità delle risposte del modello. Le valutazioni basate su griglie di valutazione sono adatte a una varietà di attività, in particolare la qualità della scrittura, la sicurezza e il rispetto delle istruzioni, che spesso sono difficili da valutare con algoritmi deterministici.
Griglie di valutazione adattive (consigliate): le griglie di valutazione vengono generate dinamicamente per ogni prompt, come i test delle unità. Le risposte vengono valutate con un insieme unico di test superati/non superati per ogni singolo prompt nel set di dati. Le griglie di valutazione mantengono la valutazione pertinente all'attività richiesta e mirano a fornire risultati oggettivi, spiegabili e coerenti.
Le griglie di valutazione adattive sono in genere il modo più rapido per iniziare a utilizzare le valutazioni, garantendo che ogni valutazione sia pertinente all'attività specifica da valutare.
Griglie di valutazione statiche: le griglie di valutazione vengono definite in modo esplicito e la stessa griglia di valutazione si applica a tutti i prompt. Le risposte vengono valutate con lo stesso insieme di valutatori basati su punteggi numerici. Un singolo punteggio numerico (ad es. 1-5) per prompt. Utilizza le griglie di valutazione statiche quando è richiesta una valutazione su una dimensione molto specifica o quando è richiesta la stessa griglia di valutazione per tutti i prompt.
Metriche basate sul calcolo: valuta le risposte con algoritmi deterministici, in genere utilizzando dati empirici reali. Un punteggio numerico (ad es. 0,0-1,0) per prompt. Quando sono disponibili dati empirici reali e possono essere abbinati a un metodo deterministico.
Metriche delle funzioni personalizzate (solo SDK Agent Platform): definisci la tua metrica tramite una funzione Python.
Esempio di griglie di valutazione adattive
Il processo di valutazione per ogni prompt utilizza un sistema a due passaggi:
Generazione della griglia di valutazione: il servizio analizza prima il prompt e genera un elenco di test specifici e verificabili (le griglie di valutazione) che una buona risposta deve soddisfare.
Convalida della griglia di valutazione: dopo che il modello genera una risposta, il servizio la valuta in base a ogni griglia di valutazione, fornendo un verdetto chiaro
PassoFaile una motivazione.
Il risultato finale è una percentuale di superamento aggregata e una suddivisione dettagliata delle griglie di valutazione superate dal modello, che ti fornisce informazioni utili per diagnosticare i problemi e misurare i miglioramenti.
Passando da punteggi soggettivi di alto livello a risultati di test granulari e oggettivi, puoi adottare un ciclo di sviluppo basato sulla valutazione e applicare le best practice di ingegneria del software al processo di creazione di applicazioni di AI generativa.
L'esempio seguente mostra le griglie di valutazione adattive di esempio generate per un insieme di prompt:
Prompt utente: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
Per questo prompt, il passaggio di generazione della griglia di valutazione potrebbe produrre le seguenti griglie di valutazione:
Griglia di valutazione 1: la risposta è un riassunto dell'articolo fornito.
Griglia di valutazione 2: la risposta contiene esattamente quattro frasi.
Griglia di valutazione 3: la risposta mantiene un tono ottimistico.
Il modello potrebbe produrre la seguente risposta: The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
Durante la convalida della griglia di valutazione, Gen AI evaluation service valuta la risposta in base a ogni griglia di valutazione:
Griglia di valutazione 1: la risposta è un riassunto dell'articolo fornito.
Esito:
PassMotivo: la risposta riassume accuratamente i punti principali.
Griglia di valutazione 2: la risposta contiene esattamente quattro frasi.
Esito:
PassMotivo: la risposta è composta da quattro frasi distinte
Griglia di valutazione 3: la risposta mantiene un tono ottimistico.
Esito:
FailMotivo: l'ultima frase introduce un punto negativo, che sminuisce il tono ottimistico.
La percentuale di superamento finale per questa risposta è del 66,7%. Per confrontare due modelli, puoi valutare le loro risposte in base a questo stesso insieme di test generati e confrontare le percentuali di superamento complessive.
Iniziare a utilizzare le valutazioni
Puoi iniziare a utilizzare le valutazioni utilizzando la console.
In alternativa, il seguente codice mostra come completare una valutazione con il client GenAI nell'SDK Agent Platform:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Agent Platform",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
Gen AI evaluation service offre due interfacce SDK Agent Platform:
Client GenAI nell'SDK Agent Platform (consigliato) (anteprima)
from vertexai import clientIl client GenAI è l'interfaccia più recente e consigliata per la valutazione, a cui si accede tramite la classe Client unificata. Supporta tutti i metodi di valutazione ed è progettato per i workflow che includono il confronto dei modelli, la visualizzazione in notebook e gli approfondimenti per la personalizzazione dei modelli.
Modulo di valutazione nell'SDK Agent Platform (GA)
from vertexai.evaluation import EvalTaskIl modulo di valutazione è l'interfaccia precedente, mantenuta per la compatibilità con le versioni precedenti dei workflow esistenti, ma non è più in fase di sviluppo attivo. Vi si accede tramite la classe
EvalTask. Questo metodo supporta le metriche standard LLM-as-a-judge e le metriche basate su calcolo, ma non supporta i metodi di valutazione più recenti come le griglie di valutazione adattive.
Aree geografiche supportate
Le seguenti regioni sono supportate per Gen AI evaluation service:
Iowa (
us-central1)Carolina del Sud (
us-east1)Virginia del Nord (
us-east4)Columbus, Ohio (
us-east5)Dallas, Texas (
us-south1)Oregon (
us-west1)Las Vegas, Nevada (
us-west4)Varsavia, Polonia (
europe-central2)Finlandia (
europe-north1)Madrid, Spagna (
europe-southwest1)Belgio (
europe-west1)Paesi Bassi (
europe-west4)Milano, Italia (
europe-west8)Parigi, Francia (
europe-west9)Globale (
global)
Notebook disponibili
| Link ai notebook | Descrizione |
|---|---|
| Guida introduttiva: valutazione rapida dell'AI generativa | Fornisce un'introduzione a Gen AI evaluation service. |
| Valutazione dei modelli di terze parti con Gen AI evaluation service | Mostra come utilizzare l'**SDK Agent Platform** per valutare vari tipi di modelli di terze parti, inclusi i modelli a cui si accede tramite API (come OpenAI, Anthropic), Model as a Service (MaaS) da Vertex Model Garden e gli endpoint Bring Your Own Model (BYOM). |
| Migrazione dei modelli con Gen AI evaluation service | Mostra come utilizzare l'**SDK Agent Platform** per Gen AI evaluation service per confrontare due modelli proprietari (ad esempio Gemini 2.0 Flash con Gemini 2.5 Flash). Evidenzia l'utilizzo di metriche predefinite basate su griglie di valutazione adattive e come i risultati della valutazione possono guidare l'ottimizzazione dei prompt. Vengono trattate anche le funzionalità chiave come la valutazione di più candidati, la visualizzazione in notebook e la valutazione batch asincrona. |
| Valutazione della qualità da testo a immagine con Gen AI evaluation service | Mostra come utilizzare l'SDK Vertex AI per Gen AI evaluation service per valutare la qualità delle immagini generate in base ai prompt di testo. Mostra l'utilizzo della metrica Gecko predefinita basata su griglie di valutazione adattive. |
| Valutazione della qualità da testo a video con Gen AI evaluation service | Mostra come utilizzare l'**SDK Agent Platform** per Gen AI evaluation service per valutare la qualità dei video generati in base ai prompt di testo. Mostra l'utilizzo della metrica Gecko predefinita basata su griglie di valutazione adattive. |