

Questa pagina descrive come visualizzare e interpretare i risultati della valutazione del modello dopo averla eseguita.
Visualizza i risultati di una valutazione
Dopo aver definito l'attività di valutazione, eseguila per ottenere i risultati della valutazione, come segue:
from vertexai.evaluation import EvalTask
eval_result = EvalTask(
dataset=DATASET,
metrics=[METRIC_1, METRIC_2, METRIC_3],
experiment=EXPERIMENT_NAME,
).evaluate(
model=MODEL,
experiment_run=EXPERIMENT_RUN_NAME,
)
La classe EvalResult rappresenta il risultato di un'esecuzione di valutazione con i seguenti attributi:
summary_metrics: un dizionario di metriche di valutazione aggregate per un'esecuzione della valutazione.metrics_table: una tabellapandas.DataFramecontenente input, risposte, spiegazioni e risultati delle metriche del set di dati di valutazione per riga.metadata: il nome dell'esperimento e il nome dell'esecuzione dell'esperimento per l'esecuzione della valutazione.
La classe EvalResult è definita come segue:
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: A dictionary of aggregated evaluation metrics for an evaluation run.
metrics_table: A pandas.DataFrame table containing evaluation dataset inputs,
responses, explanations, and metric results per row.
metadata: The experiment name and experiment run name for the evaluation run.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional["pd.DataFrame"] = None
metadata: Optional[Dict[str, str]] = None
Con l'uso delle funzioni helper, i risultati della valutazione possono essere visualizzati nel notebook di Colab come segue:

Visualizzare i risultati della valutazione
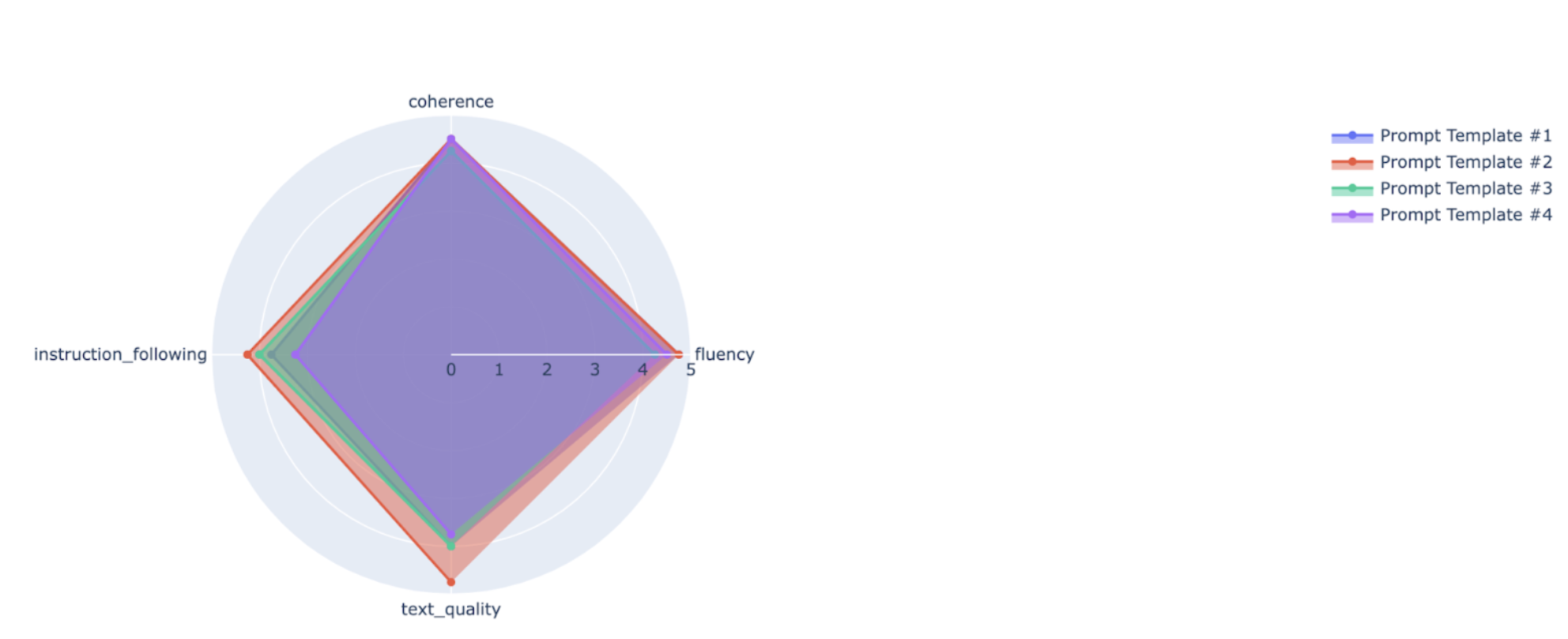
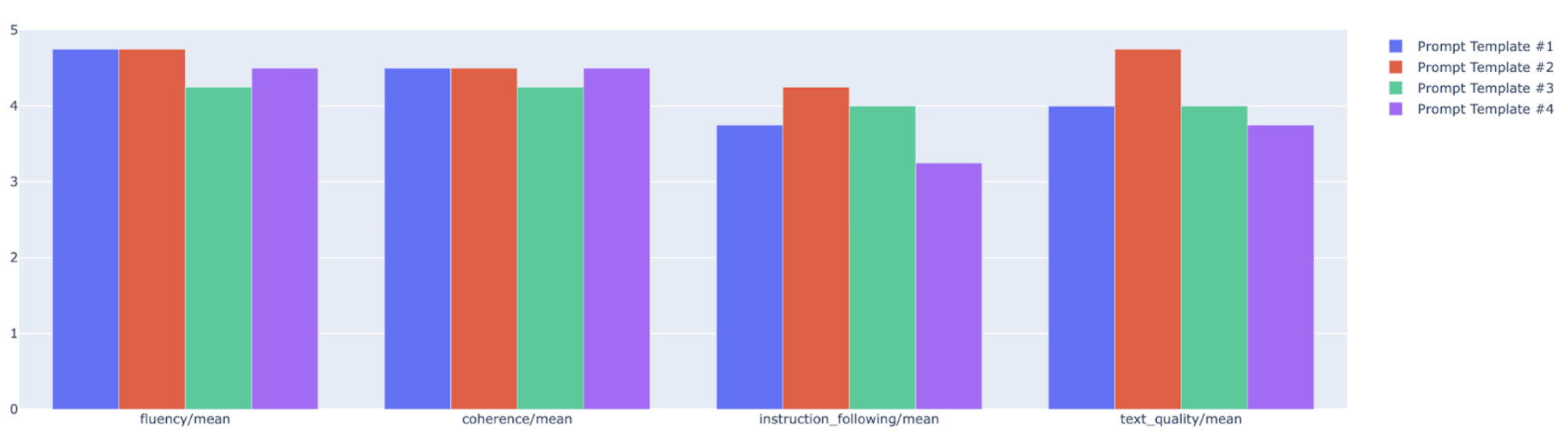
Puoi tracciare metriche riepilogative in un grafico radar o a barre per la visualizzazione e il confronto tra i risultati di diverse esecuzioni di valutazione. Questa visualizzazione può essere utile per valutare diversi modelli e diversi modelli di prompt.
Nell'esempio seguente, visualizziamo quattro metriche (coerenza, fluidità, rispetto delle istruzioni e qualità complessiva del testo) per le risposte generate utilizzando quattro diversi modelli di prompt. Dal grafico radar e a barre, possiamo dedurre che il modello di prompt n. 2 supera costantemente gli altri modelli in tutte e quattro le metriche. Ciò è particolarmente evidente nei punteggi significativamente più alti per il rispetto delle istruzioni e la qualità del testo. In base a questa analisi, il modello di prompt n. 2 sembra essere la scelta più efficace tra le quattro opzioni.
Comprendere i risultati delle metriche
Le tabelle seguenti elencano vari componenti dei risultati a livello di istanza e aggregati inclusi rispettivamente in metrics_table e summary_metrics per PointwiseMetric, PairwiseMetric e le metriche basate sul calcolo:
PointwiseMetric
Risultati a livello di istanza
| Colonna | Descrizione |
|---|---|
| risposta | La risposta generata per il prompt dal modello. |
| punteggio | La valutazione assegnata alla risposta in base ai criteri e alla griglia di valutazione. Il punteggio può essere binario (0 e 1), in scala Likert (da 1 a 5 o da -2 a 2) o mobile (da 0, 0 a 1,0). |
| spiegazione | Il motivo del punteggio del modello di valutazione. Utilizziamo il ragionamento chain-of-thought per guidare il modello di valutazione a spiegare la logica alla base di ogni verdetto. È stato dimostrato che costringere il modello di valutazione a ragionare migliora l'accuratezza della valutazione. |
Risultati aggregati
| Colonna | Descrizione |
|---|---|
| punteggio medio | Punteggio medio per tutte le istanze. |
| deviazione standard | Deviazione standard per tutti i punteggi. |
PairwiseMetric
Risultati a livello di istanza
| Colonna | Descrizione |
|---|---|
| risposta | La risposta generata per il prompt dal modello candidato. |
| baseline_model_response | La risposta generata per il prompt dal modello di riferimento. |
| pairwise_choice | Il modello con la risposta migliore. I valori possibili sono CANDIDATE, BASELINE o TIE. |
| spiegazione | Il motivo della scelta del modello di giudice. |
Risultati aggregati
| Colonna | Descrizione |
|---|---|
| candidate_model_win_rate | Proporzione di volte in cui il modello giudice ha deciso che il modello candidato ha fornito la risposta migliore rispetto al totale delle risposte. Intervalli da 0 a 1. |
| baseline_model_win_rate | Proporzione di volte in cui il modello giudice ha deciso che il modello di base ha fornito la risposta migliore rispetto al totale delle risposte. Intervalli da 0 a 1. |
Metriche basate su calcolo
Risultati a livello di istanza
| Colonna | Descrizione |
|---|---|
| risposta | La risposta del modello in fase di valutazione. |
| riferimento | La risposta di riferimento. |
| punteggio | Il punteggio viene calcolato per ogni coppia di risposte e riferimenti. |
Risultati aggregati
| Colonna | Descrizione |
|---|---|
| punteggio medio | Punteggio medio per tutte le istanze. |
| deviazione standard | Deviazione standard per tutti i punteggi. |
Esempi
Gli esempi in questa sezione mostrano come leggere e comprendere i risultati della valutazione.
Esempio 1: valutazione basata su punti
L'esempio seguente mostra un'istanza di valutazione puntuale per TEXT_QUALITY. Il punteggio della valutazione puntuale della metrica TEXT_QUALITY è 4 (su una scala da 1 a 5), il che significa che la risposta è buona. Inoltre, la spiegazione nel risultato della valutazione mostra perché il modello di valutazione ritiene che la previsione meriti il punteggio 4 e non un punteggio superiore o inferiore.
Set di dati
prompt: "Riassumi il seguente testo in modo che possa essere compreso da un bambino di cinque anni: Social Media Platform Faces Backlash Over Content Moderation Policies\nA prominent social media platform finds itself embroiled in controversy as users and content creators express discontent over its content moderation policies. Le accuse di censura parziale, applicazione incoerente e soppressione di determinati punti di vista hanno suscitato indignazione tra gli utenti che sostengono che la piattaforma stia soffocando la libertà di parola. D'altra parte, la piattaforma afferma che le sue norme sono progettate per mantenere un ambiente online sicuro e inclusivo. Questa controversia solleva questioni più ampie sul ruolo dei social media nel plasmare il discorso pubblico e sulle responsabilità delle piattaforme nella cura dei contenuti online".response: "Le persone sono arrabbiate con un sito web perché pensano che non sia giusto ciò che possono pubblicare. Alcune persone affermano che il sito web impedisce loro di dire ciò che vogliono. Tuttavia, il sito web afferma di impegnarsi per la sicurezza di tutti. Questo fa sorgere il dubbio se i siti web debbano controllare ciò che le persone possono dire online".
Risultato
score: 4,explanation: Il riepilogo nella risposta segue l'istruzione di riassumere il contesto in modo che possa essere compreso da un bambino di cinque anni. Si basa sul contesto e fornisce dettagli importanti nel riepilogo. Tuttavia, la lingua utilizzata nella risposta è un po' prolissa.
Esempio 2: valutazione basata su coppie
Questo esempio è una valutazione di confronto a coppie su PAIRWISE_QUESTION_ANSWERING_QUALITY. Il risultato pairwise_choice mostra che la risposta del candidato "La Francia è un paese situato nell'Europa occidentale" è preferita dal modello giudice rispetto alla risposta di base "La Francia è un paese" per rispondere alla domanda nel prompt. Analogamente ai risultati puntuali, viene fornita anche una spiegazione per illustrare perché la risposta del candidato è migliore di quella di base (in questo caso, la risposta del candidato è più utile).
Set di dati
prompt: "Puoi rispondere alla domanda su dove si trova la Francia in base al seguente paragrafo? La Francia è un paese situato nell'Europa occidentale. Confina con Belgio, Lussemburgo, Germania, Svizzera, Italia, Monaco, Spagna e Andorra. La costa francese si estende lungo il Canale della Manica, il Mare del Nord, l'Oceano Atlantico e il Mar Mediterraneo. Nota per la sua ricca storia, i suoi monumenti iconici come la Torre Eiffel e la sua deliziosa cucina, la Francia è una delle principali potenze culturali ed economiche in Europa e nel mondo."response: "La Francia è un paese situato nell'Europa occidentale.",baseline_model_response: "La Francia è un paese.",
Risultato
pairwise_choice: CANDIDATE,explanation: la risposta BASELINE è fondata, ma non risponde completamente alla domanda. La risposta di CANDIDATE, tuttavia, è corretta e fornisce dettagli utili sulla posizione della Francia.
Passaggi successivi
Prova un notebook di esempio per la valutazione.
Scopri di più sulla valutazione dell'AI generativa.