

Il modello e lo strumento Gemini Computer Use ti consentono di abilitare le tue applicazioni per interagire e automatizzare le attività nel browser. Utilizzando gli screenshot, il modello e lo strumento Utilizzo del computer possono dedurre informazioni su uno schermo del computer ed eseguire azioni generando azioni specifiche della UI, come clic del mouse e input da tastiera. Analogamente alla chiamata di funzioni, devi scrivere il codice dell'applicazione lato client per ricevere la chiamata di funzioni del modello Computer Use e dello strumento ed eseguire le azioni corrispondenti.
Con il modello e lo strumento Computer Use, puoi creare agenti in grado di:
- Automatizza l'inserimento di dati ripetitivi o la compilazione di moduli sui siti web.
- Navigare sui siti web per raccogliere informazioni.
- Aiuta gli utenti eseguendo sequenze di azioni nelle applicazioni web.
Questa guida tratta i seguenti argomenti:
- Come funzionano il modello e lo strumento Utilizzo del computer
- Come attivare il modello e lo strumento Utilizzo del computer
- Come inviare richieste, ricevere risposte e creare loop dell'agente
- Quali azioni del computer sono supportate
- Assistenza per la protezione e la sicurezza
- Visualizza l'anteprima dei prezzi
Questa guida presuppone che tu stia utilizzando l'SDK Gen AI per Python e che tu abbia familiarità con l'API Playwright.
Il modello e lo strumento Utilizzo del computer non sono supportati nelle altre lingue dell'SDK o nella console Google Cloud durante questa anteprima.
Inoltre, puoi visualizzare l'implementazione di riferimento per il modello e lo strumento di utilizzo del computer su GitHub.
Modelli supportati
Il modello e lo strumento di utilizzo del computer sono supportati quando utilizzi i seguenti modelli:
Fai clic per espandere i modelli supportati
Come funzionano il modello e lo strumento Utilizzo del computer
Anziché generare risposte di testo, il modello e lo strumento di utilizzo del computer determinano quando eseguire azioni specifiche dell'interfaccia utente, come i clic del mouse, e restituiscono i parametri necessari per eseguire queste azioni. Devi scrivere il codice dell'applicazione lato client per
ricevere il modello e lo strumento di utilizzo del computer function_call ed eseguire le azioni corrispondenti.
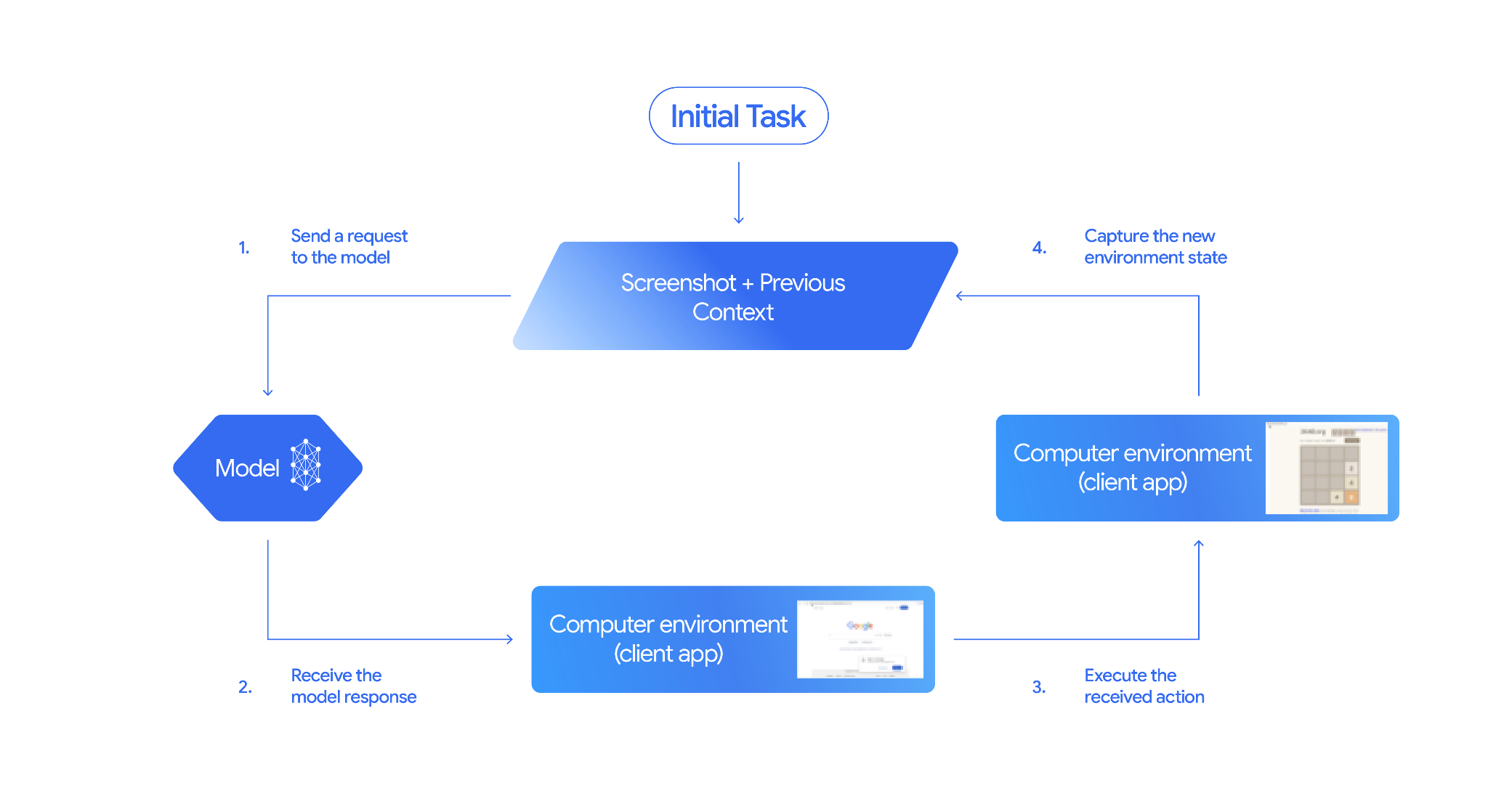
L'utilizzo del computer e le interazioni con gli strumenti seguono un processo di ciclo agentico:
Inviare una richiesta al modello
- Aggiungi il modello e lo strumento Utilizzo del computer ed eventualmente altri strumenti alla tua richiesta API.
- Richiedi al modello e allo strumento Computer Use la richiesta dell'utente e uno screenshot che rappresenti lo stato attuale della GUI.
Ricevere la risposta del modello
- Il modello analizza la richiesta e lo screenshot dell'utente e genera una
risposta che include un
function_callsuggerito che rappresenta un'azione dell'interfaccia utente (ad esempio, "fai clic sulla coordinata (x,y)" o "digita "testo""). Consulta Azioni supportate per l'elenco di tutte le azioni che puoi utilizzare con il modello. - La risposta dell'API può includere anche un
safety_responseda un sistema di sicurezza interno che ha controllato l'azione proposta dal modello. Questosafety_responseclassifica l'azione come:- Regolare o consentita:l'azione è considerata sicura. Ciò può anche
essere rappresentato dall'assenza di
safety_response. - Richiede conferma:il modello sta per eseguire un'azione che potrebbe essere rischiosa (ad esempio, fare clic su un "banner di accettazione dei cookie").
- Regolare o consentita:l'azione è considerata sicura. Ciò può anche
essere rappresentato dall'assenza di
- Il modello analizza la richiesta e lo screenshot dell'utente e genera una
risposta che include un
Esegui l'azione ricevuta
- Il codice lato client riceve
function_calle qualsiasisafety_responsedi accompagnamento. - Se
safety_responseindica normale o consentito (o se non è presente alcunsafety_response), il codice lato client può eseguire ilfunction_callspecificato nell'ambiente di destinazione (ad esempio un browser web). - Se
safety_responseindica che è necessaria una conferma, la tua applicazione deve chiedere all'utente finale di confermare prima di eseguirefunction_call. Se l'utente conferma, procedi con l'esecuzione dell'azione. Se l'utente rifiuta, non eseguire l'azione.
- Il codice lato client riceve
Acquisire il nuovo stato dell'ambiente
- Se l'azione è stata eseguita, il client acquisisce un nuovo screenshot
della GUI e dell'URL corrente da inviare al
modello e allo strumento Computer Use nell'ambito di un
function_response. - Se un'azione è stata bloccata dal sistema di sicurezza o la conferma è stata negata dall'utente, l'applicazione potrebbe inviare un altro tipo di feedback al modello o terminare l'interazione.
- Se l'azione è stata eseguita, il client acquisisce un nuovo screenshot
della GUI e dell'URL corrente da inviare al
modello e allo strumento Computer Use nell'ambito di un
Al modello viene inviata una nuova richiesta con lo stato aggiornato. Il processo si ripete dal passaggio 2, con il modello e lo strumento di utilizzo del computer che utilizzano la nuova schermata (se fornita) e l'obiettivo in corso per suggerire l'azione successiva. Il ciclo continua finché l'attività non viene completata, si verifica un errore o il processo viene terminato (ad esempio, se una risposta viene bloccata dai filtri di sicurezza o dalla decisione dell'utente).
Il seguente diagramma illustra il funzionamento del modello e dello strumento Utilizzo del computer:
Attivare il modello e lo strumento Utilizzo del computer
Per attivare il modello e lo strumento Utilizzo del computer, utilizza gemini-3-flash-preview
o gemini-3.5-flash come modello e aggiungi
il modello e lo strumento Utilizzo del computer all'elenco degli strumenti attivati:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part, FunctionResponse client = genai.Client() # Add Computer Use model and tool to the list of tools generate_content_config = genai.types.GenerateContentConfig( tools=[ types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, ) ), ] ) # Example request using the Computer Use model and tool contents = [ Content( role="user", parts=[ Part(text="Go to google.com and search for 'weather in New York'"), ], ) ] response = client.models.generate_content( model="gemini-3-flash-preview", contents=contents, config=generate_content_config, )
Inviare una richiesta
Dopo aver configurato il modello e lo strumento di utilizzo del computer, invia un prompt al modello che includa l'obiettivo dell'utente e uno screenshot iniziale della GUI.
Puoi anche aggiungere facoltativamente quanto segue:
- Azioni escluse:se ci sono azioni dall'elenco delle azioni dell'interfaccia utente
supportate che non vuoi che il modello esegua, specifica
queste azioni in
excluded_predefined_functions. - Funzioni definite dall'utente:oltre al modello e allo strumento Utilizzo del computer, potresti voler includere funzioni personalizzate definite dall'utente.
Il seguente codice campione attiva il modello e lo strumento Computer Use e invia la richiesta al modello:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part client = genai.Client() # Specify predefined functions to exclude (optional) excluded_functions = ["drag_and_drop"] # Configuration for the Computer Use model and tool with browser environment generate_content_config = genai.types.GenerateContentConfig( tools=[ # 1. Computer Use tool with browser environment types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, # Optional: Exclude specific predefined functions excluded_predefined_functions=excluded_functions ) ), # 2. Optional: Custom user-defined functions (need to defined above) # types.Tool( # function_declarations=custom_functions # ) ], ) # Create the content with user message contents: list[Content] = [ Content( role="user", parts=[ Part(text="Search for highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping. Create a bulleted list of the 3 cheapest options in the format of name, description, price in an easy-to-read layout."), # Optional: include a screenshot of the initial state # Part.from_bytes( # data=screenshot_image_bytes, # mime_type='image/png', # ), ], ) ] # Generate content with the configured settings response = client.models.generate_content( model='gemini-3-flash-preview', contents=contents, config=generate_content_config, ) # Print the response output print(response.text)
Puoi anche includere funzioni personalizzate definite dall'utente per estendere la funzionalità
del modello. Consulta Utilizzare il modello e lo strumento Utilizzo del computer per casi di utilizzo mobileper informazioni su come configurare l'utilizzo del computer per casi di utilizzo mobile aggiungendo azioni come open_app, long_press_at e go_home
escludendo le azioni specifiche del browser.
Ricevi le risposte
Il modello risponde con uno o più FunctionCalls se determina che sono necessarie azioni dell'interfaccia utente o funzioni definite dall'utente per completare l'attività. Il codice dell'applicazione deve analizzare queste azioni, eseguirle e raccogliere i risultati. Il modello e lo strumento di utilizzo del computer supportano la chiamata di funzioni parallela, il che significa che il modello può restituire più azioni indipendenti in un singolo turno.
{
"content": {
"parts": [
{
"text": "I will type the search query into the search bar. The search bar is in the center of the page."
},
{
"function_call": {
"name": "type_text_at",
"args": {
"x": 371,
"y": 470,
"text": "highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping",
"press_enter": true
}
}
}
]
}
}
A seconda dell'azione, la risposta API potrebbe restituire anche un safety_response:
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
Esegui le azioni ricevute
Dopo aver ricevuto una risposta, il modello deve eseguire le azioni ricevute.
Il seguente codice estrae le chiamate di funzione da una risposta di Gemini, converte le coordinate dall'intervallo 0-1000 in pixel effettivi, esegue azioni del browser utilizzando Playwright e restituisce lo stato di riuscita o errore per ogni azione:
import time
from typing import Any, List, Tuple
def normalize_x(x: int, screen_width: int) -> int:
"""Convert normalized x coordinate (0-1000) to actual pixel coordinate."""
return int(x / 1000 * screen_width)
def normalize_y(y: int, screen_height: int) -> int:
"""Convert normalized y coordinate (0-1000) to actual pixel coordinate."""
return int(y / 1000 * screen_height)
def execute_function_calls(response, page, screen_width: int, screen_height: int) -> List[Tuple[str, Any]]:
"""
Extract and execute function calls from Gemini response.
Args:
response: Gemini API response object
page: Playwright page object
screen_width: Screen width in pixels
screen_height: Screen height in pixels
Returns:
List of tuples: [(function_name, result), ...]
"""
# Extract function calls and thoughts from the model's response
candidate = response.candidates[0]
function_calls = []
thoughts = []
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_calls.append(part.function_call)
elif hasattr(part, 'text') and part.text:
thoughts.append(part.text)
if thoughts:
print(f"Model Reasoning: {' '.join(thoughts)}")
# Execute each function call
results = []
for function_call in function_calls:
result = None
try:
if function_call.name == "open_web_browser":
print("Executing open_web_browser")
# Browser is already open via Playwright, so this is a no-op
result = "success"
elif function_call.name == "click_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
print(f"Executing click_at: ({actual_x}, {actual_y})")
page.mouse.click(actual_x, actual_y)
result = "success"
elif function_call.name == "type_text_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
text = function_call.args["text"]
press_enter = function_call.args.get("press_enter", False)
clear_before_typing = function_call.args.get("clear_before_typing", True)
print(f"Executing type_text_at: ({actual_x}, {actual_y}) text='{text}'")
# Click at the specified location
page.mouse.click(actual_x, actual_y)
time.sleep(0.1)
# Clear existing text if requested
if clear_before_typing:
page.keyboard.press("Control+A")
page.keyboard.press("Backspace")
# Type the text
page.keyboard.type(text)
# Press enter if requested
if press_enter:
page.keyboard.press("Enter")
result = "success"
else:
# For any functions not parsed above
print(f"Unrecognized function: {function_call.name}")
result = "unknown_function"
except Exception as e:
print(f"Error executing {function_call.name}: {e}")
result = f"error: {str(e)}"
results.append((function_call.name, result))
return results
Se il valore safety_decision restituito è require_confirmation, devi chiedere all'utente di confermare prima di procedere con l'esecuzione dell'azione. Ai sensi dei termini
di servizio, non è consentito aggirare le richieste di conferma umana.
Il seguente codice aggiunge una logica di sicurezza al codice precedente:
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true"
# ... Execute function call and append to results ...
Acquisire il nuovo stato
Dopo aver eseguito le azioni, invia il risultato dell'esecuzione della funzione al modello in modo che possa utilizzare queste informazioni per generare l'azione successiva. Se
sono state eseguite più azioni (chiamate parallele), devi inviare un
FunctionResponse per ciascuna nel turno successivo dell'utente. Per le funzioni definite dall'utente, FunctionResponse deve contenere il valore restituito della funzione eseguita.
function_response_parts = []
for name, result in results:
# Take screenshot after each action
screenshot = page.screenshot()
current_url = page.url
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
# Create the user feedback content with all responses
user_feedback_content = Content(
role="user",
parts=function_response_parts
)
# Append this feedback to the 'contents' history list for the next API call
contents.append(user_feedback_content)
Crea un loop dell'agente
Combina i passaggi precedenti in un ciclo per attivare le interazioni in più passaggi. Il ciclo deve gestire le chiamate di funzioni parallele. Ricordati di gestire correttamente la cronologia della conversazione (array dei contenuti) aggiungendo sia le risposte del modello sia le risposte della funzione.
Python
from google import genai from google.genai.types import Content, Part from playwright.sync_api import sync_playwright def has_function_calls(response): """Check if response contains any function calls.""" candidate = response.candidates[0] return any(hasattr(part, 'function_call') and part.function_call for part in candidate.content.parts) def main(): client = genai.Client() # ... (config setup from "Send a request to model" section) ... with sync_playwright() as p: browser = p.chromium.launch(headless=False) page = browser.new_page() page.goto("https://www.google.com") screen_width, screen_height = 1920, 1080 # ... (initial contents setup from "Send a request to model" section) ... # Agent loop: iterate until model provides final answer for iteration in range(10): print(f"\nIteration {iteration + 1}\n") # 1. Send request to model (see "Send a request to model" section) response = client.models.generate_content( model='gemini-3-flash-preview', contents=contents, config=generate_content_config, ) contents.append(response.candidates[0].content) # 2. Check if done - no function calls means final answer if not has_function_calls(response): print(f"FINAL RESPONSE:\n{response.text}") break # 3. Execute actions (see "Execute the received actions" section) results = execute_function_calls(response, page, screen_width, screen_height) time.sleep(1) # 4. Capture state and create feedback (see "Capture the New State" section) contents.append(create_feedback(results, page)) input("\nPress Enter to close browser...") browser.close() if __name__ == "__main__": main()
Gemini 3.5 Flash o versioni successive e casi d'uso per dispositivi mobili o computer
Il modello e lo strumento di utilizzo del computer supportano l'impostazione di ambienti mobile (ENVIRONMENT_MOBILE),
desktop (ENVIRONMENT_DESKTOP) o browser (ENVIRONMENT_BROWSER). Il valore predefinito è ENVIRONMENT_BROWSER.
Gli esempi seguenti mostrano come configurare l'ambiente di esecuzione per il modello e lo strumento Utilizzo del computer con Gemini 3.5 Flash o versioni successive.
API REST
Prima di utilizzare i dati della richiesta, apporta le sostituzioni seguenti:
- PROJECT_ID: il tuo ID progetto.
Metodo HTTP e URL:
POST https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/global/publishers/google/models/gemini-3.5-flash:generateContent
Corpo JSON della richiesta:
{
"contents": [
{
"role": "user",
"parts": {
"text": "find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. start by navigating directly to flights.google.com"
}
}
],
"generation_config": {
"candidateCount": 1
},
"tools": [
{
"computer_use": {
"environment": "ENVIRONMENT_BROWSER"
}
}
]
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere un codice di stato riuscito (2xx) e una risposta vuota.
Python
L'esempio seguente richiede python-genai versione 2.7.0 o successiva.
from google import genai
from google.genai.types import (
Part,
GenerateContentConfig,
Content,
Tool,
ComputerUse,
Environment,
ThinkingConfig,
)
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
Content(
role="user",
parts=[
Part(text="find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th"),
],
)
],
config=GenerateContentConfig(
temperature=1,
top_p=0.95,
top_k=40,
max_output_tokens=8192,
tools=[
Tool(
computer_use=ComputerUse(
environment=Environment.ENVIRONMENT_MOBILE
),
),
],
thinking_config=ThinkingConfig(
include_thoughts=True
),
)
)
Gemini 3 Flash e utilizzo mobile
Il seguente esempio per Gemini 3 Flash mostra come definire
funzioni personalizzate (come open_app, long_press_at e go_home), combinarle
con lo strumento di utilizzo del computer integrato di Gemini ed escludere
funzioni specifiche del browser non necessarie. Registrando queste funzioni personalizzate, il modello può
chiamarle in modo intelligente insieme alle azioni standard dell'interfaccia utente per completare le attività in
ambienti non browser.
from typing import Optional, Dict, Any
from google import genai
from google.genai import types
from google.genai.types import Content, Part
client = genai.Client()
def open_app(app_name: str, intent: Optional[str] = None) -> Dict[str, Any]:
"""Opens an app by name.
Args:
app_name: Name of the app to open (any string).
intent: Optional deep-link or action to pass when launching, if the app supports it.
Returns:
JSON payload acknowledging the request (app name and optional intent).
"""
return {"status": "requested_open", "app_name": app_name, "intent": intent}
def long_press_at(x: int, y: int, duration_ms: int = 500) -> Dict[str, int]:
"""Long-press at a specific screen coordinate.
Args:
x: X coordinate (absolute), scaled to the device screen width (pixels).
y: Y coordinate (absolute), scaled to the device screen height (pixels).
duration_ms: Press duration in milliseconds. Defaults to 500.
Returns:
Object with the coordinates pressed and the duration used.
"""
return {"x": x, "y": y, "duration_ms": duration_ms}
def go_home() -> Dict[str, str]:
"""Navigates to the device home screen.
Returns:
A small acknowledgment payload.
"""
return {"status": "home_requested"}
# Build function declarations
CUSTOM_FUNCTION_DECLARATIONS = [
types.FunctionDeclaration.from_callable(client=client, callable=open_app),
types.FunctionDeclaration.from_callable(client=client, callable=long_press_at),
types.FunctionDeclaration.from_callable(client=client, callable=go_home),
]
# Exclude browser functions
EXCLUDED_PREDEFINED_FUNCTIONS = [
"open_web_browser",
"search",
"navigate",
"hover_at",
"scroll_document",
"go_forward",
"key_combination",
"drag_and_drop",
]
# Utility function to construct a GenerateContentConfig
def make_generate_content_config() -> genai.types.GenerateContentConfig:
"""Return a fixed GenerateContentConfig with Computer Use + custom functions."""
return genai.types.GenerateContentConfig(
tools=[
types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER,
excluded_predefined_functions=EXCLUDED_PREDEFINED_FUNCTIONS,
)
),
types.Tool(function_declarations=CUSTOM_FUNCTION_DECLARATIONS),
]
)
# Create the content with user message
contents: list[Content] = [
Content(
role="user",
parts=[
# text instruction
Part(text="Open Chrome, then long-press at 200,400."),
# optional screenshot attachment
Part.from_bytes(
data=screenshot_image_bytes,
mime_type="image/png",
),
],
)
]
# Build your fixed config (from helper)
config = make_generate_content_config()
# Generate content with the configured settings
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=contents,
config=generate_content_config,
)
print(response)
Azioni supportate
Il modello e lo strumento Utilizzo del computer consentono al modello di richiedere le seguenti
azioni utilizzando un FunctionCall. Il codice lato client deve implementare la
logica di esecuzione per queste azioni. Consulta l'implementazione di riferimento per
gli esempi. La seguente tabella mostra le azioni supportate per l'ambiente del browser.
Gemini 3 Flash e Gemini 3.5 Flash hanno set di nomi FunctionCall diversi.
Gemini 3.5 Flash
| Nome comando | Descrizione | Argomenti (in Chiamata funzione) |
|---|---|---|
| fare clic | I clic sinistri in corrispondenza della coordinata. |
y: int (0-999)x: int
(0-999)intent: str
|
| double_click | Doppio clic sulla coordinata. |
y: int (0-999)x: int
(0-999)intent: str
|
| triple_click | Tre clic in corrispondenza delle coordinate. |
y: int (0-999)x: int
(0-999)intent: str
|
| middle_click | Il cursore fa clic al centro delle coordinate. |
y: int (0-999)x: int
(0-999)intent: str
|
| right_click | Fai clic con il tasto destro del mouse sulla coordinata. |
y: int (0-999)x: int
(0-999)intent: str
|
| mouse_down | Premere e tenere premuto il tasto del mouse in corrispondenza della coordinata. |
y: int (0-999)x: int
(0-999)intent: str
|
| mouse_up | Rilascia il tasto del mouse in corrispondenza della coordinata. |
y: int (0-999)x: int
(0-999)intent: str
|
| move | Sposta il cursore nella posizione specificata. |
y: int (0-999)x: int
(0-999)intent: str
|
| type | Digita il testo. |
text: strintent:
strpress_enter: bool (facoltativo, valore predefinito false)
|
| drag_and_drop | Trascina l'elemento da start_y e start_x a end_y e end_x |
start_y: int (0-999)start_x: int
(0-999)end_y: int (0-999)end_x:
int (0-999)intent: str
|
| wait | Attendi il numero di secondi specificato. |
intent: strseconds: int (facoltativo,
valore predefinito 1)
|
| press_key | Premi il tasto specificato e lo rilascia. | key: strintent: str |
| key_down | Premere e tenere premuto il tasto specificato. | key: strintent: str |
| key_up | Rilascia la chiave specificata. | key: strintent: str |
| tasto di scelta rapida | Premi la combinazione di tasti specificata. | keys: List[str]intent: str |
| take_screenshot | Restituisce uno screenshot della schermata corrente. | intent: str |
| scroll | Scorre verso l'alto, verso il basso, a sinistra o a destra in una coordinata di una distanza in pixel. |
y: int (0-999)x: int
(0-999)direction: str ("up", "down", "left",
"right")intent:
strmagnitude_in_pixels: int (0-999, facoltativo,
valore predefinito 300)
|
| go_back | Torna alla pagina web precedente nella cronologia del browser. | intent: str |
| navigate | Consente di andare direttamente a un URL specificato. | url: strintent: str |
| go_forward | Passa alla pagina web successiva nella cronologia del browser. | intent: str |
Gemini 3 Flash
| Nome comando | Descrizione | Argomenti (in Chiamata funzione) | Esempio di chiamata di funzione |
|---|---|---|---|
| open_web_browser | Apre il browser web. | Nessuno | {"name": "open_web_browser", "args": {}} |
| wait_5_seconds | Mette in pausa l'esecuzione per 5 secondi per consentire il caricamento dei contenuti dinamici o il completamento delle animazioni. | Nessuno | {"name": "wait_5_seconds", "args": {}} |
| go_back | Conduce alla pagina precedente nella cronologia del browser. | Nessuno | {"name": "go_back", "args": {}} |
| go_forward | Conduce alla pagina successiva nella cronologia del browser. | Nessuno | {"name": "go_forward", "args": {}} |
| search | Viene visualizzata la home page del motore di ricerca predefinito (ad esempio, Google). Utile per avviare una nuova attività di ricerca. | Nessuno | {"name": "search", "args": {}} |
| navigate | Il browser passa direttamente all'URL specificato. | url: str |
{"name": "navigate", "args": {"url": "https://www.wikipedia.org"}}
|
| click_at | Clic in una coordinata specifica della pagina web. I valori x e y si basano su una griglia 1000x1000 e vengono scalati in base alle dimensioni dello schermo. | y: int (0-999), x: int (0-999) |
{"name": "click_at", "args": {"y": 300, "x": 500}}
|
| hover_at | 521963309 Passa il mouse su una coordinata specifica della pagina web. Utile per visualizzare i sottomenu. x e y si basano su una griglia 1000x1000. | y: int (0-999) x: int (0-999) |
{"name": "hover_at", "args": {"y": 150, "x": 250}}
|
| type_text_at | Digita il testo in una coordinata specifica. Per impostazione predefinita, cancella prima il campo e premi INVIO dopo la digitazione, ma queste azioni possono essere disattivate. x e y si basano su una griglia 1000x1000. |
y: int (0-999), x: int (0-999),
text: str, press_enter: bool (facoltativo,
valore predefinito True), clear_before_typing: bool (facoltativo,
valore predefinito True)
|
{"name": "type_text_at", "args": {"y": 250, "x": 400,
"text": "search query", "press_enter": false}}
|
| key_combination | Premi tasti o combinazioni di tasti della tastiera, ad esempio "Ctrl+C" o "Invio". Utile per attivare azioni (come l'invio di un modulo con "Invio") o operazioni sugli appunti. |
keys: str (ad esempio, "invio", "control+c". Consulta il riferimento
API per l'elenco completo delle chiavi consentite)
|
{"name": "key_combination", "args": {"keys":
"Control+A"}}
|
| scroll_document | Scorre l'intera pagina web "verso l'alto", "verso il basso", "verso sinistra" o "verso destra". | direction: str ("up", "down", "left" o "right") |
{"name": "scroll_document", "args": {"direction": "down"}}
|
| scroll_at | Scorre un elemento o un'area specifici in corrispondenza della coordinata (x, y) nella direzione specificata di una determinata entità. Le coordinate e la magnitudo (valore predefinito 800) si basano su una griglia 1000x1000. |
y: int (0-999), x: int (0-999),
direction: str ("up", "down", "left", "right"),
magnitude: int (0-999, facoltativo, valore predefinito 800)
|
{"name": "scroll_at", "args": {"y": 500, "x": 500,
"direction": "down", "magnitude": 400}}
|
| drag_and_drop | Trascina un elemento da una coordinata iniziale (x, y) e lo rilascia in una coordinata di destinazione (destination_x, destination_y). Tutte le coordinate si basano su una griglia 1000x1000. |
y: int (0-999), x: int (0-999),
destination_y: int (0-999),
destination_x: int (0-999)
|
{"name": "drag_and_drop", "args": {"y": 100, "x": 100,
"destination_y": 500, "destination_x": 500}}
|
Gemini 3.5 Flash: hai accesso a diversi set di chiamate di funzioni a seconda dell'ambiente selezionato:
Ambiente mobile
| Nome comando | Descrizione | Argomenti (in Chiamata funzione) |
|---|---|---|
| open_app | Apre un'applicazione in base al nome. | intent: str |
| clic | I clic sinistri in corrispondenza della coordinata. |
y: int (0-999) x: int (0-999) intent: str |
| list_apps | Elenca le applicazioni disponibili sul dispositivo, restituendone i nomi e i nomi dei pacchetti. | intent: str |
| attesa | Attende il numero di secondi specificato. |
intent: str seconds: int(Optional, default 1) |
| go_back | Torna alla pagina web precedente nella cronologia del browser. | intent: str |
| tipo | Digita il testo. |
text: str intent: str press_enter: bool(Optional, default false) |
| drag_and_drop | Trascina l'elemento da start_y e start_x a end_y e end_x |
start_y: int (0-999) start_x: int (0-999) end_y: int (0-999) end_x: int (0-999) intent: str |
| long_press | Esegue una pressione prolungata in una coordinata y (0-999), x (0-999) specifica sullo schermo. |
y: int (0-999) x: int (0-999) intent: str seconds: int (facoltativo, valore predefinito 2) |
| press_key | Premi il tasto specificato e rilascialo. |
key: str intent: str |
| take_screenshot | Restituisce uno screenshot della schermata corrente. | intent: str |
Ambiente desktop
| Nome comando | Descrizione | Argomenti (in Chiamata funzione) |
|---|---|---|
| clic | I clic sinistri in corrispondenza della coordinata. |
y: int (0-999) x: int (0-999) intent: str |
| double_click | Doppio clic sulla coordinata. |
y: int (0-999) x: int (0-999) intent: str |
| triple_click | Tre clic in corrispondenza delle coordinate. |
y: int (0-999) x: int (0-999) intent: str |
| middle_click | Il cursore fa clic al centro delle coordinate. |
y: int (0-999) x: int (0-999) intent: str |
| right_click | Fai clic con il tasto destro del mouse sulla coordinata. |
y: int (0-999) x: int (0-999) intent: str |
| mouse_down | Premere e tenere premuto il tasto del mouse in corrispondenza della coordinata. |
y: int (0-999) x: int (0-999) intent: str |
| mouse_up | Rilascia il tasto del mouse in corrispondenza della coordinata. |
y: int (0-999) x: int (0-999) intent: str |
| move | Sposta il cursore nella posizione specificata. |
y: int (0-999) x: int (0-999) intent: str |
| tipo | Digita il testo. |
text: str intent: str press_enter: bool(Optional, default false) |
| drag_and_drop | Trascina l'elemento da start_y e start_x a end_y e end_x. |
start_y: int (0-999) start_x: int (0-999) end_y: int (0-999) end_x: int (0-999) intent: str |
| attesa | Attendi il numero di secondi specificato. |
intent: str seconds: int(Optional, default 1) |
| press_key | Premi il tasto specificato e lo rilascia. |
key: str intent: str |
| key_down | Premere e tenere premuto il tasto specificato. |
key: str intent: str |
| key_up | Rilascia la chiave specificata. |
key: str intent: str |
| tasto di scelta rapida | Premi la combinazione di tasti specificata. |
keys: List[str] intent: str |
| take_screenshot | Restituisce uno screenshot della schermata corrente. | intent: str |
| scorrere | Scorre verso l'alto, verso il basso, a sinistra o a destra in una coordinata di una distanza in pixel. |
y: int (0-999) x: int (0-999) direction: str ("up", "down", "left", "right") intent: str magnitude_in_pixels: int (0-999, facoltativo, valore predefinito 300) |
Protezione e sicurezza
Questa sezione descrive le misure di salvaguardia che il modello e lo strumento di utilizzo del computer sono in atto per migliorare il controllo e la sicurezza degli utenti. Descrive inoltre le best practice per mitigare i potenziali nuovi rischi che lo strumento potrebbe presentare.
Riconoscere la decisione relativa alla sicurezza
A seconda dell'azione, la risposta del modello e dello strumento Utilizzo del computer potrebbe includere un
safety_decision da un sistema di sicurezza interno. Questa decisione verifica l'azione proposta dallo strumento per la sicurezza.
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
Se safety_decision è require_confirmation, devi chiedere all'utente finale di confermare prima di procedere con l'esecuzione dell'azione.
Il seguente esempio di codice chiede all'utente finale una conferma prima di eseguire l'azione. Se l'utente non conferma l'azione, il ciclo termina. Se l'utente
conferma l'azione, questa viene eseguita e il campo safety_acknowledgement
viene contrassegnato come True.
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true" # Safety acknowledgement
# ... Execute function call and append to results ...
Se l'utente conferma, devi includere la conferma di sicurezza nel tuo FunctionResponse.
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url,
**extra_fr_fields}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
Rilevamento di prompt injection
Il modello e lo strumento Computer Use per Gemini 3.5 Flash o versioni successive supportano
un meccanismo di sicurezza avanzato per rilevare gli attacchi di prompt injection. Se attivata,
questa funzionalità controlla se uno screenshot incluso ha il potenziale per introdurre un
attacco di prompt injection. Puoi impostare questa funzionalità nella
configurazione del modello e dello strumento Utilizzo del computer. Il valore predefinito è false.
Gli esempi seguenti mostrano l'abilitazione del modello e della configurazione dello strumento Utilizzo del computer per attivare il rilevamento dell'iniezione di prompt:
API REST
Prima di utilizzare i dati della richiesta, apporta le sostituzioni seguenti:
- PROJECT_ID: il tuo ID progetto.
Metodo HTTP e URL:
POST https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/global/publishers/google/models/gemini-3.5-flash:generateContent
Corpo JSON della richiesta:
{
"contents": [
{
"role": "user",
"parts": {
"text": "find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. start by navigating directly to flights.google.com"
}
}
],
"generation_config": {
"candidateCount": 1
},
"tools": [
{
"computer_use": {
"environment": "ENVIRONMENT_BROWSER",
"enable_prompt_injection_detection": true
}
}
]
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere un codice di stato riuscito (2xx) e una risposta vuota.
Python
L'esempio seguente richiede python-genai versione 2.7.0 o successiva.
from google import genai
from google.genai.types import (
Part,
GenerateContentConfig,
Content,
Tool,
ComputerUse,
Environment,
ThinkingConfig,
)
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
Content(
role="user",
parts=[
Part(text="find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th"),
],
)
],
config=GenerateContentConfig(
temperature=1,
top_p=0.95,
top_k=40,
max_output_tokens=8192,
tools=[
Tool(
computer_use=ComputerUse(
environment=Environment.ENVIRONMENT_MOBILE,
enable_prompt_injection_detection=True
),
),
],
thinking_config=ThinkingConfig(
include_thoughts=True
),
)
)
Best practice per la sicurezza
Il modello e lo strumento di utilizzo del computer sono nuovi e presentano nuovi rischi di cui gli sviluppatori devono essere consapevoli:
- Contenuti non attendibili e truffe: mentre il modello cerca di raggiungere l'obiettivo dell'utente, potrebbe fare affidamento su fonti di informazioni e istruzioni non attendibili sullo schermo. Ad esempio, se l'obiettivo dell'utente è acquistare uno smartphone Pixel e il modello rileva una truffa del tipo "Pixel senza costi se completi un sondaggio", esiste la possibilità che il modello completi il sondaggio.
- Azioni involontarie occasionali: il modello può interpretare in modo errato l'obiettivo di un utente o i contenuti della pagina web, causando azioni errate come fare clic sul pulsante sbagliato o compilare il modulo errato. Ciò può comportare errori nelle attività o l'esfiltrazione di dati.
- Violazioni delle norme:le funzionalità dell'API potrebbero essere indirizzate, intenzionalmente o meno, verso attività che violano i termini e le norme di Google. Sono incluse azioni che potrebbero interferire con l'integrità di un sistema, compromettere la sicurezza, aggirare misure di sicurezza come i CAPTCHA, controllare dispositivi medici e così via.
Per affrontare questi rischi, devi implementare le seguenti misure di sicurezza e best practice:
- Human-in-the-loop (HITL):
- Implementa la conferma dell'utente:quando la risposta di sicurezza indica require_confirmation, devi implementare la conferma dell'utente prima dell'esecuzione.
- Fornisci istruzioni di sicurezza personalizzate:oltre ai controlli di conferma utente integrati, gli sviluppatori possono facoltativamente aggiungere un'istruzione di sistema personalizzata che applichi le proprie norme di sicurezza, per bloccare determinate azioni del modello o richiedere la conferma dell'utente prima che il modello intraprenda determinate azioni irreversibili ad alto rischio. Ecco un esempio di istruzione del sistema di sicurezza personalizzato che puoi includere quando interagisci con il modello.
Fai clic per visualizzare un esempio di creazione di una connessione
## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask th e user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in these cases: - User confirmation - When the task is complete or you have enough information to respond to the user
- Ambiente di esecuzione sicuro: esegui l'agente in un ambiente sicuro e sandbox per limitarne il potenziale impatto (ad esempio, una macchina virtuale (VM) sandbox, un container (come Docker) o un profilo browser dedicato con autorizzazioni limitate).
- Sanitizzazione dell'input:sanitizza tutto il testo generato dagli utenti nei prompt per mitigare il rischio di istruzioni non intenzionali o prompt injection. Si tratta di un utile livello di sicurezza, ma non sostituisce un ambiente di esecuzione sicuro.
- Liste consentite e liste bloccate: implementa meccanismi di filtraggio per controllare dove il modello può navigare e cosa può fare. Una lista bloccata di siti web vietati è un buon punto di partenza, mentre una lista consentita più restrittiva è ancora più sicura.
- Osservabilità e logging:mantieni log dettagliati per il debug,
il controllo e la risposta agli incidenti. Il tuo cliente deve registrare i prompt, gli screenshot, le azioni suggerite dal modello (
function_call), le risposte di sicurezza e tutte le azioni eseguite dal cliente.
Prezzi
Il modello e lo strumento Utilizzo del computer hanno gli stessi prezzi di Gemini e utilizzano gli stessi SKU. Per dividere i costi del modello e dello strumento di utilizzo del computer, utilizza etichette di metadati personalizzate. Per saperne di più sull'utilizzo delle etichette dei metadati personalizzati per il monitoraggio dei costi, consulta Etichette dei metadati personalizzati.