
處理時間序列資料
本文說明如何使用 SQL 函式支援時間序列分析。
簡介
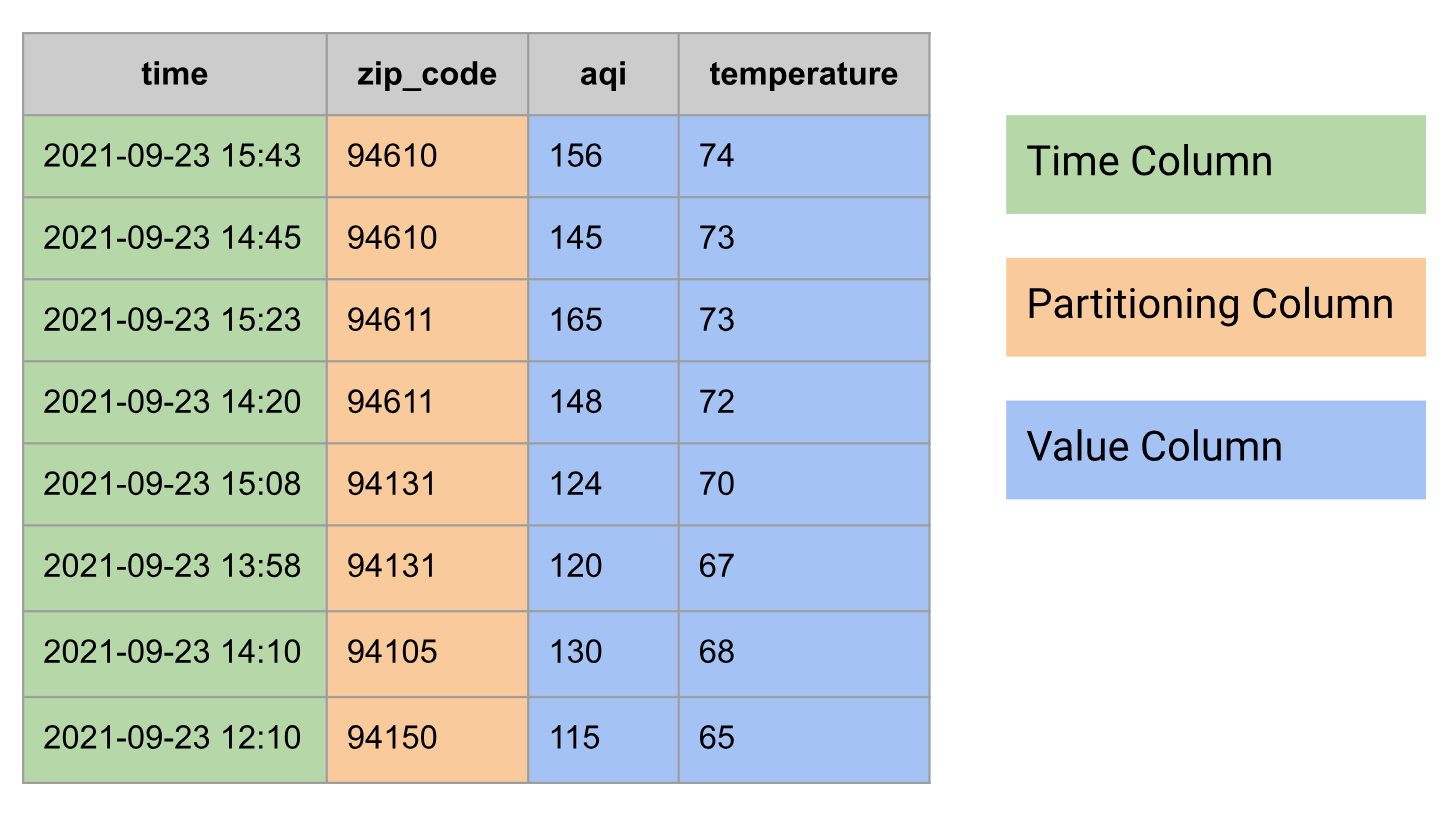
時間序列是一連串的資料點,每個資料點都包含時間和與該時間相關聯的值。通常時間序列也會有 ID, 用來為時間序列命名。
在關聯式資料庫中,時間序列會以資料表的形式建立模型,並包含下列資料欄群組:
- 時間欄
- 可能含有分割資料欄,例如郵遞區號
- 一或多個值資料欄,或結合多個值的
STRUCT類型,例如溫度和空氣品質指數
以下是時間序列資料的範例,以資料表形式呈現:
匯總時間序列
在時間序列分析中,時間匯總是指沿著時間軸執行的匯總作業。
您可以使用時間分組函式 (TIMESTAMP_BUCKET、DATE_BUCKET 和 DATETIME_BUCKET),在 BigQuery 中執行時間匯總作業。時間分組函式會將輸入的時間值對應至所屬的分組。
通常會執行時間匯總,將時間範圍內的多個資料點合併為單一資料點,並使用匯總函式,例如 AVG、MIN、MAX、COUNT 或 SUM。例如 15 分鐘的平均要求延遲時間、每日最低和最高溫度,以及每日計程車行程數。
如要執行本節中的查詢,請建立名為 mydataset.environmental_data_hourly 的資料表:
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 12:32:38', 38, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 13:29:59', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 14:31:22', 43, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 15:31:38', 42, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 15:09:19', 150, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 16:06:39', 151, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 17:08:01', 155, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 18:09:23', 154, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
從上述資料中,我們發現一個有趣的現象:測量是在任意時間範圍進行,這稱為未對齊的時間序列。匯總功能是校正時間序列的方法之一。
取得 3 小時平均值
下列查詢會計算每個郵遞區號的 3 小時平均空氣品質指數 (AQI) 和溫度。TIMESTAMP_BUCKET 函式會將每個時間值指派給特定日期,藉此執行時間彙整。
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 40 | 57 |
| 2020-09-08 15:00:00 | 60606 | 42 | 65 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 152 | 62 |
| 2020-09-08 18:00:00 | 94105 | 152 | 67 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
取得 3 小時的最低和最高值
在下列查詢中,您會計算每個郵遞區號的 3 小時最低和最高溫度:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
MIN(temperature) AS temperature_min,
MAX(temperature) AS temperature_max,
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----------------+-----------------+
| time | zip_code | temperature_min | temperature_max |
+---------------------+----------+-----------------+-----------------+
| 2020-09-08 00:00:00 | 60606 | 60 | 66 |
| 2020-09-08 03:00:00 | 60606 | 57 | 59 |
| 2020-09-08 06:00:00 | 60606 | 55 | 56 |
| 2020-09-08 09:00:00 | 60606 | 55 | 56 |
| 2020-09-08 12:00:00 | 60606 | 56 | 59 |
| 2020-09-08 15:00:00 | 60606 | 63 | 68 |
| 2020-09-08 18:00:00 | 60606 | 67 | 69 |
| 2020-09-08 21:00:00 | 60606 | 63 | 67 |
| 2020-09-08 00:00:00 | 94105 | 71 | 74 |
| 2020-09-08 03:00:00 | 94105 | 66 | 69 |
| 2020-09-08 06:00:00 | 94105 | 64 | 65 |
| 2020-09-08 09:00:00 | 94105 | 62 | 63 |
| 2020-09-08 12:00:00 | 94105 | 61 | 62 |
| 2020-09-08 15:00:00 | 94105 | 62 | 63 |
| 2020-09-08 18:00:00 | 94105 | 64 | 69 |
| 2020-09-08 21:00:00 | 94105 | 72 | 76 |
+---------------------+----------+-----------------+-----------------*/
透過自訂對齊方式取得 3 小時平均值
執行時間序列匯總時,您會隱性或顯性地使用特定時間序列視窗對齊方式。先前的查詢使用隱含對齊方式,因此產生的值區會從 00:00:00、03:00:00 和 06:00:00 等時間開始。如要在 TIMESTAMP_BUCKET 函式中明確設定這個對齊方式,請傳遞指定原點的選用引數。
在下列查詢中,來源設為 2020-01-01 02:00:00。這會變更對齊方式,並產生以 02:00:00、05:00:00 和 08:00:00 等時間為開頭的值區:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR, TIMESTAMP '2020-01-01 02:00:00') AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-07 23:00:00 | 60606 | 23 | 65 |
| 2020-09-08 02:00:00 | 60606 | 21 | 59 |
| 2020-09-08 05:00:00 | 60606 | 24 | 56 |
| 2020-09-08 08:00:00 | 60606 | 33 | 55 |
| 2020-09-08 11:00:00 | 60606 | 38 | 56 |
| 2020-09-08 14:00:00 | 60606 | 43 | 62 |
| 2020-09-08 17:00:00 | 60606 | 37 | 68 |
| 2020-09-08 20:00:00 | 60606 | 27 | 66 |
| 2020-09-08 23:00:00 | 60606 | 22 | 63 |
| 2020-09-07 23:00:00 | 94105 | 61 | 74 |
| 2020-09-08 02:00:00 | 94105 | 67 | 69 |
| 2020-09-08 05:00:00 | 94105 | 72 | 65 |
| 2020-09-08 08:00:00 | 94105 | 90 | 63 |
| 2020-09-08 11:00:00 | 94105 | 120 | 62 |
| 2020-09-08 14:00:00 | 94105 | 143 | 62 |
| 2020-09-08 17:00:00 | 94105 | 153 | 65 |
| 2020-09-08 20:00:00 | 94105 | 147 | 72 |
| 2020-09-08 23:00:00 | 94105 | 137 | 75 |
+---------------------+----------+-----+-------------*/
匯總時間序列並填補缺口
有時在匯總時間序列後,資料可能會出現缺口,需要填入一些值,才能進一步分析或呈現資料。用來填補這些缺漏的技術稱為「缺漏填補」。在 BigQuery 中,您可以使用 GAP_FILL 資料表函式填補時間序列資料中的間隙,並使用下列其中一種填補間隙的方法:
- NULL,也稱為常數
- LOCF (最後一次觀察結果延續)
- 線性:兩個相鄰資料點之間的線性插值
如要執行本節的查詢,請建立名為 mydataset.environmental_data_hourly_with_gaps 的資料表,該資料表會以先前使用的資料為基礎,但其中會有間隔。在實際情境中,資料可能會因短期氣象站故障而缺少資料點。
CREATE OR REPLACE TABLE mydataset.environmental_data_hourly_with_gaps AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<zip_code INT64, time TIMESTAMP, aqi INT64, temperature INT64>>[
STRUCT(60606, TIMESTAMP '2020-09-08 00:30:51', 22, 66),
STRUCT(60606, TIMESTAMP '2020-09-08 01:32:10', 23, 63),
STRUCT(60606, TIMESTAMP '2020-09-08 02:30:35', 22, 60),
STRUCT(60606, TIMESTAMP '2020-09-08 03:29:39', 21, 58),
STRUCT(60606, TIMESTAMP '2020-09-08 04:33:05', 21, 59),
STRUCT(60606, TIMESTAMP '2020-09-08 05:32:01', 21, 57),
STRUCT(60606, TIMESTAMP '2020-09-08 06:31:14', 22, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 07:31:06', 28, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 08:29:59', 30, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 09:29:34', 31, 55),
STRUCT(60606, TIMESTAMP '2020-09-08 10:31:24', 38, 56),
STRUCT(60606, TIMESTAMP '2020-09-08 11:31:24', 38, 56),
-- No data points between hours 12 and 15.
STRUCT(60606, TIMESTAMP '2020-09-08 16:34:22', 43, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 17:33:23', 42, 68),
STRUCT(60606, TIMESTAMP '2020-09-08 18:28:47', 36, 69),
STRUCT(60606, TIMESTAMP '2020-09-08 19:30:28', 34, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 20:30:53', 29, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 21:32:28', 27, 67),
STRUCT(60606, TIMESTAMP '2020-09-08 22:31:45', 25, 65),
STRUCT(60606, TIMESTAMP '2020-09-08 23:31:02', 22, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 00:07:11', 60, 74),
STRUCT(94105, TIMESTAMP '2020-09-08 01:07:24', 61, 73),
STRUCT(94105, TIMESTAMP '2020-09-08 02:08:07', 60, 71),
STRUCT(94105, TIMESTAMP '2020-09-08 03:11:05', 69, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 04:07:26', 72, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 05:08:11', 70, 66),
STRUCT(94105, TIMESTAMP '2020-09-08 06:07:30', 68, 65),
STRUCT(94105, TIMESTAMP '2020-09-08 07:07:10', 77, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 08:06:35', 81, 64),
STRUCT(94105, TIMESTAMP '2020-09-08 09:10:18', 82, 63),
STRUCT(94105, TIMESTAMP '2020-09-08 10:08:10', 107, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 11:08:01', 115, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 12:07:39', 120, 62),
STRUCT(94105, TIMESTAMP '2020-09-08 13:06:03', 125, 61),
STRUCT(94105, TIMESTAMP '2020-09-08 14:08:37', 129, 62),
-- No data points between hours 15 and 18.
STRUCT(94105, TIMESTAMP '2020-09-08 19:08:43', 151, 67),
STRUCT(94105, TIMESTAMP '2020-09-08 20:07:19', 150, 69),
STRUCT(94105, TIMESTAMP '2020-09-08 21:07:37', 148, 72),
STRUCT(94105, TIMESTAMP '2020-09-08 22:08:01', 143, 76),
STRUCT(94105, TIMESTAMP '2020-09-08 23:08:41', 137, 75)
]);
取得 3 小時的平均值 (包括間隔)
下列查詢會計算每個郵遞區號的 3 小時平均空氣品質指數和溫度:
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
請注意,輸出內容在特定時間間隔會出現間隙。舉例來說,郵遞區號 60606 的時間序列在 2020-09-08 12:00:00 沒有資料點,郵遞區號 94105 的時間序列在 2020-09-08 15:00:00 沒有資料點。
取得 3 小時平均值 (填補缺口)
使用上一節的查詢,並新增 GAP_FILL 函式來填補間隙:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code']
)
ORDER BY zip_code, time;
/*---------------------+----------+------+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+------+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | NULL | NULL |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | NULL | NULL |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+------+-------------*/
輸出資料表現在會在郵遞區號 60606 的 2020-09-08 12:00:00 和郵遞區號 94105 的 2020-09-08 15:00:00 遺漏資料列,並在對應的指標資料欄中顯示 NULL 值。由於您未指定任何填補間隙的方法,GAP_FILL 使用了預設的填補間隙方法 NULL。
使用線性插補和 LOCF 插補填補缺漏資料
在下列查詢中,GAP_FILL 函式會搭配 LOCF 缺口填補方法,用於 aqi 資料欄,並搭配線性內插法,用於 temperature 資料欄:
WITH aggregated_3_hr AS (
SELECT
TIMESTAMP_BUCKET(time, INTERVAL 3 HOUR) AS time,
zip_code,
CAST(AVG(aqi) AS INT64) AS aqi,
CAST(AVG(temperature) AS INT64) AS temperature
FROM mydataset.environmental_data_hourly_with_gaps
GROUP BY zip_code, time)
SELECT *
FROM GAP_FILL(
TABLE aggregated_3_hr,
ts_column => 'time',
bucket_width => INTERVAL 3 HOUR,
partitioning_columns => ['zip_code'],
value_columns => [
('aqi', 'locf'),
('temperature', 'linear')
]
)
ORDER BY zip_code, time;
/*---------------------+----------+-----+-------------+
| time | zip_code | aqi | temperature |
+---------------------+----------+-----+-------------+
| 2020-09-08 00:00:00 | 60606 | 22 | 63 |
| 2020-09-08 03:00:00 | 60606 | 21 | 58 |
| 2020-09-08 06:00:00 | 60606 | 27 | 55 |
| 2020-09-08 09:00:00 | 60606 | 36 | 56 |
| 2020-09-08 12:00:00 | 60606 | 36 | 62 |
| 2020-09-08 15:00:00 | 60606 | 43 | 67 |
| 2020-09-08 18:00:00 | 60606 | 33 | 68 |
| 2020-09-08 21:00:00 | 60606 | 25 | 65 |
| 2020-09-08 00:00:00 | 94105 | 60 | 73 |
| 2020-09-08 03:00:00 | 94105 | 70 | 67 |
| 2020-09-08 06:00:00 | 94105 | 75 | 64 |
| 2020-09-08 09:00:00 | 94105 | 101 | 62 |
| 2020-09-08 12:00:00 | 94105 | 125 | 62 |
| 2020-09-08 15:00:00 | 94105 | 125 | 65 |
| 2020-09-08 18:00:00 | 94105 | 151 | 68 |
| 2020-09-08 21:00:00 | 94105 | 143 | 74 |
+---------------------+----------+-----+-------------*/
在這項查詢中,第一個填補間隙的資料列具有 aqi 值 36,這是取自這個時間序列 (郵遞區號 60606) 在 2020-09-08 09:00:00 的前一個資料點。temperature 值 62 是資料點 2020-09-08 09:00:00 和 2020-09-08 15:00:00 之間的線性插補結果。另一個遺漏的資料列也是以類似方式建立 - aqi
值 125 是從這個時間序列的前一個資料點 (郵遞區號 94105) 延續而來,而溫度值 65 則是前一個和下一個可用資料點之間的線性插補結果。
對齊時間序列並填補間隙
時間序列可以對齊或不對齊。只有在資料點以固定間隔出現時,時間序列才會對齊。
在現實世界中,時間序列很少在收集時對齊,通常需要進一步處理才能對齊。
舉例來說,假設 IoT 裝置每分鐘都會將指標傳送至集中式收集器。要求裝置在完全相同的時間點傳送指標並不合理。通常每部裝置會以相同頻率 (週期) 傳送指標,但時間偏移 (對齊) 不同。下圖說明瞭這個範例。你可以看到每個裝置每隔一分鐘傳送資料,但有些資料會遺失 (裝置 3 位於 9:36:39),有些資料則會延遲傳送 (裝置 1 位於 9:37:28)。

您可以對未對齊的資料執行時間序列對齊,方法是使用時間匯總。如果您想變更時間序列的取樣週期,例如從原始的 1 分鐘取樣週期變更為 15 分鐘週期,這項功能就非常實用。您可以對齊資料,以利後續的時間序列處理作業,例如合併時間序列資料,或用於顯示用途 (例如繪製圖表)。
您可以使用 GAP_FILL 表格函式搭配 LOCF 或線性間隙填補方法,執行時間序列對齊作業。概念是搭配選取的輸出週期和對齊方式 (由選用的原點引數控制),使用 GAP_FILL。這項作業的結果是含有校正時間序列的表格,其中每個資料點的值都是從輸入時間序列衍生而來,並採用適用於該特定值資料欄的填補間隙方法 (LOCF 或線性)。
建立類似上圖的 mydataset.device_data 表格:
CREATE OR REPLACE TABLE mydataset.device_data AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<device_id INT64, time TIMESTAMP, signal INT64, state STRING>>[
STRUCT(2, TIMESTAMP '2023-11-01 09:35:07', 87, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:35:26', 82, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:35:39', 74, 'INACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:36:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:36:26', 82, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:37:07', 88, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:37:28', 80, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:37:39', 77, 'ACTIVE'),
STRUCT(2, TIMESTAMP '2023-11-01 09:38:07', 86, 'ACTIVE'),
STRUCT(1, TIMESTAMP '2023-11-01 09:38:26', 81, 'ACTIVE'),
STRUCT(3, TIMESTAMP '2023-11-01 09:38:39', 77, 'ACTIVE')
]);
以下是依 time 和 device_id 資料欄排序的實際資料:
SELECT * FROM mydataset.device_data ORDER BY time, device_id;
/*-----------+---------------------+--------+----------+
| device_id | time | signal | state |
+-----------+---------------------+--------+----------+
| 2 | 2023-11-01 09:35:07 | 87 | ACTIVE |
| 1 | 2023-11-01 09:35:26 | 82 | ACTIVE |
| 3 | 2023-11-01 09:35:39 | 74 | INACTIVE |
| 2 | 2023-11-01 09:36:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:36:26 | 82 | ACTIVE |
| 2 | 2023-11-01 09:37:07 | 88 | ACTIVE |
| 1 | 2023-11-01 09:37:28 | 80 | ACTIVE |
| 3 | 2023-11-01 09:37:39 | 77 | ACTIVE |
| 2 | 2023-11-01 09:38:07 | 86 | ACTIVE |
| 1 | 2023-11-01 09:38:26 | 81 | ACTIVE |
| 3 | 2023-11-01 09:38:39 | 77 | ACTIVE |
+-----------+---------------------+--------+----------*/
資料表包含每個裝置的時間序列,以及兩個指標資料欄:
signal- 裝置在取樣時觀察到的信號強度,以介於0和100之間的整數值表示。state- 取樣時的裝置狀態,以任意形式的字串表示。
在下列查詢中,GAP_FILL 函式用於以 1 分鐘間隔對齊時間序列。請注意,系統如何使用線性內插法計算 signal 資料欄的值,以及使用 LOCF 計算 state 資料欄的值。以這個範例資料來說,線性插補是計算輸出值的合適選擇。
SELECT *
FROM GAP_FILL(
TABLE mydataset.device_data,
ts_column => 'time',
bucket_width => INTERVAL 1 MINUTE,
partitioning_columns => ['device_id'],
value_columns => [
('signal', 'linear'),
('state', 'locf')
]
)
ORDER BY time, device_id;
/*---------------------+-----------+--------+----------+
| time | device_id | signal | state |
+---------------------+-----------+--------+----------+
| 2023-11-01 09:36:00 | 1 | 82 | ACTIVE |
| 2023-11-01 09:36:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:36:00 | 3 | 75 | INACTIVE |
| 2023-11-01 09:37:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:37:00 | 2 | 88 | ACTIVE |
| 2023-11-01 09:37:00 | 3 | 76 | INACTIVE |
| 2023-11-01 09:38:00 | 1 | 81 | ACTIVE |
| 2023-11-01 09:38:00 | 2 | 86 | ACTIVE |
| 2023-11-01 09:38:00 | 3 | 77 | ACTIVE |
+---------------------+-----------+--------+----------*/
輸出表格會包含每個裝置和值資料欄 (signal 和 state) 的對齊時間序列,並使用函式呼叫中指定的間隙填補方法計算。
彙整時間序列資料
您可以使用視窗化聯結或 AS OF 聯結,聯結時間序列資料。
視窗式聯結
有時您需要彙整兩個以上的資料表,並使用時間序列資料。請參考下列兩個資料表:
- ,內含每個感應器每 15 秒回報的溫度資料。
mydataset.sensor_temperatures mydataset.sensor_fuel_rates,內含每 15 秒由各感應器測量的燃料消耗率。
如要建立這些資料表,請執行下列查詢:
CREATE OR REPLACE TABLE mydataset.sensor_temperatures AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, temp FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:00.063', 37.1),
(1, TIMESTAMP '2020-01-01 12:00:15.024', 37.2),
(1, TIMESTAMP '2020-01-01 12:00:30.032', 37.3),
(2, TIMESTAMP '2020-01-01 12:00:01.001', 38.1),
(2, TIMESTAMP '2020-01-01 12:00:15.082', 38.2),
(2, TIMESTAMP '2020-01-01 12:00:31.009', 38.3)
]);
CREATE OR REPLACE TABLE mydataset.sensor_fuel_rates AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, rate FLOAT64>>[
(1, TIMESTAMP '2020-01-01 12:00:11.016', 10.1),
(1, TIMESTAMP '2020-01-01 12:00:26.015', 10.2),
(1, TIMESTAMP '2020-01-01 12:00:41.014', 10.3),
(2, TIMESTAMP '2020-01-01 12:00:08.099', 11.1),
(2, TIMESTAMP '2020-01-01 12:00:23.087', 11.2),
(2, TIMESTAMP '2020-01-01 12:00:38.077', 11.3)
]);
以下是資料表中的實際資料:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 |
+-----------+---------------------+------*/
SELECT * FROM mydataset.sensor_fuel_rates ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | rate |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------*/
如要查看每個感應器回報溫度時的油耗率,可以彙整這兩個時間序列。
雖然這兩個時間序列中的資料未對齊,但取樣間隔相同 (15 秒),因此很適合用於時間區間聯結。使用時間區間函式,對齊做為聯結鍵的時間戳記。
下列查詢說明如何使用 TIMESTAMP_BUCKET 函式,將每個時間戳記指派給 15 秒的視窗:
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_temperatures
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | temp | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
SELECT *, TIMESTAMP_BUCKET(ts, INTERVAL 15 SECOND) ts_window
FROM mydataset.sensor_fuel_rates
ORDER BY sensor_id, ts;
/*-----------+---------------------+------+---------------------+
| sensor_id | ts | rate | ts_window |
+-----------+---------------------+------+---------------------+
| 1 | 2020-01-01 12:00:11 | 10.1 | 2020-01-01 12:00:00 |
| 1 | 2020-01-01 12:00:26 | 10.2 | 2020-01-01 12:00:15 |
| 1 | 2020-01-01 12:00:41 | 10.3 | 2020-01-01 12:00:30 |
| 2 | 2020-01-01 12:00:08 | 11.1 | 2020-01-01 12:00:00 |
| 2 | 2020-01-01 12:00:23 | 11.2 | 2020-01-01 12:00:15 |
| 2 | 2020-01-01 12:00:38 | 11.3 | 2020-01-01 12:00:30 |
+-----------+---------------------+------+---------------------*/
您可以運用這個概念,將燃料消耗率資料與每個感應器回報的溫度資料合併:
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.ts AS rate_ts,
t2.rate AS rate
FROM mydataset.sensor_temperatures t1
LEFT JOIN mydataset.sensor_fuel_rates t2
ON TIMESTAMP_BUCKET(t1.ts, INTERVAL 15 SECOND) =
TIMESTAMP_BUCKET(t2.ts, INTERVAL 15 SECOND)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+---------------------+------+
| sensor_id | temp_ts | temp | rate_ts | rate |
+-----------+---------------------+------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 | 2020-01-01 12:00:11 | 10.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 | 2020-01-01 12:00:26 | 10.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 | 2020-01-01 12:00:41 | 10.3 |
| 2 | 2020-01-01 12:00:01 | 38.1 | 2020-01-01 12:00:08 | 11.1 |
| 2 | 2020-01-01 12:00:15 | 38.2 | 2020-01-01 12:00:23 | 11.2 |
| 2 | 2020-01-01 12:00:31 | 38.3 | 2020-01-01 12:00:38 | 11.3 |
+-----------+---------------------+------+---------------------+------*/
AS OF 加入
在本節中,請使用 mydataset.sensor_temperatures 資料表,並建立新資料表 mydataset.sensor_location。
mydataset.sensor_temperatures 資料表包含不同感應器每 15 秒回報一次的溫度資料:
SELECT * FROM mydataset.sensor_temperatures ORDER BY sensor_id, ts;
/*-----------+---------------------+------+
| sensor_id | ts | temp |
+-----------+---------------------+------+
| 1 | 2020-01-01 12:00:00 | 37.1 |
| 1 | 2020-01-01 12:00:15 | 37.2 |
| 1 | 2020-01-01 12:00:30 | 37.3 |
| 2 | 2020-01-01 12:00:45 | 38.1 |
| 2 | 2020-01-01 12:01:01 | 38.2 |
| 2 | 2020-01-01 12:01:15 | 38.3 |
+-----------+---------------------+------*/
如要建立 mydataset.sensor_location,請執行下列查詢:
CREATE OR REPLACE TABLE mydataset.sensor_locations AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, ts TIMESTAMP, location GEOGRAPHY>>[
(1, TIMESTAMP '2020-01-01 11:59:47.063', ST_GEOGPOINT(-122.022, 37.406)),
(1, TIMESTAMP '2020-01-01 12:00:08.185', ST_GEOGPOINT(-122.021, 37.407)),
(1, TIMESTAMP '2020-01-01 12:00:28.032', ST_GEOGPOINT(-122.020, 37.405)),
(2, TIMESTAMP '2020-01-01 07:28:41.239', ST_GEOGPOINT(-122.390, 37.790))
]);
/*-----------+---------------------+------------------------+
| sensor_id | ts | location |
+-----------+---------------------+------------------------+
| 1 | 2020-01-01 11:59:47 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:08 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:28 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 07:28:41 | POINT(-122.39 37.79) |
+-----------+---------------------+------------------------*/
現在,請將 mydataset.sensor_temperatures 的資料與 mydataset.sensor_location 的資料合併。
在這種情況下,由於溫度資料和位置資料並非以相同間隔回報,因此您無法使用視窗聯結。
在 BigQuery 中,您可以將時間戳記資料轉換為範圍,並使用 RANGE 資料類型。這個範圍代表資料列的時間效期,提供資料列的有效開始和結束時間。
使用 LEAD window 函式,找出時間序列中相對於目前資料點的下一個資料點,也就是目前資料列時間有效性的結束界線。下列查詢會示範這項做法,將位置資料轉換為有效範圍:
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT * FROM locations_ranges ORDER BY sensor_id, ts_range;
/*-----------+--------------------------------------------+------------------------+
| sensor_id | ts_range | location |
+-----------+--------------------------------------------+------------------------+
| 1 | [2020-01-01 11:59:47, 2020-01-01 12:00:08) | POINT(-122.022 37.406) |
| 1 | [2020-01-01 12:00:08, 2020-01-01 12:00:28) | POINT(-122.021 37.407) |
| 1 | [2020-01-01 12:00:28, UNBOUNDED) | POINT(-122.02 37.405) |
| 2 | [2020-01-01 07:28:41, UNBOUNDED) | POINT(-122.39 37.79) |
+-----------+--------------------------------------------+------------------------*/
現在您可以將溫度資料 (左側) 與位置資料 (右側) 彙整在一起:
WITH locations_ranges AS (
SELECT
sensor_id,
RANGE(ts, LEAD(ts) OVER (PARTITION BY sensor_id ORDER BY ts ASC)) AS ts_range,
location
FROM mydataset.sensor_locations
)
SELECT
t1.sensor_id AS sensor_id,
t1.ts AS temp_ts,
t1.temp AS temp,
t2.location AS location
FROM mydataset.sensor_temperatures t1
LEFT JOIN locations_ranges t2
ON RANGE_CONTAINS(t2.ts_range, t1.ts)
AND t1.sensor_id = t2.sensor_id
ORDER BY sensor_id, temp_ts;
/*-----------+---------------------+------+------------------------+
| sensor_id | temp_ts | temp | location |
+-----------+---------------------+------+------------------------+
| 1 | 2020-01-01 12:00:00 | 37.1 | POINT(-122.022 37.406) |
| 1 | 2020-01-01 12:00:15 | 37.2 | POINT(-122.021 37.407) |
| 1 | 2020-01-01 12:00:30 | 37.3 | POINT(-122.02 37.405) |
| 2 | 2020-01-01 12:00:01 | 38.1 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:15 | 38.2 | POINT(-122.39 37.79) |
| 2 | 2020-01-01 12:00:31 | 38.3 | POINT(-122.39 37.79) |
+-----------+---------------------+------+------------------------*/
合併及分割範圍資料
在本節中,請合併範圍重疊的範圍資料,並將範圍資料分割成較小的範圍。
合併範圍資料
含有範圍值的表格可能會有重疊的範圍。在下列查詢中,時間範圍會以約 5 分鐘的間隔擷取感應器狀態:
CREATE OR REPLACE TABLE mydataset.sensor_metrics AS
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATETIME>, flow INT64, spins INT64>>[
(1, RANGE<DATETIME> "[2020-01-01 12:00:01, 2020-01-01 12:05:23)", 10, 1),
(1, RANGE<DATETIME> "[2020-01-01 12:05:12, 2020-01-01 12:10:46)", 10, 20),
(1, RANGE<DATETIME> "[2020-01-01 12:10:27, 2020-01-01 12:15:56)", 11, 4),
(1, RANGE<DATETIME> "[2020-01-01 12:16:00, 2020-01-01 12:20:58)", 11, 9),
(1, RANGE<DATETIME> "[2020-01-01 12:20:33, 2020-01-01 12:25:08)", 11, 8),
(2, RANGE<DATETIME> "[2020-01-01 12:00:19, 2020-01-01 12:05:08)", 21, 31),
(2, RANGE<DATETIME> "[2020-01-01 12:05:08, 2020-01-01 12:10:30)", 21, 2),
(2, RANGE<DATETIME> "[2020-01-01 12:10:22, 2020-01-01 12:15:42)", 21, 10)
]);
下表中的查詢會顯示多個重疊範圍:
SELECT * FROM mydataset.sensor_metrics;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:05:23) | 10 | 1 |
| 1 | [2020-01-01 12:05:12, 2020-01-01 12:10:46) | 10 | 20 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:20:58) | 11 | 9 |
| 1 | [2020-01-01 12:20:33, 2020-01-01 12:25:08) | 11 | 8 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:10:30) | 21 | 2 |
| 2 | [2020-01-01 12:10:22, 2020-01-01 12:15:42) | 21 | 10 |
+-----------+--------------------------------------------+------+-------*/
在部分重疊範圍中,flow 欄的值相同。
舉例來說,第 1 列和第 2 列重疊,且讀數相同 (flow)。您可以合併這兩列,減少表格中的列數。您可以使用 RANGE_SESSIONIZE 資料表函式找出與每個資料列重疊的範圍,並提供額外的 session_range 資料欄,其中包含所有重疊範圍的聯集。如要顯示每列的會期範圍,請執行下列查詢:
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
# Input data.
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
# Range column.
"duration",
# Partitioning columns. Ranges are sessionized only within these partitions.
["sensor_id", "flow"],
# Sessionize mode.
"OVERLAPS")
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
請注意,如果 sensor_id 的值為 2,則第一列的結束邊界與第二列的開始邊界具有相同的日期時間值。不過,由於結束界線是互斥的,因此不會重疊 (只會相遇),因此不在相同的工作階段範圍內。如要將這兩列放在相同的工作階段範圍,請使用 MEETS 工作階段化模式。
如要合併範圍,請依 session_range 和分割欄 (sensor_id 和 flow) 將結果分組:
SELECT sensor_id, session_range, flow
FROM RANGE_SESSIONIZE(
(SELECT sensor_id, duration, flow FROM mydataset.sensor_metrics),
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+
| sensor_id | session_range | flow |
+-----------+--------------------------------------------+------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 |
+-----------+--------------------------------------------+------*/
最後,使用 SUM 彙整工作階段資料,加入 spins 資料欄。
SELECT sensor_id, session_range, flow, SUM(spins) as spins
FROM RANGE_SESSIONIZE(
TABLE mydataset.sensor_metrics,
"duration",
["sensor_id", "flow"],
"OVERLAPS")
GROUP BY sensor_id, session_range, flow
ORDER BY sensor_id, session_range;
/*-----------+--------------------------------------------+------+-------+
| sensor_id | session_range | flow | spins |
+-----------+--------------------------------------------+------+-------+
| 1 | [2020-01-01 12:00:01, 2020-01-01 12:10:46) | 10 | 21 |
| 1 | [2020-01-01 12:10:27, 2020-01-01 12:15:56) | 11 | 4 |
| 1 | [2020-01-01 12:16:00, 2020-01-01 12:25:08) | 11 | 17 |
| 2 | [2020-01-01 12:00:19, 2020-01-01 12:05:08) | 21 | 31 |
| 2 | [2020-01-01 12:05:08, 2020-01-01 12:15:42) | 21 | 12 |
+-----------+--------------------------------------------+------+-------*/
分割範圍資料
您也可以將範圍分割成較小的範圍。在本範例中,請使用下列含有範圍資料的表格:
/*-----------+--------------------------+------+-------+
| sensor_id | duration | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
現在,請將原始範圍分成 3 個月間隔:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data, UNNEST(GENERATE_RANGE_ARRAY(duration, INTERVAL 3 MONTH)) AS expanded_range;
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2020-12-31) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2021-12-31) | 11 | 4 |
| 2 | [2020-04-15, 2020-07-15) | 21 | 31 |
| 2 | [2020-07-15, 2020-10-15) | 21 | 31 |
| 2 | [2020-10-15, 2021-01-15) | 21 | 31 |
| 2 | [2021-01-15, 2021-04-15) | 21 | 31 |
| 2 | [2021-04-15, 2021-07-15) | 21 | 12 |
| 2 | [2021-07-15, 2021-10-15) | 21 | 12 |
| 2 | [2021-10-15, 2022-01-15) | 21 | 12 |
| 2 | [2022-01-15, 2022-04-15) | 21 | 12 |
+-----------+--------------------------+------+-------*/
在先前的查詢中,每個原始範圍都細分成較小的範圍,寬度設為 INTERVAL 3 MONTH。不過,這 3 個月的範圍並未對齊共同的起點。如要將這些範圍對齊至共同原點 2020-01-01,請執行下列查詢:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_OVERLAPS(duration, expanded_range);
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-04-01, 2020-07-01) | 21 | 31 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 12 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
在先前的查詢中,範圍為 [2020-04-15, 2021-04-15) 的資料列會分割成 5 個範圍,從 [2020-04-01, 2020-07-01) 範圍開始。請注意,為了與通用來源對齊,起始邊界現在會超出原始起始邊界。如果不想讓開始界線超出原始開始界線,可以限制 JOIN 條件:
WITH sensor_data AS (
SELECT * FROM UNNEST(
ARRAY<STRUCT<sensor_id INT64, duration RANGE<DATE>, flow INT64, spins INT64>>[
(1, RANGE<DATE> "[2020-01-01, 2020-12-31)", 10, 21),
(1, RANGE<DATE> "[2021-01-01, 2021-12-31)", 11, 4),
(2, RANGE<DATE> "[2020-04-15, 2021-04-15)", 21, 31),
(2, RANGE<DATE> "[2021-04-15, 2022-04-15)", 21, 12)
])
)
SELECT sensor_id, expanded_range, flow, spins
FROM sensor_data
JOIN UNNEST(GENERATE_RANGE_ARRAY(RANGE<DATE> "[2020-01-01, 2022-12-31)", INTERVAL 3 MONTH)) AS expanded_range
ON RANGE_CONTAINS(duration, RANGE_START(expanded_range));
/*-----------+--------------------------+------+-------+
| sensor_id | expanded_range | flow | spins |
+-----------+--------------------------+------+-------+
| 1 | [2020-01-01, 2020-04-01) | 10 | 21 |
| 1 | [2020-04-01, 2020-07-01) | 10 | 21 |
| 1 | [2020-07-01, 2020-10-01) | 10 | 21 |
| 1 | [2020-10-01, 2021-01-01) | 10 | 21 |
| 1 | [2021-01-01, 2021-04-01) | 11 | 4 |
| 1 | [2021-04-01, 2021-07-01) | 11 | 4 |
| 1 | [2021-07-01, 2021-10-01) | 11 | 4 |
| 1 | [2021-10-01, 2022-01-01) | 11 | 4 |
| 2 | [2020-07-01, 2020-10-01) | 21 | 31 |
| 2 | [2020-10-01, 2021-01-01) | 21 | 31 |
| 2 | [2021-01-01, 2021-04-01) | 21 | 31 |
| 2 | [2021-04-01, 2021-07-01) | 21 | 31 |
| 2 | [2021-07-01, 2021-10-01) | 21 | 12 |
| 2 | [2021-10-01, 2022-01-01) | 21 | 12 |
| 2 | [2022-01-01, 2022-04-01) | 21 | 12 |
| 2 | [2022-04-01, 2022-07-01) | 21 | 12 |
+-----------+--------------------------+------+-------*/
您現在會看到範圍 [2020-04-15, 2021-04-15) 分割成 4 個範圍,從範圍 [2020-07-01, 2020-10-01) 開始。
儲存資料的最佳做法
儲存時間序列資料時,請務必考量用於儲存資料的資料表查詢模式。一般來說,查詢時間序列資料時,您可以篩選特定時間範圍的資料。
為最佳化這些使用模式,建議將時間序列資料儲存在分區資料表中,並依時間資料欄或擷取時間將資料分區。這項做法可讓 BigQuery 刪除不含查詢資料的分區,因此能大幅提升時間序列資料的查詢時間效能。
您可以對時間、範圍或其中一個分割資料欄啟用分群功能,進一步提升查詢時間效能。