
הרצת קוד PySpark ב-notebooks של BigQuery Studio
במאמר הזה מוסבר איך להריץ קוד PySpark ב-Notebook של Python ב-BigQuery.
לפני שמתחילים
אם עדיין לא עשיתם זאת, יוצרים Google Cloud פרויקט וקטגוריה ב-Cloud Storage.
הגדרת הפרויקט
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Enable the Managed Service for Apache Spark, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Enable the Managed Service for Apache Spark, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
יוצרים קטגוריה של Cloud Storage בפרויקט אם אין לכם קטגוריה שתוכלו להשתמש בה.
הגדרת ה-Notebook
- פרטי כניסה של מחברת: כברירת מחדל, בסשן של המחברת נעשה שימוש בפרטי הכניסה של המשתמש. לחלופין, אפשר להשתמש בפרטי הכניסה של חשבון שירות של סשן.
- פרטי משתמש: לחשבון המשתמש שלכם צריכים להיות מוקצים התפקידים הבאים של ניהול זהויות והרשאות גישה (IAM):
- עורך (
roles/dataproc.editorתפקיד) ב-Managed Service for Apache Spark - BigQuery Studio User (תפקיד
roles/bigquery.studioUser) - התפקיד משתמש בחשבון שירות (roles/iam.serviceAccountUser) בחשבון השירות של הסשן.
התפקיד הזה מכיל את ההרשאה הנדרשת
iam.serviceAccounts.actAsלהתחזות לחשבון השירות.
- עורך (
- פרטי כניסה של חשבון שירות: אם רוצים לציין פרטי כניסה של חשבון שירות במקום פרטי כניסה של משתמש להפעלת מחברת, לחשבון השירות של הסשן צריכים להיות התפקידים הבאים:
- פרטי משתמש: לחשבון המשתמש שלכם צריכים להיות מוקצים התפקידים הבאים של ניהול זהויות והרשאות גישה (IAM):
- זמן ריצה של מחברת: המחברת משתמשת בזמן ריצה של Gemini Enterprise Agent Platform כברירת מחדל, אלא אם בוחרים זמן ריצה אחר. אם רוצים להגדיר סביבת זמן ריצה משלכם, צריך ליצור אותה מהדף Runtimes במסוף Google Cloud . הערה: כשמשתמשים בספריית NumPy, צריך להשתמש בגרסה 1.26 של NumPy, שנתמכת על ידי Spark 3.5, בזמן הריצה של המחברת.
- פרטי כניסה של מחברת: כברירת מחדל, בסשן של המחברת נעשה שימוש בפרטי הכניסה של המשתמש. לחלופין, אפשר להשתמש בפרטי הכניסה של חשבון שירות של סשן.
תמחור
מידע על תמחור זמין במאמר בנושא תמחור של זמן ריצה של מחברת ב-BigQuery.
פתיחת מחברת Python ב-BigQuery Studio
במסוף Google Cloud , עוברים לדף BigQuery.
בסרגל הכרטיסיות של חלונית הפרטים, לוחצים על החץ לצד הסימן + ואז על מחברת.
יצירת סשן Spark בפריט Notebook ב-BigQuery Studio
אתם יכולים להשתמש ב-Notebook של Python ב-BigQuery Studio כדי ליצור סשן אינטראקטיבי של Spark Connect. לכל מחברת BigQuery Studio אפשר לשייך רק סשן Spark פעיל אחד.
אפשר ליצור סשן Spark ב-Notebook של Python ב-BigQuery Studio באחת מהדרכים הבאות:
- להגדיר וליצור סשן יחיד בנוטבוק.
- מגדירים סשן Spark בתבנית של סשן אינטראקטיבי, ואז משתמשים בתבנית כדי להגדיר וליצור סשן במחברת.
BigQuery מספק תכונה
Query using Sparkשעוזרת לכם להתחיל לכתוב קוד לסשן מבוסס-תבנית, כמו שמוסבר בכרטיסייה Templated Spark session.
סשן יחיד
כדי ליצור סשן Spark בנוטבוק חדש:
בסרגל הכרטיסיות של חלונית העריכה, לוחצים על החץ לתפריט הנפתח לצד הסימן + ואז לוחצים על Notebook.
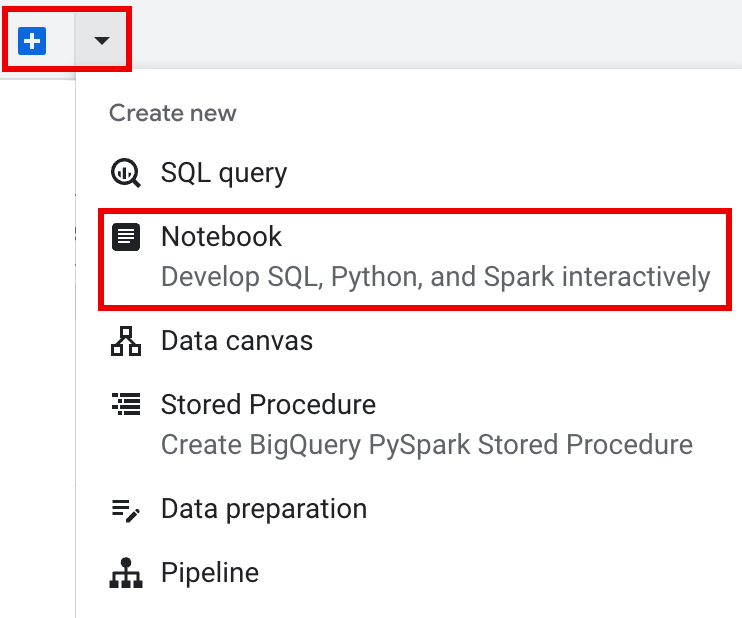
מעתיקים ומריצים את הקוד הבא בתא של מחברת כדי להגדיר וליצור סשן Spark בסיסי.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
import pyspark.sql.functions as f
session = Session()
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate()
)
מחליפים את מה שכתוב בשדות הבאים:
- APP_NAME: שם אופציונלי לסשן.
- הגדרות אופציונליות של סשנים: אתם יכולים להוסיף הגדרות של Managed Service for Apache Spark API
Sessionכדי להתאים אישית את הסשן. לדוגמה:RuntimeConfig: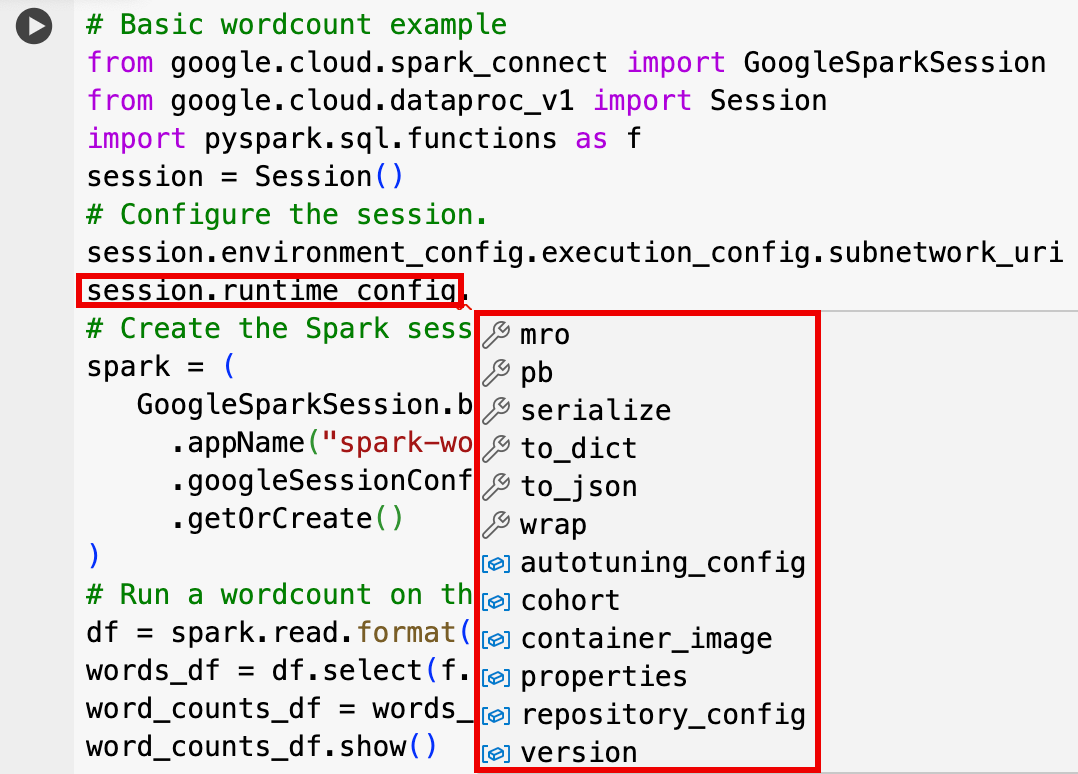
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: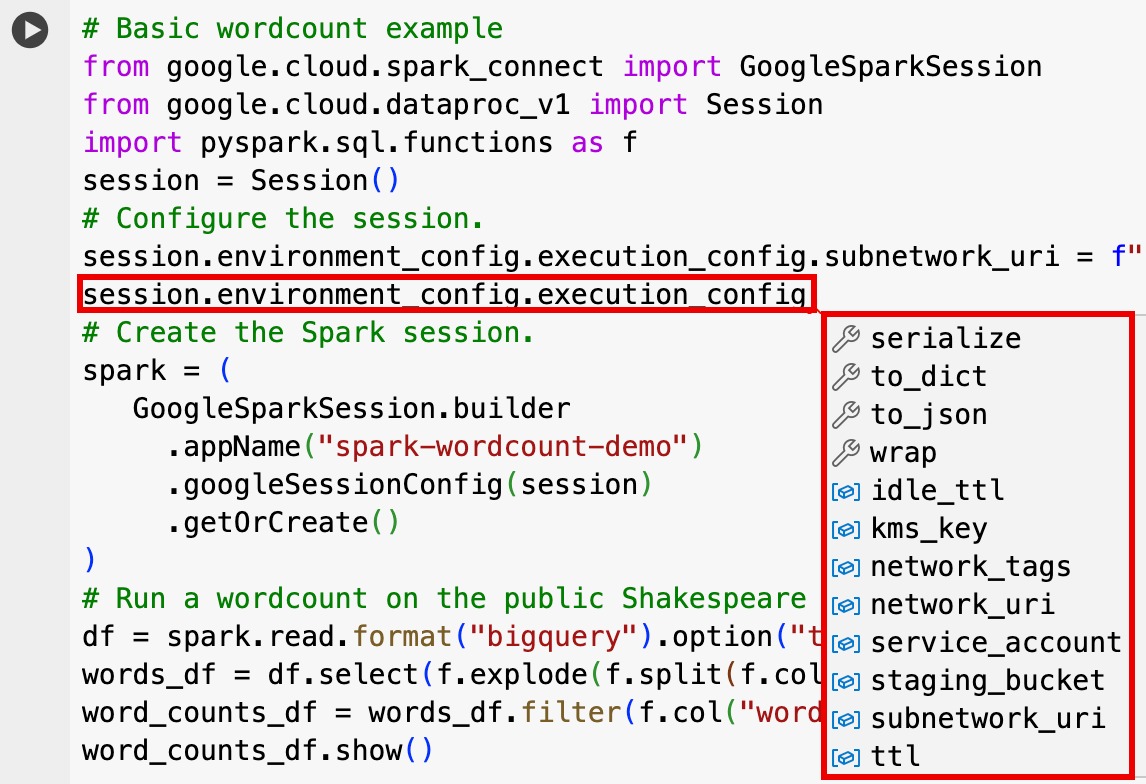
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
סשן Spark עם תבנית
אפשר להזין ולהריץ את הקוד בתא של מחברת כדי ליצור סשן Spark על סמך תבנית סשן קיימת.
כל הגדרות התצורה של session שאתם מציינים בקוד של המחברת יחליפו את אותן הגדרות שמוגדרות בתבנית הסשן.
כדי להתחיל במהירות, משתמשים בתבנית Query using Spark כדי לאכלס מראש את המחברת בקוד של תבנית הפעלה של Spark:
- בסרגל הכרטיסיות של חלונית העריכה, לוחצים על החץ לתפריט הנפתח לצד הסימן + ואז לוחצים על Notebook.
- בקטע Start with a template (התחלה עם תבנית), לוחצים על Query using Spark (שאילתה באמצעות Spark) ואז על Use template (שימוש בתבנית) כדי להוסיף את הקוד למחברת.
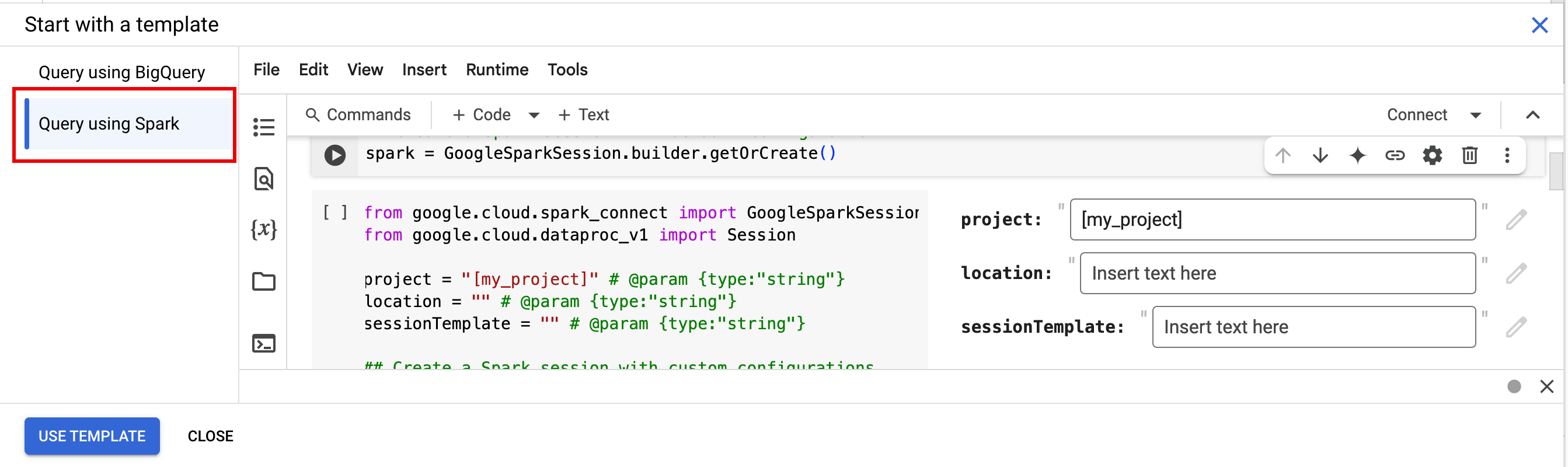
- מציינים את המשתנים כמו שמוסבר בהערות.
- אפשר למחוק תאים נוספים של קוד לדוגמה שהוכנסו ל-Notebook.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
project_id = "PROJECT_ID"
location = "LOCATION"
# Configure the session with an existing session template.
session_template = "SESSION_TEMPLATE"
session.session_template = f"projects/{project_id}/locations/{location}/sessionTemplates/{session_template}"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate()
)
מחליפים את מה שכתוב בשדות הבאים:
- PROJECT_ID: מזהה הפרויקט, שמופיע בקטע Project info במרכז הבקרה שלGoogle Cloud המסוף.
- LOCATION: האזור של Compute Engine שבו יפעל סשן המחברת. אם לא תציינו אזור, המערכת תשתמש באזור של מכונת ה-VM שיוצרת את המחברת.
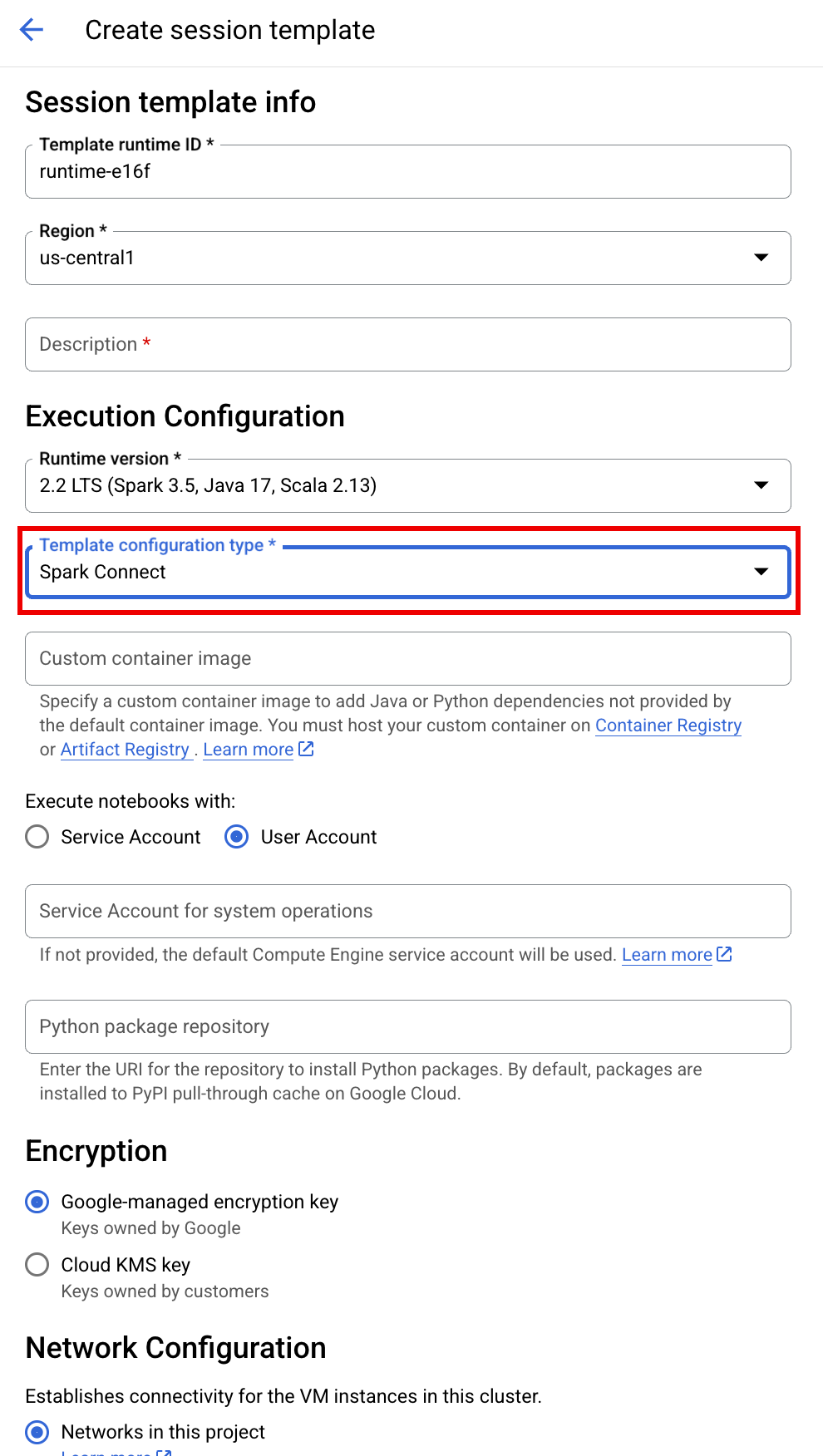
SESSION_TEMPLATE: השם של תבנית קיימת של סשן אינטראקטיבי. ההגדרות של הסשן נלקחות מהתבנית. בנוסף, בתבנית צריך לציין את ההגדרות הבאות:
- גרסת זמן ריצה
2.3+ סוג ה-Notebook:
Spark Connectדוגמה:
- גרסת זמן ריצה
APP_NAME: שם אופציונלי לסשן.
כתיבה והרצה של קוד PySpark במחברת BigQuery Studio
אחרי שיוצרים סשן Spark במחברת, משתמשים בסשן כדי להריץ קוד של מחברת Spark במחברת.
תמיכה ב-Spark Connect PySpark API: סשן המחברת של Spark Connect תומך ברוב ממשקי PySpark API, כולל DataFrame, Functions ו-Column, אבל לא תומך ב-SparkContext וב-RDD ובממשקי PySpark API אחרים. מידע נוסף זמין במאמר בנושא מה נתמך ב-Spark 3.5.
כתיבה ישירה של מחברת Spark Connect: סשנים של Spark במחברת BigQuery Studio מגדירים מראש את מחבר Spark BigQuery כדי לבצע כתיבה ישירה של נתונים. בשיטת הכתיבה DIRECT נעשה שימוש ב-BigQuery Storage Write API, שכותב נתונים ישירות ל-BigQuery. בשיטת הכתיבה INDIRECT, שהיא ברירת המחדל עבור אצוות של Managed Service for Apache Spark, הנתונים נכתבים לקטגוריה של Cloud Storage, ואז נכתבים ל-BigQuery (מידע נוסף על כתיבה INDIRECT זמין במאמר קריאה וכתיבה של נתונים מ-BigQuery ואליו).
API ספציפי ל-Managed Service for Apache Spark: Managed Service for Apache Spark מפשט את התהליך של הוספת חבילות PyPI באופן דינמי לסשן Spark באמצעות הרחבת השיטה addArtifacts. אפשר לציין את הרשימה בפורמט version-scheme (בדומה ל-pip install). כך, שרת Spark Connect יקבל הוראה להתקין חבילות ואת התלויות שלהן בכל צמתי האשכול, והן יהיו זמינות לעובדים עבור פונקציות ה-UDF.
דוגמה להתקנת גרסה ספציפית של textdistance וספריות random2 תואמות עדכניות באשכול, כדי לאפשר הפעלה של UDF באמצעות textdistance ו-random2 בצמתי עובד.
spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)
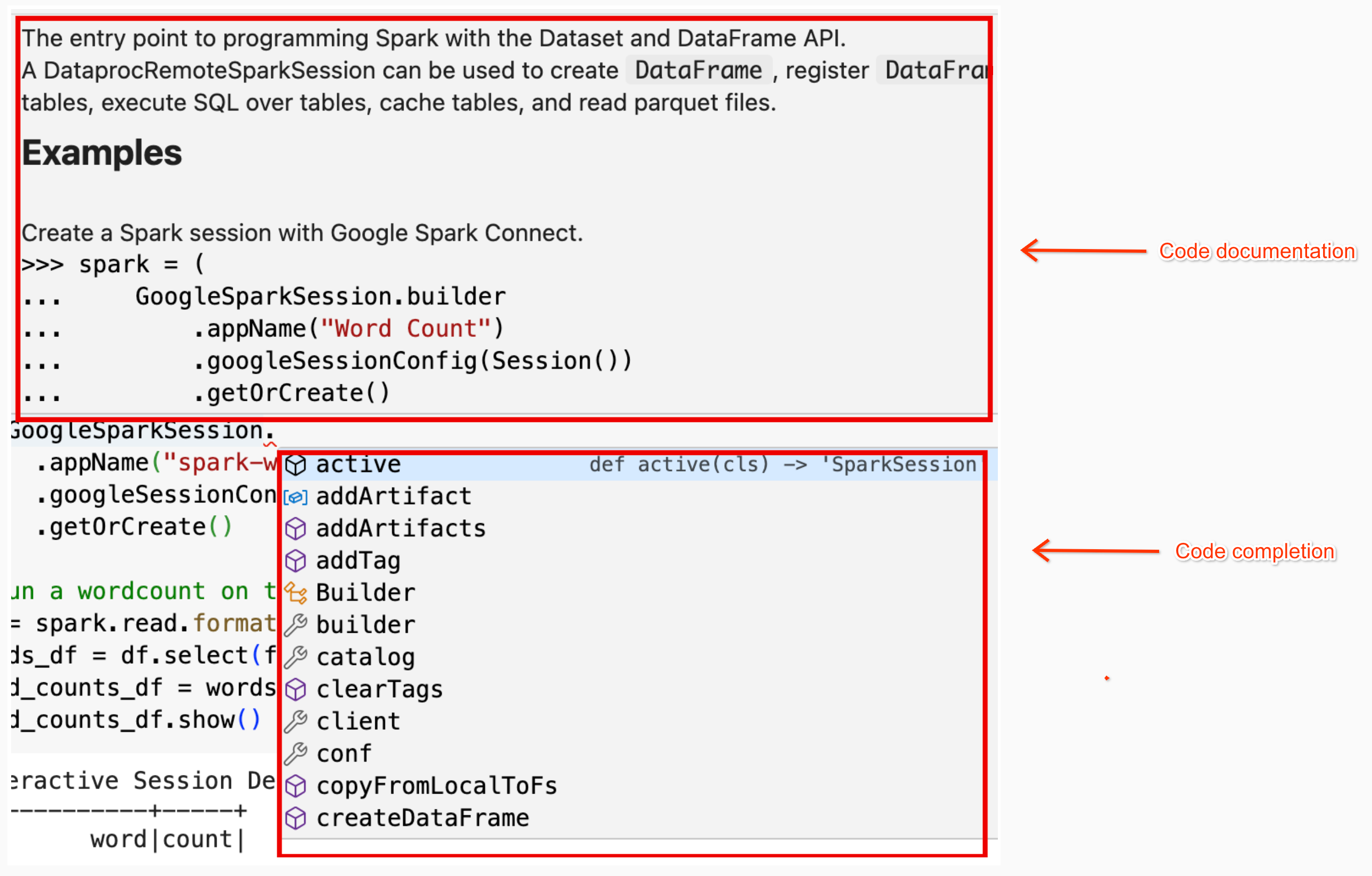
עזרה בקוד של מחברת: במחברת של BigQuery Studio יש עזרה בקוד כשמעבירים את מצביע העכבר מעל שם של מחלקה או שיטה, ועזרה בהשלמת קוד כשמזינים קוד.
בדוגמה הבאה, אם מזינים DataprocSparkSession ומחזיקים את מצביע העכבר מעל שם המחלקה, מוצגת השלמת קוד ועזרה לגבי התיעוד.
דוגמאות ל-PySpark ב-Notebook של BigQuery Studio
בקטע הזה מפורטות דוגמאות ל-Notebook של Python ב-BigQuery Studio עם קוד PySpark לביצוע המשימות הבאות:
- הרצת ספירת מילים במערך נתונים ציבורי של שייקספיר.
- יצירת טבלת Iceberg עם מטא-נתונים ששמורים בקטלוג זמן הריצה של Lakehouse.
ספירת מילים
בדוגמה הבאה של PySpark נוצרת סשן Spark, ואז נספרות המופעים של מילים במערך נתונים ציבורי bigquery-public-data.samples.shakespeare.
# Basic wordcount example
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
import pyspark.sql.functions as f
session = Session()
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate()
)
# Run a wordcount on the public Shakespeare dataset.
df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load()
words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word"))
word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word")
word_counts_df.show()
מחליפים את מה שכתוב בשדות הבאים:
- APP_NAME: שם אופציונלי לסשן.
פלט:
הפלט של התא מציג דוגמה של הפלט של ספירת המילים. כדי לראות את פרטי הסשן במסוף Google Cloud , לוחצים על הקישור Interactive Session Detail View. כדי לעקוב אחרי סשן Spark, לוחצים על View Spark UI (הצגת ממשק המשתמש של Spark) בדף פרטי הסשן.

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
טבלת Iceberg
הרצת קוד PySpark כדי ליצור טבלת Iceberg עם מטא-נתונים של קטלוג זמן ריצה של Lakehouse
בדוגמת הקוד הבאה נוצר sample_iceberg_table עם מטא-נתונים של טבלה שמאוחסנים בקטלוג של Lakehouse בזמן הריצה, ואז מתבצעת שאילתה בטבלה.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
# Create the Dataproc Serverless session.
session = Session()
# Set the session configuration for BigLake Metastore with the Iceberg environment.
project_id = "PROJECT_ID"
region = "REGION"
subnet_name = "SUBNET_NAME"
location = "LOCATION"
session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}"
warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY"
catalog = "CATALOG"
namespace = "NAMESPACE"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}"
session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}"
# Create the Spark Connect session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate()
)
# Create the namespace in BigQuery.
spark.sql(f"USE `{catalog}`;")
spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;")
spark.sql(f"USE `{namespace}`;")
# Create the Iceberg table.
spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`");
spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;")
spark.sql("DESCRIBE sample_iceberg_table;")
# Insert table data and query the table.
spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");")
# Alter table, then query and display table data and schema.
spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);")
spark.sql("DESCRIBE sample_iceberg_table;")
df = spark.sql("SELECT * FROM sample_iceberg_table")
df.show()
df.printSchema()
הערות:
- PROJECT_ID: מזהה הפרויקט, שמופיע בקטע Project info במרכז הבקרה שלGoogle Cloud המסוף.
- REGION ו-SUBNET_NAME: מציינים את האזור של Compute Engine ואת השם של רשת משנה באזור הסשן. Managed Service for Apache Spark מאפשר גישה פרטית ל-Google (PGA) ברשת המשנה שצוינה.
- LOCATION: ברירת המחדל של
BigQuery_metastore_config.locationושלspark.sql.catalog.{catalog}.gcp_locationהיאUS, אבל אפשר לבחור כל מיקום נתמך ב-BigQuery. - BUCKET ו-WAREHOUSE_DIRECTORY: הקטגוריה והתיקייה ב-Cloud Storage שמשמשות לספריית מחסן Iceberg.
- CATALOG ו-NAMESPACE: השילוב של שם הקטלוג ומרחב השמות של Iceberg משמש לזיהוי טבלת Iceberg (
catalog.namespace.table_name). - APP_NAME: שם אופציונלי לסשן.
בפלט של התא מופיע sample_iceberg_table עם העמודה שנוספה, ומוצג קישור לדף Interactive Session Details במסוף Google Cloud .
אפשר ללחוץ על View Spark UI בדף פרטי הסשן כדי לעקוב אחרי סשן Spark.
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
הצגת פרטי הטבלה ב-BigQuery
כדי לבדוק את פרטי טבלת Iceberg ב-BigQuery:
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית של משאבי הפרויקט, לוחצים על הפרויקט ואז על מרחב השמות כדי להציג את הטבלה
sample_iceberg_table. לוחצים על הטבלה פרטים כדי לראות את המידע פתיחת הגדרות טבלת קטלוג.פורמטי הקלט והפלט הם פורמטים סטנדרטיים של מחלקות Hadoop
InputFormatו-OutputFormatשמשמשים את Iceberg.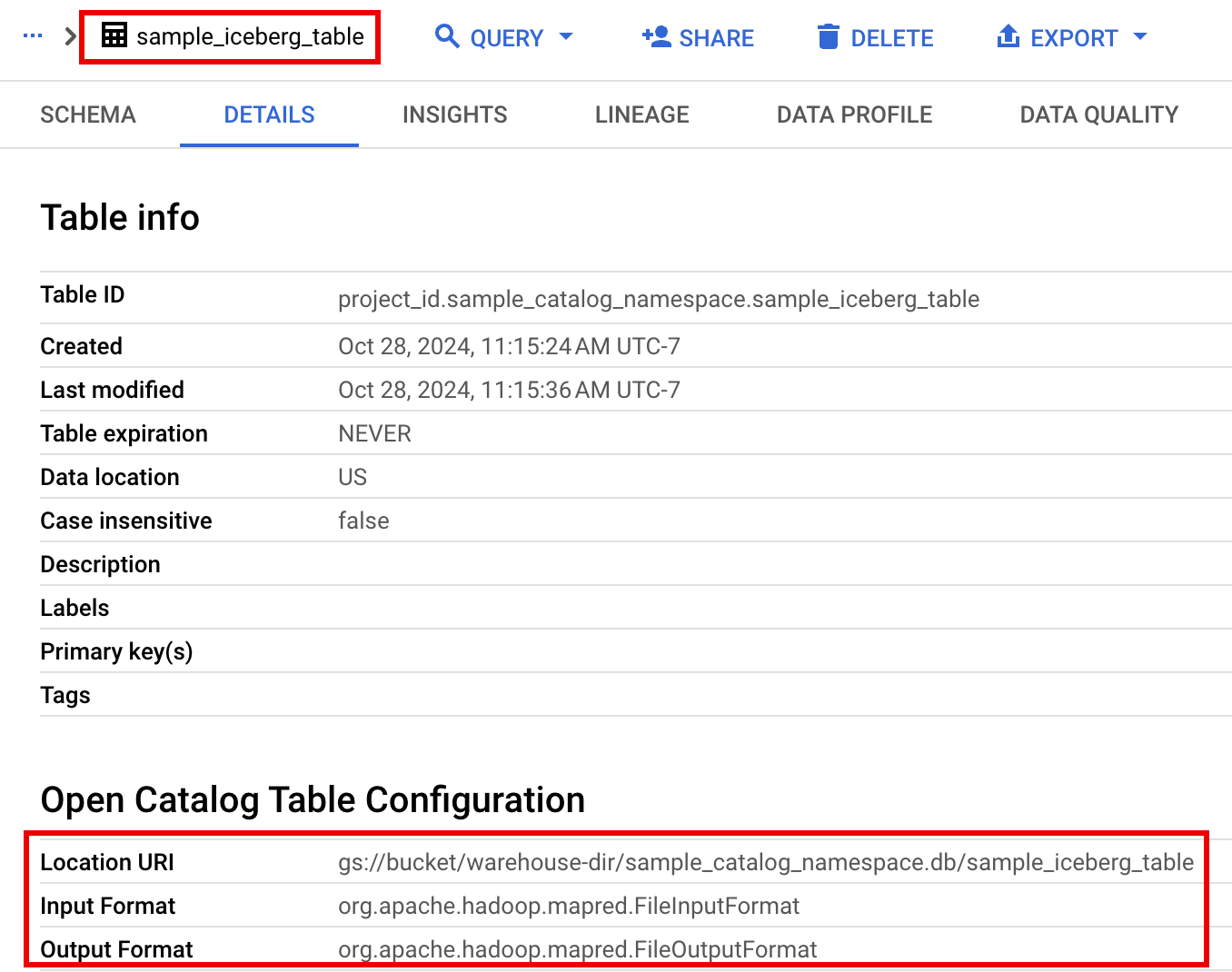
דוגמאות נוספות
יצירת Spark DataFrame (sdf) מ-Pandas DataFrame (df).
sdf = spark.createDataFrame(df)
sdf.show()
הרצת צבירות ב-Spark DataFrames.
from pyspark.sql import functions as f
sdf.groupby("segment").agg(
f.mean("total_spend_per_user").alias("avg_order_value"),
f.approx_count_distinct("user_id").alias("unique_customers")
).show()
קריאה מ-BigQuery באמצעות המחבר Spark-BigQuery.
spark.conf.set("viewsEnabled","true")
spark.conf.set("materializationDataset","my-bigquery-dataset")
sdf = spark.read.format('bigquery') \
.load(query)
כתיבת קוד Spark באמצעות Gemini Code Assist
אתם יכולים לבקש מ-Gemini Code Assist ליצור קוד PySpark במחברת שלכם. Gemini Code Assist מאחזר טבלאות רלוונטיות של BigQuery ו-Dataproc Metastore וסכימות שלהן, ומשתמש בהן כדי ליצור תשובה של קוד.
כדי ליצור קוד באמצעות Gemini Code Assist בנוטבוק:
כדי להוסיף תא קוד חדש, לוחצים על + Code (קוד) בסרגל הכלים. בתא הקוד החדש מוצג
Start coding or generate with AI. לוחצים על יצירה.בעורך היצירה, מזינים הנחיה בשפה טבעית ולוחצים על
enter. חשוב לכלול את מילת המפתחsparkאוpysparkבהנחיה.הנחיה לדוגמה:
create a spark dataframe from order_items and filter to orders created in 2024
פלט לדוגמה:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")
טיפים ליצירת קוד באמצעות Gemini Code Assist
כדי לאפשר ל-Gemini Code Assist לאחזר טבלאות וסכימות רלוונטיות, צריך להפעיל את הסנכרון של Data Catalog עבור מופעים של Dataproc Metastore.
מוודאים שלחשבון המשתמש יש גישה ל-Data Catalog ולטבלאות של השאילתות. כדי לעשות את זה, צריך להקצות את התפקיד
DataCatalog.Viewer.
סיום סשן Spark
כדי להפסיק את הסשן של Spark Connect במחברת BigQuery Studio, אפשר לבצע כל אחת מהפעולות הבאות:
- מריצים את
spark.stop()בתא ב-notebook. - סיום זמן הריצה ב-Notebook:
- לוחצים על בורר זמן הריצה ואז על ניהול סשנים.
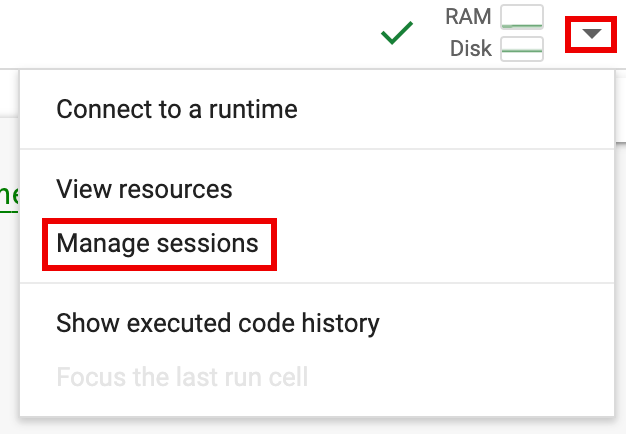
- בתיבת הדו-שיח סשנים פעילים, לוחצים על סמל הסיום ואז על סיום.
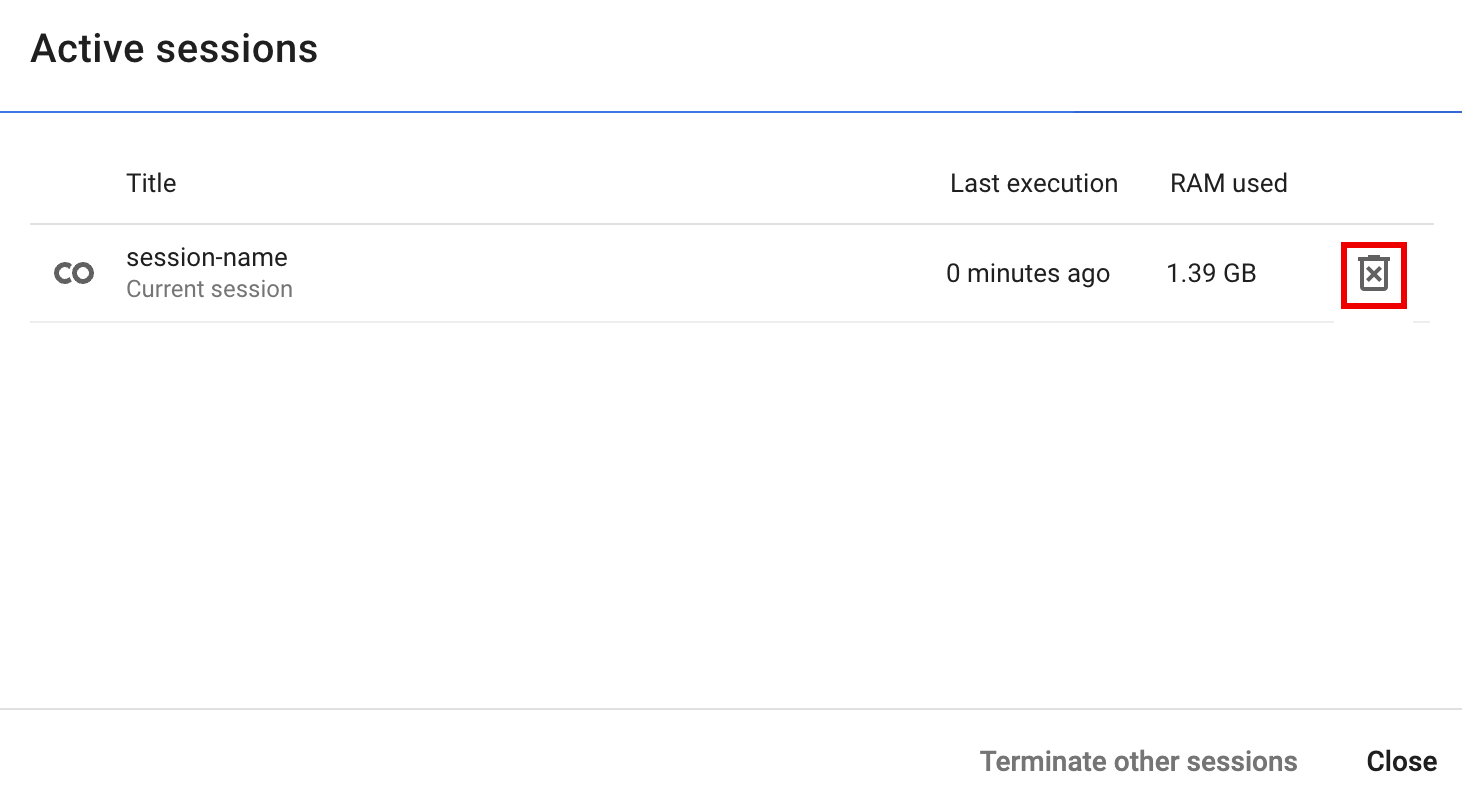
- לוחצים על בורר זמן הריצה ואז על ניהול סשנים.
ארגון קוד במחברת BigQuery Studio
אפשר לתזמן קוד של מחברת ב-BigQuery Studio באופנים הבאים:
תזמון קוד של מחברת מתוך Google Cloud המסוף (תמחור מחברות חל).
הפעלת קוד במחברת כעומס עבודה של עיבוד ברצף (batch processing) (המחירון של Managed Service for Apache Spark חל).
תזמון קוד של מחברת מהמסוף Google Cloud
אפשר לתזמן קוד של מחברת בדרכים הבאות:
- מתזמנים את ה-Notebook.
- אם הפעלת קוד ב-notebook היא חלק מתהליך עבודה, כדאי לתזמן את ה-notebook כחלק מצינור עיבוד נתונים.
הרצת קוד ב-notebook בתור עומס עבודה של אצווה
כדי להריץ קוד של מחברת BigQuery Studio כעומס עבודה של אצווה:
מורידים את קוד המחברת לקובץ בטרמינל מקומי או ב-Cloud Shell.
במסוף Google Cloud , בדף BigQuery Studio, פותחים את המחברת בחלונית Explorer.
כדי להרחיב את סרגל התפריטים, לוחצים על keyboard_arrow_down הצגה או הסתרה של הכותרת.
לוחצים על קובץ > הורדה ואז על Download.py.
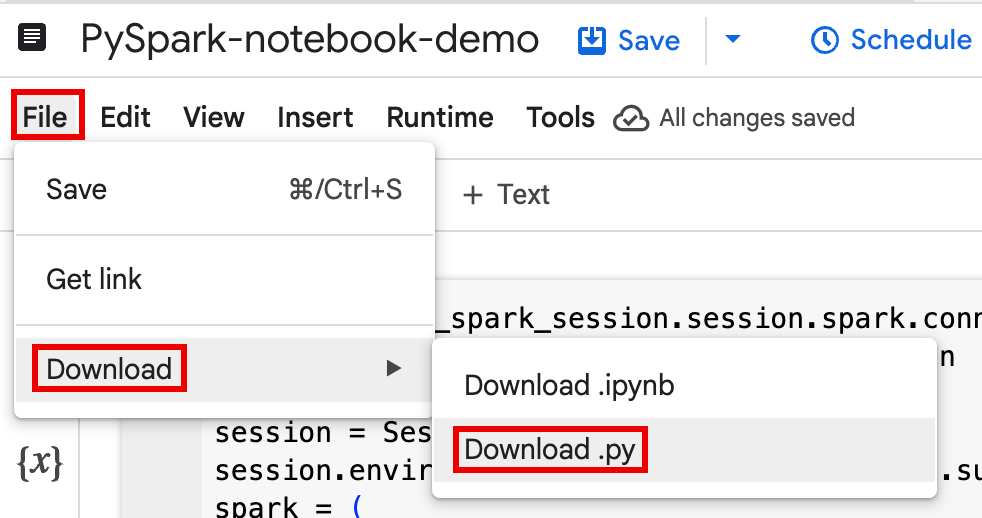
יצירת
requirements.txt.- מתקינים את
pipreqsבספרייה שבה שמרתם את הקובץ.py.pip install pipreqs
מריצים את הפקודה
pipreqsכדי ליצור אתrequirements.txt.pipreqs filename.py
משתמשים ב-Google Cloud CLI כדי להעתיק את הקובץ המקומי
requirements.txtלקטגוריה ב-Cloud Storage.gcloud storage cp requirements.txt gs://BUCKET/
- מתקינים את
מעדכנים את הקוד של סשן Spark על ידי עריכת הקובץ
.pyשהורד.מסירים או מוסיפים הערות לכל פקודות סקריפט ה-Shell.
מסירים את הקוד שמגדיר את סשן Spark, ואז מציינים פרמטרים של הגדרות כפרמטרים של שליחת עומס עבודה של אצווה. (ראו שליחת עומס עבודה של אצווה ב-Spark).
דוגמה:
מסירים את השורה הבאה של הגדרת רשת המשנה של הסשן מהקוד:
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"כשמריצים את עומס העבודה של אצווה, משתמשים בדגל
--subnetכדי לציין את רשת המשנה.gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
משתמשים בקטע קוד פשוט ליצירת סשן.
דוגמה לקוד של מחברת שהורדה לפני פישוט.
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
קוד של עומס עבודה של אצווה אחרי פישוט.
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
מריצים את עומס העבודה של האצווה.
הוראות מפורטות מופיעות במאמר בנושא שליחת עומס עבודה של אצווה ב-Spark.
חשוב לכלול את הדגל --deps-bucket כדי להפנות לקטגוריה של Cloud Storage שמכילה את הקובץ
requirements.txt.דוגמה:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
הערות:
- FILENAME: השם של קובץ הקוד של המחברת שהורדתם ועריכתם.
- REGION: האזור ב-Compute Engine שבו נמצא האשכול.
- BUCKET השם של הקטגוריה של Cloud Storage שמכילה את הקובץ
requirements.txt. -
--version: spark runtime version 2.3 is selected to run the batch workload.
מבצעים קומיט של הקוד.
- אחרי שבודקים את קוד עומס העבודה של האצווה, אפשר לבצע קומיט של הקובץ
.ipynbאו.pyלמאגר באמצעות לקוחgit, כמו GitHub, GitLab או Bitbucket, כחלק מצינור עיבוד הנתונים של CI/CD.
- אחרי שבודקים את קוד עומס העבודה של האצווה, אפשר לבצע קומיט של הקובץ
תזמון עומסי עבודה באצווה באמצעות Managed Service for Apache Airflow.
- הוראות מפורטות מופיעות במאמר בנושא הפעלת עומסי עבודה של Managed Service for Apache Spark באמצעות Managed Airflow.
פתרון שגיאות ב-notebook
אם מתרחש כשל בתא שמכיל קוד Spark, אפשר לפתור את השגיאה על ידי לחיצה על הקישור Interactive Session Detail View בפלט של התא (ראו את הדוגמאות של Wordcount וטבלת Iceberg).
בעיות מוכרות ופתרונות
שגיאה: זמן ריצה של Notebook
שנוצר עם Python בגרסה 3.10 עלול לגרום לשגיאה PYTHON_VERSION_MISMATCH
בניסיון להתחבר לסשן Spark.
פתרון: יוצרים מחדש את זמן הריצה עם גרסת Python 3.11.
המאמרים הבאים
- סרטון ב-YouTube: מינוף העוצמה של Apache Spark בשילוב עם BigQuery.
- שימוש בקטלוג זמן ריצה של Lakehouse עם Managed Service for Apache Spark
- שימוש בקטלוג זמן ריצה של Lakehouse עם Managed Service for Apache Spark