
מבוא ל-BigQuery Storage Write API
BigQuery Storage Write API הוא ממשק API מאוחד להטמעת נתונים ב-BigQuery. זהו ממשק API בעל ביצועים משופרים, שמשולבות בו הפונקציונליות של הטמעת עדכונים בזמן אמת והפונקציונליות של טעינת נתונים בכמות גדולה. אתם יכולים להשתמש ב-Storage Write API כדי להזרים רשומות ל-BigQuery בזמן אמת או כדי לעבד מספר גדול של רשומות ולבצע אותן בפעולה אטומית אחת.
היתרונות של שימוש ב-Storage Write API
סמנטיקה של אספקה בדיוק פעם אחת. Storage Write API תומך בסמנטיקה של מסירה חד-פעמית באמצעות שימוש בהיסטים של הזרם. בניגוד לשיטה tabledata.insertAll, Storage Write API אף פעם לא כותב שתי הודעות עם אותו היסט בתוך זרם, אם הלקוח מספק היסטים של זרם כשמוסיפים רשומות.
עסקאות ברמת הזרם. אפשר לכתוב נתונים למקור נתונים ולבצע את הנתונים כעסקה אחת. אם פעולת השמירה נכשלת, אפשר לנסות שוב לבצע את הפעולה.
עסקאות בכל הזרמים. כמה עובדים יכולים ליצור זרמים משלהם כדי לעבד נתונים באופן עצמאי. אחרי שכל העובדים יסיימו, תוכלו לבצע commit לכל הזרמים כעסקה.
פרוטוקול יעיל. ה-Storage Write API יעיל יותר מהשיטה הקודמת insertAll כי הוא משתמש בסטרימינג של gRPC ולא ב-REST על HTTP. בנוסף, Storage Write API תומך בפורמט הבינארי מאגר אחסון לפרוטוקולים ובפורמט העמודות Apache Arrow, שהם פורמטים יעילים יותר מ-JSON. בקשות כתיבה הן אסינכרוניות
עם סדר מובטח.
זיהוי עדכוני סכימה. אם סכימת הטבלה הבסיסית משתנה בזמן שהלקוח מעביר נתונים בסטרימינג, Storage Write API שולח ללקוח הודעה על כך. הלקוח יכול להחליט אם להתחבר מחדש באמצעות הסכימה המעודכנת, או להמשיך לכתוב לחיבור הקיים.
עלות נמוכה יותר. העלות של Storage Write API נמוכה משמעותית מזו של insertAll Streaming API מהדור הקודם. בנוסף, אתם יכולים להעלות עד 2 TiB בחודש בחינם.
ההרשאות הנדרשות
כדי להשתמש ב-Storage Write API, אתם צריכים הרשאות bigquery.tables.updateData.
התפקידים המוגדרים מראש הבאים של ניהול זהויות והרשאות גישה (IAM) כוללים את ההרשאות bigquery.tables.updateData:
bigquery.dataEditorbigquery.dataOwnerbigquery.admin
במאמר תפקידים והרשאות מוגדרים מראש יש מידע נוסף על תפקידים והרשאות ב-IAM ב-BigQuery.
היקפי הרשאות
כדי להשתמש ב-Storage Write API, צריך להגדיר אחד מהיקפי ההרשאות הבאים של OAuth:
https://www.googleapis.com/auth/bigqueryhttps://www.googleapis.com/auth/cloud-platformhttps://www.googleapis.com/auth/bigquery.insertdata
מידע נוסף מופיע במאמר סקירה כללית על אימות.
סקירה כללית על Storage Write API
ההפשטה העיקרית ב-Storage Write API היא stream. הנתונים נכתבים לטבלה ב-BigQuery באמצעות זרם. יותר מזרם אחד יכולים לכתוב בו-זמנית לאותה טבלה.
ברירת מחדל לשידור
Storage Write API מספק זרם ברירת מחדל, שנועד לתרחישי סטרימינג שבהם הנתונים מגיעים באופן רציף. המאפיינים שלו הם:
- הנתונים שנכתבים למקור הנתונים שמוגדר כברירת מחדל זמינים מיד לשליחת שאילתות.
- הסטרימינג שמוגדר כברירת מחדל תומך בסמנטיקה של 'לפחות פעם אחת'.
- לא צריך ליצור במפורש את שידור ברירת המחדל.
אם אתם מבצעים מיגרציה מ-API מדור קודם של
tabledata.insertall, כדאי להשתמש בזרם ברירת המחדל. יש לו סמנטיקה דומה של כתיבה, עם עמידות גבוהה יותר של הנתונים ופחות הגבלות על שינוי הגודל.
תהליך ה-API:
-
AppendRows(לולאה)
מידע נוסף וקוד לדוגמה זמינים במאמר בנושא שימוש בזרם ברירת המחדל לסמנטיקה של 'לפחות פעם אחת'.
מקורות נתונים שנוצרו על ידי אפליקציה
אתם יכולים ליצור במפורש מקור נתונים אם אתם צריכים את אחת מההתנהגויות הבאות:
- סמנטיקה של כתיבה בדיוק פעם אחת באמצעות שימוש בהיסטים של הזרם.
- תמיכה במאפייני ACID נוספים.
באופן כללי, סטרים שנוצרו על ידי אפליקציה מאפשרים שליטה רבה יותר בפונקציונליות, אבל הם מורכבים יותר.
כשיוצרים זרם, מציינים סוג. הסוג קובע מתי הנתונים שנכתבים לזרם יהיו גלויים לקריאה ב-BigQuery.
סוג בהמתנה
בסוג בהמתנה, הרשומות נשמרות בזיכרון במצב בהמתנה עד שמבצעים את הזרם. כשמבצעים קומיט של זרם, כל הנתונים בהמתנה הופכים לזמינים לקריאה. ההעברה היא פעולה אטומית. אפשר להשתמש בסוג הזה לעומסי עבודה (workloads) של אצווה, כחלופה למשימות טעינה ב-BigQuery. מידע נוסף זמין במאמר בנושא טעינת נתונים באצווה באמצעות Storage Write API.
תהליך ה-API:
סוג ההתחייבות
בסוג committed, הרשומות זמינות לקריאה מיד כשכותבים אותן לזרם. משתמשים בסוג הזה לעומסי עבודה של סטרימינג שדורשים השהיה מינימלית בקריאה. הזרם שמוגדר כברירת מחדל משתמש בטופס מסוג committed לפחות פעם אחת. מידע נוסף זמין במאמר שימוש בסוג מחויב כדי להבטיח סמנטיקה של שליחה חד-פעמית.
תהליך ה-API:
CreateWriteStream-
AppendRows(לולאה) -
FinalizeWriteStream(אופציונלי)
סוג עם זיכרון זמני
סוג מאוחסן במאגר זמני הוא סוג מתקדם שבדרך כלל לא מומלץ להשתמש בו, אלא עם מחבר Apache Beam BigQuery I/O. אם יש לכם קבוצות קטנות שאתם רוצים לוודא שיופיעו יחד, אתם יכולים להשתמש בסוג committed ולשלוח כל קבוצה בבקשה אחת. בסוג הזה, יש פעולות commit ברמת השורה, והרשומות נשמרות במאגר זמני עד שהשורה מועברת על ידי ניקוי הזרם.
תהליך ה-API:
CreateWriteStream-
AppendRows⇒FlushRows(לולאה) -
FinalizeWriteStream(אופציונלי)
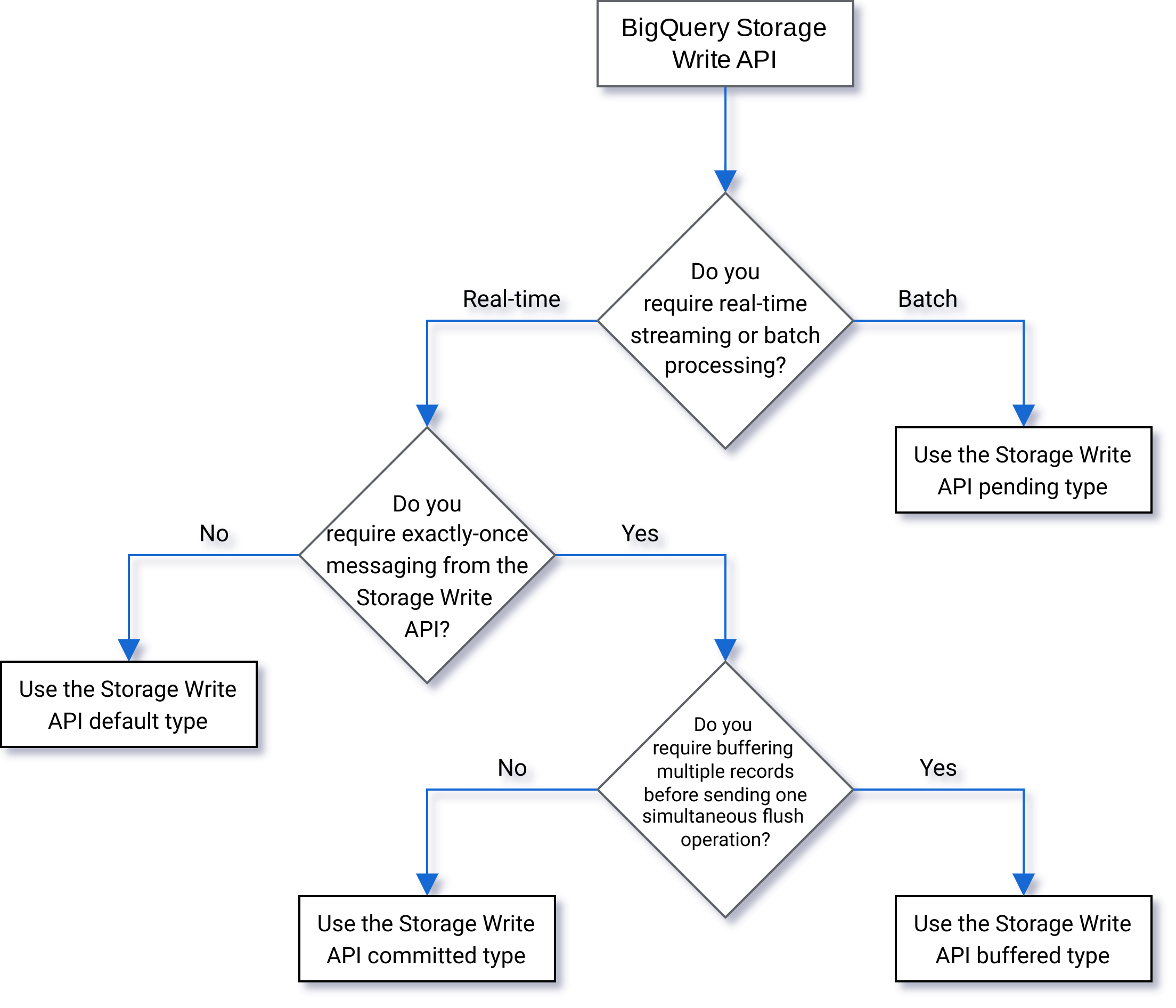
בחירת סוג
תרשים הזרימה הבא יעזור לכם להחליט איזה סוג הכי מתאים לעומס העבודה שלכם:
פרטי ה-API
כשמשתמשים ב-Storage Write API, כדאי לקחת בחשבון את הנקודות הבאות:
AppendRows
ה-method AppendRows מוסיף רשומה אחת או יותר לזרם. הקריאה הראשונה אל AppendRows חייבת להכיל שם של מקור נתונים יחד עם סכימת הנתונים, שצוינה כ-DescriptorProto. לחלופין, אפשר להוסיף סכימת חץ מסודרת בקריאה הראשונה אל AppendRows אם אתם מבצעים המרה של נתונים בפורמט Apache Arrow. מומלץ לשלוח אצווה של שורות בכל קריאה ל-AppendRows. אל תשלחו שורה אחת בכל פעם.
טיפול במאגר אחסון לפרוטוקולים
פרוטוקול buffers מספק מנגנון שאינו תלוי בשפה או בפלטפורמה, וניתן להרחבה, לסריאליזציה של נתונים מובְנים באופן שתואם קדימה ותואם אחורה. היתרון שלהם הוא שהם מאפשרים אחסון נתונים קומפקטי וניתוח מהיר ויעיל. מידע נוסף על מאגרי פרוטוקולים זמין במאמר סקירה כללית על מאגרי פרוטוקולים.
אם אתם מתכוונים לצרוך את ה-API ישירות עם הודעת מאגר אחסון לפרוטוקולים מוגדרת מראש, הודעת מאגר אחסון לפרוטוקולים לא יכולה להשתמש במציין package, וכל הסוגים המקוננים או סוגי הספירה צריכים להיות מוגדרים בהודעת הבסיס ברמה הבסיסית (root).
אסור להשתמש בהפניות להודעות חיצוניות. לדוגמה, אפשר לעיין ב-sample_data.proto.
לקוחות Java ו-Go תומכים במאגרי אחסון לפרוטוקולים שרירותיים, כי ספריית הלקוח מבצעת נירמול של סכימת מאגר אחסון לפרוטוקולים.
טיפול ב-Apache Arrow
Apache Arrow הוא פורמט אוניברסלי של נתונים בטורים וארגז כלים רב-לשוני לעיבוד נתונים. Apache Arrow מספק פורמט זיכרון עצמאי לשפה, מבוסס-עמודות, לנתונים שטוחים והיררכיים, שמסודרים לפעולות ניתוח יעילות בחומרה מודרנית. Storage Write API תומך בהטמעה של Arrow באמצעות סכימת Arrow מסודרת ונתונים ב-מחלקת AppendRowsRequest.
ספריות הלקוח של Python ו-Java כוללות תמיכה מובנית בהעברה של נתונים בפורמט Apache Arrow.
FinalizeWriteStream
השיטה FinalizeWriteStream מסיימת את הזרם כך שלא ניתן להוסיף לו נתונים חדשים. השיטה הזו נדרשת בסוג Pending והיא אופציונלית בסוגים Committed ו-Buffered. שידור ברירת המחדל לא תומך בשיטה הזו.
טיפול בשגיאות
אם מתרחשת שגיאה, התגובה google.rpc.Status יכולה לכלול StorageError בפרטי השגיאה. כדי למצוא את סוג השגיאה הספציפי, אפשר לעיין בStorageErrorCode. מידע נוסף על מודל השגיאות של Google API זמין במאמר שגיאות.
חיבורים
Storage Write API הוא gRPC API שמשתמש בחיבורים דו-כיווניים. השיטה AppendRows יוצרת חיבור לסטרים. אפשר לפתוח כמה חיבורים בזרם ברירת המחדל. ההוספות האלה הן אסינכרוניות, ולכן אפשר לשלוח סדרה של פעולות כתיבה בו-זמנית. הודעות התגובה בכל חיבור דו-כיווני מגיעות באותו סדר שבו הבקשות נשלחו.
לסטרימינג שנוצר על ידי אפליקציה יכול להיות רק חיבור פעיל אחד. מומלץ להגביל את מספר החיבורים הפעילים ולהשתמש בחיבור אחד לכתיבה של כמה שיותר נתונים. כשמשתמשים בזרם ברירת המחדל ב-Java או ב-Go, אפשר להשתמש בריבוב של Storage Write API כדי לכתוב לכמה טבלאות יעד עם חיבורים משותפים.
בדרך כלל, חיבור יחיד תומך ברוחב פס של לפחות 1 MBps. הגבול העליון תלוי בכמה גורמים, כמו רוחב הפס של הרשת, הסכימה של הנתונים ועומס השרת. כשחיבור מגיע למגבלת התפוקה, יכול להיות שבקשות נכנסות יידחו או יוכנסו לתור עד שמספר הבקשות הפעילות יירד. אם אתם צריכים תפוקה גבוהה יותר, תוכלו ליצור עוד חיבורים.
BigQuery סוגר את חיבור ה-gRPC אם החיבור נשאר במצב סרק יותר מדי זמן. אם זה קורה, קוד התגובה הוא HTTP 409. החיבור ל-gRPC
יכול להיסגר גם אם השרת מופעל מחדש או מסיבות אחרות. אם מתרחשת שגיאת חיבור, צריך ליצור חיבור חדש. ספריות הלקוח של Java ו-Go
מתחברות מחדש באופן אוטומטי אם החיבור נסגר.
תמיכה בספריות לקוח
קיימות ספריות לקוח ל-Storage Write API בכמה שפות תכנות, והן חושפות את מבני ה-API הבסיסיים שמבוססים על gRPC. ה-API הזה מתבסס על תכונות מתקדמות כמו סטרימינג דו-כיווני, שעשויות לדרוש עבודת פיתוח נוספת כדי לתמוך בהן. לכן, יש מספר הפשטות ברמה גבוהה יותר שזמינות ל-API הזה, שמפשטות את האינטראקציות האלה ומפחיתות את הדאגות של המפתחים. מומלץ להשתמש בהפשטות אחרות של הספריות האלה, כשהדבר אפשרי.
בקטע הזה מפורטים שפות וספריות שבהן ניתנו למפתחים יכולות נוספות מעבר ל-API שנוצר.
כדי לראות דוגמאות קוד שקשורות ל-Storage Write API, אפשר לעיין בכל דוגמאות הקוד של BigQuery.
לקוח Java
ספריית הלקוח Java מספקת שני אובייקטים של כתיבה:
StreamWriter: מקבל נתונים בפורמט של מאגר פרוטוקולים.
JsonStreamWriter: מקבל נתונים בפורמט JSON וממיר אותם למאגרי פרוטוקולים לפני שליחתם דרך החיבור.JsonStreamWriterתומך גם בעדכונים אוטומטיים של סכימות. אם סכימת הטבלה משתנה, הכותב מתחבר מחדש באופן אוטומטי לסכימה החדשה, וכך הלקוח יכול לשלוח נתונים באמצעות הסכימה החדשה.
מודל התכנות דומה בשני המקרים. ההבדל העיקרי הוא בפורמט של מטען הייעודי (payload).
אובייקט הכתיבה מנהל חיבור ל-Storage Write API. אובייקט הכתיבה מנקה אוטומטית את הבקשות, מוסיף את כותרות הניתוב האזורי לבקשות ומתחבר מחדש אחרי שגיאות בחיבור. אם אתם משתמשים ישירות ב-gRPC API, אתם צריכים לטפל בפרטים האלה.
אפשר גם להשתמש בפורמט ההטמעה Apache Arrow כפרוטוקול חלופי להטמעת נתונים באמצעות Storage Write API. מידע נוסף זמין במאמר שימוש בפורמט Apache Arrow להטמעת נתונים.
לקוח Go
לקוח Go משתמש בארכיטקטורת לקוח-שרת כדי לקודד הודעות בפורמט של מאגר אחסון לפרוטוקולים באמצעות proto2. במסמכי התיעוד של Go מופיעים פרטים על אופן השימוש בלקוח Go, עם דוגמאות קוד.
לקוח Python
לקוח Python הוא לקוח ברמה נמוכה יותר שעוטף את gRPC API. כדי להשתמש בלקוח הזה, צריך לשלוח את הנתונים כמאגרי פרוטוקולים, בהתאם לזרימת ה-API של הסוג שצוין.
מומלץ להימנע משימוש ביצירה דינמית של הודעות פרוטו ב-Python, כי הביצועים של הספרייה הזו לא מספיקים.
כדי לקבל מידע נוסף על השימוש ב-Protocol Buffers עם Python, אפשר לקרוא את המדריך בנושא יסודות Protocol Buffers ב-Python.
אתם יכולים גם להשתמש בפורמט ההטמעה של Apache Arrow כפרוטוקול חלופי להטמעת נתונים באמצעות Storage Write API. מידע נוסף זמין במאמר בנושא שימוש בפורמט Apache Arrow להעברת נתונים.
לקוח NodeJS
ספריית הלקוח NodeJS מקבלת קלט JSON ומספקת תמיכה בחיבור מחדש אוטומטי. במאמרי העזרה מוסבר איך להשתמש בלקוח.
הכינוי לא זמין
ניסיון חוזר עם השהיה מעריכית לפני ניסיון חוזר (exponential backoff) יכול לצמצם שגיאות אקראיות ותקופות קצרות של חוסר זמינות של השירות, אבל כדי להימנע מהשמטת שורות במהלך תקופות ארוכות של חוסר זמינות, צריך לחשוב על פתרונות נוספים. בפרט, אם לקוח לא מצליח להוסיף שורה באופן עקבי, מה עליו לעשות?
התשובה תלויה בדרישות שלכם. לדוגמה, אם משתמשים ב-BigQuery לניתוח תפעולי, ומקובל שחלק מהשורות חסרות, הלקוח יכול לוותר אחרי כמה ניסיונות חוזרים ולמחוק את הנתונים. אם כל שורה חשובה לעסק, כמו במקרה של נתונים פיננסיים, תצטרכו לגבש אסטרטגיה לשמירת הנתונים עד שאפשר יהיה להוסיף אותם מאוחר יותר.
דרך נפוצה להתמודדות עם שגיאות חוזרות היא פרסום השורות בנושא Pub/Sub לצורך הערכה מאוחרת יותר ואפשרות להוספה. שיטה נפוצה נוספת היא לשמור את הנתונים באופן זמני בצד הלקוח. שתי השיטות יכולות לשמור על הלקוחות לא חסומים, ובמקביל לוודא שניתן להוסיף את כל השורות ברגע שהזמינות משוחזרת.
הזרמה לטבלאות מחולקות למחיצות
Storage Write API תומך בהעברת נתוני סטרימינג אל טבלאות עם חלוקה למחיצות.
כשמבצעים סטרימינג של הנתונים, הם ממוקמים בהתחלה במחיצה __UNPARTITIONED__. אחרי שנאספים מספיק נתונים לא מחולקים, מערכת BigQuery מחלקת מחדש את הנתונים וממקמת אותם במחיצה המתאימה.
עם זאת, אין הסכם רמת שירות (SLA) שמגדיר כמה זמן יכול לקחת עד שהנתונים האלה יועברו מהמחיצה __UNPARTITIONED__.
בטבלאות עם מחיצות לפי זמן הטמעה ועם מחיצות לפי עמודה של יחידת זמן, אפשר להחריג נתונים שלא חולקו למחיצות משאילתה על ידי סינון הערכים של NULL מהמחיצה __UNPARTITIONED__ באמצעות אחת מהעמודות הווירטואליות (_PARTITIONTIME או _PARTITIONDATE, בהתאם לסוג הנתונים המועדף).
חלוקה למחיצות (partitioning) לפי זמני כתיבת הנתונים
כשמבצעים סטרימינג אל טבלה מחולקת למחיצות (Partitions) לפי זמני כתיבת הנתונים, ה-Storage Write API מסיק את מחיצת היעד מתוך השעה הנוכחית במערכת לפי UTC.
אם אתם מעבירים נתונים בסטרימינג לטבלה עם חלוקה למחיצות לפי יום, אתם יכולים לבטל את ההיסק של התאריך על ידי ציון קישוט של מחיצה כחלק מהבקשה.
כוללים את ה-decorator בפרמטר tableID. לדוגמה, אפשר להזרים למחיצה שמתאימה לתאריך 2025-06-01 בטבלה table1 באמצעות קישוט המחיצה table1$20250601.
כשמבצעים סטרימינג עם decorator של מחיצה, אפשר לבצע סטרימינג למחיצות מ-31 ימים בעבר עד 16 ימים בעתיד. כדי לכתוב למחיצות של תאריכים מחוץ לגבולות האלה, צריך להשתמש במקום זאת בעבודת טעינה או שאילתה, כמו שמתואר במאמר כתיבת נתונים למחיצה ספציפית.
הזרמה באמצעות קישוט מחיצות נתמכת רק בטבלאות עם מחיצות יומיות, ולא בטבלאות עם מחיצות לפי שעה, חודש או שנה.
חלוקה למחיצות לפי עמודה של יחידת זמן
כשמבצעים סטרימינג לטבלה עם חלוקה למחיצות לפי עמודה של יחידת זמן, מערכת BigQuery מכניסה את הנתונים באופן אוטומטי למחיצה הנכונה על סמך הערכים של עמודת החלוקה למחיצות DATE, DATETIME או TIMESTAMP שהוגדרה מראש בטבלה. אפשר להזרים נתונים לטבלה מחולקת למחיצות של עמודה של יחידת זמן אם הנתונים שאליהם מתייחסת עמודת החלוקה למחיצות הם בין 10 שנים בעבר לשנה בעתיד.
חלוקה למחיצות (partitioning) של טווח מספרים שלמים
כשמבצעים סטרימינג לטבלה עם חלוקה למחיצות לפי טווח מספרים שלמים, מערכת BigQuery מכניסה את הנתונים באופן אוטומטי למחיצה הנכונה על סמך הערכים של עמודת החלוקה למחיצות INTEGER שהוגדרה מראש בטבלה.
Fluent Bit Storage Write API output plugin
התוסף של Fluent Bit Storage Write API output מאפשר להטמיע רשומות JSON ב-BigQuery באופן אוטומטי, בלי שתצטרכו לכתוב קוד. כדי להתחיל להזרים נתונים באמצעות הפלאגין הזה, צריך רק להגדיר פלאגין קלט תואם וקובץ הגדרות. Fluent Bit הוא מעבד יומנים ומשגר בפלטפורמות שונות בקוד פתוח, שמשתמש בפלאגינים של קלט ופלט כדי לטפל בסוגים שונים של מקורות נתונים ויעדים.
הפלאגין הזה תומך בפעולות הבאות:
- סמנטיקה של 'לפחות פעם אחת' באמצעות סוג ברירת המחדל.
- סמנטיקה של בדיוק פעם אחת באמצעות סוג הנתונים committed.
- שינוי גודל דינמי של הזרמים שמוגדרים כברירת מחדל, כשמוצגת אינדיקציה של לחץ חוזר.
מדדי פרויקט של Storage Write API
כדי לעקוב אחרי מדדים של הטמעת נתונים באמצעות Storage Write API, אפשר להשתמש בINFORMATION_SCHEMA.WRITE_API_TIMELINE view או לעיין במדדים שלGoogle Cloud .
שימוש בשפת טיפול בנתונים (DML) עם נתונים שהוזרמו לאחרונה
אתם יכולים להשתמש בשפת טיפול בנתונים (DML), כמו הפקודות UPDATE, DELETE או MERGE, כדי לשנות שורות שנכתבו לאחרונה בטבלת BigQuery באמצעות BigQuery Storage Write API. פעולות כתיבה מהזמן האחרון הן פעולות שהתרחשו ב-30 הדקות האחרונות.
למידע נוסף על שימוש ב-DML כדי לשנות את הנתונים שמוזרמים, אפשר לעיין במאמר בנושא שימוש בשפת טיפול בנתונים.
מגבלות
- התמיכה בהרצת הצהרות DML לשינוי נתונים שהועברו לאחרונה באמצעות סטרימינג לא חלה על נתונים שהועברו באמצעות סטרימינג באמצעות insertAll streaming API.
- אין תמיכה בהרצת הצהרות DML משנות בתוך טרנזקציה עם כמה הצהרות על נתונים שהועברו לאחרונה בסטרימינג.
מכסות של Storage Write API
מידע על המכסות והמגבלות של Storage Write API זמין במאמר מכסות ומגבלות של BigQuery Storage Write API.
אתם יכולים לעקוב אחרי השימוש במכסות של חיבורים בו-זמניים ושל קצב העברת הנתונים בGoogle Cloud דף המכסות במסוף.
חישוב התפוקה
נניח שהמטרה שלכם היא לאסוף יומנים מ-100 מיליון נקודות קצה
ולצור 1,500 רשומות יומן בדקה. אחר כך אפשר לאמוד את קצב העברת הנתונים באמצעות הנוסחה
100 million * 1,500 / 60 seconds = 2.5 GB per second.
צריך לוודא מראש שיש לכם מכסת שימוש מספקת כדי להציג את קצב העברת הנתונים הזה.
תמחור של Storage Write API
למידע על תמחור, ראו תמחור של הטמעת נתונים.
תרחיש שימוש לדוגמה
נניח שיש פייפליין לעיבוד נתוני אירועים מיומני נקודות קצה. האירועים נוצרים באופן רציף וצריכים להיות זמינים להרצת שאילתות ב-BigQuery בהקדם האפשרי. עדכניות הנתונים היא קריטית לתרחיש השימוש הזה, ולכן Storage Write API היא הבחירה הטובה ביותר להטמעת נתונים ב-BigQuery. ארכיטקטורה מומלצת לשמירה על יעילות נקודות הקצה האלה היא שליחת אירועים ל-Pub/Sub, שממנו הם נצרכים על ידי צינור Dataflow לסטרימינג שמעביר אותם ישירות ל-BigQuery.
הבעיה העיקרית באמינות של הארכיטקטורה הזו היא איך להתמודד עם מצב שבו לא מצליחים להוסיף רשומה ל-BigQuery. אם כל רשומה חשובה ואי אפשר לאבד אותה, צריך לשמור את הנתונים במאגר זמני לפני שמנסים להוסיף אותם. בארכיטקטורה המומלצת שלמעלה, Pub/Sub יכול לשמש כמאגר נתונים זמני הודות ליכולות שימור ההודעות שלו. צריך להגדיר את צינור הנתונים של Dataflow כך שינסה שוב להזין זרם נתונים ב-BigQuery באמצעות השהיה אקספוננציאלית קטומה. אחרי שהקיבולת של Pub/Sub כמאגר זמני מוצתה, למשל במקרה של זמינות ממושכת של BigQuery או של כשל ברשת, צריך לשמור את הנתונים בלקוח, והלקוח צריך מנגנון להמשך הוספת רשומות שנשמרו אחרי שהזמינות משוחזרת. מידע נוסף על אופן הטיפול במצב הזה זמין בפוסט בבלוג מדריך האמינות של Google Pub/Sub.
מקרה כשל נוסף שצריך לטפל בו הוא רשומה פגומה. רשומת poison היא רשומה שנדחתה על ידי BigQuery כי לא ניתן להוסיף אותה בגלל שגיאה שלא ניתן לנסות שוב לתקן אותה, או רשומה שלא נוספה בהצלחה אחרי מספר הניסיונות המקסימלי. שני סוגי הרשומות צריכים להישמר בתור של הודעות שלא נמסרו על ידי צינור הנתונים של Dataflow לצורך בדיקה נוספת.
אם נדרשת סמנטיקה של בדיוק פעם אחת, צריך ליצור זרם כתיבה בסוג מחויב, עם היסטים של רשומות שסופקו על ידי הלקוח. כך נמנעים כפילויות, כי פעולת הכתיבה מתבצעת רק אם ערך ההיסט תואם להיסט הבא של הוספת הנתונים. אם לא מציינים היסט, הרשומות מצורפות לסוף הנוכחי של הזרם, וניסיון חוזר לצרף רשומה שנכשל עלול לגרום להופעת הרשומה יותר מפעם אחת בזרם.
אם לא נדרשות ערבויות של 'פעם אחת בדיוק', כתיבה לזרם ברירת המחדל מאפשרת תפוקה גבוהה יותר, וגם לא נספרת במסגרת מגבלת המכסה על יצירת זרמי כתיבה.
הערכה של תפוקת הרשת צריך לוודא מראש שיש לכם מכסה מספקת כדי להכניס לשימוש בסביבת הייצור את התפוקה.
אם עומס העבודה שלכם יוצר או מעבד נתונים בקצב לא אחיד, כדאי לנסות להחליק את העליות החדות בעומס בצד הלקוח ולשדר ל-BigQuery עם תפוקה קבועה. כך תוכלו לפשט את תכנון הקיבולת. אם זה לא אפשרי, חשוב לוודא שאתם מוכנים לטפל בשגיאות 429 (המשאבים מוצו) אם וברגע שקצב העברת הנתונים יעלה על המכסה במהלך עליות קצרות.
דוגמה מפורטת לשימוש ב-Storage Write API מופיעה במאמר בנושא הזרמת נתונים באמצעות Storage Write API.
המאמרים הבאים
- הזרמת נתונים באמצעות Storage Write API
- טעינת נתונים באצווה באמצעות Storage Write API
- סוגי נתונים נתמכים של Protocol Buffer ו-Arrow
- שיטות מומלצות ל-Storage Write API