
המחבר spark-bigquery-connector משמש עם Apache Spark לקריאה ולכתיבה של נתונים מ-BigQuery ואליו. המחבר משתמש ב-BigQuery Storage API כשקוראים נתונים מ-BigQuery.
במדריך הזה מוסבר על הזמינות של המחבר שהותקן מראש, ומוצגות הוראות להפיכת גרסה ספציפית של מחבר לזמינה לעבודות Spark. בדוגמת הקוד אפשר לראות איך משתמשים במחבר Spark BigQuery באפליקציית Spark.
שימוש במחבר שמותקן מראש
מחבר Spark BigQuery מותקן מראש וזמין למשימות Spark שמופעלות באשכולות Managed Service for Apache Spark שנוצרו עם גרסאות תמונה 2.1 ואילך. גרסת המחבר שמותקנת מראש מופיעה בדפי הגרסאות של תמונת המערכת.
הפיכת גרסה ספציפית של מחבר לזמינה לעבודות Spark
אם רוצים להשתמש בגרסה של מחבר ששונה מגרסה שהותקנה מראש באשכול של גרסת תמונה 2.1 ומעלה, או אם רוצים להתקין את המחבר באשכול של גרסת תמונה שקודמת ל-2.1, צריך לפעול לפי ההוראות שבקטע הזה.
חשוב: גרסה spark-bigquery-connector צריכה להיות תואמת לגרסת תמונת האשכול של Managed Service for Apache Spark. אפשר לעיין בטבלת התאימות של תמונות המחבר ל-Managed Service for Apache Spark.
אשכולות של גרסאות תמונות מ-2.1 ואילך
כשיוצרים אשכול Managed Service for Apache Spark עם גרסת תמונה 2.1 ואילך, צריך לציין את גרסת המחבר כמטא-נתונים של האשכול.
דוגמה ל-CLI של gcloud:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
הערות:
SPARK_BQ_CONNECTOR_VERSION: ציון גרסת מחבר. גרסאות של מחבר Spark BigQuery מפורטות בדף spark-bigquery-connector/releases ב-GitHub.
דוגמה:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL: מציינים כתובת URL שמפנה לקובץ ה-JAR ב-Cloud Storage. אפשר לציין את כתובת ה-URL של מחבר שמופיע בעמודה link בקטע Downloading and Using the Connector ב-GitHub, או את הנתיב למיקום ב-Cloud Storage שבו שמרתם קובץ jar של מחבר מותאם אישית.
דוגמאות:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
2.0 וקלאסטרים של גרסאות קודמות של תמונות
אפשר להשתמש במחבר Spark BigQuery באפליקציה באחת מהדרכים הבאות:
כדי להתקין את spark-bigquery-connector בספריית ה-JAR של Spark בכל צומת, משתמשים בפעולת האתחול של Managed Service for Apache Spark connectors כשיוצרים את האשכול.
כששולחים את העבודה לאשכול באמצעות Google Cloud המסוף, gcloud CLI או Managed Service for Apache Spark API, צריך לספק את כתובת ה-URL של קובץ ה-JAR של המחבר.
המסוף
משתמשים בפריט Jars files (קבצי JAR) במשימת Spark בדף Submit a job (שליחת משימה) של Managed Service for Apache Spark.
gcloud
API
משתמשים בשדה
SparkJob.jarFileUris.איך מציינים את קובץ ה-JAR של המחבר כשמריצים משימות Spark באשכולות של גרסת תמונה ישנה יותר מ-2.0
- מציינים את קובץ ה-JAR של המחבר על ידי החלפת המידע על גרסת המחבר ו-Scala במחרוזת ה-URI הבאה:
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- שימוש ב-Scala
2.12עם גרסאות תמונות של Managed Service for Apache Spark1.5+gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- שימוש ב-Scala
2.11עם גרסאות תמונת Managed Service for Apache Spark1.4וגרסאות קודמות:gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- מציינים את קובץ ה-JAR של המחבר על ידי החלפת המידע על גרסת המחבר ו-Scala במחרוזת ה-URI הבאה:
כוללים את קובץ ה-jar של המחבר באפליקציית Scala או Java Spark כתלות (ראו קומפילציה מול המחבר).
חישוב העלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
- Managed Service for Apache Spark
- BigQuery
- Cloud Storage
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
קריאה וכתיבה של נתונים מ-BigQuery ואליו
בדוגמה הזו, הנתונים נקראים מ-BigQuery לתוך Spark DataFrame כדי לבצע ספירת מילים באמצעות API של מקור נתונים סטנדרטי.
המחבר כותב את הנתונים ל-BigQuery על ידי אחסון כל הנתונים בטבלה זמנית ב-Cloud Storage. לאחר מכן, המערכת מעתיקה את כל הנתונים אל BigQuery בפעולה אחת. המחבר מנסה למחוק את הקבצים הזמניים אחרי שפעולת הטעינה של BigQuery מצליחה, ושוב כשאפליקציית Spark מסתיימת.
אם העבודה נכשלת, מסירים את כל הקבצים הזמניים שנותרו ב-Cloud Storage. בדרך כלל, קבצים זמניים של BigQuery נמצאים בתיקייה gs://[bucket]/.spark-bigquery-[jobid]-[UUID].
הגדרת חיוב
כברירת מחדל, הפרויקט שמשויך לפרטי הכניסה או לחשבון השירות מחויב על השימוש ב-API. כדי לחייב פרויקט אחר, מגדירים את ההגדרה הבאה: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
אפשר גם להוסיף אותו לפעולת קריאה או כתיבה, באופן הבא:
.option("parentProject", "<BILLED-GCP-PROJECT>").
הרצת הקוד
לפני שמריצים את הדוגמה הזו, צריך ליצור מערך נתונים בשם wordcount_dataset או לשנות את מערך הנתונים של הפלט בקוד למערך נתונים קיים ב-BigQuery בפרויקטGoogle Cloud .
משתמשים בפקודה bq כדי ליצור את wordcount_dataset:
bq mk wordcount_dataset
משתמשים בפקודה Google Cloud CLI כדי ליצור קטגוריה של Cloud Storage, שתשמש לייצוא ל-BigQuery:
gcloud storage buckets create gs://[bucket]
Scala
- בודקים את הקוד ומחליפים את placeholder [bucket] בקטגוריה של Cloud Storage שיצרתם קודם.
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- הרצת הקוד באשכול
- משתמשים ב-SSH כדי להתחבר לצומת הראשי של אשכול Managed Service for Apache Spark
master node
- נכנסים לדף Managed Service for Apache Spark Clusters במסוף Google Cloud ולוחצים על שם האשכול
 .
.
- בדף >פרטי האשכול, בוחרים בכרטיסייה 'מכונות וירטואליות'. אחר כך לוחצים על
SSHמשמאל לשם של הצומת הראשי של האשכול>
חלון דפדפן נפתח בספריית הבית שלכם בצומת הראשיConnected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- נכנסים לדף Managed Service for Apache Spark Clusters במסוף Google Cloud ולוחצים על שם האשכול
- יוצרים את
wordcount.scalaבאמצעות עורך הטקסטvi,vimאוnanoשהותקן מראש, ואז מדביקים את קוד Scala מתוך רשימת קוד Scala.nano wordcount.scala
- מפעילים את
spark-shellREPL.$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
- מריצים את wordcount.scala באמצעות הפקודה
:load wordcount.scalaכדי ליצור את הטבלהwordcount_outputב-BigQuery. ברשימת הפלט מוצגות 20 שורות מתוך הפלט של ספירת המילים. :load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
כדי לראות תצוגה מקדימה של טבלת הפלט, פותחים את הדףBigQuery, בוחרים את הטבלהwordcount_outputולוחצים על תצוגה מקדימה.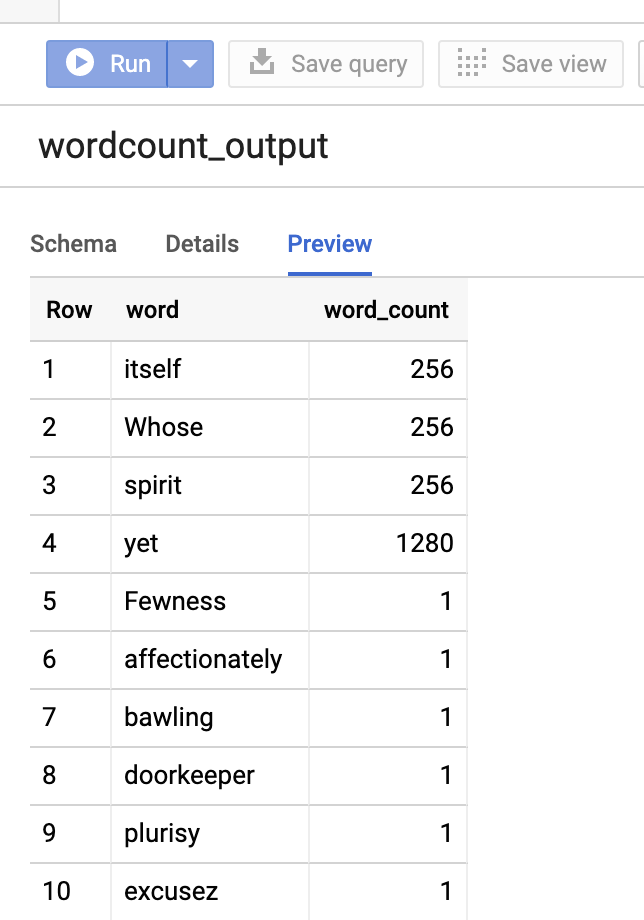
- משתמשים ב-SSH כדי להתחבר לצומת הראשי של אשכול Managed Service for Apache Spark
master node
PySpark
- בודקים את הקוד ומחליפים את placeholder [bucket] בקטגוריה של Cloud Storage שיצרתם קודם.
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- הפעלת הקוד באשכול
- שימוש ב-SSH כדי להתחבר לצומת הראשי של אשכול Managed Service for Apache Spark
- נכנסים לדף Managed Service for Apache Spark Clusters במסוף Google Cloud ולוחצים על שם האשכול .
- בדף פרטי האשכול, בוחרים בכרטיסייה 'מכונות וירטואליות'. אחר כך, לוחצים על
SSHמשמאל לשם של הצומת הראשי של האשכול
חלון דפדפן נפתח בספריית הבית שלכם בצומת הראשיConnected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- נכנסים לדף Managed Service for Apache Spark Clusters במסוף Google Cloud ולוחצים על שם האשכול
- יוצרים
wordcount.pyבאמצעות עורך הטקסטvi,vimאוnanoשהותקן מראש, ואז מדביקים את קוד PySpark מתוך רשימת קוד PySpark.nano wordcount.py
- מריצים את wordcount עם
spark-submitכדי ליצור את הטבלהwordcount_outputב-BigQuery. ברשימת הפלט מוצגות 20 שורות מפלט ספירת המילים. spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
כדי לראות תצוגה מקדימה של טבלת הפלט, פותחים את הדףBigQuery, בוחרים את הטבלהwordcount_outputולוחצים על תצוגה מקדימה.
- שימוש ב-SSH כדי להתחבר לצומת הראשי של אשכול Managed Service for Apache Spark
טיפים לפתרון בעיות
אפשר לבדוק את יומני העבודות ב-Cloud Logging ובכלי לבדיקת עבודות ב-BigQuery כדי לפתור בעיות בעבודות Spark שמשתמשות במחבר BigQuery.
יומני מנהלי ההתקנים של Managed Service for Apache Spark מכילים רשומה של
BigQueryClientעם מטא-נתונים של BigQuery שכוללים אתjobId:ClassNotFoundException
INFO BigQueryClient:.. jobId: JobId{project=PROJECT_ID, job=JOB_ID, location=LOCATION} משימות BigQuery מכילות תוויות
Managed Service for Apache Spark_job_idו-Managed Service for Apache Spark_job_uuid:- רישום ביומן:
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_id="JOB_ID" protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.labels.dataproc_job_uuid="JOB_UUID" protoPayload.serviceData.jobCompletedEvent.job.jobName.jobId="JOB_NAME"
- BigQuery Jobs Explorer: לוחצים על מזהה משימה כדי לראות את פרטי המשימה בקטע Labels (תוויות) ב-Job information (פרטי המשימה).
- רישום ביומן:
המאמרים הבאים
- מידע נוסף זמין במאמר BigQuery Storage & Spark SQL - Python.
- איך יוצרים קובץ הגדרת טבלה למקור נתונים חיצוני
- איך שולחים שאילתות לנתונים שחולקו למחיצות באופן חיצוני
- טיפים לשיפור ביצועים של משימות Spark