
Configurer la connectivité privée pour les transferts Snowflake
Ce guide vous explique comment configurer la connectivité privée pour créer des transferts de données privés de Snowflake vers BigQuery. Les transferts de données privés vous permettent de transférer des données d'une source à une autre au sein d'un réseau privé. Ils vous permettent également de réduire les risques de sécurité lorsque vous transférez des données sur l'Internet public.
Les sections suivantes décrivent les étapes requises pour configurer la connectivité privée avant de pouvoir créer un transfert Snowflake.
Les transferts privés sont compatibles avec les instances Snowflake hébergées sur Amazon Web Services (AWS), Microsoft Azure et Google Cloud.
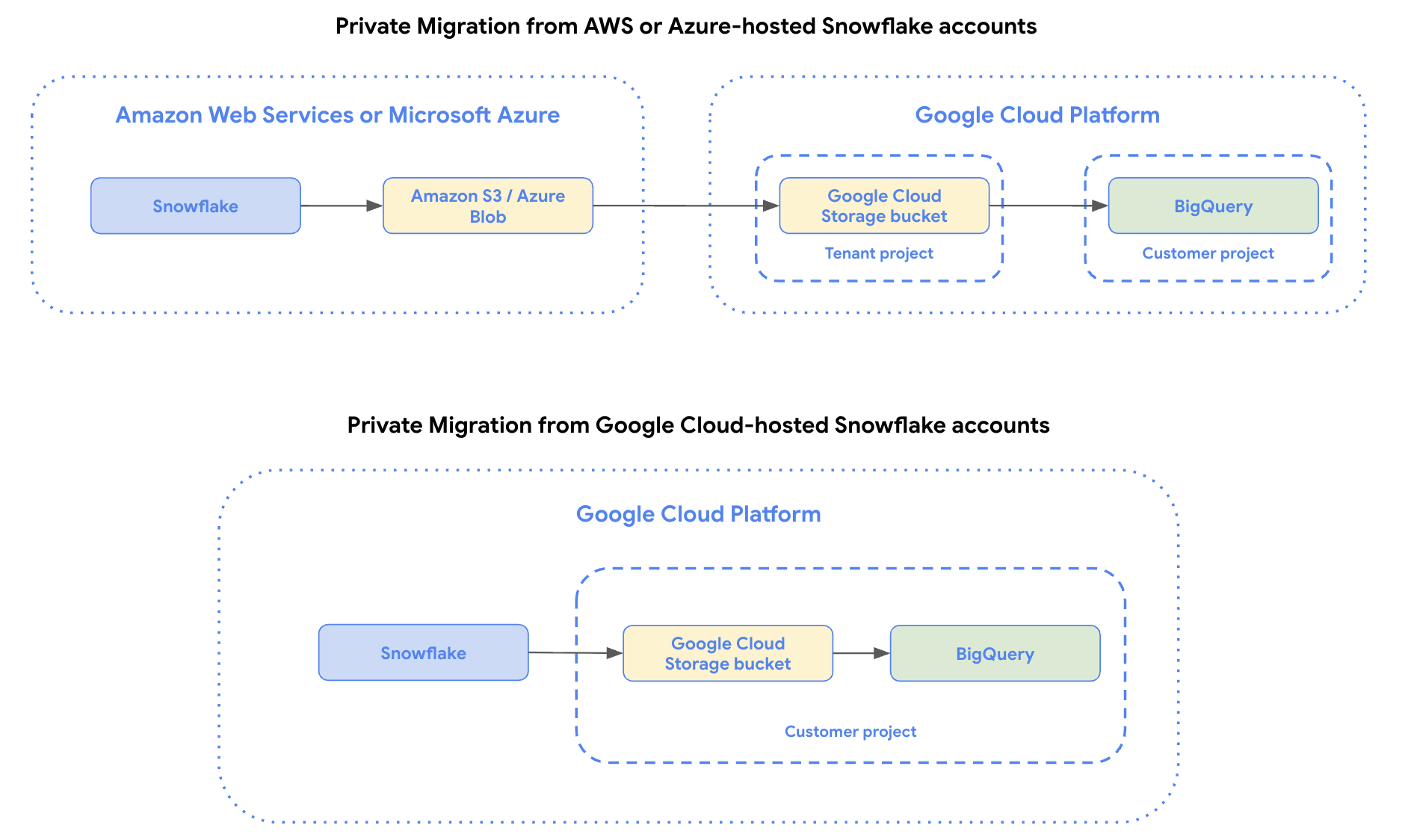
Créer un lien privé vers Snowflake
Créez un lien privé qui connecte votre compte Snowflake à votre fournisseur de services cloud. Pour en savoir plus, sélectionnez l'une des options suivantes :
AWS
Configurez AWS PrivateLink pour associer votre compte Snowflake à votre compte AWS. Votre compte AWS doit contenir le bucket de préparation Amazon S3 requis pour un transfert Snowflake.
Azure
Configurez Azure Private Link pour connecter votre réseau virtuel Azure (VNet) au réseau virtuel Snowflake dans Azure. Votre compte Azure doit contenir le bucket de staging Blob requis pour un transfert Snowflake.
Google Cloud
Configurez Google Cloud Private Service Connect pour connecter le sous-réseau de votre réseau de cloud privé virtuel (VPC) à votre compte Snowflake hébergé sur Google Cloud. VotreGoogle Cloud doit disposer d'un bucket Cloud Storage intermédiaire requis pour un transfert Snowflake.
Configurer interconnexion cross-cloud ou un VPN haute disponibilité
Configurez interconnexion cross-cloud ou un VPN haute disponibilité depuis AWS ou Azure. Cette étape n'est pas requise pour les comptes Snowflake hébergés surGoogle Cloud.
AWS
Un VPN haute disponibilité vous permet de transférer des données via un tunnel VPN chiffré. Pour utiliser un VPN haute disponibilité pour votre transfert Snowflake privé, consultez Créer des connexions VPN haute disponibilité entre Google Cloud et AWS.
Une connexion Cross-Cloud Interconnect crée une liaison privée dédiée entre les fournisseurs de services cloud. Elle est adaptée aux transferts de données volumineux nécessitant une faible latence. Pour utiliser interconnexion cross-cloud pour votre transfert Snowflake privé, consultez Se connecter à AWS.
Azure
Un VPN haute disponibilité vous permet de transférer des données via un tunnel VPN chiffré. Pour utiliser un VPN haute disponibilité pour votre transfert Snowflake privé, consultez Créer des connexions VPN haute disponibilité entre Google Cloud et Azure.
Une connexion Cross-Cloud Interconnect crée une liaison privée dédiée entre les fournisseurs de services cloud. Elle est adaptée aux transferts de données volumineux nécessitant une faible latence. Pour utiliser interconnexion cross-cloud pour votre transfert Snowflake privé, consultez Se connecter à Azure.
Créer une VM proxy
Pour établir une connexion privée, une VM proxy est nécessaire pour établir la connexion entre vos sources de données sans que vos données n'atteignent l'Internet public. Cette étape est requise pour les instances Snowflake hébergées sur AWS, Azure ou Google Cloud.
Pour créer et configurer une VM proxy pour un transfert Snowflake privé, procédez comme suit :
- Créez une ou plusieurs instances de VM Compute Engine dans le réseau VPC consommateur.
- Téléchargez un logiciel de proxy TCP, tel que HAProxy ou Nginx, et configurez les éléments suivants :
- Spécifiez un port. Par exemple,
443. - Transférez tout le trafic TCP entrant vers le nom d'hôte et le port privés de l'instance Snowflake.
- Spécifiez un port. Par exemple,
- Configurez les VM pour qu'elles résolvent le nom d'hôte privé Snowflake via le DNS configuré dans le réseau VPC consommateur.
- Configurez un équilibreur de charge passthrough interne en procédant comme suit :
Créer un rattachement de service
Utilisez Private Service Connect pour créer un rattachement réseau et publier le service. Cette étape est requise pour les instances Snowflake hébergées sur AWS, Azure ou Google Cloud.
Votre rattachement de service doit se trouver dans la même région que votre ensemble de données BigQuery.
Si votre service utilise l'approbation explicite (connection-preference est défini sur ACCEPT_MANUAL), le compte de service utilisé dans votre transfert de données privées Snowflake doit disposer des autorisations IAM suivantes :
compute.serviceAttachments.getcompute.serviceAttachments.updatecompute.regionOperations.get
Une fois le rattachement de service créé, notez son URI. Vous aurez besoin de cet URI lorsque vous créerez votre configuration de transfert Snowflake.
Créer un point de terminaison
Créez un point de terminaison dans votre compte AWS ou Azure. Cette étape n'est pas requise pour les comptes Snowflake hébergés surGoogle Cloud.
AWS
Dans AWS, créez un point de terminaison VPC qui se connecte à Amazon S3. Pour en savoir plus, consultez Accéder à un service AWS à l'aide d'un point de terminaison VPC d'interface.
Azure
Configurez un point de terminaison privé sur le compte de stockage dans Azure. Pour en savoir plus, consultez Utiliser des points de terminaison privés pour Azure Storage.
Le service de transfert de stockage nécessite le point de terminaison *.blob.core.microsoft.net. Le point de terminaison *.dfs.core.microsoft.net n'est pas accepté.
Une fois le point de terminaison créé, notez son adresse IP. Vous devrez spécifier l'adresse IP lorsque vous créerez votre équilibreur de charge dans la section suivante.
Créer un équilibreur de charge réseau
Configurez un équilibreur de charge réseau (NLB) proxy interne régional avec une connectivité hybride. Vous pouvez créer l'équilibreur de charge pour acheminer le trafic vers les points de terminaison VPC Amazon S3 ou les points de terminaison privés Azure Storage que vous avez créés dans la section précédente. Pour en savoir plus, consultez Configurer un équilibreur de charge réseau proxy interne régional avec une connectivité hybride.
Enregistrer votre NLB
Après avoir créé votre équilibreur de charge réseau, enregistrez-le dans l'annuaire des services du service de transfert de stockage. Pour en savoir plus, consultez Enregistrer votre équilibreur de charge réseau auprès de Service Directory.
Notez le lien vers l'annuaire des services. Vous aurez besoin du lien vers le service lorsque vous créerez votre configuration de transfert Snowflake.
Préparer le bucket de préproduction
Pour effectuer un transfert de données Snowflake, vous devez créer un bucket intermédiaire, puis le configurer pour autoriser l'accès en écriture depuis Snowflake.
Sélectionnez l'une des options suivantes :
AWS
Pour les comptes Snowflake hébergés sur AWS, créez un bucket Amazon S3 pour préparer les données Snowflake avant de les charger dans BigQuery.
Créez et configurez un objet d'intégration de stockage Snowflake pour permettre à Snowflake d'écrire des données dans le bucket Amazon S3 en tant qu'étape externe.
Pour autoriser l'accès en lecture à votre bucket Amazon S3, vous devez également effectuer les opérations suivantes :
Créez un utilisateur Amazon IAM dédié et accordez-lui la règle
AmazonS3ReadOnlyAccess.Créez une paire de clés d'accès Amazon pour l'utilisateur IAM.
Azure
Pour les comptes Snowflake hébergés sur Azure, créez un conteneur Azure Blob Storage pour préparer les données Snowflake avant de les charger dans BigQuery.
- Créez un compte de stockage Azure et un conteneur de stockage dans ce compte.
- Créez et configurez un objet d'intégration de stockage Snowflake pour permettre à Snowflake d'écrire des données dans le conteneur de stockage Azure en tant qu'étape externe. Vous pouvez ignorer les étapes de création d'un stage externe, car ce n'est pas obligatoire.
Pour autoriser l'accès en lecture à votre conteneur Azure, générez un jeton SAP pour celui-ci.
Google Cloud
Pour les comptes Snowflake hébergés sur Google Cloud, créez un bucket Cloud Storage pour préproduire les données Snowflake avant de les charger dans BigQuery.
- Créez un bucket Cloud Storage.
- Créez et configurez un objet d'intégration de stockage Snowflake pour permettre à Snowflake d'écrire des données dans le bucket Cloud Storage en tant qu'étape externe.
Pour autoriser l'accès au bucket intermédiaire, accordez le rôle
roles/storage.objectViewerà l'agent de service DTS à l'aide de la commande suivante :gcloud storage buckets add-iam-policy-binding gs://STAGING_BUCKET_NAME \ --member=serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com \ --role=roles/storage.objectViewer
Créer une configuration de transfert Snowflake privée
Créez le transfert Snowflake. Lorsque vous configurez la configuration du transfert, procédez comme suit :
Console
- Pour Utiliser un réseau privé, sélectionnez True.
- Dans le champ Rattachement de service PSC, saisissez l'URI du rattachement de service. Pour savoir comment trouver l'URI du rattachement de service, consultez Afficher les détails d'un service publié.
L'URI du rattachement de service est au format
projects/PROJECT_ID/regions/REGION/serviceAttachments/SERVICE_ATTACHMENT. - Pour Private Network Service, saisissez le lien auto du service NLB.
Il utilise le format
projects/PROJECT_ID/locations/LOCATION/namespaces/NAMESPACE/services/SERVICE_NAME. - URI du bucket intermédiaire que vous souhaitez utiliser pour le transfert :
- Pour un compte Snowflake hébergé sur AWS, un URI de bucket Amazon S3 est requis, ainsi que des identifiants d'accès.
- Pour un compte Snowflake hébergé sur Azure, un compte et un conteneur Azure Blob Storage sont requis.
- Pour un compte Snowflake hébergé surGoogle Cloud, un URI de bucket Cloud Storage est requis.
Pour Fournisseur de services cloud, sélectionnez
AWS,AZUREouGCPselon le fournisseur de services cloud qui héberge votre compte Snowflake.AWS
- Pour URI Amazon S3, saisissez l'URI du bucket Amazon S3 à utiliser comme bucket intermédiaire.
- Dans les champs ID de clé d'accès et Clé d'accès secrète, saisissez la paire de clés d'accès.
Azure
- Dans les champs Nom du compte de stockage Azure et Conteneur dans le compte de stockage Azure, saisissez le nom du compte de stockage et du conteneur Azure Blob Storage à utiliser comme bucket intermédiaire.
- Dans le champ Jeton SAP, saisissez le jeton SAP généré pour le conteneur.
Google Cloud
- Pour URI GCS, saisissez l'URI Cloud Storage à utiliser comme bucket intermédiaire.
bq
- Pour le paramètre
use_private_network, définissez la valeur surTRUE. - Pour le paramètre
service_attachment, spécifiez l'URI du rattachement de service. Pour savoir comment trouver l'URI du rattachement de service, consultez Afficher les détails d'un service publié. L'URI du rattachement de service est au formatprojects/PROJECT_ID/regions/REGION/serviceAttachments/SERVICE_ATTACHMENT. - Pour le paramètre
private_network_service, fournissez le lien autonome du service NLB. Il utilise le formatprojects/PROJECT_ID/locations/LOCATION/namespaces/NAMESPACE/services/SERVICE_NAME. cloud_provider: saisissezAWS,AZUREouGCPselon le fournisseur de services cloud qui héberge votre compte Snowflake.staging_s3_uri: saisissez l'URI du bucket S3 à utiliser comme bucket intermédiaire. Obligatoire uniquement lorsque votrecloud_providerest défini surAWS.aws_access_key_id: saisissez la paire de clés d'accès. Obligatoire uniquement lorsque votrecloud_providerest défini surAWS.aws_secret_access_key: saisissez la paire de clés d'accès. Obligatoire uniquement lorsque votrecloud_providerest défini surAWS.azure_storage_account: saisissez le nom du compte de stockage à utiliser comme bucket intermédiaire. Obligatoire uniquement lorsque votrecloud_providerest défini surAZURE.staging_azure_container: saisissez le conteneur dans Azure Blob Storage à utiliser comme bucket intermédiaire. Obligatoire uniquement lorsque votrecloud_providerest défini surAZURE.azure_sas_token: saisissez le jeton SAS. Obligatoire uniquement lorsque votrecloud_providerest défini surAZURE.staging_gcs_uri: saisissez l'URI Cloud Storage à utiliser comme bucket intermédiaire. Obligatoire uniquement lorsque votrecloud_providerest défini surGCP.