
이 튜토리얼에서는 Colab Enterprise 데이터 과학 에이전트를 사용하여 자연어 프롬프트로 머신러닝 (ML) 모델을 빌드하는 방법을 보여줍니다.
이 튜토리얼에서는 아이오와주 주류 소매 판매 공개 데이터 세트를 사용하여 주류 판매를 예측하는 ML 모델을 빌드합니다. AI 기반 에이전트를 사용하면 자연어 프롬프트를 사용하여 노트북 내에서 직접 코드를 작성, 설명, 문제 해결하여 데이터 과학 워크플로를 가속화할 수 있습니다.
이 튜토리얼은 데이터 실무자를 대상으로 합니다.
목표
이 튜토리얼에서는 데이터 과학 에이전트를 사용하여 다음 작업을 수행하는 방법을 알아봅니다.
- 아이오와 주류 소매 판매 공개 데이터 세트에 대한 탐색적 데이터 분석 (EDA)을 수행하여 데이터 분포를 파악하고, 누락된 값을 확인하고, 전반적인 데이터 품질을 검증합니다.
- 모든 제품에서 가장 많은 갤런의 알코올을 판매한 매장을 찾습니다.
- BigQuery ML을 사용하여 주류 판매를 예측하는 모델을 빌드, 학습, 평가합니다.
- 주요 통계와 모델 성능을 생성하고 요약합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
BigQuery, Gemini for Google Cloud, Dataform, Compute Engine API를 사용 설정합니다.
API 사용 설정에 필요한 역할
API를 사용 설정하려면
serviceusage.services.enable권한이 포함된 서비스 사용량 관리자 IAM 역할(roles/serviceusage.serviceUsageAdmin)이 필요합니다. 역할 부여 방법 알아보기새 프로젝트에서는 BigQuery API가 자동으로 사용 설정됩니다.
필요한 역할
새 프로젝트를 만든 경우 이 튜토리얼을 완료하는 데 필요한 모든 권한이 있습니다. 기존 프로젝트를 사용하는 경우 관리자에게 다음 역할을 부여해 달라고 요청하세요.
노트북을 만들고 실행할 수 있는 권한
노트북을 만들고 실행하는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대한 BigQuery Studio 사용자 (roles/bigquery.studioUser) IAM 역할을 부여해 달라고 요청하세요.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
노트북을 만들고 실행하는 데 필요한 권한을 보려면 노트북 만들기 페이지의 설정 단계를 참고하세요.
BigQuery Identity and Access Management(IAM)에 대한 자세한 내용은 IAM으로 액세스 제어를 참조하세요.
Colab Enterprise 노트북을 만들고 런타임에 연결하기
Colab Enterprise 노트북은 Dataform으로 구동되는 BigQuery Studio 코드 애셋입니다. 노트북을 사용하여 SQL, Python, 기타 일반적인 패키지 및 API로 분석 및 ML 워크플로를 완료할 수 있습니다.
새 노트북을 만들고 기본 런타임에 연결하려면 다음 단계를 따르세요.
BigQuery 페이지로 이동합니다.
왼쪽 창에서 프로젝트를 펼친 다음 Notebooks를 클릭합니다.
새 노트북 > 빈 노트북을 클릭합니다.
저장을 클릭합니다.
새 노트북을 보려면 노트북 탭을 클릭합니다. 새로고침 새로고침을 클릭해야 할 수도 있습니다 .
제목이 없는 노트북에서 more_vert 작업 열기를 클릭한 다음 이름 변경을 선택합니다.
노트북 이름에
predict_liquor_sales을 입력한 후 이름 바꾸기를 클릭합니다.predict_liquor_sales탭을 클릭합니다.노트북 툴바에서 연결을 클릭하여 노트북을 기본 런타임 환경에 연결합니다.
데이터 과학 에이전트를 사용하여 데이터 분석
데이터 과학 에이전트는 노트북 내에서 직접 코드를 작성하고 설명하며 문제를 해결할 수 있는 Gemini 기반 어시스턴트입니다. 탐색적 데이터 분석부터 머신러닝 예측 및 예측 생성에 이르기까지 다양한 작업을 지원하며, 그 예는 다음과 같습니다.
- 계획 생성: 데이터 과학 문제를 해결하기 위한 단계별 계획을 만듭니다.
- 데이터 탐색 및 정리. 누락된 값과 이상치를 식별하고 분포를 시각화합니다.
- 특성 추출 범주형 특성을 변환하고 새 범주형 특성을 만듭니다.
- 모델 학습 및 평가 선형 회귀 또는 랜덤 포레스트와 같은 모델을 학습시키고 성능을 비교합니다.
이 튜토리얼에서는 데이터 과학 에이전트를 사용하여 아이오와 주류 소매 판매 공개 데이터 세트의 데이터를 분석하고 주류 판매를 예측하는 모델을 만듭니다.
데이터 과학 에이전트를 사용하여 데이터를 분석하려면 다음 단계를 따르세요.
predict_liquor_sales노트북에서 Gemini 채팅 창이 열려 있지 않으면 spark Colab에서 Gemini 전환을 클릭하여 채팅 대화상자를 엽니다.채팅 인터페이스에 다음 프롬프트를 입력합니다.
Analyze the liquor sales data from bigquery-public-data.iowa_liquor_sales.sales by performing exploratory data analysis. Find the stores that sold the most gallons of alcohol across all products. Then, create a model that predicts liquor sales by store by using BigQuery ML. Visualize the results, evaluate the model, summarize the model's performance, and provide any key insights.모델이 Gemini 3.0 Flash로 설정되어 있는지 확인합니다.
보내기를 클릭합니다.
에이전트가 생성한 계획을 검토합니다. 계획은 다음과 유사합니다.
'아이오와 주류 판매 데이터 요청을 분석하여 전략 계획을 수립했습니다. 데이터가 BigQuery에 저장되어 있고 BigQuery ML을 사용하도록 지정했으므로 데이터 탐색부터 시작하여 실적이 가장 우수한 매장을 식별한 다음 회귀 모델을 빌드하여 매출을 예측합니다. 단계별 계획은 다음과 같습니다.
- 데이터 탐색 및 프로파일링: 'bigquery-public-data.iowa_liquor_sales.sales' 테이블을 초기 탐색하여 데이터 분포를 파악하고, 누락된 값을 확인하고, 매장 정보, 판매량, 판매액과 같은 주요 열의 데이터 품질을 확인합니다.
- 판매량 기준 상위 매장 식별: 모든 제품에서 각 매장이 판매한 총 알코올 갤런을 집계하고 실적이 가장 우수한 매장을 식별합니다.
- 데이터 준비: 매장별 주류 판매를 집계하고 예측 모델에 적합한 기능을 선택하여 학습 데이터를 준비합니다.
- 모델 개발: BigQuery ML을 사용하여 각 매장의 주류 판매량을 예측하는 회귀 모델을 학습시킵니다.
- 모델 평가: 표준 회귀 측정항목을 사용하여 학습된 모델의 성능을 평가합니다.
- 모델 예측: 학습된 모델을 사용하여 주류 판매 예측을 생성합니다.
- 시각화: 예측된 주류 판매량과 실제 값을 비교하는 분산형 차트를 만들어 모델의 정확성을 시각적으로 평가합니다.
- 작업 완료: 모델의 실적을 요약하고, 매장 판매에 관한 주요 통계를 제공하고, 분석을 마무리해 줘."
계획을 검토한 후 수락 및 실행을 클릭합니다. 에이전트가 데이터 탐색 및 프로파일링이라는 첫 번째 하위 작업을 생성합니다. 코드를 검토하고 수락할 때까지 에이전트가 일시중지됩니다. 상담사가 사용자 입력을 기다리는 경우 생성된 셀은 녹색 배경으로 렌더링됩니다.
생성된 코드 셀과 에이전트가 제공한 추론을 검토합니다.
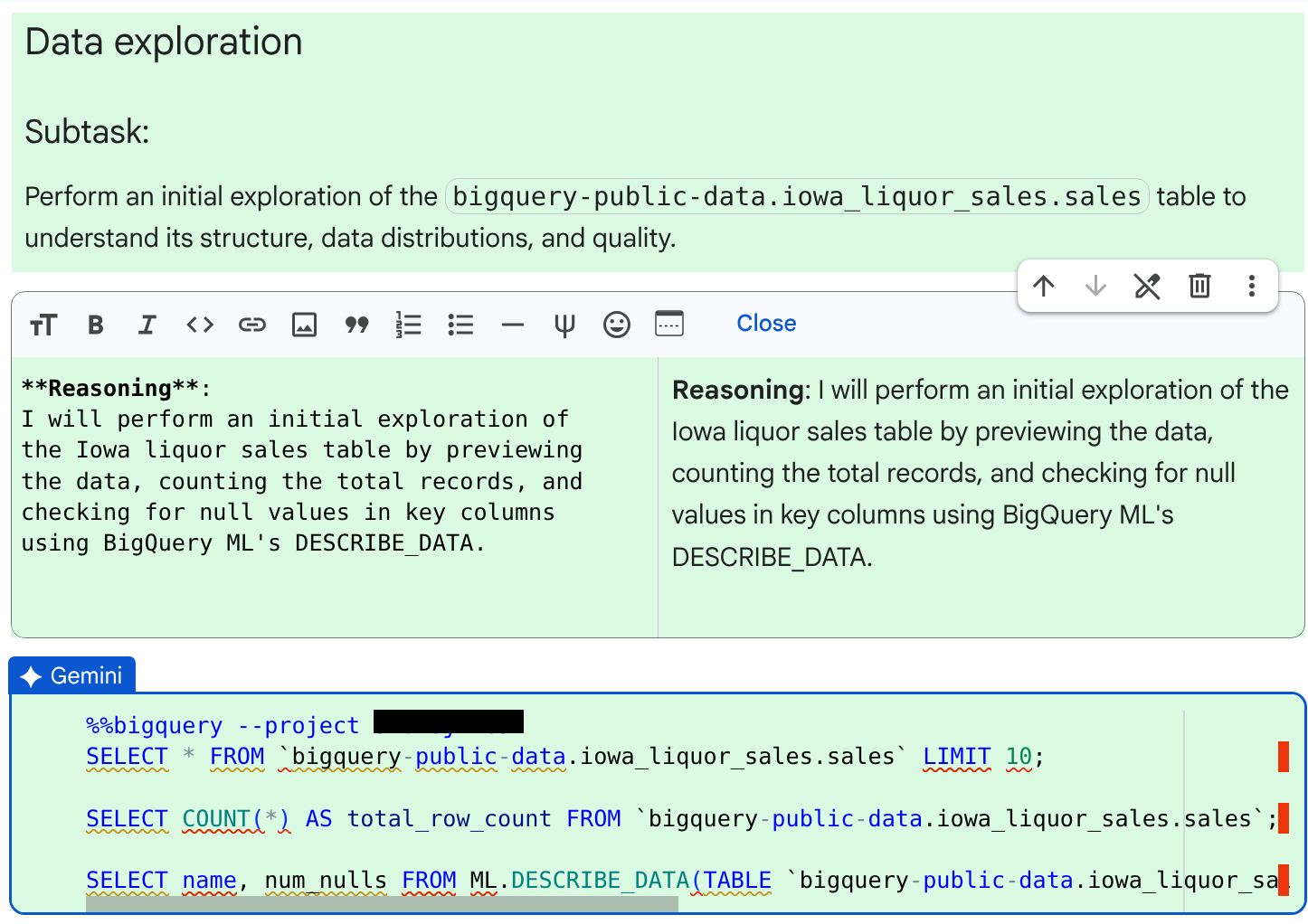
수락 및 실행을 클릭합니다. 에이전트의 접근 방식에 문제가 있는 경우 문제를 수정하는 방법에 관한 추론을 제공하고 변경된 코드를 수락하라는 메시지를 표시합니다.
코드 셀의 출력을 검토합니다.
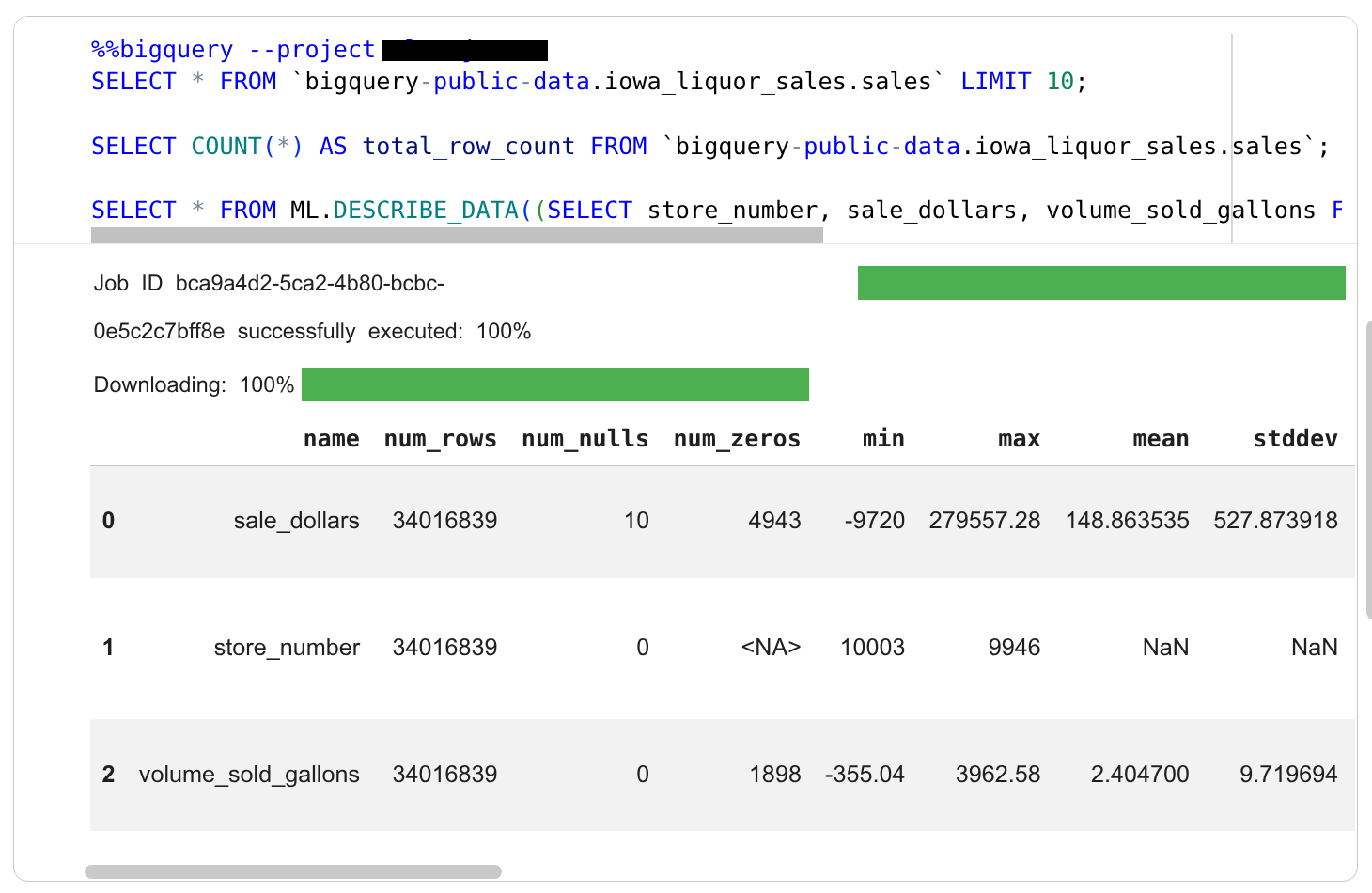
결과 아래에 에이전트가 다음 하위 작업을 완료하기 위해 새 셀을 만듭니다. 주류 판매량이 가장 높은 매장을 찾는 것입니다.
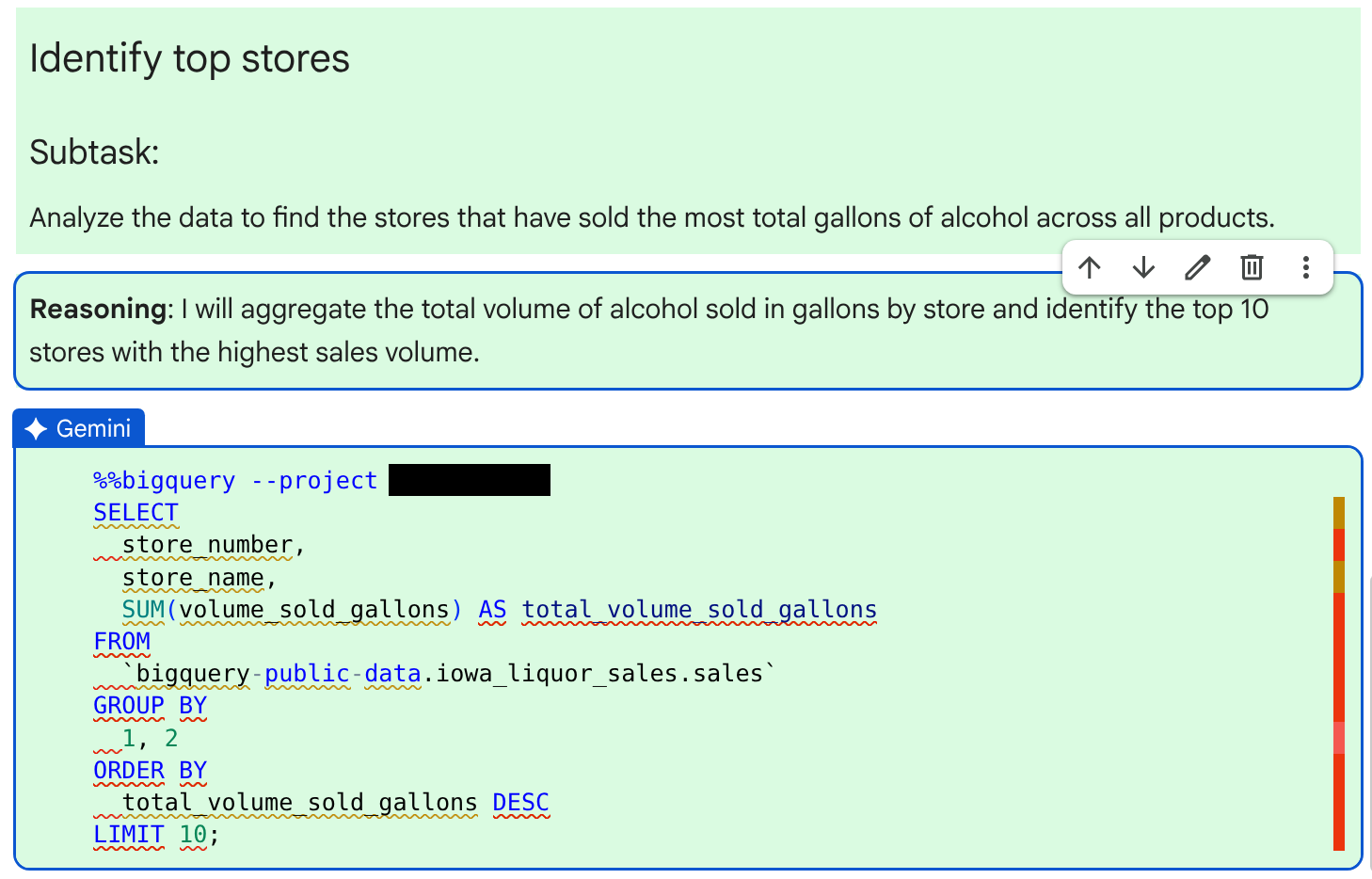
판매된 알코올 양을 기준으로 상위 매장의 데이터를 쿼리하는 생성된 SQL 코드를 검토합니다. 코드 위의 Reasoning 텍스트 셀을 확인하여 에이전트의 추론을 검토할 수 있습니다. 코드가 올바르다고 판단되면 수락 및 실행을 클릭합니다.
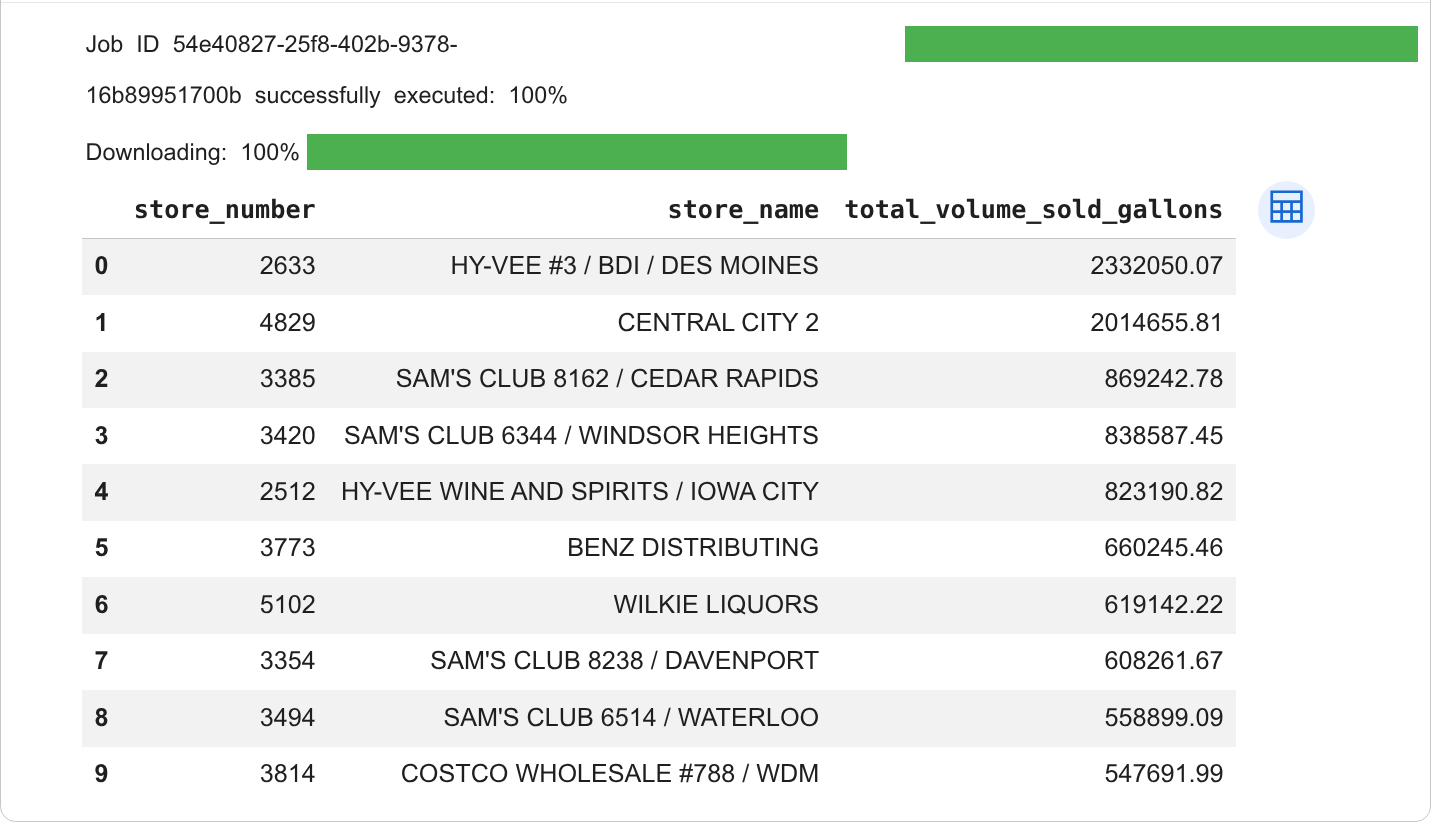
셀의 출력에서 쿼리 결과를 살펴봅니다. 결과는 다음과 비슷합니다.
다음 하위 작업인 모델 학습을 위한 데이터 준비를 위해 에이전트가 생성한 코드와 추론을 검토합니다.
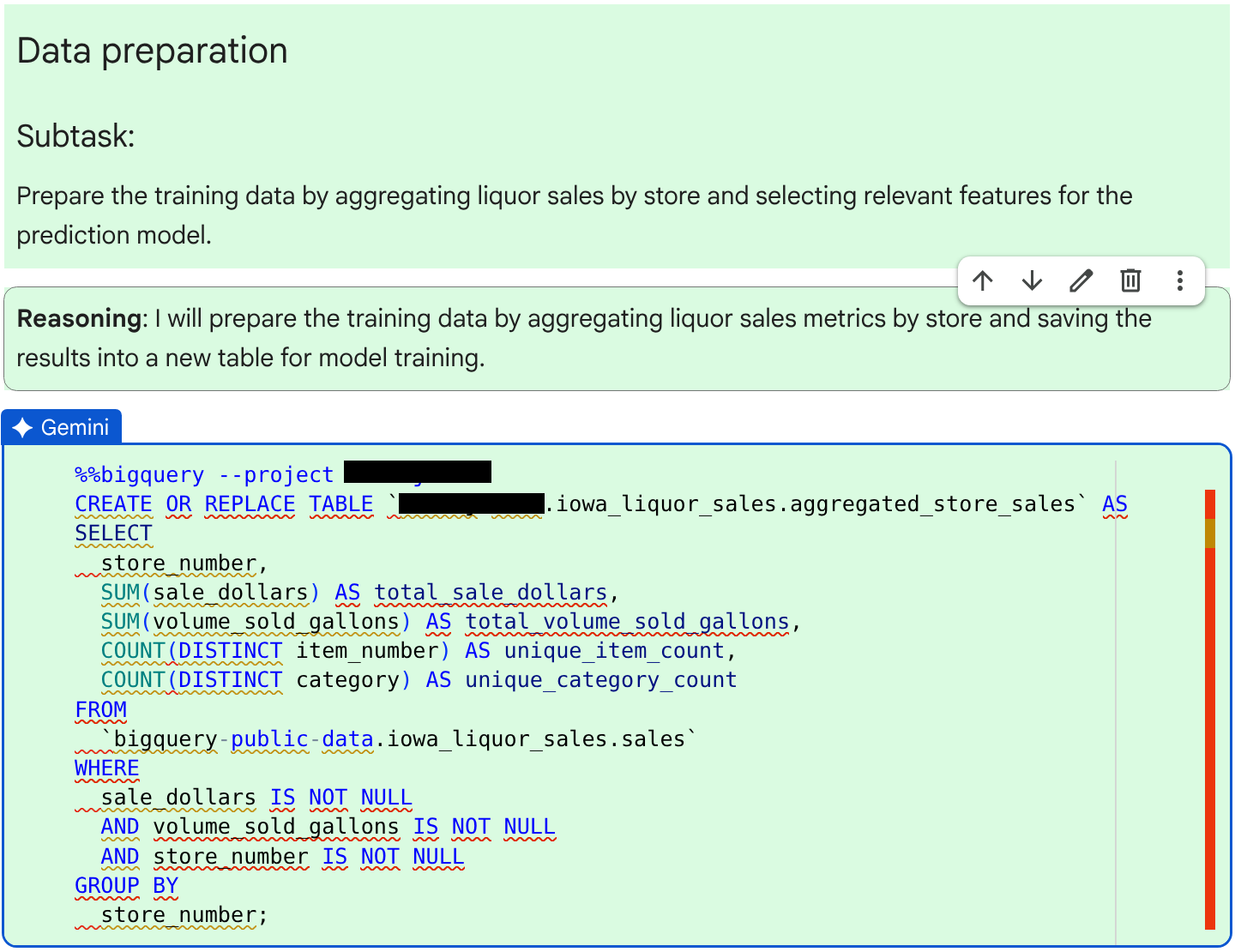
SQL 코드가 올바른지 확인한 후 수락 및 실행을 클릭합니다.
코드 셀의 출력을 검토합니다. 다음과 유사한 메시지가 표시됩니다.
JOB ID 123456 successfully executed.다음 하위 작업인 회귀 모델 학습을 위해 에이전트가 생성한 코드와 추론을 검토합니다.
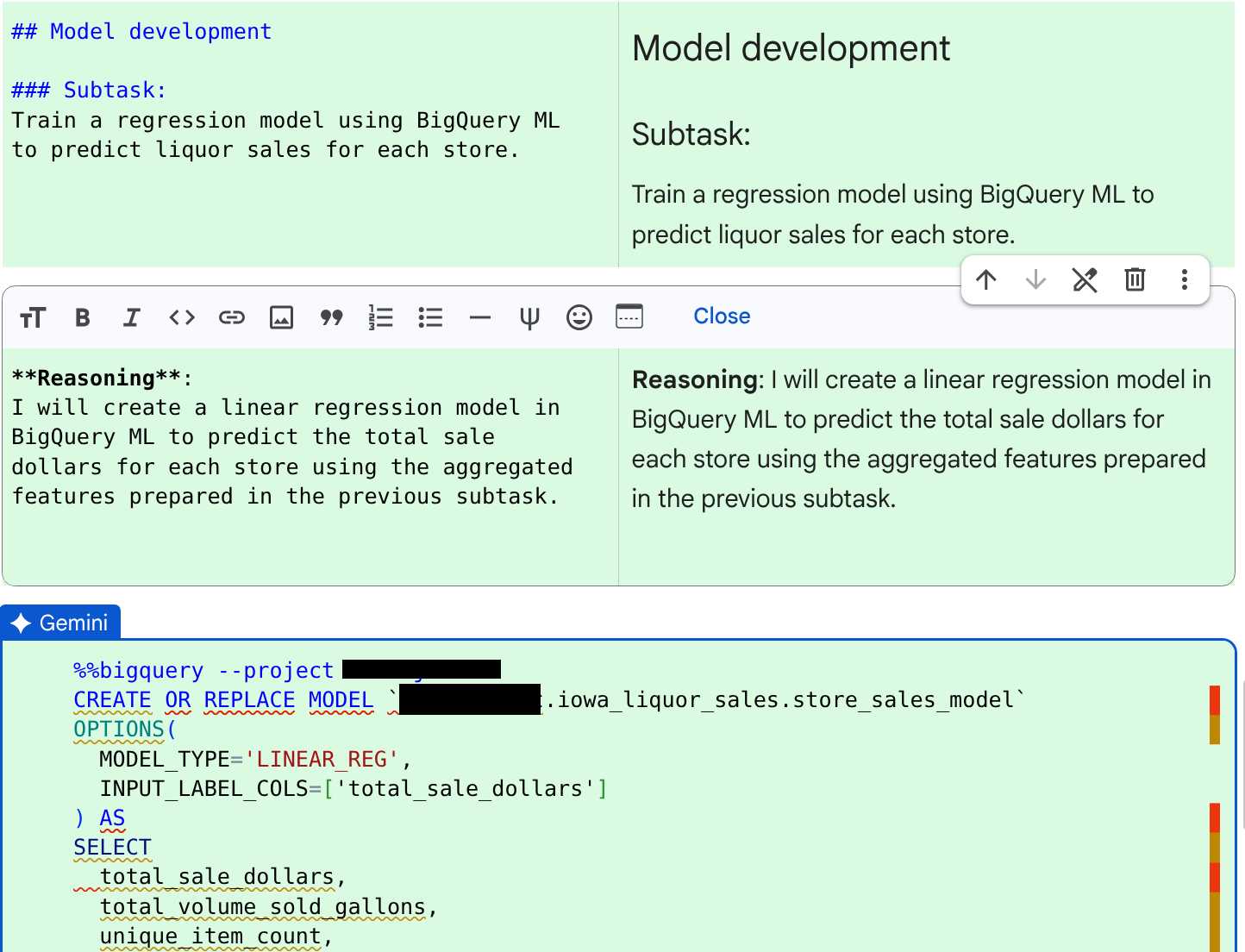
코드와 이유를 확인한 후 수락 및 실행을 클릭합니다.
코드 셀의 출력을 검토합니다. 다음과 유사한 메시지가 표시됩니다.
JOB ID 123456 successfully executed.다음 하위 작업인 모델 평가를 위해 에이전트가 생성한 코드와 추론을 검토합니다.
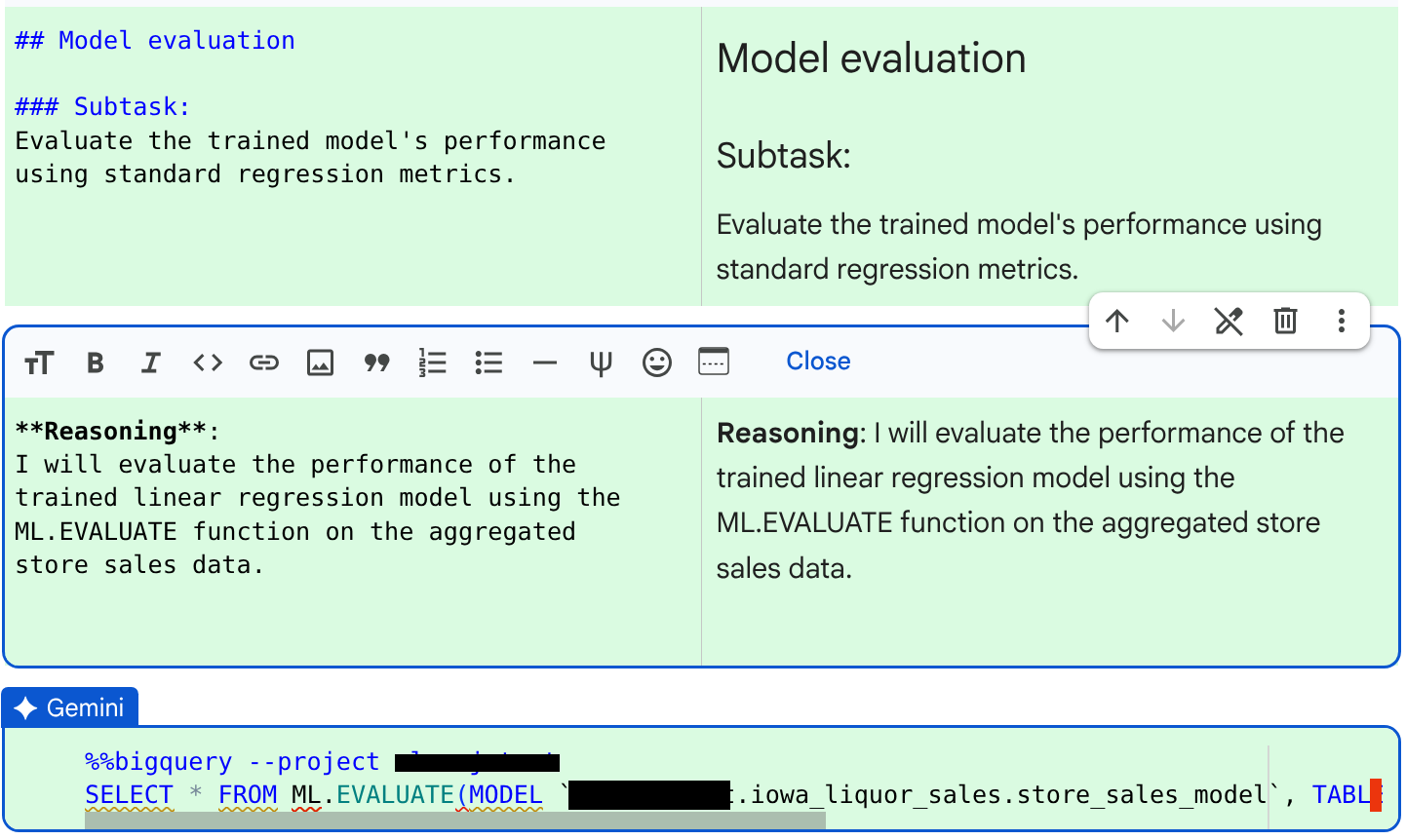
코드와 이유를 확인한 후 수락 및 실행을 클릭합니다.
코드 셀의 출력을 검토합니다.
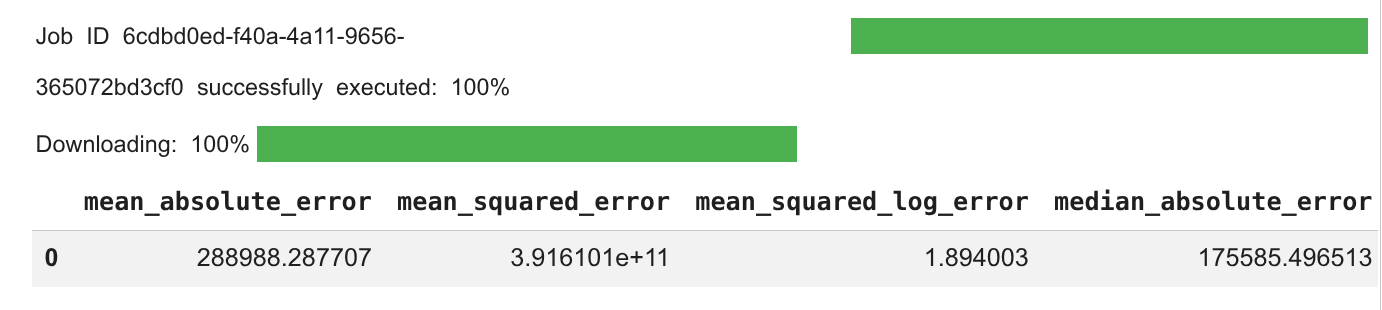
다음 하위 작업인 예측 생성에 대해 에이전트가 생성한 코드와 추론을 검토합니다.
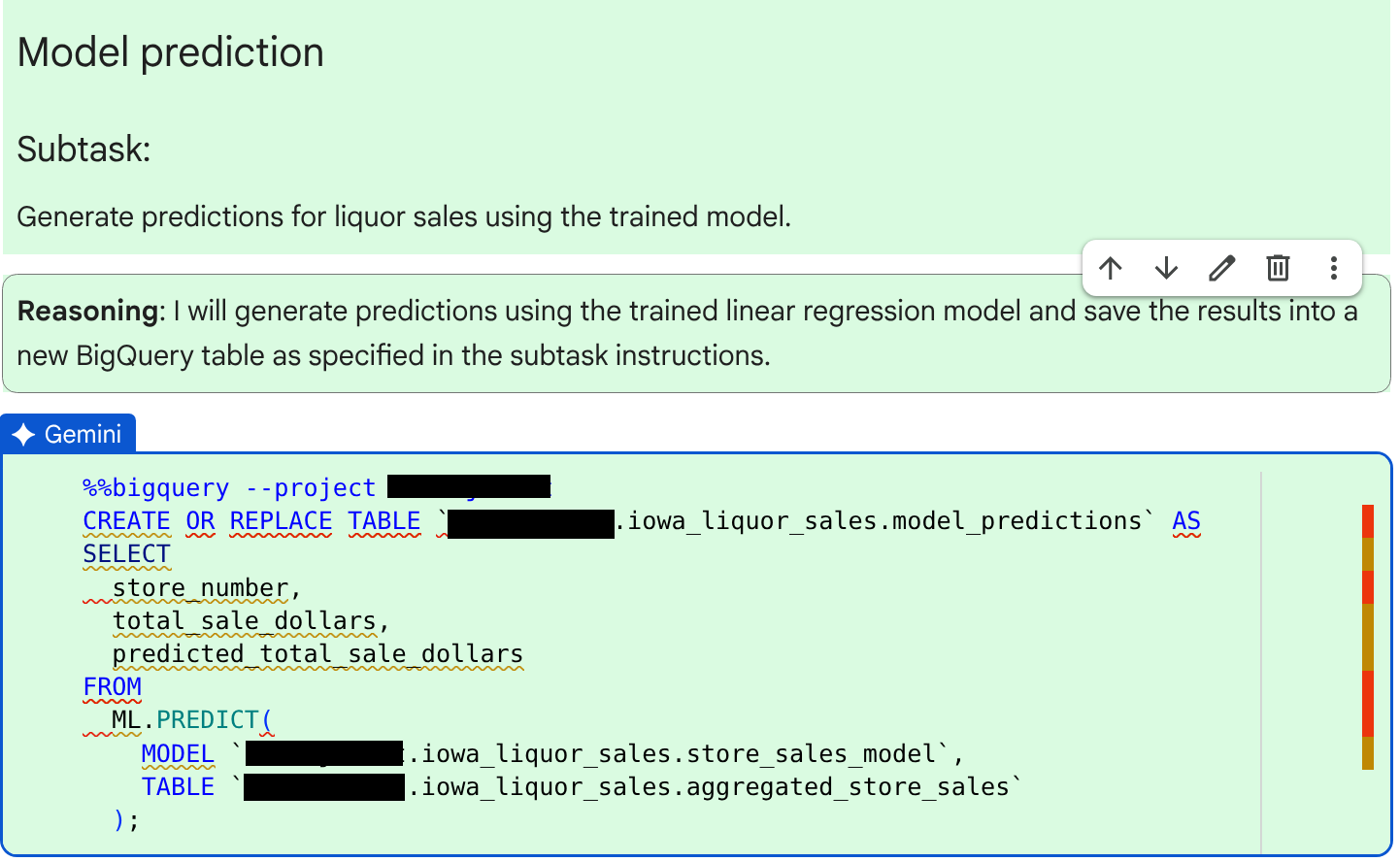
코드와 이유를 확인한 후 수락 및 실행을 클릭합니다.
코드 셀의 출력을 검토합니다. 다음과 유사한 메시지가 표시됩니다.
JOB ID 123456 successfully executed.쿼리가 실행되면 에이전트는 다음 하위 작업인 데이터 시각화를 위한 코드 셀을 만듭니다.
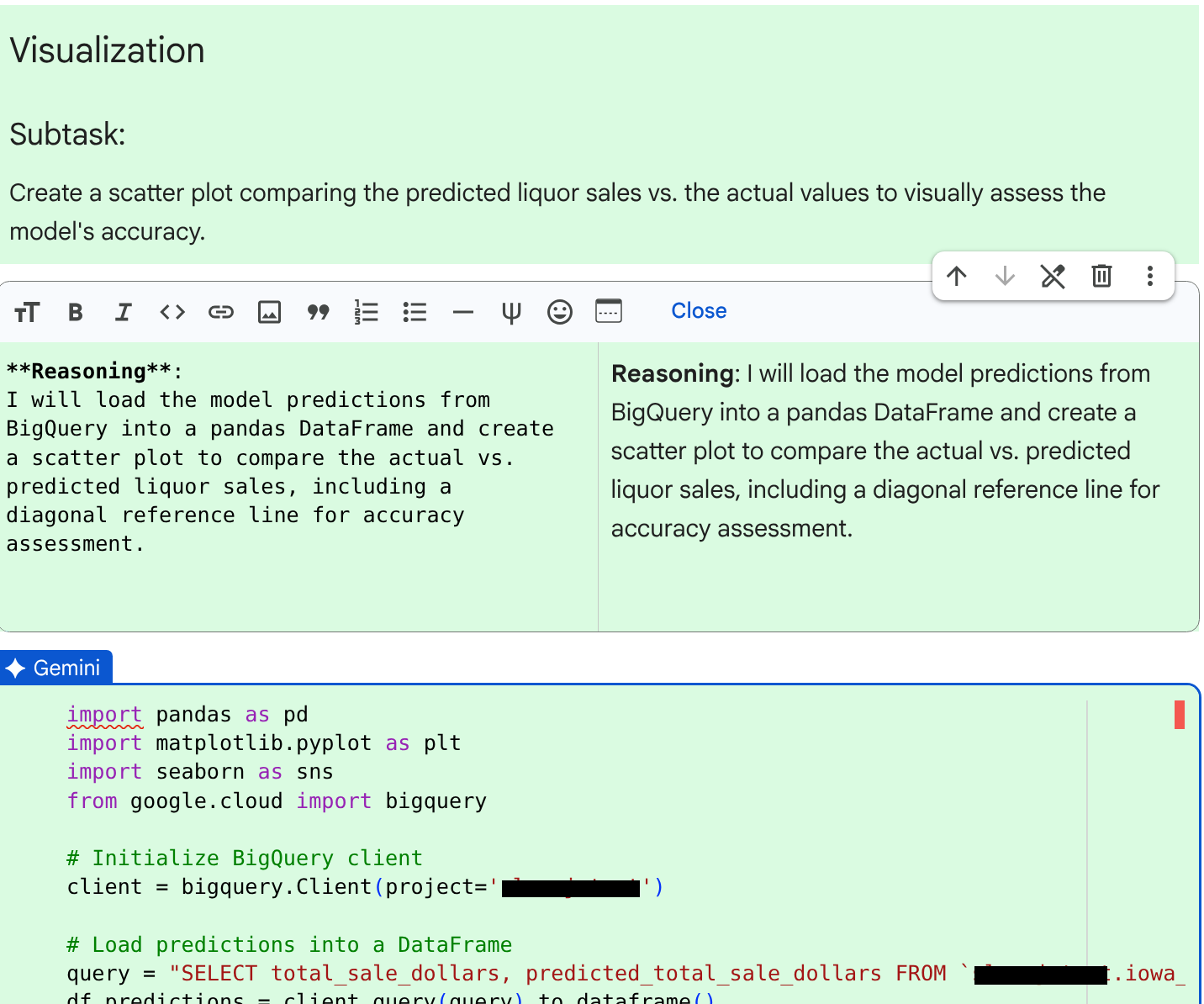
코드와 이유를 확인한 후 수락 및 실행을 클릭합니다.
코드 셀의 출력을 검토합니다. 실제 주류 판매량과 예측 주류 판매량을 표시하는 차트가 표시됩니다. 차트는 다음과 유사합니다.
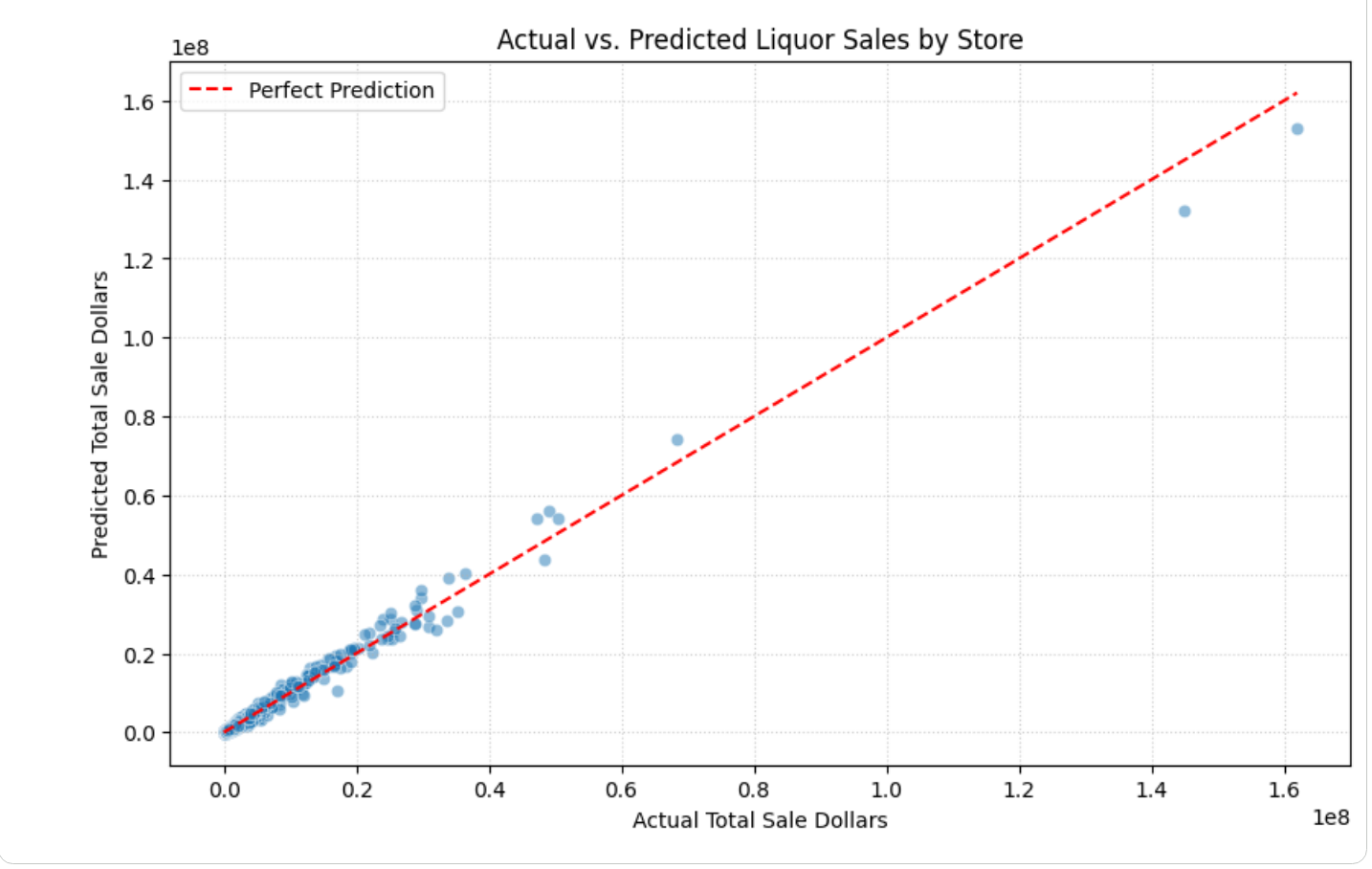
차트가 생성되면 에이전트는 주요 결과와 통계가 포함된 결과 요약을 생성합니다.
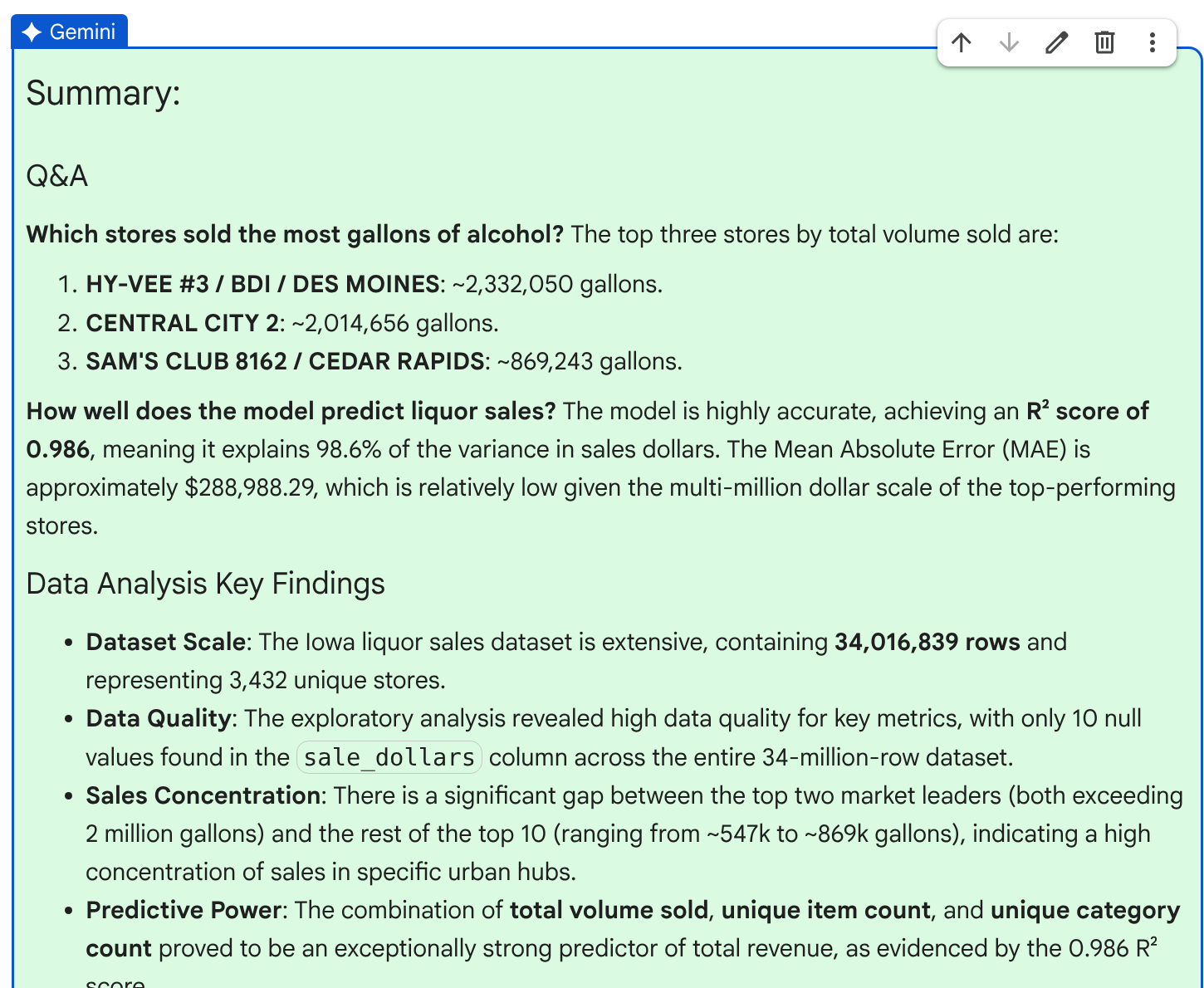
요약을 검토한 후 수락을 클릭하여 계획을 완료합니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
이 튜토리얼에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 만든 노트북을 삭제하면 됩니다. 노트북을 삭제하려면 다음 단계를 따르세요.BigQuery 페이지로 이동합니다.
왼쪽 창에서 프로젝트를 펼친 다음 Notebooks를 클릭합니다.
predict_liquor_sales노트북에서 more_vert 작업 열기를 클릭한 다음 삭제를 선택합니다.삭제를 클릭하여 노트북을 삭제합니다.
다음 단계
- 데이터 과학 에이전트의 기능에 대해 알아봅니다.
- BigQuery의 Colab Enterprise 노트북에 대해 자세히 알아보세요.
- BigQuery의 Gemini에 관한 문서를 읽어보세요.