
במדריך הזה תלמדו איך להשתמש בARIMA_PLUS מודל חד-משתני של סדרת זמנים כדי לחזות את הערך העתידי של עמודה מסוימת, על סמך הערכים ההיסטוריים של העמודה הזו.
במדריך הזה נסביר איך ליצור תחזית לכמה סדרות עיתיות. הערכים החזויים מחושבים לכל נקודת זמן, לכל ערך בעמודה אחת או יותר שצוינו. לדוגמה, אם רוצים לחזות את מזג האוויר ומציינים עמודה שמכילה נתוני עיר, הנתונים החזויים יכללו תחזיות לכל נקודות הזמן עבור עיר א', ואז ערכים חזויים לכל נקודות הזמן עבור עיר ב', וכן הלאה.
במדריך הזה נעשה שימוש בנתונים מהטבלה הציבורית bigquery-public-data.new_york.citibike_trips. הטבלה הזו מכילה מידע על נסיעות ב-Citi Bike בניו יורק.
לפני שקוראים את המדריך הזה, מומלץ מאוד לקרוא את המאמר יצירת תחזית של סדרת זמן יחידה באמצעות מודל חד-משתני.
מטרות
במדריך הזה מוסבר איך לבצע את הפעולות הבאות:
- יצירת מודל של סדרת זמנים כדי לחזות את מספר הנסיעות באופניים באמצעות הצהרת
CREATE MODEL. - הערכת המידע של ממוצע נע משולב אוטומטי (ARIMA) במודל באמצעות הפונקציה
ML.ARIMA_EVALUATE. - בדיקת מקדמי המודל באמצעות הפונקציה
ML.ARIMA_COEFFICIENTS. - אחזור של נתוני תחזית לגבי נסיעה באופניים מהמודל באמצעות הפונקציה
ML.FORECAST. - אחזור רכיבים של סדרת הזמן, כמו עונתיות ומגמה, באמצעות הפונקציה
ML.EXPLAIN_FORECAST. אתם יכולים לבדוק את הרכיבים של סדרת הזמן כדי להסביר את הערכים החזויים.
עלויות
במדריך הזה נעשה שימוש ברכיבים של Google Cloudשחלים עליהם חיובים, כולל:
- BigQuery
- BigQuery ML
מידע נוסף על העלויות ב-BigQuery זמין בדף תמחור ב-BigQuery.
מידע נוסף על העלויות של BigQuery ML זמין במאמר תמחור ב-BigQuery ML.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery מופעל באופן אוטומטי בפרויקטים חדשים.
כדי להפעיל את BigQuery בפרויקט קיים, עוברים אל
מפעילים את BigQuery API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים
ההרשאות הנדרשות
כדי ליצור את מערך הנתונים, אתם צריכים את ההרשאה
bigquery.datasets.createב-IAM.כדי ליצור את המודל, צריך את ההרשאות הבאות:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
כדי להריץ הסקה, אתם צריכים את ההרשאות הבאות:
bigquery.models.getDatabigquery.jobs.create
במאמר מבוא ל-IAM יש מידע נוסף על תפקידים והרשאות ב-IAM ב-BigQuery.
יצירת מערך נתונים
יוצרים מערך נתונים ב-BigQuery לאחסון מודל ה-ML.המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית Explorer, לוחצים על שם הפרויקט.
לוחצים על הצגת פעולות > יצירת מערך נתונים.
בדף Create dataset, מבצעים את הפעולות הבאות:
בשדה Dataset ID (מזהה מערך הנתונים), מזינים
bqml_tutorial.בקטע Location type, בוחרים באפשרות Multi-region ואז בוחרים באפשרות US.
משאירים את הגדרות ברירת המחדל שנותרו כמו שהן ולוחצים על Create dataset (יצירת מערך נתונים).
BQ
כדי ליצור מערך נתונים חדש, משתמשים בפקודה bq mk --dataset.
יוצרים מערך נתונים בשם
bqml_tutorialעם מיקום הנתונים שמוגדר ל-US.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
בודקים שמערך הנתונים נוצר:
bq ls
API
מבצעים קריאה לשיטה datasets.insert
עם משאב מוגדר של מערך נתונים.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
המחשת נתוני הקלט
לפני שיוצרים את המודל, אפשר להציג את נתוני הסדרות העיתיות של הקלט כדי לקבל מושג לגבי הפיזור. אפשר לעשות זאת באמצעות Data Studio.
SQL
ההצהרה SELECT של השאילתה הבאה משתמשת בפונקציה EXTRACT כדי לחלץ את פרטי התאריך מהעמודה starttime. השאילתה משתמשת בסעיף COUNT(*) כדי לקבל את המספר הכולל של הנסיעות ב-Citi Bike ביום.
כדי להציג את נתוני סדרת הזמנים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date;
כשהשאילתה מסתיימת, לוחצים על Open in (פתיחה ב) > Data Studio. Data Studio ייפתח בכרטיסייה חדשה. מבצעים את השלבים הבאים בכרטיסייה החדשה.
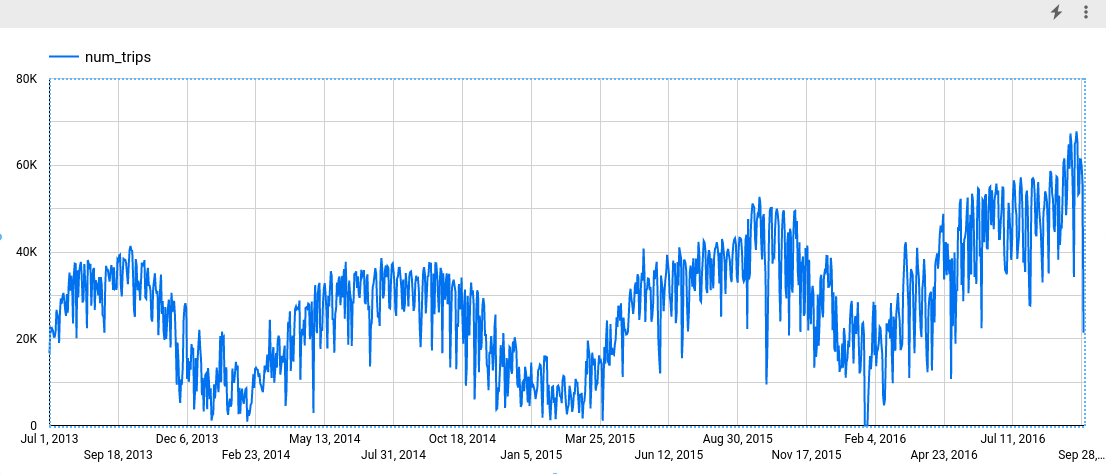
ב-Data Studio, לוחצים על הוספה > תרשים של סדרת זמנים.
בחלונית תרשים, בוחרים בכרטיסייה הגדרה.
בקטע Metric, מוסיפים את השדה num_trips ומסירים את מדד ברירת המחדל Record Count. התרשים שיתקבל ייראה כך:
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
יצירת מודל של סדרת זמנים
אתם רוצים לחזות את מספר הנסיעות באופניים לכל תחנת Citi Bike, ולכן אתם צריכים הרבה מודלים של סדרות זמן – אחד לכל תחנת Citi Bike שכלולה בנתוני הקלט. אפשר ליצור כמה מודלים כדי לעשות את זה, אבל זה יכול להיות תהליך מייגע שגוזל הרבה זמן, במיוחד אם יש לכם מספר גדול של סדרות זמן. במקום זאת, אפשר להשתמש בשאילתה אחת כדי ליצור ולהתאים קבוצה של מודלים של סדרות זמן, כדי לחזות כמה סדרות זמן בבת אחת.
SQL
בשאילתה הבאה, הפסקה OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
מציינת שאתם יוצרים מודל של סדרת זמנים שמבוסס על ARIMA. משתמשים באפשרות time_series_id_col של הצהרת CREATE MODEL כדי לציין עמודה אחת או יותר בנתוני הקלט שרוצים לקבל לגביהם תחזיות. במקרה הזה, תחנת Citi Bike, שמיוצגת על ידי העמודה start_station_name. השתמשנו בפסקה WHERE כדי להגביל את תחנות המוצא לאלה שכוללות Central Park בשם שלהן. האפשרות auto_arima_max_order של הצהרת CREATE MODEL שולטת במרחב החיפוש של כוונון היפרפרמטרים באלגוריתם auto.ARIMA. אפשרות ברירת המחדל של decompose_time_series במשפט CREATE MODEL היא TRUE, כך שכשמעריכים את המודל בשלב הבא, מוחזר מידע על נתוני סדרת הזמנים.
כדי ליצור את המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date;
השאילתה נמשכת כ-24 שניות, ולאחר מכן אפשר לגשת למודל
nyc_citibike_arima_model_group. מכיוון שהשאילתה משתמשת בהצהרתCREATE MODEL, לא מוצגות תוצאות של השאילתה.
השאילתה הזו יוצרת 12 מודלים של סדרות זמן, אחד לכל אחת מ-12 תחנות ההתחלה של Citi Bike בנתוני הקלט. עלות הזמן, כ-24 שניות, גבוהה רק פי 1.4 מזו של יצירת מודל יחיד של סדרת זמנים, בגלל המקביליות. עם זאת, אם מסירים את סעיף WHERE ... LIKE ..., יהיו יותר מ-600 סדרות זמן לתחזית, והתחזית לא תתבצע במקביל באופן מלא בגלל מגבלות הקיבולת של המשבצות. במקרה כזה, השלמת השאילתה תימשך כ-15 דקות. כדי לקצר את זמן הריצה של השאילתה, תוך התפשרות על ירידה קלה באיכות המודל, אפשר להקטין את הערך של auto_arima_max_order.
כך מצמצמים את מרחב החיפוש של כוונון ההיפר-פרמטרים באלגוריתם auto.ARIMA. מידע נוסף זמין במאמר Large-scale time series forecasting best practices.
BigQuery DataFrames
בקטע הקוד הבא, אנחנו יוצרים מודל של סדרת זמנים שמבוסס על ARIMA.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
הפעולה הזו יוצרת 12 מודלים של סדרות זמנים, אחד לכל אחת מ-12 תחנות ההתחלה של Citi Bike בנתוני הקלט. עלות הזמן, כ-24 שניות, גבוהה רק פי 1.4 מזו של יצירת מודל יחיד של סדרת זמן, בגלל המקביליות.
הערכת המודל
SQL
כדי להעריך את מודל הסדרות העיתיות, משתמשים בפונקציה ML.ARIMA_EVALUATE. הפונקציה ML.ARIMA_EVALUATE מציגה את מדדי ההערכה שנוצרו עבור המודל במהלך התהליך של כוונון אוטומטי של היפר-פרמטרים.
כדי להעריך את המודל, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
התוצאות אמורות להיראות כך:
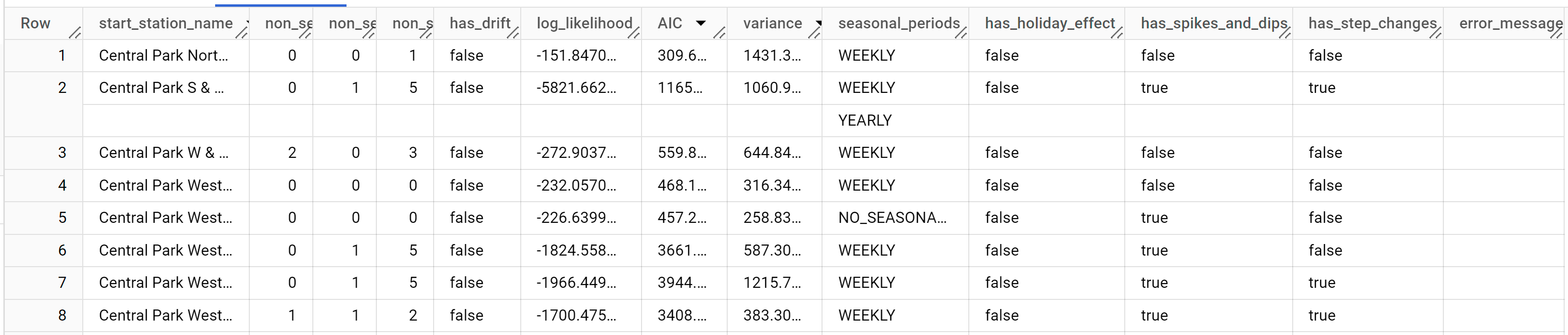
הפונקציה
auto.ARIMAמעריכה עשרות מודלים אפשריים של ARIMA לכל סדרת זמן, אבל כברירת מחדל הפונקציהML.ARIMA_EVALUATEמציגה רק את המידע של המודל הכי טוב כדי שטבלת הפלט תהיה קומפקטית. כדי להציג את כל המודלים המועמדים, אפשר להגדיר את הארגומנטshow_all_candidate_modelשל הפונקציהML.ARIMA_EVALUATEלערךTRUE.
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
בעמודה start_station_name מוגדרת עמודת נתוני הקלט שעבורה נוצרו סדרות הזמן. זו העמודה שציינתם באמצעות האפשרות time_series_id_col כשייצרתם את המודל.
עמודות הפלט non_seasonal_p, non_seasonal_d, non_seasonal_q ו-has_drift מגדירות מודל ARIMA בצינור העיבוד לאימון. עמודות הפלט log_likelihood, AIC ו-variance רלוונטיות לתהליך ההתאמה של מודל ARIMA. תהליך ההתאמה קובע את מודל ה-ARIMA הטוב ביותר באמצעות האלגוריתם auto.ARIMA, אחד לכל סדרת זמן.
האלגוריתם auto.ARIMA משתמש במבחן KPSS כדי לקבוע את הערך הטוב ביותר ל-non_seasonal_d, שבמקרה הזה הוא 1. כשהערך של non_seasonal_d הוא 1, אלגוריתם auto.ARIMA מאמן 42 מודלים שונים של ARIMA במקביל.
בדוגמה הזו, כל 42 המודלים האפשריים תקפים, ולכן הפלט מכיל 42 שורות, אחת לכל מודל ARIMA אפשרי. במקרים שבהם חלק מהמודלים לא תקפים, הם לא נכללים בפלט. המודלים האלה מוצגים בסדר עולה לפי AIC. למודל בשורה הראשונה יש את ערך ה-AIC הנמוך ביותר, והוא נחשב למודל הטוב ביותר. המודל הכי טוב נשמר כמודל הסופי ומשמש לחיזוי נתונים, להערכת המודל ולבדיקת המקדמים של המודל, כמו שמוצג בשלבים הבאים.
העמודה seasonal_periods מכילה מידע על הדפוס העונתי שזוהה בנתוני הסדרות העיתיות. לכל סדרת זמן יכולים להיות דפוסים עונתיים שונים. לדוגמה, מהאיור אפשר לראות שלסדרת זמן אחת יש דפוס שנתי, אבל לאחרות אין.
העמודות has_holiday_effect, has_spikes_and_dips ו-has_step_changes מתמלאות רק כשמגדירים את decompose_time_series=TRUE. העמודות האלה משקפות גם מידע על נתוני סדרות הזמן של הקלט, והן לא קשורות למודל ARIMA. הערכים בעמודות האלה זהים בכל שורות הפלט.
בדיקת המקדמים של המודל
SQL
בודקים את המקדמים של מודל סדרת הזמן באמצעות הפונקציה ML.ARIMA_COEFFICIENTS.
כדי לאחזר את המקדמים של המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
השלמת השאילתה נמשכת פחות משנייה. התוצאות אמורות להיראות כך:
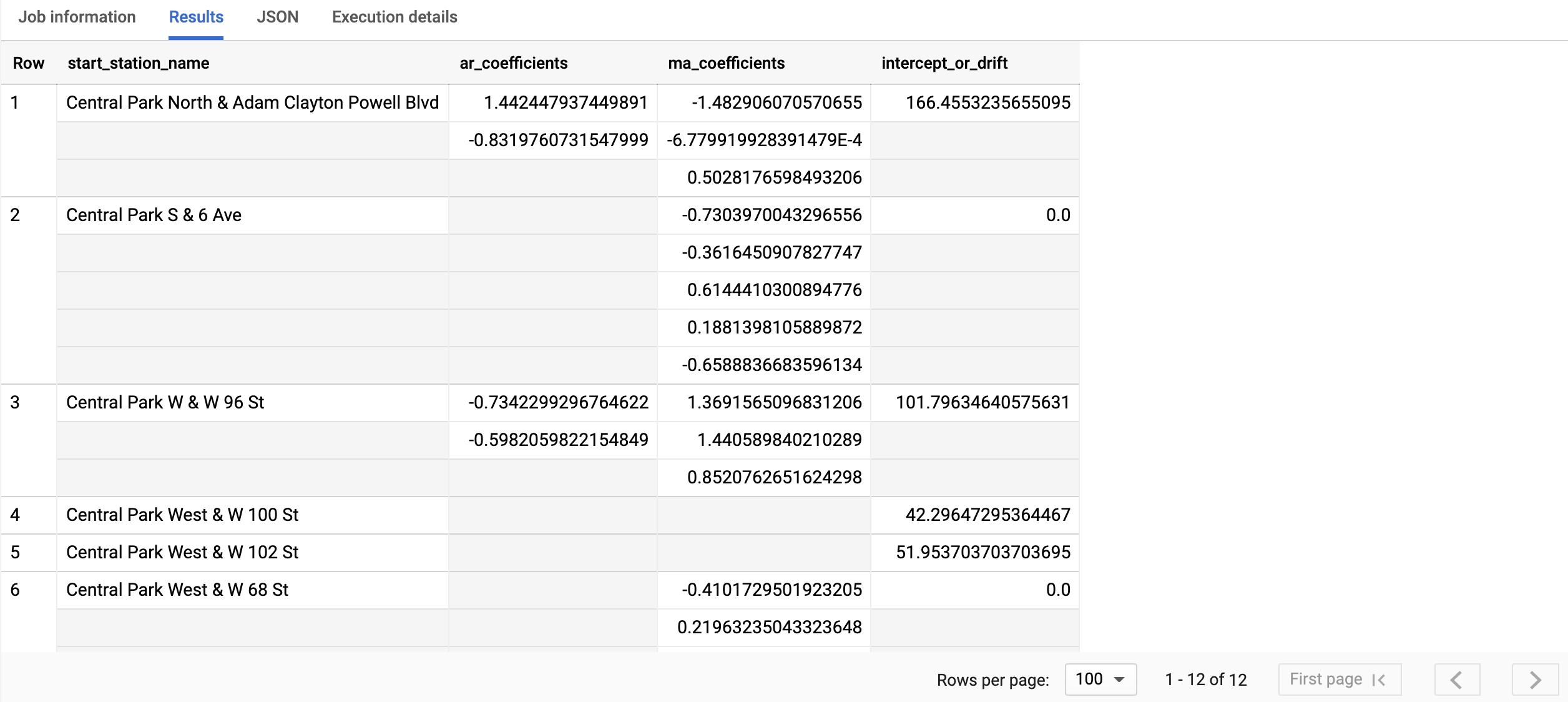
מידע נוסף על עמודות הפלט זמין במאמר בנושא הפונקציה
ML.ARIMA_COEFFICIENTS.
BigQuery DataFrames
בודקים את המקדמים של מודל סדרת הזמן באמצעות הפונקציה coef_.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
בעמודה start_station_name מוגדרת עמודת נתוני הקלט שעבורה נוצרו סדרות הזמן. זו העמודה שציינתם באפשרות time_series_id_col כשיוצרים את המודל.
בעמודת הפלט ar_coefficients מוצגים מקדמי המודל של החלק האוטוגרסיבי (AR) של מודל ARIMA. באופן דומה, בעמודת הפלט ma_coefficients
מוצגים מקדמי המודל של החלק של הממוצע הנע (MA) במודל ARIMA. שתי העמודות האלה מכילות ערכי מערך, והאורך שלהן שווה ל-non_seasonal_p ול-non_seasonal_q, בהתאמה. הערך של intercept_or_drift הוא האיבר הקבוע במודל ARIMA.
שימוש במודל כדי לחזות נתונים
SQL
אפשר לחזות ערכים עתידיים של סדרות זמן באמצעות הפונקציה ML.FORECAST.
בשאילתת GoogleSQL הבאה, פסוקית STRUCT(3 AS horizon, 0.9 AS confidence_level) מציינת שהשאילתה חוזה 3 נקודות זמן עתידיות, ומפיקה מרווח חיזוי עם רמת סמך של 90%.
כדי לחזות נתונים באמצעות המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
לוחצים על Run.
השלמת השאילתה נמשכת פחות משנייה. התוצאות אמורות להיראות כך:
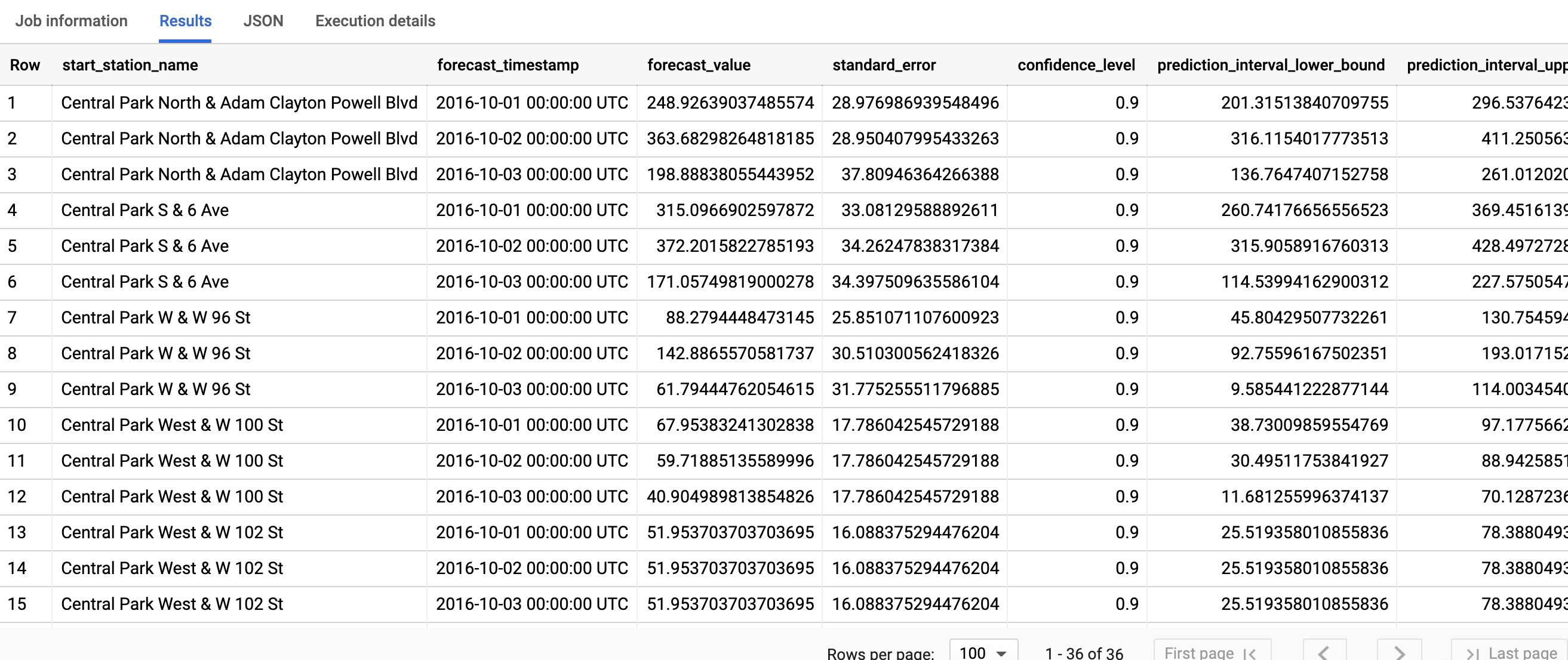
מידע נוסף על עמודות הפלט זמין במאמר בנושא הפונקציה ML.FORECAST.
BigQuery DataFrames
כדי לחזות ערכים עתידיים של סדרת זמן, משתמשים בפונקציה predict.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
בעמודה הראשונה, start_station_name, מופיעה הערה לגבי סדרת הזמנים שלפיה מותאם כל מודל של סדרת זמנים. לכל start_station_name יש שלוש שורות של תוצאות צפויות, כפי שמצוין בערך horizon.
לכל start_station_name, שורות הפלט מסודרות לפי סדר כרונולוגי לפי הערך בעמודה forecast_timestamp. בתחזית של סדרת זמן, מרווח החיזוי, שמיוצג על ידי הערכים בעמודות prediction_interval_lower_bound ו-prediction_interval_upper_bound, חשוב לא פחות מהערך בעמודה forecast_value. הערך של forecast_value הוא נקודת האמצע של מרווח החיזוי. מרווח החיזוי תלוי בערכים של העמודות standard_error ו-confidence_level.
הסבר על תוצאות התחזית
SQL
אפשר לקבל מדדים של יכולת הסבר בנוסף לנתוני התחזית באמצעות הפונקציה ML.EXPLAIN_FORECAST. הפונקציה ML.EXPLAIN_FORECAST חוזה ערכים עתידיים של סדרת זמנים, וגם מחזירה את כל הרכיבים הנפרדים של סדרת הזמנים. אם רוצים רק להחזיר נתוני תחזית, צריך להשתמש בפונקציה ML.FORECAST
כפי שמוסבר במאמר שימוש במודל לחיזוי נתונים.
הסעיף STRUCT(3 AS horizon, 0.9 AS confidence_level) שמשמש בפונקציה ML.EXPLAIN_FORECAST מציין שהשאילתה חוזה 3 נקודות זמן עתידיות ויוצרת רווח בר-סמך עם רמת סמך של 90%.
כדי להסביר את התוצאות של המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level));
השלמת השאילתה נמשכת פחות משנייה. התוצאות אמורות להיראות כך:


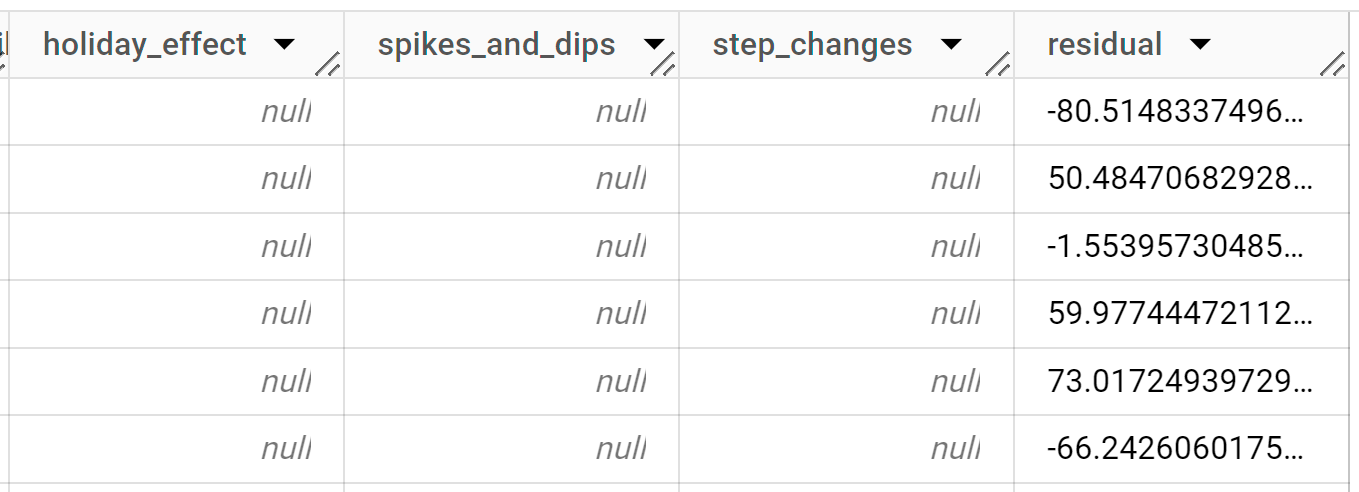
אלף השורות הראשונות שמוחזרות הן נתונים היסטוריים. כדי לראות את נתוני התחזית, צריך לגלול בתוצאות.
השורות בפלט מסודרות קודם לפי
start_station_name, ואז לפי הערך בעמודהtime_series_timestampבסדר כרונולוגי. בתחזיות של סדרות זמן, מרווח החיזוי, שמיוצג על ידי הערכים בעמודותprediction_interval_lower_boundו-prediction_interval_upper_bound, חשוב לא פחות מהערך בעמודהforecast_value. הערך שלforecast_valueהוא נקודת האמצע של מרווח החיזוי. מרווח החיזוי תלוי בערכים של העמודותstandard_errorו-confidence_level.מידע נוסף על עמודות הפלט זמין במאמר
ML.EXPLAIN_FORECAST.
BigQuery DataFrames
אפשר לקבל מדדים של יכולת הסבר בנוסף לנתוני התחזית באמצעות הפונקציה predict_explain. הפונקציה predict_explain חוזה ערכים עתידיים של סדרת זמנים, וגם מחזירה את כל הרכיבים הנפרדים של סדרת הזמנים. אם רוצים רק להחזיר נתוני תחזית, צריך להשתמש בפונקציה predict
כפי שמוסבר במאמר שימוש במודל לחיזוי נתונים.
הסעיף horizon=3, confidence_level=0.9 שמשמש בפונקציה predict_explain מציין שהשאילתה חוזה 3 נקודות זמן עתידיות ויוצרת רווח בר-סמך עם רמת סמך של 90%.
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
השורות בפלט מסודרות קודם לפי time_series_timestamp, ואז לפי הערך בעמודה start_station_name בסדר כרונולוגי. בתחזיות של סדרות זמן, מרווח החיזוי, שמיוצג על ידי הערכים בעמודות prediction_interval_lower_bound ו-prediction_interval_upper_bound, חשוב לא פחות מהערך בעמודה forecast_value. הערך של forecast_value הוא נקודת האמצע של מרווח החיזוי. מרווח החיזוי תלוי בערכים של העמודות standard_error ו-confidence_level.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
- אתם יכולים למחוק את הפרויקט שיצרתם.
- אפשר גם להשאיר את הפרויקט ולמחוק את קבוצת הנתונים.
מחיקת מערך נתונים
אם מוחקים פרויקט, כל מערכי הנתונים וכל הטבלאות בפרויקט נמחקים. אם אתם מעדיפים להשתמש מחדש בפרויקט, אתם יכולים למחוק את מערך הנתונים שיצרתם במדריך הזה:
אם צריך, פותחים את הדף BigQuery במסוףGoogle Cloud .
בחלונית הניווט, לוחצים על מערך הנתונים bqml_tutorial שיצרתם.
לוחצים על מחיקת מערך הנתונים כדי למחוק את מערך הנתונים, את הטבלה ואת כל הנתונים.
בתיבת הדו-שיח מחיקת מערך נתונים, מקלידים את שם מערך הנתונים (
bqml_tutorial) כדי לאשר את פקודת המחיקה, ואז לוחצים על מחיקה.
מחיקת פרויקט
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- איך יוצרים תחזית של סדרת זמנים אחת באמצעות מודל חד-משתני
- איך יוצרים תחזית של סדרת זמנים אחת באמצעות מודל רב-משתני
- איך משתמשים במודל חד-משתני כדי לחזות כמה סדרות זמן בכמה שורות
- איך יוצרים תחזית היררכית של כמה סדרות זמן באמצעות מודל חד-משתני
- סקירה כללית על BigQuery ML זמינה במאמר מבוא ל-AI ול-ML ב-BigQuery.