
במדריך הזה תלמדו איך להאיץ באופן משמעותי את האימון של מודל חד-משתני של סדרות עיתיות, כדי לבצע כמה תחזיות של סדרות עיתיות באמצעות שאילתה אחת.ARIMA_PLUS בנוסף, נסביר איך להעריך את דיוק התחזיות.
במדריך הזה נסביר איך ליצור תחזית לכמה סדרות עיתיות. הערכים החזויים מחושבים לכל נקודת זמן, לכל ערך בעמודה אחת או יותר שצוינו. לדוגמה, אם רוצים לחזות את מזג האוויר ומציינים עמודה שמכילה נתוני עיר, הנתונים החזויים יכללו תחזיות לכל נקודות הזמן עבור עיר א', ואז ערכים חזויים לכל נקודות הזמן עבור עיר ב', וכן הלאה.
במדריך הזה נעשה שימוש בנתונים מהטבלאות הציבוריות bigquery-public-data.new_york.citibike_trips ו-iowa_liquor_sales.sales. נתוני הנסיעות באופניים מכילים רק כמה מאות סדרות זמן, ולכן הם משמשים להמחשת אסטרטגיות שונות להאצת אימון המודל.
נתוני המכירות של המשקאות החריפים כוללים יותר ממיליון סדרות זמן, ולכן הם משמשים להצגת חיזוי של סדרות זמן בהיקף גדול.
לפני שקוראים את המדריך הזה, מומלץ לקרוא את המאמרים תחזית של כמה סדרות זמן באמצעות מודל חד-משתני ושיטות מומלצות ליצירת תחזיות של סדרות זמן בקנה מידה גדול.
מטרות
במדריך הזה תשתמשו ב:
- יצירת מודל של סדרת זמנים באמצעות ההצהרה
CREATE MODEL. - הערכת רמת הדיוק של המודל באמצעות הפונקציה
ML.EVALUATE. - שימוש באפשרויות
AUTO_ARIMA_MAX_ORDER,TIME_SERIES_LENGTH_FRACTION,MIN_TIME_SERIES_LENGTHו-MAX_TIME_SERIES_LENGTHשל הצהרתCREATE MODELכדי לקצר משמעותית את זמן אימון המודל.
כדי לפשט את המדריך, לא נסביר בו איך להשתמש בפונקציות ML.FORECAST או ML.EXPLAIN_FORECAST כדי ליצור תחזיות. הוראות לשימוש בפונקציות האלה מפורטות במאמר תחזית של כמה סדרות זמן באמצעות מודל חד-משתני.
עלויות
במדריך הזה נעשה שימוש ברכיבים של Google Cloudשחלים עליהם חיובים, כולל:
- BigQuery
- BigQuery ML
מידע נוסף על עלויות זמין בדף תמחור ב-BigQuery ובדף תמחור ב-BigQuery ML.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery מופעל באופן אוטומטי בפרויקטים חדשים.
כדי להפעיל את BigQuery בפרויקט קיים, עוברים אל
מפעילים את BigQuery API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים
ההרשאות הנדרשות
כדי ליצור את מערך הנתונים, אתם צריכים את ההרשאה
bigquery.datasets.createב-IAM.כדי ליצור את המודל, צריך את ההרשאות הבאות:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
כדי להריץ הסקה, אתם צריכים את ההרשאות הבאות:
bigquery.models.getDatabigquery.jobs.create
במאמר מבוא ל-IAM יש מידע נוסף על תפקידים והרשאות ב-IAM ב-BigQuery.
יצירת מערך נתונים
יוצרים מערך נתונים ב-BigQuery לאחסון מודל ה-ML.
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית Explorer, לוחצים על שם הפרויקט.
לוחצים על הצגת פעולות > יצירת מערך נתונים.
בדף Create dataset, מבצעים את הפעולות הבאות:
בשדה Dataset ID (מזהה מערך הנתונים), מזינים
bqml_tutorial.בקטע Location type, בוחרים באפשרות Multi-region ואז בוחרים באפשרות US.
משאירים את הגדרות ברירת המחדל שנותרו כמו שהן ולוחצים על Create dataset (יצירת מערך נתונים).
BQ
כדי ליצור מערך נתונים חדש, משתמשים בפקודה bq mk --dataset.
יוצרים מערך נתונים בשם
bqml_tutorialעם מיקום הנתונים שמוגדר ל-US.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
בודקים שמערך הנתונים נוצר:
bq ls
API
מבצעים קריאה לשיטה datasets.insert
עם משאב מוגדר של מערך נתונים.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
יצירת טבלה של נתוני קלט
ההצהרה SELECT של השאילתה הבאה משתמשת בפונקציה EXTRACT כדי לחלץ את פרטי התאריך מהעמודה starttime. השאילתה משתמשת בסעיף COUNT(*) כדי לקבל את המספר הכולל של הנסיעות ב-Citi Bike ביום.
ל-table_1 יש 679 סדרות עיתיות. השאילתה משתמשת בלוגיקה נוספת של INNER JOIN כדי לבחור את כל סדרות הזמן שיש בהן יותר מ-400 נקודות זמן, וכתוצאה מכך מתקבלות 383 סדרות זמן.
כדי ליצור את טבלת נתוני הקלט:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
יצירת מודל לכמה סדרות עיתיות עם פרמטרים שמוגדרים כברירת מחדל
אתם רוצים לחזות את מספר הנסיעות באופניים לכל תחנת Citi Bike, ולכן אתם צריכים הרבה מודלים של סדרות עיתיות – אחד לכל תחנת Citi Bike שכלולה בנתוני הקלט. אפשר לכתוב כמה שאילתות CREATE MODEL כדי לעשות את זה, אבל זה יכול להיות תהליך מייגע שגוזל זמן רב, במיוחד אם יש לכם מספר גדול של סדרות זמן. במקום זאת, אפשר להשתמש בשאילתה אחת כדי ליצור ולהתאים קבוצה של מודלים של סדרות זמנים, כדי לחזות כמה סדרות זמנים בבת אחת.
הפסקה OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
מציינת שאתם יוצרים קבוצה של מודלים של סדרות עיתיות שמבוססים על ARIMA ARIMA_PLUS. האפשרות time_series_timestamp_col מציינת את העמודה שמכילה את סדרת הזמן, האפשרות time_series_data_col מציינת את העמודה שלגביה רוצים ליצור תחזית, והאפשרות time_series_id_col מציינת מאפיין אחד או יותר שלגביהם רוצים ליצור סדרת זמן.
בדוגמה הזו, לא נכללות נקודות הזמן בסדרת הזמן אחרי 1 ביוני 2016, כדי שאפשר יהיה להשתמש בהן בהמשך להערכת דיוק התחזית באמצעות הפונקציה ML.EVALUATE.
כדי ליצור את המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
השלמת השאילתה נמשכת כ-15 דקות.
הערכת דיוק התחזית לכל סדרת זמן
כדי להעריך את דיוק התחזית של המודל, משתמשים בפונקציה ML.EVALUATE.
כדי להעריך את המודל, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
השאילתה הזו מדווחת על כמה מדדי תחזית, כולל:
התוצאות אמורות להיראות כך:
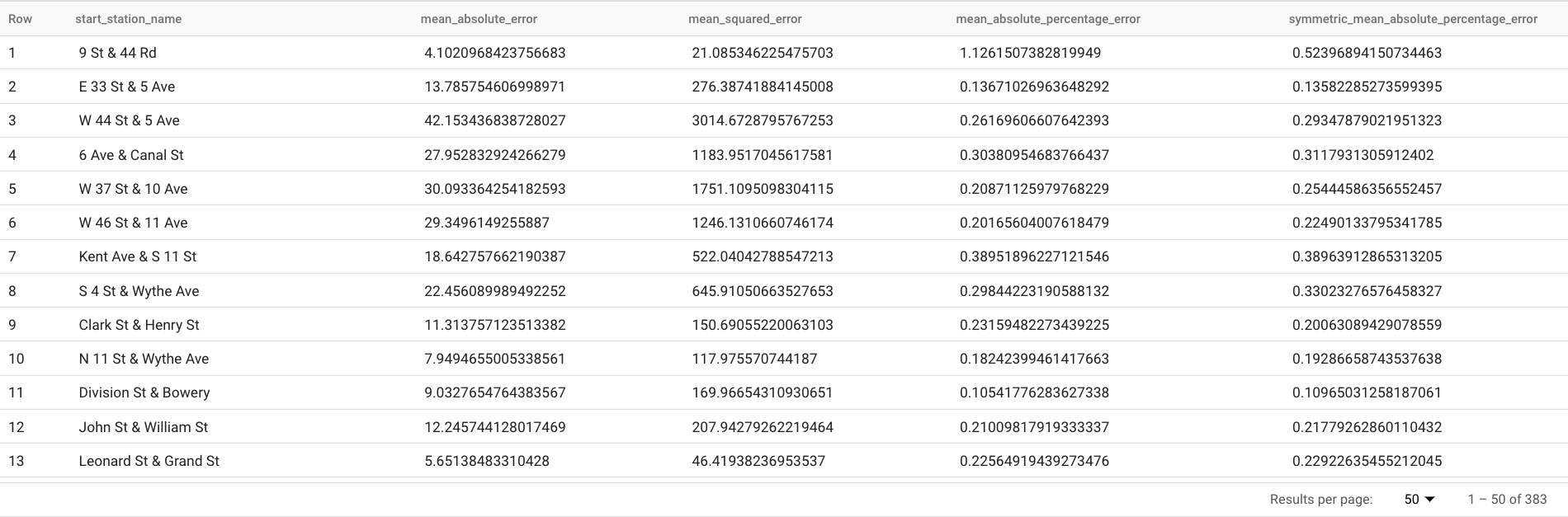
הפסקה
TABLEבפונקציהML.EVALUATEמזהה טבלה שמכילה את נתוני האמת. התוצאות של התחזיות מושוות לנתוני האמת כדי לחשב מדדי דיוק. במקרה הזה,nyc_citibike_time_seriesמכיל את הנקודות בסדרת הזמן שלפני 1 ביוני 2016 וגם את הנקודות שאחרי התאריך הזה. הנקודות אחרי 1 ביוני 2016 הן נתוני האמת. הנקודות שלפני 1 ביוני 2016 משמשות לאימון המודל כדי ליצור תחזיות אחרי התאריך הזה. כדי לחשב את המדדים, צריך להשתמש רק בנקודות שהצטברו אחרי 1 ביוני 2016. המערכת מתעלמת מהנקודות שנצברו לפני 1 ביוני 2016 בחישוב המדדים.בסעיף
STRUCTבפונקציהML.EVALUATEצוינו פרמטרים לפונקציה. הערך שלhorizonהוא7, כלומר השאילתה מחשבת את דיוק התחזית על סמך תחזית של שבע נקודות. הערה: אם בנתוני האמת יש פחות משבע נקודות להשוואה, מדדי הדיוק מחושבים על סמך הנקודות הזמינות בלבד. הערך שלperform_aggregationהואTRUE, כלומר מדדי הדיוק של התחזית מצטברים על בסיס המדדים בנקודת הזמן. אם מציינים ערך שלperform_aggregationשהואFALSE, הפונקציה מחזירה את רמת הדיוק של התחזית לכל נקודת זמן בתחזית.מידע נוסף על עמודות הפלט זמין במאמר בנושא הפונקציה
ML.EVALUATE.
הערכת הדיוק הכולל של התחזיות
הערכת דיוק התחזית לכל 383 סדרות הזמן.
מבין מדדי התחזיות שמוחזרים על ידי ML.EVALUATE, רק mean absolute percentage error ו-symmetric mean absolute percentage error הם בלתי תלויים בערך של סדרת הזמן. לכן, כדי להעריך את דיוק התחזית הכולל של קבוצת סדרות הזמן, רק הצבירה של שני המדדים האלה היא משמעותית.
כדי להעריך את המודל, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
השאילתה הזו מחזירה ערך MAPE של 0.3471 וערך sMAPE של 0.2563.
יצירת מודל לחיזוי של כמה סדרות זמנים עם מרחב חיפוש קטן יותר של היפר-פרמטרים
בקטע Create a model to multiple time-series with default parameters (יצירת מודל לכמה סדרות עיתיות עם פרמטרים שמוגדרים כברירת מחדל), השתמשתם בערכי ברירת המחדל לכל אפשרויות האימון, כולל האפשרות auto_arima_max_order. האפשרות הזו קובעת את מרחב החיפוש של כוונון ההיפר-פרמטרים באלגוריתם auto.ARIMA.
במודל שנוצר על ידי השאילתה הבאה, משתמשים במרחב חיפוש קטן יותר להיפרפרמטרים על ידי שינוי ערך האפשרות auto_arima_max_order מברירת המחדל 5 ל-2.
כדי להעריך את המודל, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
השלמת השאילתה נמשכת כ-2 דקות. נזכיר שהמודל הקודם נמשך כ-15 דקות כשהערך של
auto_arima_max_orderהיה5, כך שהשינוי הזה משפר את מהירות אימון המודל בערך פי 7. אם אתם תוהים למה העלייה במהירות היא לא5/2=2.5x, הסיבה לכך היא שכשהערך שלauto_arima_max_orderעולה, לא רק שמספר המודלים הפוטנציאליים עולה, אלא גם המורכבות. כתוצאה מכך, זמן האימון של המודל מתארך.
הערכת דיוק התחזית של מודל עם מרחב חיפוש קטן יותר של היפרפרמטרים
כדי להעריך את המודל, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
השאילתה הזו מחזירה ערך MAPE של 0.3337 וערך sMAPE של 0.2337.
בקטע Evaluate overall forecasting accuracy (הערכת הדיוק הכולל של התחזית), הערכתם מודל עם מרחב חיפוש גדול יותר של היפרפרמטרים, שבו ערך האפשרות auto_arima_max_order הוא 5. התוצאה הייתה ערך של MAPE
0.3471 וערך של sMAPE 0.2563. במקרה הזה, אפשר לראות שמרחב חיפוש קטן יותר של היפרפרמטרים נותן למעשה רמת דיוק גבוהה יותר בתחזיות. אחת הסיבות לכך היא שהאלגוריתם auto.ARIMA מבצע רק כוונון של היפרפרמטרים למודול המגמות של כל צינור המודלים. יכול להיות שמודל ה-ARIMA הטוב ביותר שנבחר על ידי האלגוריתם auto.ARIMA לא יניב את תוצאות התחזית הטובות ביותר לכל הצינור.
יצירת מודל לתחזית של כמה סדרות זמן עם מרחב קטן יותר של חיפוש היפר-פרמטרים ואסטרטגיות אימון מהירות וחכמות
בשלב הזה, משתמשים במרחב חיפוש קטן יותר של היפר-פרמטרים ובשיטת האימון המהיר החכם באמצעות אחת או יותר מאפשרויות האימון max_time_series_length, max_time_series_length או time_series_length_fraction.
בניית מודלים תקופתיים, כמו מודלים של עונתיות, דורשת מספר מסוים של נקודות זמן, אבל בניית מודלים של מגמות דורשת פחות נקודות זמן. בינתיים, מודלים של מגמות דורשים הרבה יותר משאבי מחשוב מרכיבים אחרים של סדרות זמן, כמו עונתיות. באמצעות אפשרויות האימון המהיר שצוינו למעלה, אפשר ליצור מודל יעיל של רכיב המגמה באמצעות קבוצת משנה של נתוני הסדרה העתית, בזמן שרכיבים אחרים של הסדרה העתית משתמשים בכל נתוני הסדרה העתית.
בדוגמה הבאה השתמשנו באפשרות max_time_series_length כדי להשיג אימון מהיר. אם מגדירים את ערך האפשרות max_time_series_length ל-30, המערכת משתמשת רק ב-30 נקודות הזמן האחרונות כדי ליצור מודל של רכיב המגמה. כל 383
סדרות הזמן עדיין משמשות ליצירת מודל של הרכיבים שאינם מגמה.
כדי ליצור את המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
השאילתה נמשכת כ-35 שניות. השאילתה הזו מהירה פי 3 בהשוואה לשאילתה שבה השתמשתם בקטע יצירת מודל לחיזוי של כמה סדרות זמן עם מרחב חיפוש קטן יותר של היפרפרמטרים. בגלל התקורה הקבועה של הזמן בחלק של השאילתה שלא קשור לאימון, כמו עיבוד מקדים של הנתונים, השיפור במהירות גבוה בהרבה כשמספר סדרות הזמן גדול בהרבה מאשר בדוגמה הזו. עבור מיליון סדרות זמן, מהירות ההשגה מתקרבת ליחס בין אורך סדרת הזמן לבין ערך האפשרות
max_time_series_length. במקרה כזה, השיפור במהירות יהיה גדול פי 10.
הערכת דיוק התחזיות של מודל עם מרחב חיפוש קטן יותר של היפרפרמטרים ואסטרטגיות אימון מהירות וחכמות
כדי להעריך את המודל, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
השאילתה הזו מחזירה ערך MAPE של 0.3515 וערך sMAPE של 0.2473.
תזכורת: בלי שימוש בשיטות אימון מהירות, התוצאות של דיוק התחזית הן MAPE עם ערך של 0.3337 ו-sMAPE עם ערך של 0.2337.
ההפרש בין שני סטים של ערכי מדדים הוא בטווח של 3%, שהוא
לא משמעותי מבחינה סטטיסטית.
בקיצור, השתמשתם במרחב חיפוש קטן יותר של היפרפרמטרים ובאסטרטגיות אימון מהירות וחכמות כדי להאיץ את אימון המודל פי 20 ויותר בלי לפגוע בדיוק של התחזיות. כמו שציינתי קודם, ככל שיש יותר נתונים של סדרות זמן, שיטות האימון המהיר החכם יכולות להניב שיפור משמעותי יותר במהירות. בנוסף, בוצע אופטימיזציה בספריית ה-ARIMA הבסיסית שמשמשת את מודלי ARIMA_PLUS, כך שהיא פועלת מהר פי 5 מבעבר. השיפורים האלה מאפשרים ליצור תחזיות למיליוני סדרות זמן תוך שעות.
יצירת מודל לחיזוי של מיליון סדרות זמן
בשלב הזה, אתם חוזים את מכירות המשקאות החריפים של יותר ממיליון מוצרים שונים של משקאות חריפים בחנויות שונות, באמצעות נתוני מכירות של משקאות חריפים במדינת איווה שזמינים לציבור. האימון של המודל מתבצע באמצעות מרחב חיפוש קטן של היפר-פרמטרים ושיטת אימון מהירה וחכמה.
כדי להעריך את המודל, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
השלמת השאילתה נמשכת כשעה ו-16 דקות.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
- אתם יכולים למחוק את הפרויקט שיצרתם.
- אפשר גם להשאיר את הפרויקט ולמחוק את קבוצת הנתונים.
מחיקת מערך נתונים
אם מוחקים פרויקט, כל מערכי הנתונים וכל הטבלאות בפרויקט נמחקים. אם אתם מעדיפים להשתמש מחדש בפרויקט, אתם יכולים למחוק את מערך הנתונים שיצרתם במדריך הזה:
אם צריך, פותחים את הדף BigQuery במסוףGoogle Cloud .
בחלונית הניווט, לוחצים על מערך הנתונים bqml_tutorial שיצרתם.
לוחצים על מחיקת מערך הנתונים כדי למחוק את מערך הנתונים, את הטבלה ואת כל הנתונים.
בתיבת הדו-שיח מחיקת מערך נתונים, מקלידים את שם מערך הנתונים (
bqml_tutorial) כדי לאשר את פקודת המחיקה, ואז לוחצים על מחיקה.
מחיקת פרויקט
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- איך יוצרים תחזית של סדרת זמנים אחת באמצעות מודל חד-משתני
- איך יוצרים תחזית של סדרת זמנים אחת באמצעות מודל רב-משתני
- איך יוצרים תחזית של כמה סדרות זמנים באמצעות מודל חד-משתני
- איך יוצרים תחזית היררכית של כמה סדרות זמן באמצעות מודל חד-משתני
- סקירה כללית על BigQuery ML זמינה במאמר מבוא ל-AI ול-ML ב-BigQuery.