

Nesta seção, descrevemos os serviços da plataforma de agentes do Gemini Enterprise que ajudam a implementar operações de machine learning (MLOps) com seu fluxo de trabalho de machine learning (ML).
Depois de implantados, os modelos precisam acompanhar a alteração de dados do ambiente para ter um desempenho ideal e se manter relevantes. MLOps é um conjunto de práticas que melhoram a estabilidade e a confiabilidade dos sistemas de ML.
As ferramentas de MLOps da plataforma de agentes do Gemini Enterprise ajudam a colaborar com as equipes de IA e melhorar os modelos por meio de monitoramento preditivo, alerta, diagnóstico e explicações acionáveis. Todas as ferramentas são modulares, para que você possa integrá-las aos seus sistemas atuais conforme necessário.
Para mais informações sobre MLOps, consulte Pipelines de entrega contínua e automação em machine learning e o Guia de práticas para MLOps.
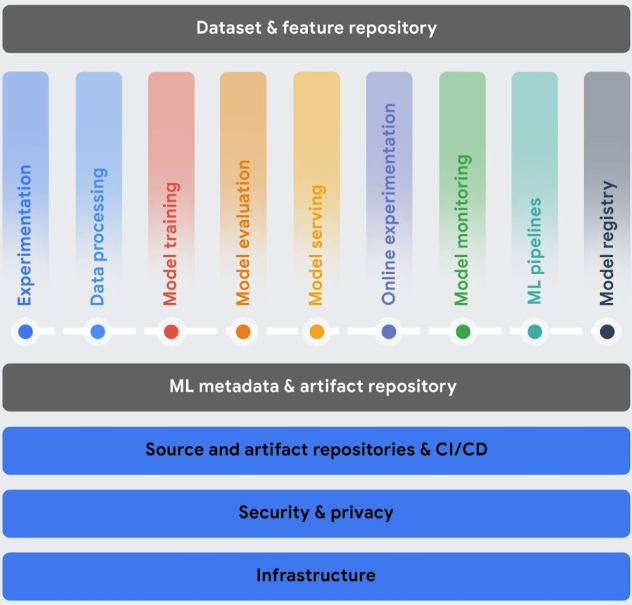
Orquestre fluxos de trabalho: o treinamento e a exibição manuais dos modelos podem ser demorados e propensos a erros, principalmente se você precisar repetir os processos muitas vezes.
- Os pipelines da plataforma de agentes do Gemini Enterprise ajudam a automatizar, monitorar e governar seus fluxos de trabalho de ML.
Gerenciar e escalonar jobs de treinamento: o gerenciamento eficiente de recursos de computação para treinamento é um desafio central de MLOps, especialmente ao escalonar da experimentação para a produção. O Vertex AI Training resolve isso fornecendo serviços flexíveis e totalmente gerenciados com opções de computação para se adequar a todo o ciclo de vida de ML.
Para experimentação e cargas de trabalho variáveis, o treinamento personalizado envolve a plataforma sem servidor padrão que provisiona recursos sob demanda, oferecendo flexibilidade máxima.
Para cargas de trabalho previsíveis e em grande escala, os clusters de treinamento da plataforma de agentes do Gemini Enterprise em clusters reservados fornecem um ambiente persistente e dedicado que garante a disponibilidade de recursos, oferece desempenho estável e ajuda a otimizar custos para equipes de alta utilização.
Rastrear os metadados usados no seu sistema de ML: na ciência de dados, é importante rastrear os parâmetros, artefatos e métricas usados no fluxo de trabalho de ML , especialmente quando você repete vários fluxos de trabalho vezes.
- O Vertex ML Metadata permite que você registre os metadados, parâmetros e artefatos usados no seu sistema de ML. Em seguida, é possível consultar esses metadados para ajudar a analisar, depurar e auditar o desempenho do sistema de ML ou dos artefatos que ele produz.
Identificar o melhor modelo para um caso de uso: ao testar novos algoritmos de treinamento, você precisa saber qual modelo treinado tem o melhor desempenho.
Os Experimentos da Vertex AI permitem rastrear e analisar diferentes arquiteturas de modelo, hiperparâmetros e ambientes de treinamento para identificar o melhor modelo para seu caso de uso.
O Vertex AI TensorBoard ajuda a rastrear, visualizar e comparar experimentos de ML para medir o desempenho dos modelos.
Gerencie versões de modelos: adicionar modelos a um repositório central ajuda a acompanhar as versões de modelos.
- O Model Registry da plataforma de agentes do Gemini Enterprise oferece uma visão geral dos seus modelos para que você possa organizar, rastrear e treinar melhor novas versões. No Model Registry, é possível avaliar modelos, implantar modelos em um endpoint, criar inferências em lote e visualizar detalhes sobre modelos específicos e versões de modelos.
Gerenciar recursos: ao reutilizar recursos de ML em várias equipes, você precisa de uma maneira rápida e eficiente de compartilhar e disponibilizar os recursos.
- O Feature Store da Vertex AI oferece um repositório centralizado para organizar, armazenar e exibir atributos de ML. Um featurestore central permite que uma organização reutilize recursos de ML em escala e aumente a velocidade de desenvolvimento e implantação de novos aplicativos de ML.
Monitorar a qualidade do modelo: um modelo implantado em produção tem um desempenho melhor em dados de entrada de inferência semelhantes aos dados de treinamento. Quando os dados de entrada se desviam dos dados usados para treinar o modelo, o desempenho do modelo pode se deteriorar, mesmo que o próprio modelo não tenha mudado.
- O Model Monitoring da plataforma de agentes do Gemini Enterprise monitora modelos para deslocamento de veiculação de treinamento e desvio de inferência e envia alertas quando os dados de inferência de entrada estão muito distantes do valor de referência de treinamento. É possível usar os alertas e as distribuições de recursos para avaliar se você precisa treinar novamente seu modelo.
Escalonar aplicativos de IA e Python: o Ray é um framework de código aberto para escalonar aplicativos de IA e Python. O Ray fornece a infraestrutura para realizar computação distribuída e processamento paralelo para seu fluxo de trabalho de machine learning (ML).
- O Ray na plataforma de agentes foi projetado para que você possa usar o mesmo código aberto Ray para escrever programas e desenvolver aplicativos na plataforma de agentes do Gemini Enterprise com alterações mínimas. Em seguida, é possível usar as integrações da plataforma de agentes do Gemini Enterprise com outros Google Cloud serviços, como o Vertex AI Inference e BigQuery, como parte do fluxo de trabalho de machine learning (ML).