Questa pagina descrive come visualizzare e interpretare i risultati della valutazione del modello dopo aver eseguito la valutazione del modello utilizzando Gen AI evaluation service.
Visualizza i risultati di una valutazione
Gen AI evaluation service ti consente di visualizzare i risultati della valutazione direttamente nel tuo ambiente di sviluppo, ad esempio un notebook Colab o Jupyter. Il metodo .show(), disponibile sia sugli oggetti EvaluationDataset che su quelli EvaluationResult, esegue il rendering di un report HTML interattivo per l'analisi.
Visualizzare le rubriche generate nel set di dati
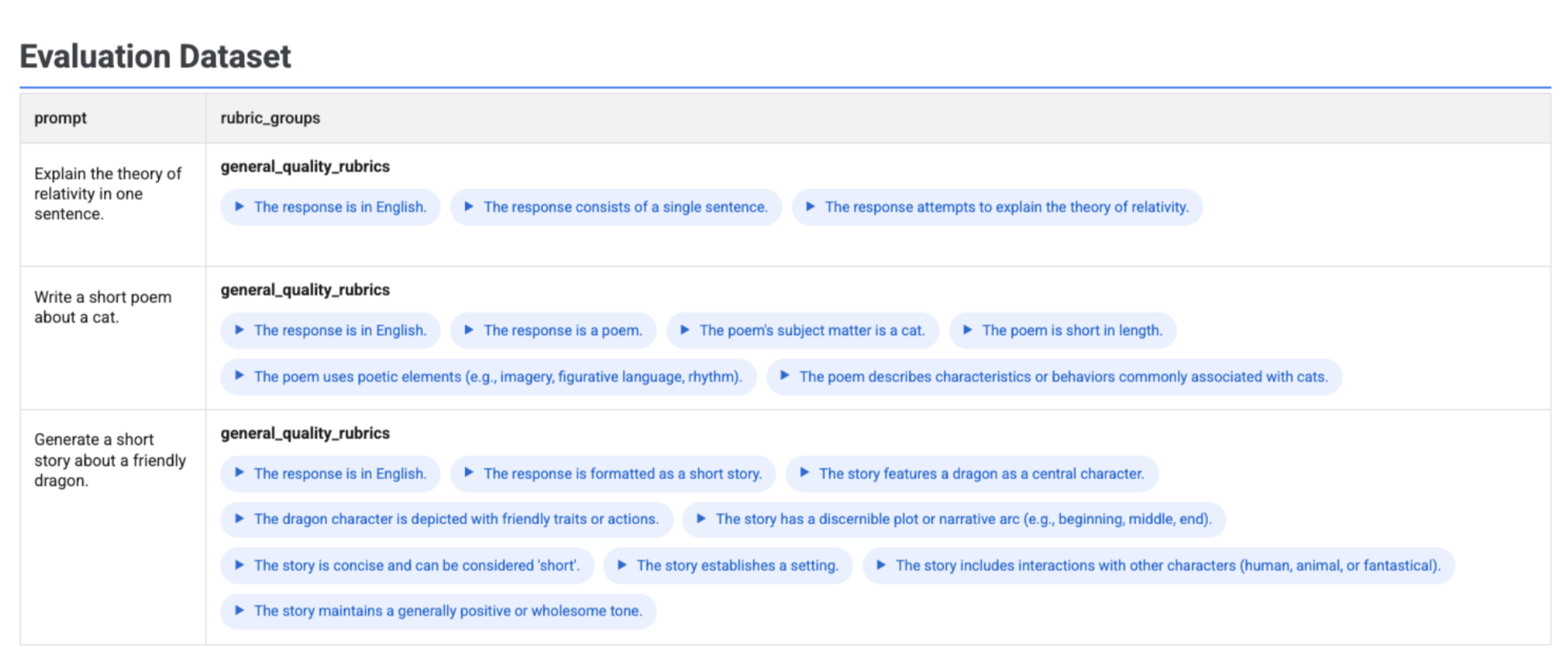
Se esegui client.evals.generate_rubrics(), l'oggetto EvaluationDataset risultante contiene una colonna rubric_groups. Puoi visualizzare questo set di dati per esaminare i criteri generati per ogni prompt prima di eseguire la valutazione.
# Example: Generate rubrics using a predefined method
data_with_rubrics = client.evals.generate_rubrics(
src=prompts_df,
rubric_group_name="general_quality_rubrics",
predefined_spec_name=types.RubricMetric.GENERAL_QUALITY,
)
# Display the dataset with the generated rubrics
data_with_rubrics.show()
Viene visualizzata una tabella interattiva con ogni prompt e le rubriche associate generate, nidificate nella colonna rubric_groups:
Visualizzare i risultati dell'inferenza
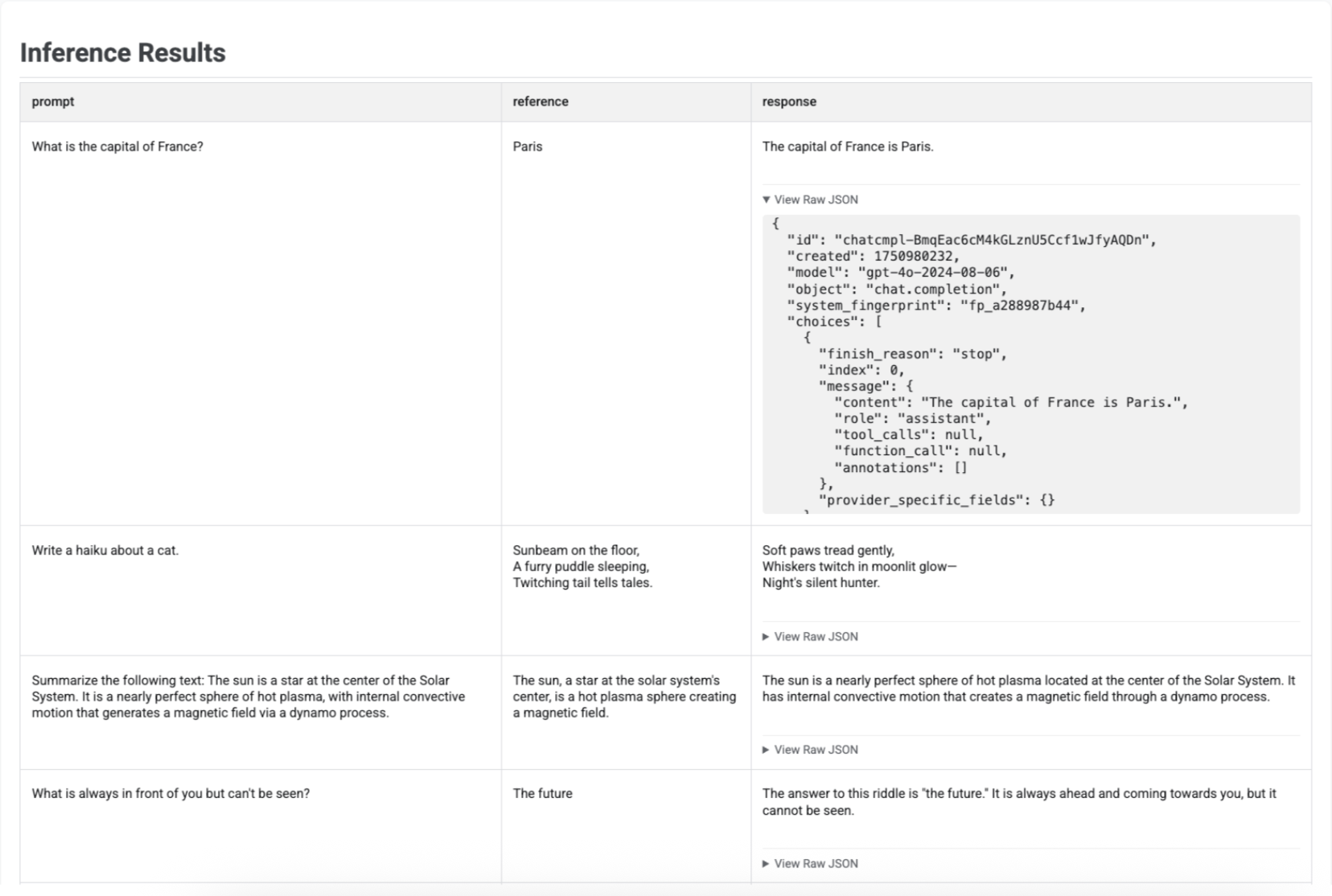
Dopo aver generato risposte con run_inference(), puoi chiamare .show() sull'oggetto EvaluationDataset risultante per esaminare gli output del modello insieme ai prompt e ai riferimenti originali. È utile per un rapido controllo della qualità prima di eseguire una valutazione completa:
# First, run inference to get an EvaluationDataset
gpt_response = client.evals.run_inference(
model='gpt-4o',
src=prompt_df
)
# Now, visualize the inference results
gpt_response.show()
Viene visualizzata una tabella con ogni prompt, il riferimento corrispondente (se fornito) e la risposta appena generata:
Per l'inferenza dell'agente, vengono visualizzati anche gli input della sessione (se forniti) e gli eventi intermedi (se generati).
Visualizzare i report sulla valutazione
Quando chiami .show() su un oggetto EvaluationResult o EvaluationRun, un report mostra le seguenti sezioni:
Metriche riepilogative: una visualizzazione aggregata di tutte le metriche, che mostra il punteggio medio e la deviazione standard nell'intero set di dati.
Risultati dettagliati: una suddivisione caso per caso che ti consente di esaminare il prompt, il riferimento, la risposta del candidato, il punteggio specifico e la spiegazione per ogni metrica. Per la valutazione dell'agente, i risultati dettagliati includono anche le tracce che mostrano le interazioni dell'agente. Per maggiori informazioni sulle tracce, vedi Tracciare un agente.
Informazioni sull'agente (solo per la valutazione dell'agente): informazioni che descrivono l'agente valutato, ad esempio istruzioni per gli sviluppatori, descrizione dell'agente e definizioni degli strumenti.
Report di valutazione di un singolo candidato
Per una singola valutazione del modello, il report descrive in dettaglio i punteggi per ogni metrica:
# First, run an evaluation on a single candidate
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[
types.RubricMetric.TEXT_QUALITY,
types.RubricMetric.FLUENCY,
types.Metric(name='rouge_1'),
]
)
# Visualize the detailed evaluation report
eval_result.show()
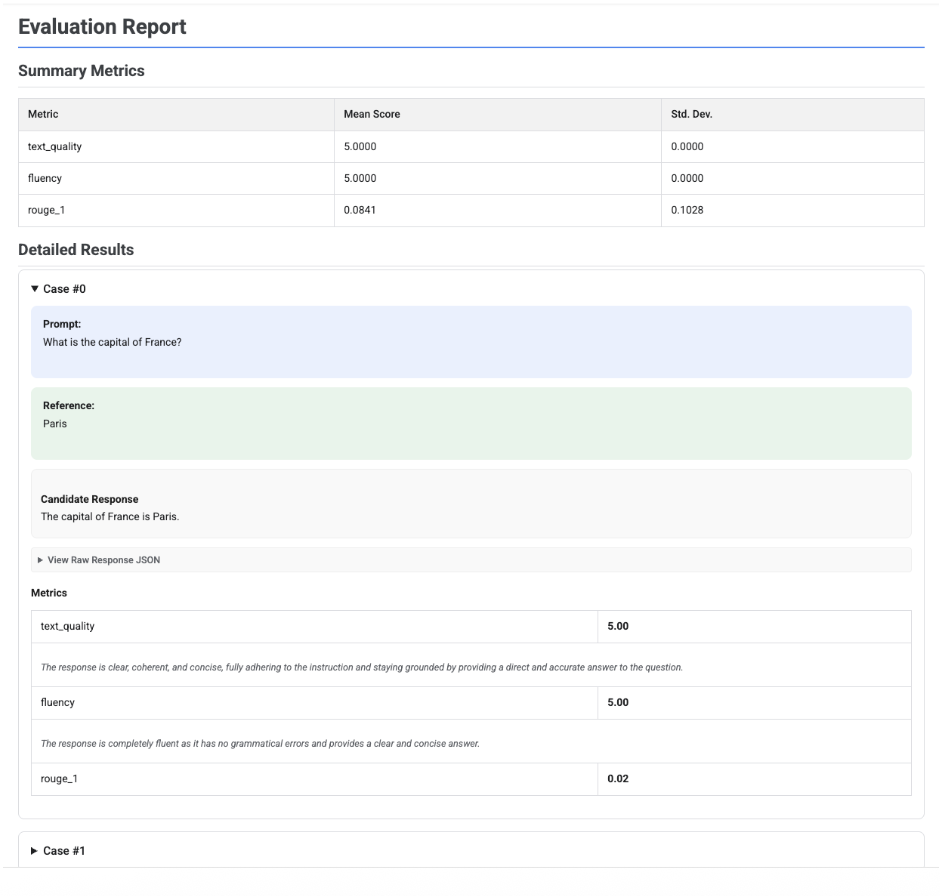
Per tutti i report, puoi espandere una sezione Visualizza JSON non elaborato per esaminare i dati in qualsiasi formato strutturato, ad esempio Gemini o OpenAI Chat Completion API.
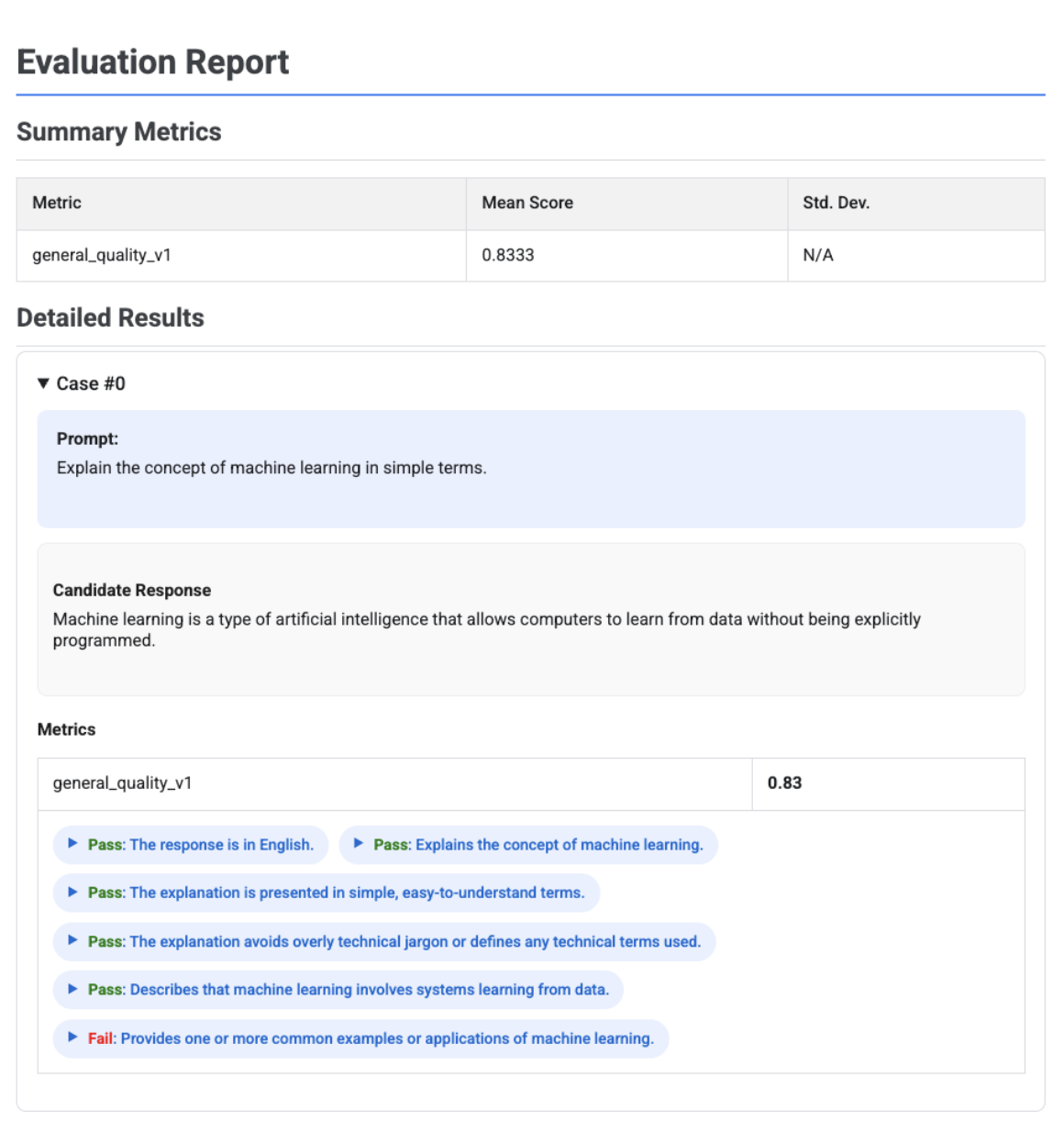
Report di valutazione basato su griglie adattive con verdetti
Quando utilizzi metriche adattive basate su griglie di valutazione, i risultati includono i verdetti di superamento o non superamento e il ragionamento per ogni griglia di valutazione applicata alla risposta.
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.PrebuiltMetric.GENERAL_QUALITY],
)
eval_result.show()
La visualizzazione mostra ogni rubrica, il relativo verdetto (Superato o Non superato) e la motivazione, nidificati all'interno dei risultati delle metriche per ogni caso. Per ogni verdetto specifico della rubrica, puoi espandere una scheda per visualizzare il payload JSON non elaborato. Questo payload JSON include dettagli aggiuntivi come la descrizione completa della rubrica, il tipo di rubrica, l'importanza e la motivazione dettagliata alla base del verdetto.
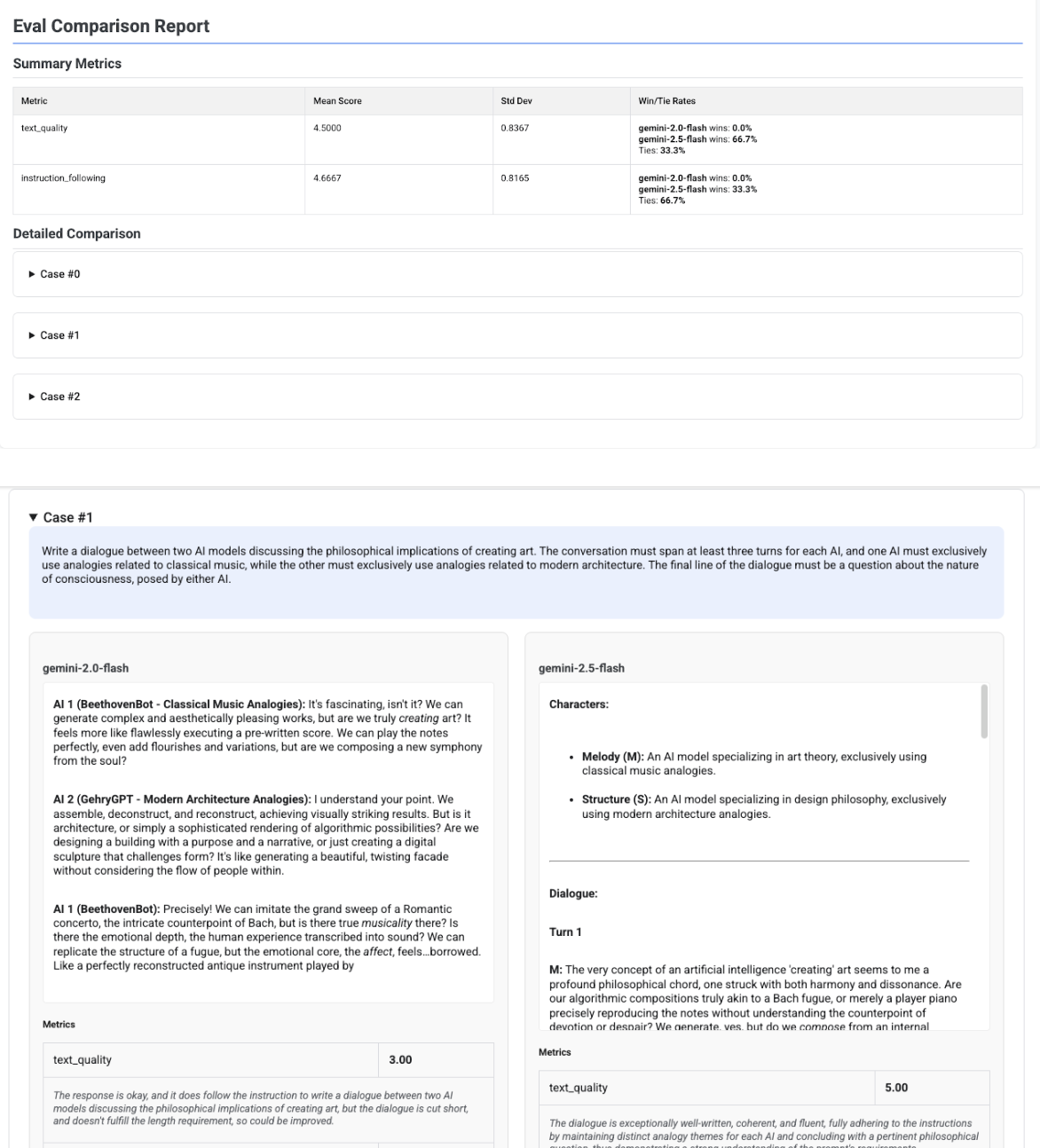
Report Confronto tra più candidati
Il formato del report si adatta a seconda che tu stia valutando un singolo candidato o confrontando più candidati. Per una valutazione di più candidati, il report fornisce una visualizzazione affiancata e include i calcoli del tasso di vittoria o pareggio nella tabella riepilogativa.
# Example of comparing two models
inference_result_1 = client.evals.run_inference(
model="gemini-2.0-flash",
src=prompts_df,
)
inference_result_2 = client.evals.run_inference(
model="gemini-2.5-flash",
src=prompts_df,
)
comparison_result = client.evals.evaluate(
dataset=[inference_result_1, inference_result_2],
metrics=[types.PrebuiltMetric.TEXT_QUALITY]
)
comparison_result.show()